初めに
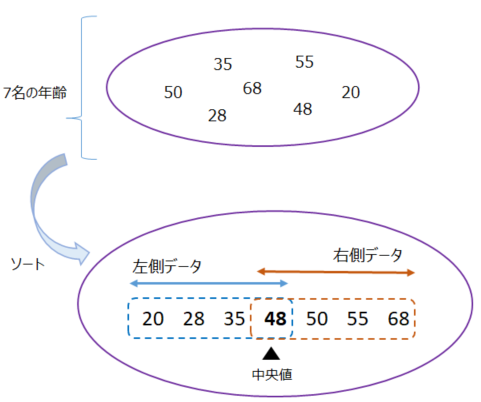
年齢の違う7人がいます
このグループ内での真ん中の年齢を
SQLで求めてみます
真ん中の年齢・・(o゚Д゚o)?
【取出し方】
ざっくりですが・・・
①元になるデータを作る
②左側のデータを作る
③右側のデータを作る
④重複する場所を探す
⇨ 重なる部分が中央値となる
ソートしたデータを見ると
イメージしやすいかと思います
▼ 中央値と取出しイメージ
PostgreSQLで動作確認してます
Table & Data
CREATE TABLE ages (
id CHAR(3) PRIMARY KEY -- ID
,age INTEGER -- 年齢
);
INSERT INTO ages VALUES('A01', 20);
INSERT INTO ages VALUES('A02', 28);
INSERT INTO ages VALUES('B04', 35);
INSERT INTO ages VALUES('B07', 48);
INSERT INTO ages VALUES('C03', 50);
INSERT INTO ages VALUES('C06', 55);
INSERT INTO ages VALUES('C08', 68);
▼ 出力
| id | age |
|---|---|
| A01 | 20 |
| A02 | 28 |
| B04 | 35 |
| B07 | 48 |
| C03 | 50 |
| C06 | 55 |
| C08 | 68 |
元データを作る
-- ages テーブルの自己結合
SELECT A1.*, A2.*
FROM ages A1, ages A2
ages テーブル同士をCROSS JOINしてます
⇒ 全部の組合せを作る
⇒ ages テーブルは7行
⇒ 7 x 7 = 49(行)のデータができる
どの様に結合されるのかは
下記図を確認ください
▼ 出力(画像左)

元データを加工する
SELECT A1.age, ARRAY_AGG(A2.age)
FROM ages A1, ages A2
GROUP BY A1.age
▼ 出力
| A1.age | ARRAY_AGG(A2.age) |
|---|---|
| 20 | { 20,28,35,48,50,55,68 } |
| 28 | { 20,28,35,48,50,55,68 } |
| 35 | { 20,28,35,48,50,55,68 } |
| 48 | { 20,28,35,48,50,55,68 } |
| 50 | { 20,28,35,48,50,55,68 } |
| 55 | { 20,28,35,48,50,55,68 } |
| 68 | { 20,28,35,48,50,55,68 } |
GROUP BY A1.age で何をしてる?
id = A01 を見る
⓵ A1.age(20)が6行あるので1行にする
⇒ ユニークになる
⓶ A2.ageが6行あるが数字が違う
⇒ 20,28,35,48,50,55,68
⇒ これを1行にまとめる
⇒ ARRAY_AGG()で配列にしてる
重要なのは⓶のデータです
実際にはこの記述は必要ないのですが
SQLの処理を可視化する為
確認用に追加してます
▼ ARRAY_AGG()のイメージ図

『左側データ』を作る準備
SELECT
A1.age
,ARRAY_AGG(A2.age) AS ary
-- 『左側データ』は不等号が逆になる
,ARRAY_AGG(CASE WHEN A2.age >= A1.age THEN 1 ELSE 0 END) AS flg_1
,SUM(CASE WHEN A2.age >= A1.age THEN 1 ELSE 0 END) AS cnt_1
FROM ages A1, ages A2
GROUP BY A1.age
GROUP BYで1行に集約してるので
A1.ageとA2.age(20,28,35,48,50,55,68)
を比較することができます
⇒ 比較結果を flg_1
⇒ 比較結果のSUMを cnt_1
とします
▼ 出力
| A1.age | ARRAY_AGG(A2.age) | flg_1 | cnt_1 |
|---|---|---|---|
| 20 | { 20,28,35,48,50,55,68 } | { 1, 1, 1, 1, 1, 1, 1 } | 7 |
| 28 | { 20,28,35,48,50,55,68 } | { 0, 1, 1, 1, 1, 1, 1 } | 6 |
| 35 | { 20,28,35,48,50,55,68 } | { 0, 0, 1, 1, 1, 1, 1 } | 5 |
| 48 | { 20,28,35,48,50,55,68 } | { 0, 0, 0, 1, 1, 1, 1 } | 4 |
| 50 | { 20,28,35,48,50,55,68 } | { 0, 0, 0, 0, 1, 1, 1 } | 3 |
| 55 | { 20,28,35,48,50,55,68 } | { 0, 0, 0, 0, 0, 1, 1 } | 2 |
| 68 | { 20,28,35,48,50,55,68 } | { 0, 0, 0, 0, 0, 0, 1 } | 1 |

