初めに
この問題は、SQLパズル #3 忙しい麻酔医 を参考にしています
このクイズは時間が入っているデータから重複する時間を取出す問題です
各仕事ID(proc_id)がいくつの仕事と時間が重なっているか?を抽出します
SQLパズル #3(その1) と重なる時間の取出し方が違います。
まずはここから解説してみたいと思います
最終的な重なり合う時間は同じとなります
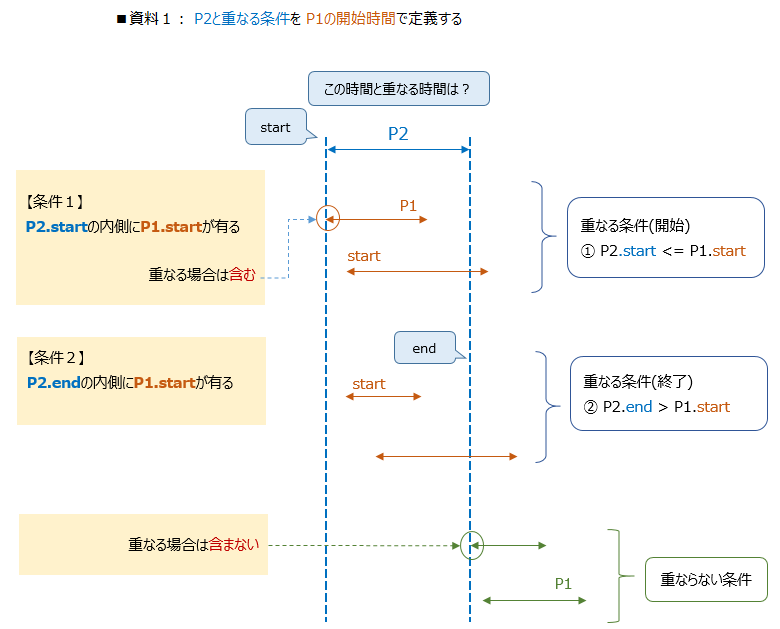
重なる時間の考え方
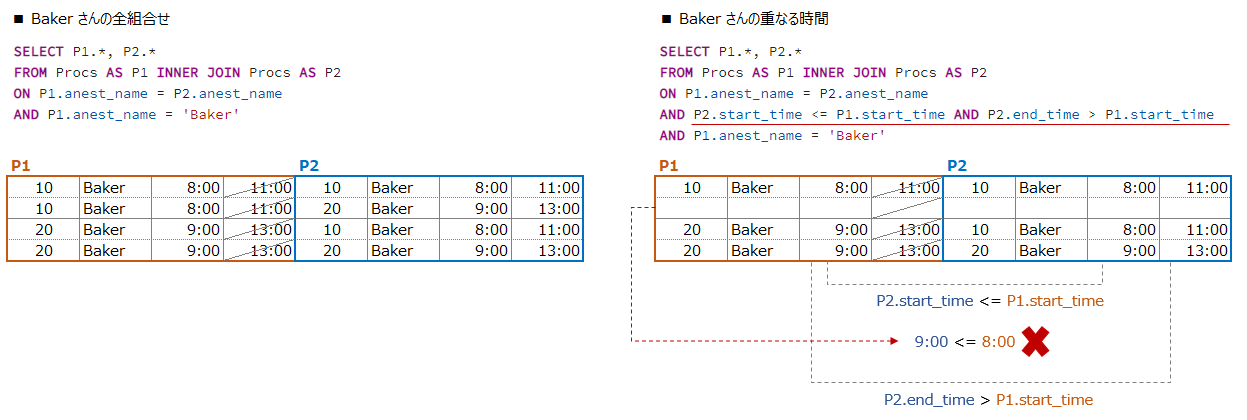
[1] 資料1 にある青い点線の部分を重なる時間とします
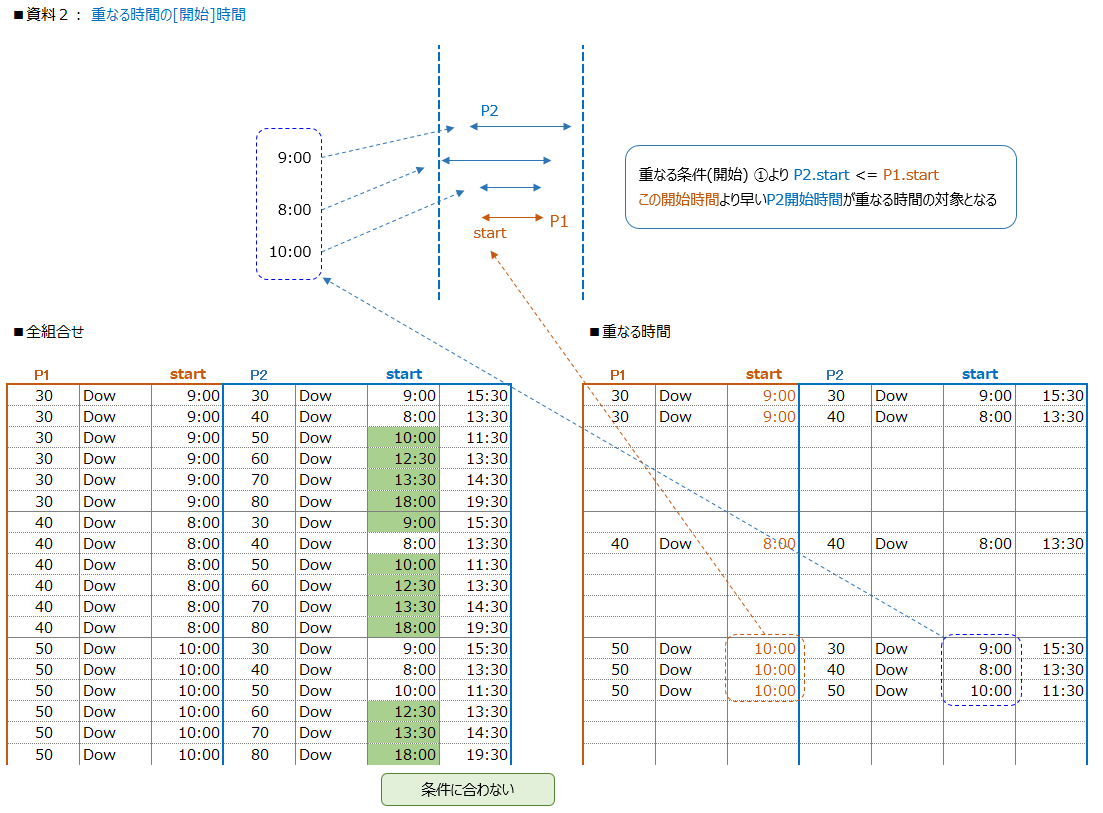
[2] 資料2 開始時間と重なる時間の開始時間を見ます
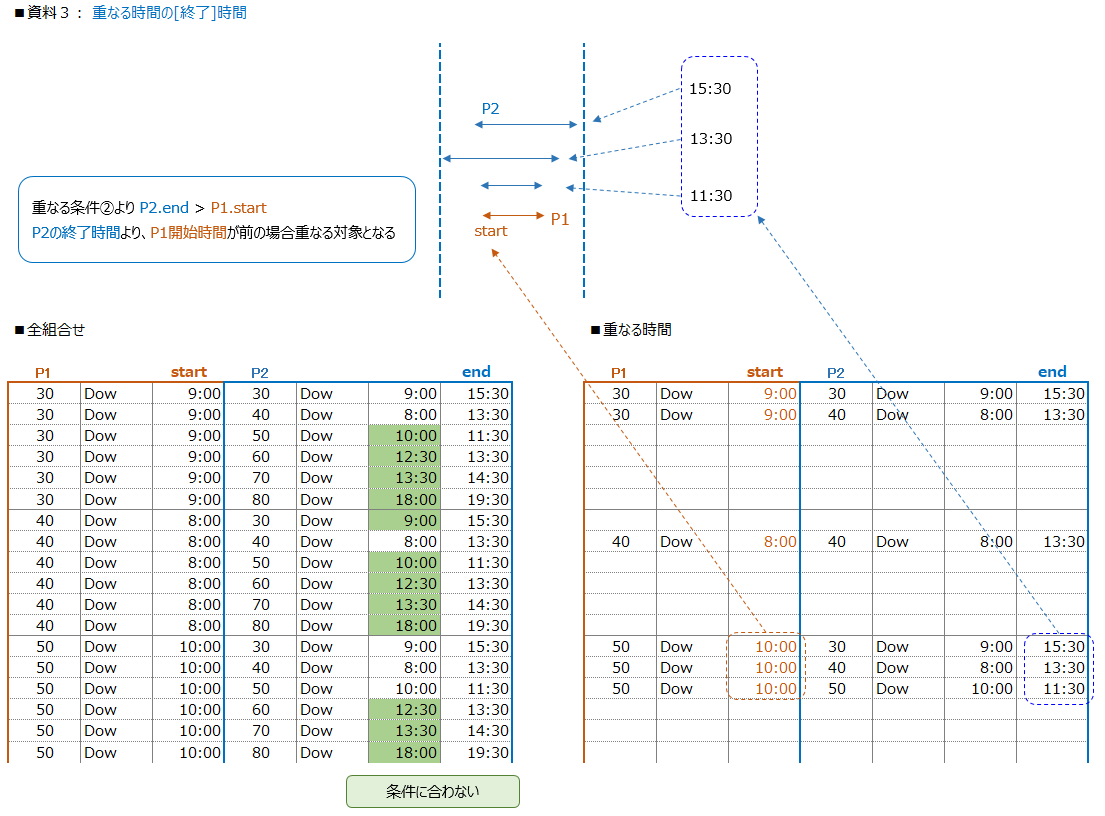
[3] 資料3 開始時間と重なる時間の終了時間を見ます
