この記事はNuco アドベントカレンダーの16日目の記事です。
はじめまして、higasunです。
今回の内容は、データベースについてです。
種類や歴史に始まり、実際に作ってみるところまでやってみることで理解を深めていきます。
データベース初心者でも「データベースの基本を理解して、簡単なSQLなら書ける!」くらいの状態になれる仕上がりだと思っていますので、最後までお付き合いください。
※もし間違いなどありましたらコメントで教えていただけると幸いです。
データベースって何?
データベースの定義
データベースとは、構造を持ったデータの集合のことです。
平たく言うと、あるルールに従って格納・取り出されるデータの集まりです。
データベースには複数の種類があり、それぞれにデータの扱い方のルールがあります。
データベースの歴史
最も最初に登場したデータベースは50年以上も前に遡ります。
ここでは、様々なデータベースを登場した時系列順に紹介していきます。
大きく分けると、ナビゲーショナル、リレーショナル、ポストリレーショナルという3つの時代に分類できます。
ナビゲーショナル
歴史上最初に登場したのは、ナビゲーショナルデータベースと呼ばれるものです。
データを検索する際に、データからデータへと誘導(navigate)を行うという特徴があります。
階層型データベース
階層型データベースは、データを樹形図のように階層に分けて管理するデータベースです。
上から下に向かってデータ間で親子という関係があり、下の例では、弦楽器という親ノードがギターとベースという子ノードを持っています。
また、子ノードは1つの親ノードを持つことしかできないため、ノードに対する経路が1つに定まりアクセス速度が速くなるという特徴があります。
ただ、データの登録・削除が起こるたびにノードへの経路が変わるため、データ管理が柔軟に行えないというデメリットがあります。
ネットワーク型データベース
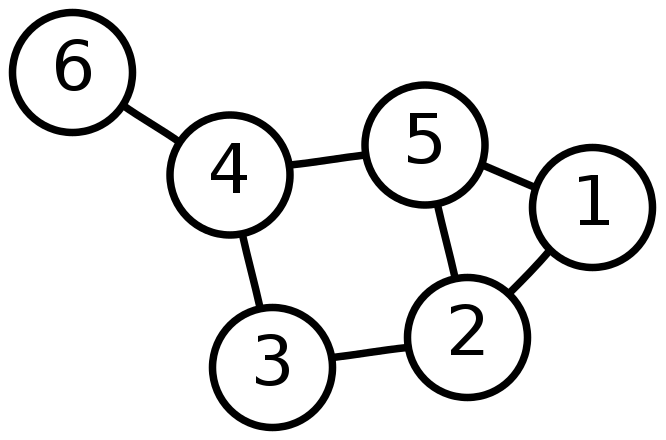
ネットワーク型データベースは、下のようにデータとデータがグラフ状に繋がっているものです。
(競プロをやったことがある人には馴染み深いかもしれません。)
階層型データベースとは異なり、ノード間を自由に接続することができます。
ただ、、階層型と同様にデータの登録・削除が起こるたびにノードへの経路が変わるというデメリットは残っています。
リレーショナル
次に登場したデータベースがリレーショナルデータベース(RDB)です。
データの格納方法を二次元の表形式として事前に定義し、構造化データとして保存します。
RDBは、SQLという言語を用いて、データの内容に応じた処理(登録・検索・更新・削除)を行うことができます。
また、複数の表を関係づけることで情報を効率的に保存したり、複雑な条件での検索が可能です。
具体的には下のようなアドレス帳のようなものです。
