初めに
この問題は、SQLパズル #3 忙しい麻酔医 を参考にしています
このクイズは時間が入っているデータから重複する時間を取出す問題です
各仕事ID(proc_id)がいくつの仕事と時間が重なっているか?を抽出します
イメージしやすい様に図を用いて解説します。
お手元にSQLパズルの本が有れば違う図もあるのでイメージしやすいです
重なる時間の考え方
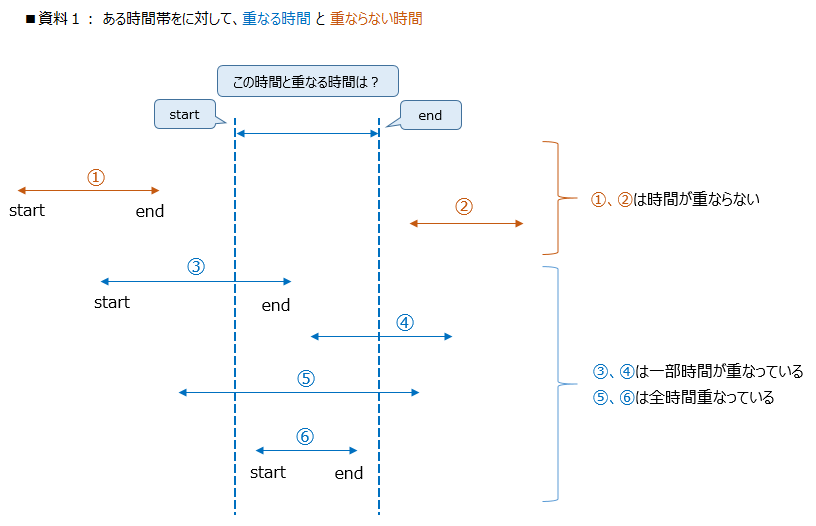
[1] 資料1 にある青い点線の部分を重なる時間とします
[2] この点線部分と重なる条件が ③、④、⑤、⑥ 、重ならない条件が ①、② となります
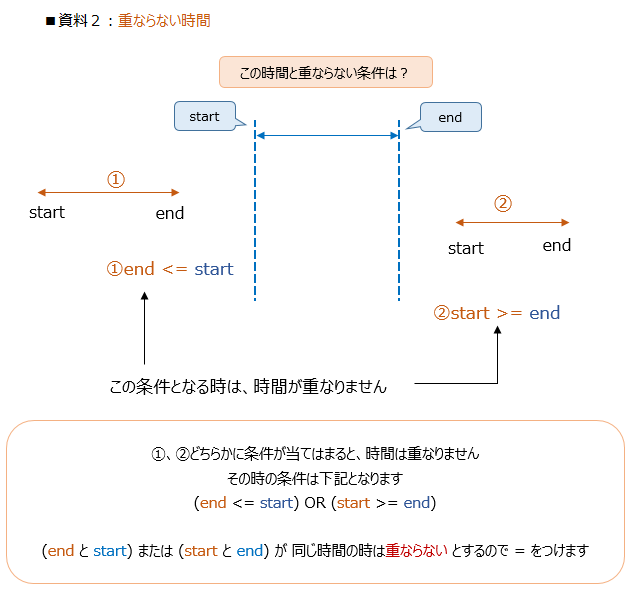
[3] 資料1から重ならない時間帯だけを取出します ⇒ 資料2
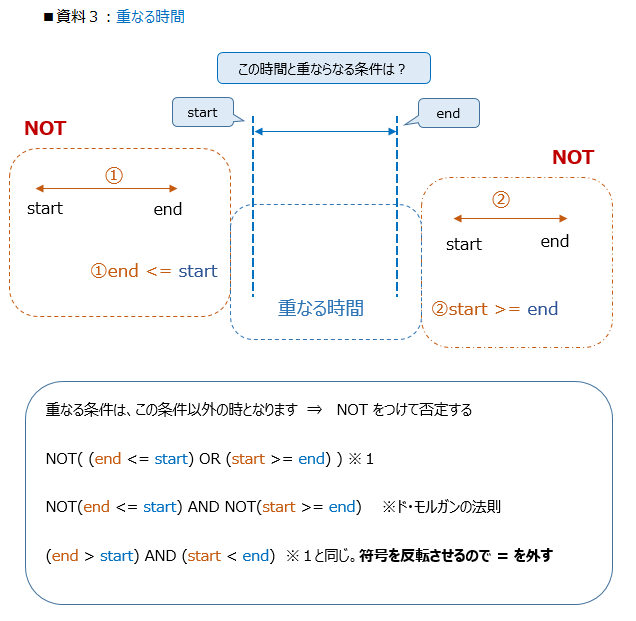
[4] この条件の逆、つまり否定すると 重なる条件となります ⇒ 資料3
重なる時間のイメージ図
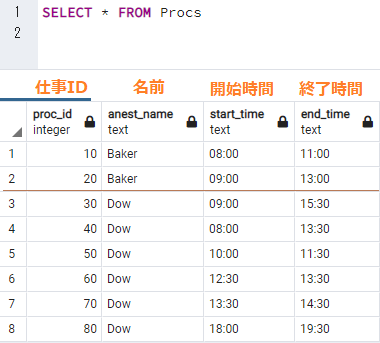
Proc テーブルデータ
CREATE TABLE Procs(
proc_id integer,
anest_name text,
start_time text,
end_time text);
INSERT INTO Procs VALUES(10,'Baker','08:00','11:00');
INSERT INTO Procs VALUES(20,'Baker','09:00','13:00');
INSERT INTO Procs VALUES(30,'Dow','09:00','15:30');
INSERT INTO Procs VALUES(40,'Dow','08:00','13:30');
INSERT INTO Procs VALUES(50,'Dow','10:00','11:30');
INSERT INTO Procs VALUES(60,'Dow','12:30','13:30');
