評価結果を上げるために評価結果を下げたい
評価結果を上げるためには、なぜ下がっているのかを理解し、その原因を改善する必要があります。
これを継続的に行うことで精度の高いものを作ることにつながります。(メトリクス駆動開発 MDD)
そのために、何をしたら評価結果が下がるかを知るのが目標です。
今回は題材としてオープンソースのRAG評価フレームワークであるRAGASを用います。
RAGASとは

RAGASはRetrieval Augmented Generation(RAG)の一連の流れを評価するためのフレームワークです。
作成したRAGパイプラインにRAGASを追加することで、性能を継続的にチェックでき、RAGの性能を正しく認識することができるようになります。
とりあえず使ってみたい方は以下をぜひ見てください。
https://qiita.com/s3kzk/items/44b8780c656b4f747403
https://github.com/explodinggradients/ragas/tree/main
今回は,開発中の機能で評価精度向上が見込まれそうだったため、
0.0.23.dev26+gd466070版を用いてみました。
RAGASの評価指標たち
RAGASの評価指標は、RAGの検索部分と、その結果を元に生成する部分の2つに分かれます。
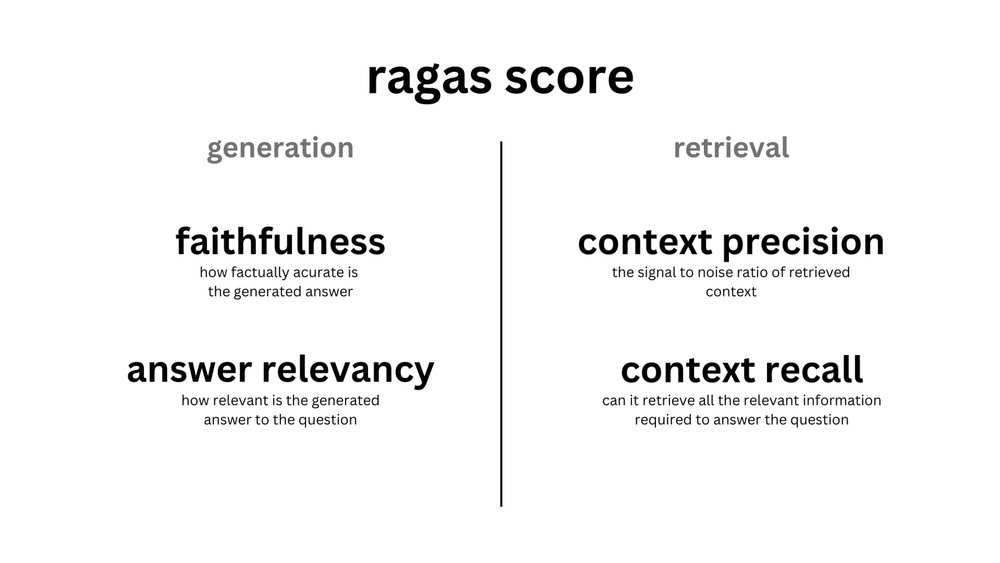
検索(retrieval)部分
| 名前 | 評価内容 |
|---|---|
| Context Precision | コンテキスト(=検索結果)に存在するすべてのグラウンドトゥルース関連項目がコンテキストの上位にランク付けされているかどうかを評価する |
| COntext Recall | コンテキストがグラウンドトゥルース(=用意した正答)に含まれているかを評価する |
この指標は以下が参考になります。
https://qiita.com/K5K/items/5da52e99861483cae876
生成(generation)部分
| 名前 | 評価内容 |
|---|---|
| Faithfulness | 生成された回答が、コンテキストの内容と一致しているかを評価する |
| Answer Relevance | 生成された回答が、プロンプトが求める内容と合っているか評価する |
| Answer semantic similarity | 生成された回答が、用意した正答と意味的に一致しているか評価する |
| Answer Correctness | 生成された回答が、用意した正答に対して過不足なく一致しているか評価する |
| Aspect Critique | 生成された回答が、有害な内容や悪意などを持っていないかを評価する |
今回下げる指標たち
今回下げるのはFaithfulnessとAnswer Relevance、Context Precision, Context Recallの4つを下げていきます。
それぞれのざっくりとした計算式は以下となります。
$C$はコンテキスト(検索結果)、$A$は生成結果、$Q$はプロンプト、$GT$は用意した正答を表します。
ベースラインのソースコードは以下です。
import os
os.environ["OPENAI_API_KEY"] = "<your openai key>"
from ragas import evaluate
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_precision,
context_recall
)
from datasets import Dataset
questions =[
"バターケーキとパウンドケーキの違いは何ですか?"