比較の挙動については・・
もう少し詳しくみてみます (´◉ω◉`)
A1.ageとA2.ageを比較する
【A1.age(35)で確認】
◾️CASE文
CASE WHEN A2.age >= A1.age THEN 1 ELSE 0 END
⇒ {20,28,35,48,50,55,68} >= 35
⇒ A2.ageが35より大きい or 同じ
◾️ARRAY_AGG(CASE WHEN ・・・)
⇒ CASE文が TRUE の時 1
⇒ CASE文が FALSE の時 0
⇒ 戻り値を1行にまとめる
⇒ { 0, 0, 1, 1, 1, 1, 1 } (配列)
⇒ flg_1
◾️SUM(CASE WHEN ・・・)
⇒ ( 0 + 0 + 1 + 1 + 1 + 1 + 1 )
⇒ 合計する
⇒ 5
⇒ cnt_1
▼ A1.age(35)とA2.ageを比較

cnt_1はデータの位置
cnt_1 は CASE文の比較結果(1 or 0)を
全て足し算(SUM)した数字です
この数字が
中央値(重なる部分)を探すKeyになります
〜〜 (・_・?)
ここで
A2.age(20,28,35,48,50,55,68)
を 集合Aと呼びます
◾️ A1.age = 20 の時
20と集合Aを比較
CASE文が全てTRUEになる
⇒ 1の数が7個
言い換えると
20より大きい or 同じ数字が7個ある
20は一番小さな数字なので・・
位置は一番左
〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
◾️ A1.age = 48 の時
48と集合Aを比較
CASE文で48,50,55,68がTRUEになる
⇒ 1の数が4個
言い換えると
48より大きい or 同じ数字が4個ある
全7個の内4つなので・・
48の位置は真ん中
〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
◾️ A1.age = 68 の時
68と集合Aを比較
CASE文で68がTRUEになる
⇒ 1の数が1個
言い換えると
68より大きい or 同じ数字が1個しかない
68は一番大きな数字なので・・
位置は一番右
▼ cnt_1(数字)はA1.ageの位置を表してる

『左側データ』を取出す
SELECT
A1.age
-- ,ARRAY_AGG(A2.age) AS ary
-- ,ARRAY_AGG(CASE WHEN A2.age >= A1.age THEN 1 ELSE 0 END) AS flg_1
,SUM(CASE WHEN A2.age >= A1.age THEN 1 ELSE 0 END) AS cnt_1
,COUNT(A1.age)/2.0 AS middle
FROM ages A1, ages A2
GROUP BY
A1.age
HAVING
SUM(CASE WHEN A2.age >= A1.age THEN 1 ELSE 0 END) >= COUNT(A1.age)/2.0
▼ 出力
| A1.age | cnt_1 | middle |
|---|---|---|
| 20 | 7 | 3.5 |
| 28 | 6 | 3.5 |
| 35 | 5 | 3.5 |
| 48 | 4 | 3.5 |
HAVINGで『左側データ』を取る
⇒ 中間点より大きい数字
中間点・・とは?
数字が7個並んでます
cnt_1 を使って、場所(1~7)が決まってます
⇒ 7の中間は3.5
⇒ COUNT(A1.age)/2.0
⇒ ここでは、3.5を中間点と呼びます
cnt_1が中間点(3.5)より大きな数字を取出す
⇒ 『左側データ』が残ります
20 28 35 48 50 55 68
▼ 『左側データ』を取出すイメージ

次に、同じ様にして
『右側データ』を取出します
『右側データ』を作る準備
SELECT
A1.age
,ARRAY_AGG(A2.age) AS ary
-- 『右側データ』と不等号の向きが逆
,ARRAY_AGG(CASE WHEN A2.age <= A1.age THEN 1 ELSE 0 END) AS flg_2
,SUM(CASE WHEN A2.age <= A1.age THEN 1 ELSE 0 END) AS cnt_2
FROM ages A1, ages A2
GROUP BY A1.age
▼ 出力(画像上側)