INSERT INTO Procs VALUES(70,'Dow','13:30','14:30');
INSERT INTO Procs VALUES(80,'Dow','18:00','19:30');
Baker さんと Dow さんの二人の医者がいます。
お仕事の開始時間が違うので時間帯によってお仕事が重なる時間が出てきます。
重なる時間をSQLで取り出します
CROSS JOIN | データ同士の掛け算
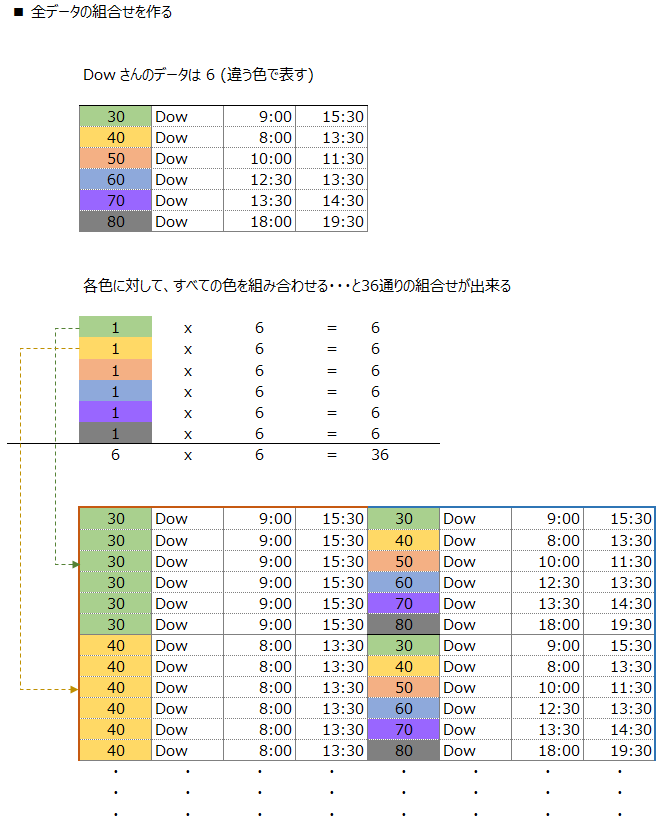
全データの組合せを考える時に、CROSS JOIN を用います。
データ同士の掛け算となるのでデータ量が多い場合は気を付ける必要が有ります
頻繁に使うことは無いかと思いますが、必要となる場合は有ります。
下記がそのイメージです
集計対象となる元データの作成
Bakerさんは proc_idが 10,20 2つのお仕事があるので全組合せは 2 x 2 = 4件
Dowさんは proc_idが 30,40,50,60,70,80 6件のお仕事が有るので 6 x 6 = 36件
CROSS JOIN を使って全データの組合せを作ります
P1 に対して P2を cross join しています
組合せのイメージ図を見ると
左側のproc_id(1色)に対して、右側には全proc_id(6色)が結合されています
右側の時間(P2) が 左側の時間(P1) と重なるか?をWHERE句で判定しています
画像左側に全組合せのデータ
画像右側に重なる時間の条件を WHERE句に追加した結果のデータを示します
⇒右側が、重なり合う時間を取出す元データになります

CTEを使って、VIEW の様なsqlを作成します
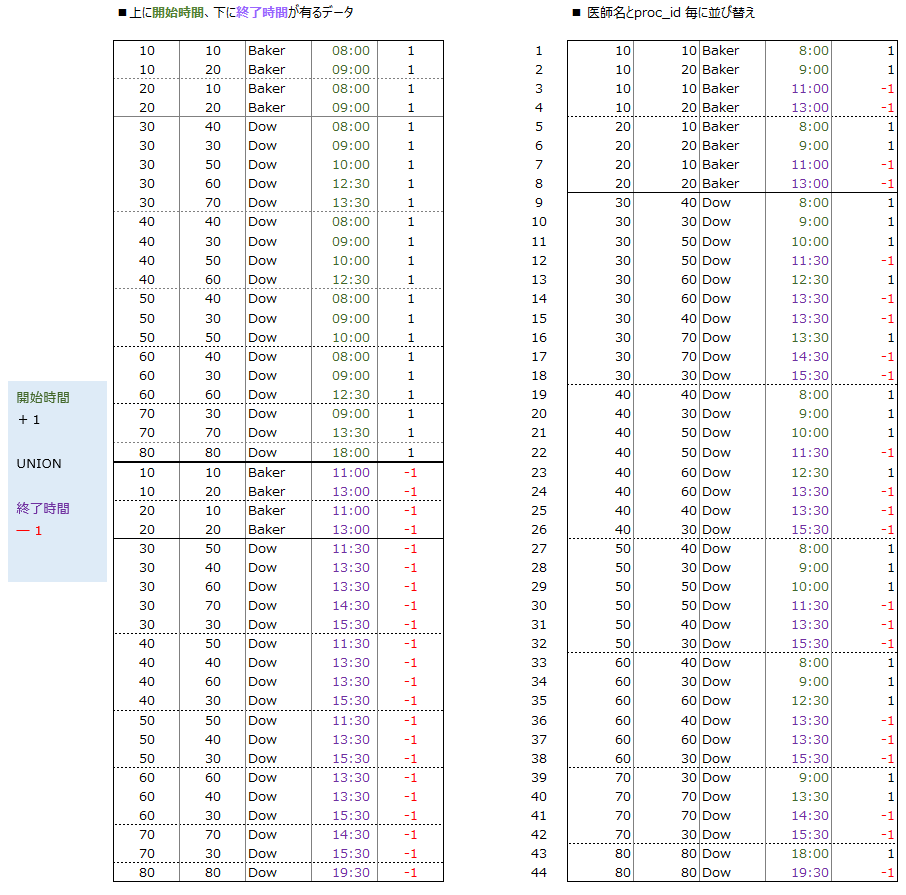
開始時間のデータに対して +1 のデータを追加
終了時間のデータに対して -1 のデータを追加
それぞれを UNION で縦につなげる
⇒(4+18) + (4+18) = 44件のデータが出来上がる
ここで、注意してみて頂きたいのですが・・・
UNION の上の部分は P2.start_time を t1 と命名しています