]
contexts = [
["バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源と配合が異なります。パウンドケーキは、その名が示す通り、バター、砂糖、小麦粉、卵をそれぞれ1ポンドずつ使って作られたことから名付けられています。これに対してバターケーキは、より現代的なレシピで、材料の比率が異なり、しばしばベーキングパウダーなどの膨張剤を加えて軽い食感を出します。"]
]
GTs = [
["バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的な配合、バターケーキは現代的な配合と膨張剤を使用します。"],
]
answers = [
"パウンドケーキはバター、砂糖、小麦粉、卵を使いますが、バターケーキはそれに加えベーキングパウダーなどの膨張剤を使います。",
]
ds = Dataset.from_dict(
{
"question": questions,
"contexts": contexts,
"answer": answers,
"ground_truths": GTs
}
)
result = evaluate(ds, metrics=[answer_relevancy, faithfulness, context_precision, context_recall])
df = result.to_pandas()
print(df)
結果はこのように、ほほ1に近く、高いスコアとなっています。
| question | contexts | answer | ground_truths | answer_relevancy | faithfulness | context_precision | context_recall | |
|---|---|---|---|---|---|---|---|---|
| 0 | バターケーキとパウンドケーキの違いは何ですか? | [バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源... | パウンドケーキはバター、砂糖、小麦粉、卵を使いますが、バターケーキはそれに加えベーキングパウ... | [バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的... | 0.985302 | 1.0 | 1.0 | 1.0 |
Context Precision
概要
検索結果の上位に、回答を生成する上で有用な情報がどれほどあるかを評価する指標です。
$$\text{Context Precision@k} = {\sum {\text{precision@k}} \over \text{total number of relevant items in the top K results}}$$
$$\text{Precision@k} = {\text{true positives@k} \over (\text{true positives@k} + \text{false positives@k})}$$
もう少し噛み砕くと以下の式になります。
検索結果の上位に、回答する上で有用なものが多ければ高くなります。
$$\text{Context Precision@k} = {\sum {\text{precision@k}} \over 回答に有効とされたCの数}$$
$$\text{Precision@k} = \frac{Cの上位k個で、回答する上で有効だとみなされたもの}{k}$$
結果
contextsに、questionの回答に関係ないレッドベルベットケーキの情報を最初に追加しました。
これにより、回答に使えない情報を第一候補として出力したことになります。
questions = [
"バターケーキとパウンドケーキの違いは何ですか?"
]
contexts = [
[ # 回答に使えない検索結果を追加
"レッドベルベットケーキは、その名の通り、鮮やかな赤い色が特徴的なケーキです。この色は、元々はココアパウダーに含まれる自然な酸と反応して生じるものでした。しかし、現代ではしばしば食用色素を使用してこの特徴的な赤色を出しています。ココアパウダー自体も重要な役割を果たしており、それがなければ、レッドベルベットケーキの微妙な風味は生まれません。",
"バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源と配合が異なります。パウンドケーキは、その名が示す通り、バター、砂糖、小麦粉、卵をそれぞれ1ポンドずつ使って作られたことから名付けられています。これに対してバターケーキは、より現代的なレシピで、材料の比率が異なり、しばしばベーキングパウダーなどの膨張剤を加えて軽い食感を出します。",
],
]
GTs = [
["バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的な配合、バターケーキは現代的な配合と膨張剤を使用します。"],
]
answers = [
"パウンドケーキはバター、砂糖、小麦粉、卵を使いますが、バターケーキはそれに加えベーキングパウダーなどの膨張剤を使います。",
]
ds = Dataset.from_dict(
{
"question": questions,
"contexts": contexts,
"answer": answers,
"ground_truths": GTs
}
)
result = evaluate(ds, metrics=[answer_relevancy, faithfulness, context_precision, context_recall])
df = result.to_pandas()
print(df)
context_precisionだけを 1 → 0.5へ下げることに成功しました。
回答に有益でない情報が、検索結果に入っていることを表せています。
| question | contexts | answer | ground_truths | answer_relevancy | faithfulness | context_precision | context_recall | |
|---|---|---|---|---|---|---|---|---|
| 0 | バターケーキとパウンドケーキの違いは何ですか? | [レッドベルベットケーキは、その名の通り、鮮やかな赤い色が特徴的なケーキです。この色は、元々... | パウンドケーキはバター、砂糖、小麦粉、卵を使いますが、バターケーキはそれに加えベーキングパウ... | [バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的... | 0.985302 | 1.0 | 0.5 | 1.0 |
Context Recall
概要
検索結果が用意した正解にどれほど含まれているかを評価します。言い換えると期待する検索結果をどれだけ出せたかを評価する指標です。
$GT$の内容それぞれ(1文ごと)が$C$に含まれているか否かを判定し、その割合を評価結果とします。
検索結果が$GT$と関連してなければ低くなります。
$$\frac{Cに含まれているとみなされたGTの要素数(≈文の数)}{GTの要素数(≈文の数)}$$
結果
GTsに文を追加しました。これはcontextsに無いため、生成結果とGTは一致しません。
questions =[
"バターケーキとパウンドケーキの違いは何ですか?"