各行が1つのデータ(レコード)に対応していて、各列(フィールド)がデータの種類を示します。
このような1つの表のことをテーブルと呼びます。
| ID | 名前 | 住所 | 電話番号 |
|---|---|---|---|
| 1 | 田中太郎 | 東京都江東区 | 1234 |
| 2 | 佐藤花子 | 宮城県仙台市 | 5678 |
| 3 | 佐藤三郎 | 東京都足立区 | 0123 |
ポストリレーショナル
ポストリレーショナルなデータベースとして、登場したのがNoSQLです。
実はNoSQLは具体的なデータベースを指しているというわけではなく、RDB以外のデータベースを指す大まかな分類です。
もともと、「RDB以外のデータベース利用を促進しよう(Not only SQL)」というような標語的な意味合いがありました。
キーバリュー型データベース
キーバリュー型データベースは、データをキーとバリューという単純なペアで保持します。
これは辞書型やハッシュテーブルと呼ばれるデータ型としても知られます。
大量のデータを保存が必要で、複雑なデータ検索を行わないような場合に適しています。
具体的には下のように、あるキーとそれに対応するバリューを格納します。
キーに対応して、データであるバリューが取得できます。
バリューの内容はデータによって異なっても構いません。

ドキュメント指向データベース
ドキュメント指向データベースでは、下の図のようにデータを制約無く自由な形で保存します。
JSONやXMLといった形式で保存されることが多いです。
RDBのようにデータの構造設計は必要ない、というスキーマレスという特徴があります。
そのためデータの形式が変わっても対応ができます。
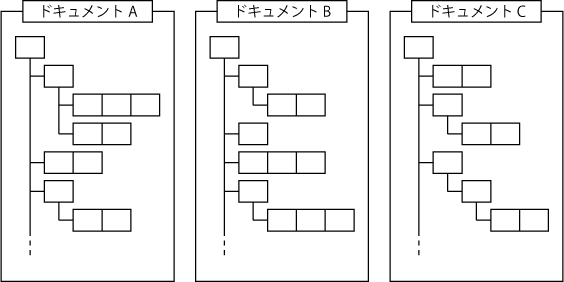
出典: <ドキュメント指向データベースと列指向データベース>
NewSQL
NoSQLに競合するポストリレーショナルなデータベースとしてNewSQLというものがあります。
これは、従来のRDBとNoSQLのいいとこ取りを目指したデータベースモデルです。
詳しく知りたい方は、以下の記事がまとまっていて分かりやすいので読んでみてください。
各データベースの特徴
ここでは、現在よく使われているRDBとNoSQLの特徴を比較してみます。
比較のためにいくつかの概念をまず紹介します。
ACID特性
突然ですが、銀行のATMシステムが行なっている処理について考えてみましょう。
「自分の口座から5万円を別の口座に送金する」ということをしたい場合、ATMのシステムは
- 自分の口座から5万円を引く
- 送り先の口座に5万円足す
という処理を行なっていますね。
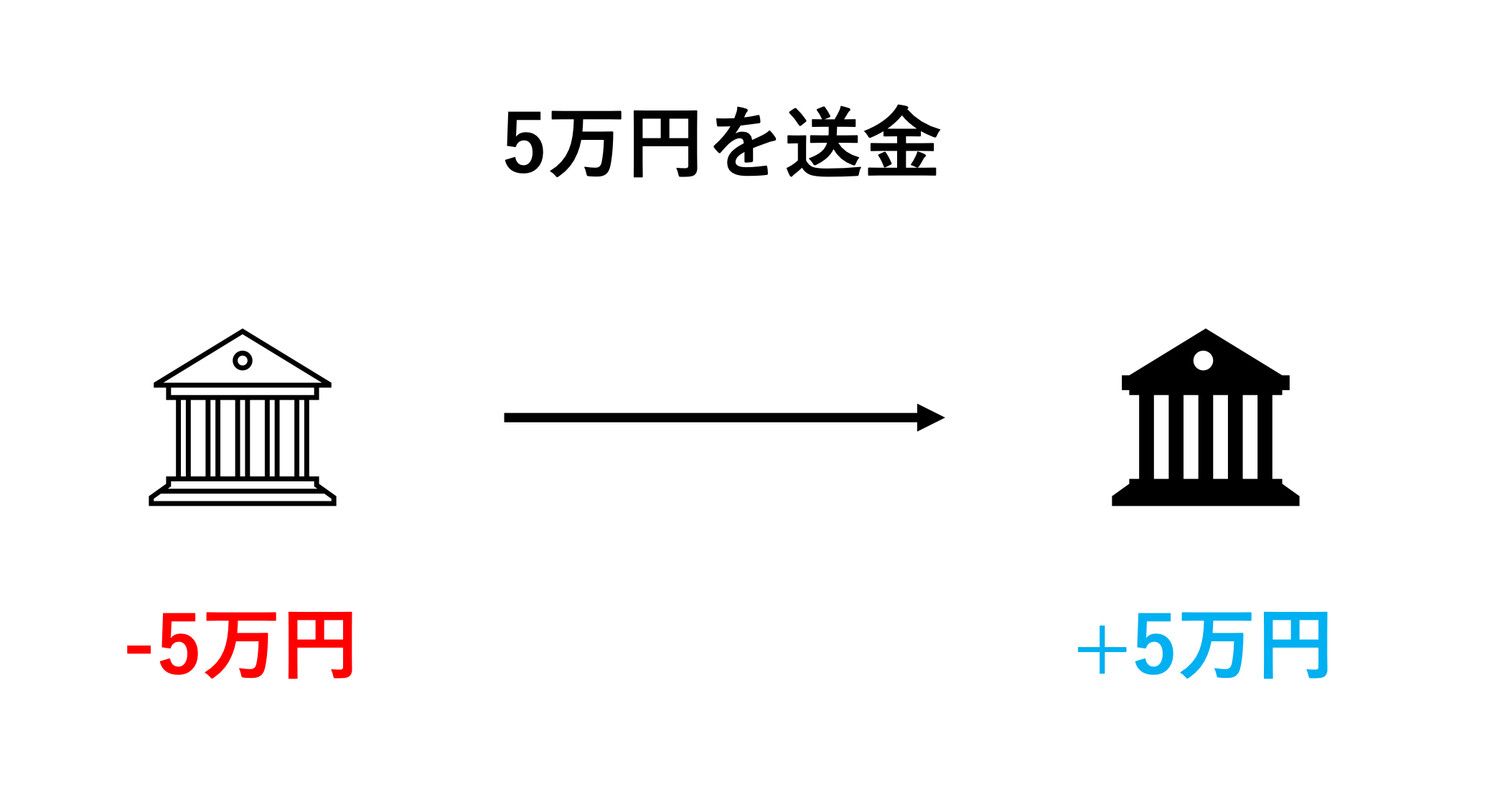
このような処理をトランザクション処理と言います。
正確に言うと、相互依存の関係にある複数の処理をまとめて、矛盾なく処理するということです。