UNION の下の部分は P2.end_time を t1 と命名しています
つまり
P2の開始時間(start_time) と P2の終了時間(end_time) が横に並んでいるデータを
縦持ちのデータとして加工しています
その為、データ量も倍になっています
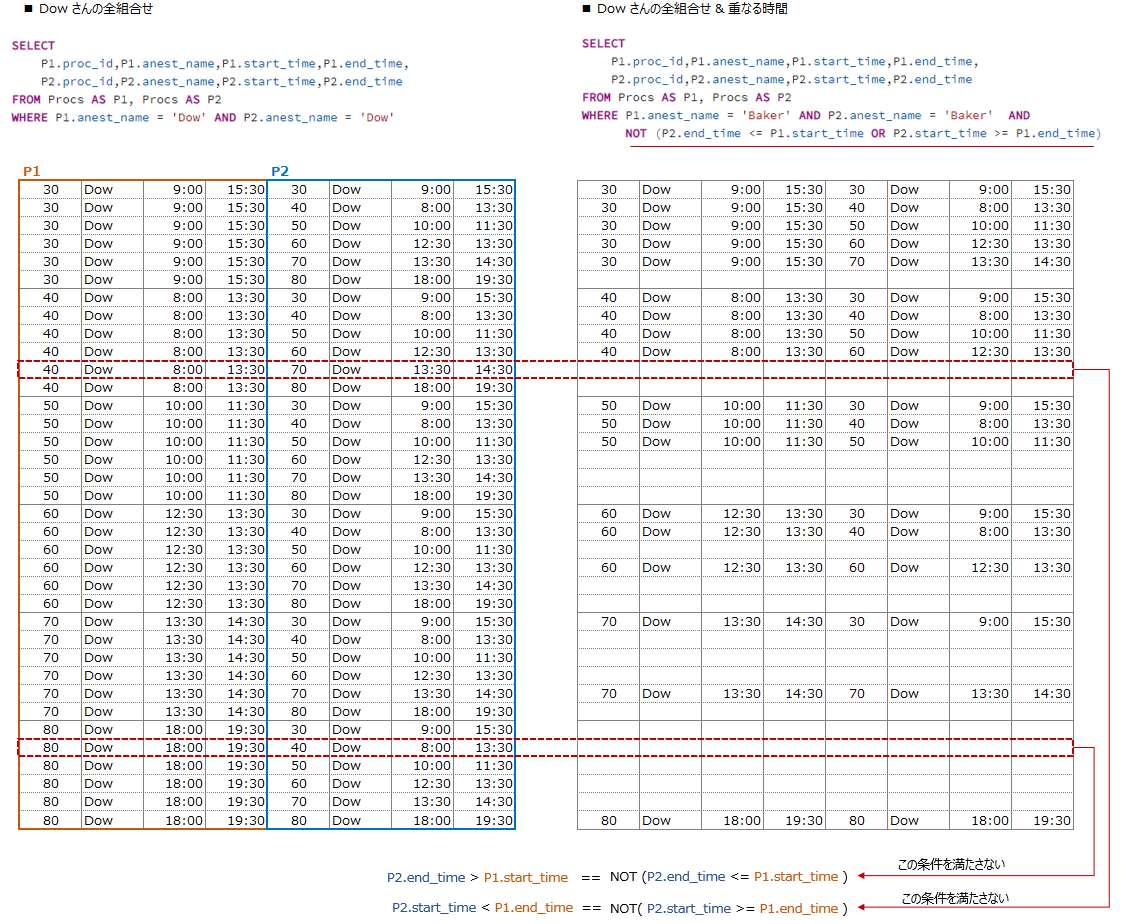
WITH Events AS
(
SELECT P1.proc_id AS a1, P2.proc_id AS a2, P1.anest_name
, P2.start_time AS t1 -------------------------------------- 開始時間
, +1 AS event_type ----------------------------------------- プラス 1
FROM Procs AS P1, Procs AS P2
WHERE P1.anest_name = P2.anest_name AND -- 同じ名前同士を結合
NOT (P2.end_time <= P1.start_time OR P2.start_time >= P1.end_time) --重なる条件
UNION
SELECT P1.proc_id AS a1, P2.proc_id AS a2, P1.anest_name
, P2.end_time AS t1 ---------------------------------------- 終了時間
, -1 AS event_type ---------------------------------------- マイナス 1
FROM Procs AS P1, Procs AS P2
WHERE P1.anest_name = P2.anest_name AND -- 同じ名前同士を結合
NOT (P2.end_time <= P1.start_time OR P2.start_time >= P1.end_time) --重なる条件
)
SELECT * FROM Events