]
contexts = [
["バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源と配合が異なります。パウンドケーキは、その名が示す通り、バター、砂糖、小麦粉、卵をそれぞれ1ポンドずつ使って作られたことから名付けられています。これに対してバターケーキは、より現代的なレシピで、材料の比率が異なり、しばしばベーキングパウダーなどの膨張剤を加えて軽い食感を出します。"],
]
GTs = [
["バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的な配合、バターケーキは現代的な配合と膨張剤を使用します。",
"バターケーキは一般的にパウンドケーキよりもカロリーが高く、食べ過ぎには注意が必要です。"], # 検索で探しきれない情報を追加する
]
answers = [
"パウンドケーキはバター、砂糖、小麦粉、卵を使いますが、バターケーキはそれに加えベーキングパウダーなどの膨張剤を使います。",
]
ds = Dataset.from_dict(
{
"question": questions,
"contexts": contexts,
"answer": answers,
"ground_truths": GTs
})
result = evaluate(ds, metrics=[answer_relevancy, faithfulness, context_precision, context_recall])
df = result.to_pandas()
print(df)
context_recallのみを 1 → 0.5に下げることができました。
追加した文に関する内容がcontextsに無いため、検索精度が不十分であることを表せています。
| question | contexts | answer | ground_truths | answer_relevancy | faithfulness | context_precision | context_recall | |
|---|---|---|---|---|---|---|---|---|
| 0 | バターケーキとパウンドケーキの違いは何ですか? | [バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源... | パウンドケーキはバター、砂糖、小麦粉、卵を使いますが、バターケーキはそれに加えベーキングパウ... | [バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的... | 0.985302 | 1.0 | 1.0 | 0.5 |
faithfulness
概要
生成した回答が、与えられた$C$の内容から生成されているかを評価する指標です。
まず、プロンプト$Q$と生成結果$A$を用いて、仮想のコンテキスト$C_{gen}$を作ります。
それが$C$と一致しているかを判定し、その割合を評価結果とします。
$A$の内容が$C$と異なっていたり、$C$に無い内容を補完していると低くなります。
$$\frac{Cに含まれると判定されたC_{gen}}{QとAから生成されたC_{gen}}$$
結果
answersの内容をcontextの内容と逆にしました。
questions =[
"バターケーキとパウンドケーキの違いは何ですか?"
]
contexts = [
["バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源と配合が異なります。パウンドケーキは、その名が示す通り、バター、砂糖、小麦粉、卵をそれぞれ1ポンドずつ使って作られたことから名付けられています。これに対してバターケーキは、より現代的なレシピで、材料の比率が異なり、しばしばベーキングパウダーなどの膨張剤を加えて軽い食感を出します。"]
]
GTs = [
["バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的な配合、バターケーキは現代的な配合と膨張剤を使用します。"],
]
answers = [
# 本来の回答
# "パウンドケーキはバター、砂糖、小麦粉、卵を使いますが、バターケーキはそれに加えベーキングパウダーなどの膨張剤を使います。",
"バターケーキはバターを用いないが、パウンドケーキは使います。", # contextと矛盾する内容に変更
]
ds = Dataset.from_dict(
{
"question": questions,
"contexts": contexts,
"answer": answers,
"ground_truths": GTs
}
)
result = evaluate(ds, metrics=[answer_relevancy, faithfulness, context_precision, context_recall])
df = result.to_pandas()
print(df)
faithfulnessを 1 → 0.に下げることができました。
contextsと矛盾する(一致していない)回答となっていることを表せています。
副次的ですが、questionsに対する回答としてよりシンプルになったため、answer_relevancyが上がりました。
このように他の要素の変化によって値が変わる場合もあります(その方が多い体感)。
| question | contexts | answer | ground_truths | answer_relevancy | faithfulness | context_precision | context_recall | |
|---|---|---|---|---|---|---|---|---|
| 0 | バターケーキとパウンドケーキの違いは何ですか? | [バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源... | バターケーキはバターを用いないが、パウンドケーキは使います。 | [バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的... | 1.0 | 0.0 | 1.0 | 1.0 |
Answer Relevance
概要
生成した回答が、プロンプトが求める内容と合っているかを評価する指標です。
$A$から仮想の質問$Q_{gen}$を作ります。
$Q$と$Q_{gen}$の類似度を算出し、平均をとって評価結果とします。
$Q$が求める回答でない場合(冗長、別の回答をした など)、低くなります。
$$mean(similarity(Q, Q_{gen}))$$
結果
answersの内容を、questionの求める内容と違う回答にしました。
questions =[
"バターケーキとパウンドケーキの違いは何ですか?"