もし「自分の口座からは5万円が引かれたのに、送り先の口座残額は増えていない」というようなことが起こると困ってしまいますね。
このようなトラブルを防ぐために、トランザクション処理にはACID特性と呼ばれる「データの整合性を保証する特性」が求められます。
具体的には、以下のような4つの特性のことで、頭文字を取ってACIDと呼ばれています。
| 意味 | ATMの例 | |
|---|---|---|
| Atomicity | 処理が中断されない | 出金と入金をひとまとまりに行う |
| Consistency | データに矛盾がない | 口座残額がマイナスになったりしない |
| Isolation | 処理中の状態は外部から見えない | 「出金されたが入金が行われていない」という状態は外部から見えない |
| Durability | 処理の結果が必ず保存される | 送金中に障害が起こっても元の口座にお金が戻る |
CAP定理
今度は、インターネット上の大量のデータを扱う場合を考えましょう。
扱うデータが大きくなると1台のコンピュータでは処理が遅くなります。
そこで、複数のコンピュータでデータ処理を行う「分散処理」によって効率化を図ります。
CAP定理は、「分散処理において次の3つの望ましい性質のうち、全てを同時に満たすことはできない」というものです。
※ここでいうノードとはネットワークに繋がっているひとつひとつのコンピュータのことだと理解していただいて大丈夫です。
| 訳 | 意味 | |
|---|---|---|
| Consistency | 一貫性 | 常に全てのノードで最新のデータが得られる |
| Availability | 可用性 | ノードの一部に障害が発生しても生存ノードが応答する |
| Partition-tolerance | 分断耐性 | ネットワークに障害が起こってノード間が分断されても正常に動作する |
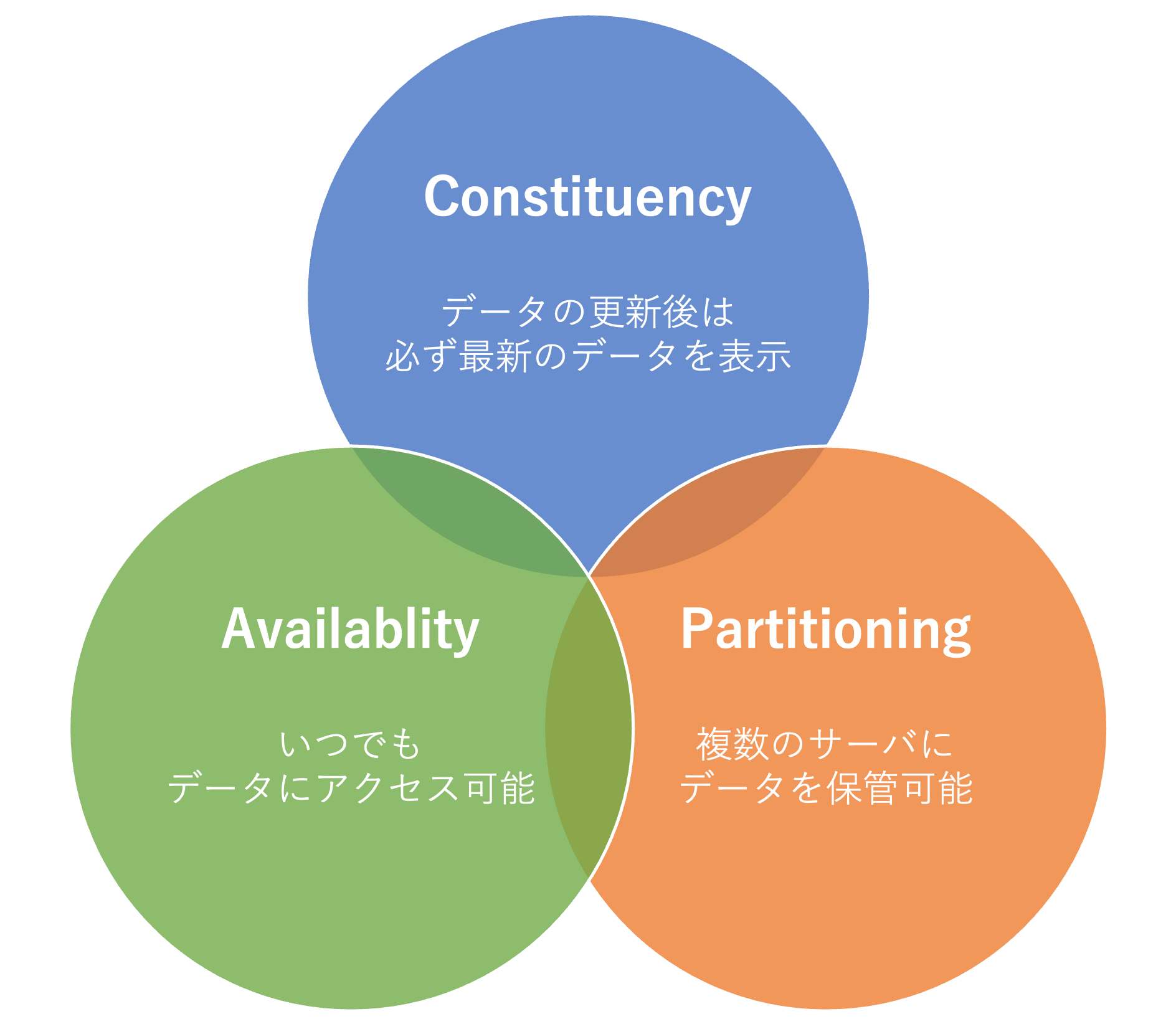
例えば、一貫性(C)と可用性(A)を満たすシステムを作りたい場合、全てのノードで最新のデータを共有しなければなりません。
しかし、このようなシステムはネットワークが分断されると「全てのノードで最新のデータを共有」することは不可能となり、分断耐性(P)を持つことができないということになります。
RDBとNoSQLの比較
簡単にRDBとNoSQLが適している用途をまとめると、以下のようになります。
| RDB | NoSQL |
|---|---|
| 構造化データ | 非構造化データ |
| データに対する厳密な一貫性 | 大量のデータに対する迅速な処理 |
RDBのメリット
RDBは基本的に上で紹介したトランザクション処理に最適化された設計になっています。
ということは、RDBは「データの整合性を保つ」つまりACID特性を持っているということです。
CAP定理で言うと、RDBが満たすのはCとAで、データがいつでも利用可能で一貫しています。