CTEで作成した Events をそのまま出力すると 左側の様なデータが表示されます
⇒上半分が開始時間のデータ、下半分が終了時間のデータ
右側のデータは、名前とproc_id, t1(時間)でソートしています
重なる時間を合計する
WITH Events AS (
-- 割愛
)
SELECT E1.anest_name,E1.a1 AS prod_id, E1.t1 AS time,
(SELECT SUM(E2.event_type) FROM Events AS E2 WHERE E2.a1 = E1.a1 AND E2.t1 < E1.t1) AS goukei,
(SELECT array_agg(E2.t1) FROM Events AS E2 WHERE E2.a1 = E1.a1 AND E2.t1 < E1.t1) AS jikan
FROM Events AS E1
SELECT文の中に jikan というカラムがあります
この抽出条件は WHERE E2.a1 = E1.at AND E2.t1 < E1.t1 です
⇒この意味は
1:同じ名前のデータを結合する
2:E1データが持っているE1.t1(開始) より 小さな E2.t1(開始)を抽出する
ここは注意が必要です
元となるデータを作成する時に CROSS JOIN を使用しています。その為、全組合せの中には、自分と同じ時間も含まれます。
重なり合う時間を求める時に、自分自身と同じ時間は除く必要が有ります
⇒8:00開始と8:00開始の組合せは必要ありません
ここで求めたいのは
各proc_idが重なり合う数なので SUM(E2.event_type) をカウントすればいいのですが
下記イメージ図でこのクイズの全体が想像出来れば幸いです
上記で説明したように
・開始時間と終了時間を持つデータを結合(UNION)し、仕事ID毎にソート
・E1の開始時間に対して、重なる時間を E2が持っています。
・データの各行が持っている E1.t1(時間)より、小さなE2.t1(時間)を取出し
・array_agg(E2.t1) がその時間
・この時間が持っている +1 や -1 (E2.event_type)を合計 SUM(E2.event_type)