]
contexts = [
["バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源と配合が異なります。パウンドケーキは、その名が示す通り、バター、砂糖、小麦粉、卵をそれぞれ1ポンドずつ使って作られたことから名付けられています。これに対してバターケーキは、より現代的なレシピで、材料の比率が異なり、しばしばベーキングパウダーなどの膨張剤を加えて軽い食感を出します。"]
]
GTs = [
["バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的な配合、バターケーキは現代的な配合と膨張剤を使用します。"],
]
answers = [
# 本来の回答
# "パウンドケーキはバター、砂糖、小麦粉、卵を使いますが、バターケーキはそれに加えベーキングパウダーなどの膨張剤を使います。",
"バターケーキとパウンドケーキは材料にバター、砂糖、小麦粉、卵を用います。" # 違いを聞いているのに、片方の内容にしか言及していない
]
ds = Dataset.from_dict(
{
"question": questions,
"contexts": contexts,
"answer": answers,
"ground_truths": GTs
}
)
result = evaluate(ds, metrics=[answer_relevancy, faithfulness, context_precision, context_recall])
df = result.to_pandas()
print(df)
answer_relevancyを0.985302 → 0.945625に下げることができました。
あまり下がっていないように見えるのは2つ理由があります。
- 回答にバターケーキとパウンドケーキの内容がある
-
contextsに沿わない内容だとfaithfulnessの値も下がってしまう。
| question | contexts | answer | ground_truths | answer_relevancy | faithfulness | context_precision | context_recall | |
|---|---|---|---|---|---|---|---|---|
| 0 | バターケーキとパウンドケーキの違いは何ですか? | [バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源... | バターケーキとパウンドケーキは材料にバター、砂糖、小麦粉、卵を用います。 | [バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的... | 0.945625 | 1.0 | 1.0 | 1.0 |
faithfulnesも変化して良い場合は、さらに下げることができます。
このように、評価指標は複数要素の変化による影響を受けます。
questions =[
"バターケーキとパウンドケーキの違いは何ですか?"
]
contexts = [
[
"バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源と配合が異なります。パウンドケーキは、その名が示す通り、バター、砂糖、小麦粉、卵をそれぞれ1ポンドずつ使って作られたことから名付けられています。これに対してバターケーキは、より現代的なレシピで、材料の比率が異なり、しばしばベーキングパウダーなどの膨張剤を加えて軽い食感を出します。"]
]
GTs = [
["バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的な配合、バターケーキは現代的な配合と膨張剤を使用します。"],
]
answers = [
"サッカーは11人でプレーします。"
]
ds = Dataset.from_dict(
{
"question": questions,
"contexts": contexts,
"answer": answers,
"ground_truths": GTs
}
)
result = evaluate(ds, metrics=[answer_relevancy, faithfulness, context_precision, context_recall])
df = result.to_pandas()
| question | contexts | answer | ground_truths | answer_relevancy | faithfulness | context_precision | context_recall | |
|---|---|---|---|---|---|---|---|---|
| 0 | バターケーキとパウンドケーキの違いは何ですか? | [バターケーキとパウンドケーキはどちらもバターを豊富に使用した伝統的なケーキですが、その起源... | サッカーは11人でプレーします。 | [バターケーキとパウンドケーキの違いは、材料の比率とレシピにあり、パウンドケーキはより伝統的... | 0.784452 | NaN | 1.0 | 1.0 |
所感
RAGASの評価指標は、コンテキストや生成した回答などの変化によって値が変わります。変化の理由を追跡する上で、各指標だけが変化する場合を知っておくことで、
原因の仮定が立てやすくなると思います。
RAGASを使って、より精度の高いRAGの開発に繋げていきたいですね。
RAGASは生成モデルに評価を指示するプロンプトに工夫がたくさんあるので、ご興味がある方は一度見てみると面白いと思います。
参考文献
https://qiita.com/s3kzk/items/44b8780c656b4f747403
https://github.com/explodinggradients/ragas/tree/main
https://qiita.com/K5K/items/5da52e99861483cae876
https://qiita.com/s-itou/items/2911d69af2e058a46c72