なので、先ほど挙げた銀行のシステムや電子商取引など、データの厳密な一貫性が求められる場合に活躍します。
RDBのデメリット
RDBには、データ量が多いと処理速度が遅かったり、元々1台のコンピュータで動くように設計されていたという背景もあり分散処理をさせるために拡張しづらかったりするという特徴があります。
また、構造化されたデータを扱うことはできますが、画像や文章などの非構造化データは扱えません。
インターネットが普及し、扱うデータの種類や量が増えるとこのようなデメリットを持つRDBでは対応できなくなってきたため、NoSQLの必要性が叫ばれたという背景があります。
NoSQLのメリット
NoSQLは処理速度が速く、分散処理を効率的に行うことができる上、画像や文章といった非構造化データを扱えるといった特徴があり、RDBのデメリットをカバーしています。
したがって、NoSQLは大量のデータを扱ったり、扱うデータに対する柔軟性が欲しい時に活躍します。
CAP定理で言うと、NoSQLの多くはC+PまたはA+Pを満たすものに分けられます。
分散処理をしたいときは、Pの「システムの一部が分断しても機能できる」という性質が不可欠だからですね。
その上で、Cの一貫性とAの可用性のどちらを重視するかは実際のデータベースによって異なります。
NoSQLのデメリット
NoSQLはACID特性を求められる用途には向いていません。
RDBは一貫性に特化したACID特性を基に設計されていますが、NoSQLはBASE特性と呼ばれる別の思想に基づいて設計されているからです。
BASE特性では、先ほど紹介したようjにCAPのうち一貫性(C)や可用性(A)の一部を犠牲にすることで、分散処理のために必要な分断耐性(P)を保証します。
したがって、ACID特性のようにいつでも最新のデータを得られるわけではありません。
※ただしBASE特性では、十分な時間が経つと一貫性が保たれます。
また、RDBが得意とする複雑な条件でのデータ検索を行いたい場合には適していません。
リレーショナルデータベースを作って遊んでみる
ここからは実際にリレーショナルデータベースを作ってみて、理解を深めましょう!
データベースを使うためのツール
まず、RDBを扱うためのツールを紹介します。
DBMS
DBMSはデータベースマネジメントシステムの略で、実際にデータベースを作成・管理するためのツールです。
具体的な名前を上げるとMySQLやDB2、Oracleなど様々なものがあります。
注意してほしいのは、「データベース」はあくまで抽象的なものであり、DBMSは「データベース」を実現するための具体的なツールであるということです。
今回はMySQLというDBMSを使用します。
SQL
SQLはStructured Query Languageの略で、データベースを操作するための言語です。
データの追加、削除、更新、検索といった操作を行えます。