回答:重なり合う時間の数
このクイズの回答は下記となります(各proc_id に対する、最大の掛持ちの個数)
WITH Events AS (
SELECT
P1.proc_id AS a1,
P2.proc_id AS a2,
P1.anest_name,
P2.start_time AS t1,
+1 AS event_type
FROM Procs AS P1, Procs AS P2
WHERE
P1.anest_name = P2.anest_name AND
NOT (P2.end_time <= P1.start_time OR P2.start_time >= P1.end_time)
UNION
SELECT
P1.proc_id AS a1,
P2.proc_id AS a2,
P1.anest_name,
P2.end_time AS t1,
-1 AS event_type
FROM Procs AS P1, Procs AS P2
WHERE
P1.anest_name = P2.anest_name AND
NOT (P2.end_time <= P1.start_time OR P2.start_time >= P1.end_time)
)
SELECT b1.proc_id,MAX(cnt) AS cnt
FROM
(
SELECT E1.a1 AS proc_id, E1.t1 AS event_time,
(SELECT SUM(E2.event_type) FROM Events AS E2
WHERE E2.a1 = E1.a1 AND E2.t1 < E1.t1) AS cnt
FROM Events AS E1
) AS b1
GROUP BY b1.proc_id --仕事ID毎に重なり合う時間を求めるので proc_id が集約
| proc_id | cnt |
|---|---|
| 10 | 2 |
| 20 | 2 |
| 30 | 3 |
| 40 | 3 |
| 50 | 3 |
| 60 | 3 |
| 70 | 2 |
| 80 | 1 |