『右側データ』の取出し方は
左側とほぼ同じですが・・・
不等号の向きが逆になります
他は同じなので、詳細は割愛します
A1.ageとA2.ageを比較した結果(flg_2)の
1となる場所が対照になってます
⇒ 不等号の向きを変えたので
何となく理解はできます(。-_-。)
再度、A1.ageとA2.ageを比較する
【A1.age(35)で確認】
CASE文の比較ですが・・
『左側データ』の時と同じです
不等号の向きが違うので
TURE or FALSEの結果が違ってきます
▼ 出力

cnt_2はデータの位置
『左側データ』と同じように
cnt_2 を使って7個の数字の位置を決めます
⇒ cnt_2 は比較結果の合計です
cnt_2は、中間点(3.5)より大きな数字を
取得する為に使用します
▼ 『右側データ』を取出す準備

『右側データ』を取出す
SELECT
A1.age
-- ,ARRAY_AGG(A2.age) AS ary
-- ,ARRAY_AGG(CASE WHEN A2.age <= A1.age THEN 1 ELSE 0 END) AS flg_2
,SUM(CASE WHEN A2.age <= A1.age THEN 1 ELSE 0 END) AS cnt_2
,COUNT(A1.age)/2.0 AS middle
FROM ages A1, ages A2
GROUP BY
A1.age
HAVING
SUM(CASE WHEN A2.age <= A1.age THEN 1 ELSE 0 END) >= COUNT(A1.age)/2.0
▼ 出力
| A1.age | cnt_2 | middle |
|---|---|---|
| 48 | 4 | 3.5 |
| 50 | 5 | 3.5 |
| 55 | 6 | 3.5 |
| 68 | 7 | 3.5 |
HAVINGで『右側データ』を取る
条件を追記してます
⇒ HAVING cnt_2 >= 3.5
中間点(3.5)より大きな数字を取出します
⇒ 『右側データ』が残ります
20 28 35 48 50 55 68
▼『右側データ』を取出すイメージ

ようやく終わりが見えました (´д`;)
最後に・・
『左側データ』と『右側データ』の共通部分を
取出します
回答SQL
SELECT A1.age
FROM ages A1, ages A2
GROUP BY A1.age
HAVING
-- 『左側データ』取出し
SUM(CASE WHEN A2.age >= A1.age THEN 1 ELSE 0 END) >= COUNT(A1.age)/2.0
AND
-- 『右側データ』取出し
SUM(CASE WHEN A2.age <= A1.age THEN 1 ELSE 0 END) >= COUNT(A1.age)/2.0
▼ 出力
| A1.age |
|---|
| 48 |
ここで重要なのは
『左側データ』『右側データ』の取得条件に
=がついている事です
↓
cnt_1 >= 中間点 (3.5)
cnt_2 <= 中間点 (3.5)
=がついているので、重複が発生します
▼ 重なる場所

【注意点】
このクエリはデータの数が奇数の場合に
動作しますが、偶数の場合は少し違ってきます
Table & Data | 偶数データ
DELETE FROM ages;
INSERT INTO ages VALUES('A01', 20);
INSERT INTO ages VALUES('A02', 28);
INSERT INTO ages VALUES('B04', 35);
INSERT INTO ages VALUES('B07', 48);
INSERT INTO ages VALUES('C03', 50);
INSERT INTO ages VALUES('C06', 55);
-- INSERT INTO ages VALUES('C08', 68);
データを1行削除して全部で6行に変更
回答SQLを実行
SELECT
A1.age
,COUNT(A1.age)/2.0 AS middle -- 中間点
FROM ages A1, ages A2
GROUP BY A1.age
HAVING
-- 『左側データ』取出し
SUM(CASE WHEN A2.age >= A1.age THEN 1 ELSE 0 END) >= COUNT(A1.age)/2.0
AND
-- 『右側データ』取出し
SUM(CASE WHEN A2.age <= A1.age THEN 1 ELSE 0 END) >= COUNT(A1.age)/2.0
▼ 出力
| A1.age | middle |
|---|---|
| 35 | 3.0 |
| 48 | 3.0 |
中間点を追記して実行しました
出力が2行になりました
⇒ 下記イメージ図をご確認ください
中間点(3.0)より大きい『左側データ』『右側データ』を
HAVINGで取出すと、重複が2箇所となります
その為、中央値は(35+48)/2 ですね
⇒ 平均値
▼ 重複が2箇所

回答SQL 修正
SELECT AVG(b1.age) AS age
FROM (
SELECT A1.age
FROM ages A1, ages A2
GROUP BY A1.age
HAVING
-- 『左側データ』取出し
SUM(CASE WHEN A2.age >= A1.age THEN 1 ELSE 0 END) >= COUNT(A1.age)/2.0
AND
-- 『右側データ』取出し
SUM(CASE WHEN A2.age <= A1.age THEN 1 ELSE 0 END) >= COUNT(A1.age)/2.0
) AS b1
▼ 出力
| A1.age |
|---|
| 41.5 |
回答SQLをサブクエリにして
ここから平均値を取出すように変更しました
これなら、偶数、奇数の両方で
中央値が取れます
以上となります ヾ( ˆoˆ )/