以下は検索を行うSQL文の例で、「stockというテーブルからpriceというフィールドが1000以下のレコードを取り出して」という意味です。
詳しい説明は後ほど行うので、ここではなんとなくイメージを掴んでもらえると良いです。
SELECT * FROM stock WHERE price <= 1000;
MySQLのインストール
それでは実際にMySQLをインストールしてみましょう。
Progateのサイトが分かりやすいのでOSに応じて参照しながらインストールしてください。
上記のサイトに従ってMySQLのインストールとログインを済ませると、以下のような画面になると思います。
ここにSQL文を打ち込んでいきます。
mysql >
Databaseの作成
今回は、果物屋の在庫表データベースを作ってみて理解を深めましょう。
MySQLではまずdatabaseというものを作り、その中にテーブルを作成していきます。
以下のコマンドでshopというdatabaseを作成しましょう。
CREATE DATABASE shop;
作成できたらshopというdatabaseを使うことを宣言しましょう。
USE shop;
今回作りたい在庫表テーブル
今回作りたい果物の在庫表は以下のように、4つフィールドを持っているものとします
nameは果物の名前、priceは値段、countryは産地を表します。
ちなみにIDは、このテーブルにおける主キーと呼ばれるもので、レコードを一意に区別するためのものです。
| id | name | price | country |
|---|---|---|---|
| 1 | orange | 100 | us |
| 2 | apple | 150 | japan |
| 3 | mango | 300 | taiwan |
| 4 | orange | 180 | japan |
| 5 | grape | 500 | italy |
テーブルの作成
テーブルの作成は以下のように行います。
CREATE TABLE stock
(id INT AUTO_INCREMENT,
name TEXT,
price INT,
country TEXT,
PRIMARY KEY (id));
CREATE TABLE stockでテーブルの名前をstockと定義していますね。
二行目以降は各フィールドのデータの型を定義しています。
最後の行でこのテーブルの主キーがidである、と宣言しています。
また、idの部分AUTO_INCREMENTとあるのは、新たなに追加されたレコードに対して、現在格納されているレコードのうち最大のidに1だけ足したidを与えるという設定です。
これによって他のレコードと被ることはありませんね。
新しいデータを登録する
新しいレコードの登録は以下のような構文でできます。
INSERT INTO table
(field1, field2, ...)
VALUES (value1, value2)...
フィールドとそれに対応するデータを入れていくというイメージですね。
今回はこのようなデータを登録していきます。
| id | name | price | country |
|---|---|---|---|
| 1 | orange | 100 | us |
| 2 | apple | 150 | japan |
| 3 | mango | 300 | taiwan |
| 4 | orange | 180 | japan |
| 5 | grape | 500 | italy |
試しに1つめのUS産のオレンジを追加してみます。
INSERT INTO stock
(name, price, country)
VALUES ('orange', 100, 'us');
これに倣って表にある他の果物もどんどん追加してみてください。
答え合わせは、以下のSQLを打ち込んで
SELECT * FROM stock;
このように表と同じ結果が得られれば、正解です!
+----+--------+-------+---------+
| id | name | price | country |
+----+--------+-------+---------+
| 1 | orange | 100 | us |
| 2 | apple | 150 | japan |
| 3 | mango | 300 | taiwan |
| 4 | orange | 180 | japan |
| 5 | grape | 500 | italy |
+----+--------+-------+---------+
データを検索する
基本的な構文
実は先ほどの答え合わせで使った、SELECTというコマンドはデータを取り出すためのものです。
以下のような構文でhogeというテーブルからfield1とfield2について取り出すことができます。
SELECT field1, field2, ... FROM hoge;
先ほど使った*はワイルドカードと呼ばれ、全てのフィールドについて取り出すことができます。
SELECT * FROM hoge;
WHEREによる条件付け
作成したstockテーブルから日本産の果物だけを見たいときはどうすれば良いでしょうか。
ここで活躍するのが、WHERE句による条件づけです。以下のSQL文を打ってみましょう。
SELECT * FROM stock
WHERE country = 'japan';
このように日本産の果物の在庫が表示されると思います。
+----+--------+-------+---------+
| id | name | price | country |
+----+--------+-------+---------+
| 2 | apple | 150 | japan |
| 4 | orange | 180 | japan |
+----+--------+-------+---------+
このSQLのWHERE country = 'japan'の部分が、countryフィールドが'japan'となるような条件づけを行なっています。
他にも、150円以上の果物を表示したいときは以下のようにすれば良いです。
SELECT * FROM stock
WHERE price >= 150;
+----+--------+-------+---------+
| id | name | price | country |
+----+--------+-------+---------+
| 2 | apple | 150 | japan |
| 3 | mango | 300 | taiwan |
| 4 | orange | 180 | japan |
| 5 | grape | 500 | italy |
+----+--------+-------+---------+
データを更新する
では最後にデータの更新を行なってみます。
例として、日本産のオレンジの値段が130円を下げたい場合、このように書けば良いです。
UPDATE stock
SET price = 130
WHERE name = 'orange' AND country = 'japan';
ここでもWHERE句が使われていますね。
今回は、ANDによって2つの条件がどちらも成り立つようなレコードを指定しています。
さらに、SET price = 130によって更新したいフィールド(price)に新しい値(130)を渡しています。
正しくデータが更新されていることをSELECT文で確認してみましょう。
SELECT * FROM stock
WHERE name = 'orange' AND country = 'japan';
このような結果が得られると思います。正しく130円に値下げされていますね。
+----+--------+-------+---------+
| id | name | price | country |
+----+--------+-------+---------+
| 4 | orange | 130 | japan |
+----+--------+-------+---------+
もっとデータベースを学ぶ
データベースの歴史
データベースの歴史やどんな種類があるのかを学びたい場合は以下のサイトが参考になります。
SQLの練習
ここで紹介したSQL文はほんの基礎の基礎に過ぎません。
もっとSQLを練習したいという方は、以下のサイトを参考にして練習してみてください。
どちらもブラウザ上で動かせるので、手軽に勉強ができます。
RDB
リレーショナルデータベースについて基本をしっかり押さえたいという方は以下の本をお勧めします。データベースの基本的な内容から運用コストや冗長化などの実践的な内容も学ぶことができます。

参考
以下のサイトを参考にしました。
分かりやすいものが多いので是非見てみてください。
おわりに
弊社では、経験の有無を問わず、社員やインターン生の採用を行っています。
興味のある方はこちらをご覧ください。