『その1』での重なる条件と大きく違う所は、重なる条件を開始時間だけ見てます
全組合せを作成し、開始時間をP1で保持します
P2側に、全組合せの開始時間と終了時間を保持します
P1の開始時間が、P2の開始時間と終了時間の中に入っているか?を判定します
重なる時間のイメージ図
P2を重なる時間とし、P1の開始時間がP2の内側に入っているか?で判定しています
重なる時間の判定ですが
資料1、資料2の両方の条件に合う時間P2が、重なる時間となる
Proc テーブルデータ
CREATE TABLE Procs(
proc_id integer,
anest_name text,
start_time text,
end_time text);
INSERT INTO Procs VALUES(10,'Baker','08:00','11:00');
INSERT INTO Procs VALUES(20,'Baker','09:00','13:00');
INSERT INTO Procs VALUES(30,'Dow','09:00','15:30');
INSERT INTO Procs VALUES(40,'Dow','08:00','13:30');
INSERT INTO Procs VALUES(50,'Dow','10:00','11:30');
INSERT INTO Procs VALUES(60,'Dow','12:30','13:30');
INSERT INTO Procs VALUES(70,'Dow','13:30','14:30');
INSERT INTO Procs VALUES(80,'Dow','18:00','19:30');
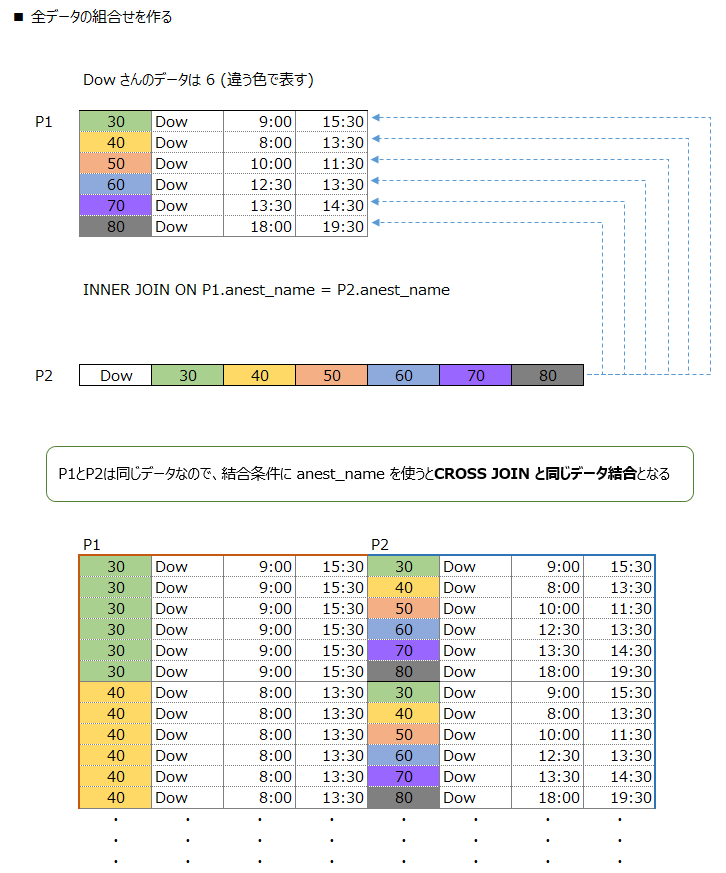
INNER JOIN でデータ結合
『その1』では CROSS JOIN を使いましたが、『その2』ではINNER JOINを使用しています
結果的には CROSS JOIN と同じ全データの組合せが作成されます
集計対象となる元データの作成(1回目)
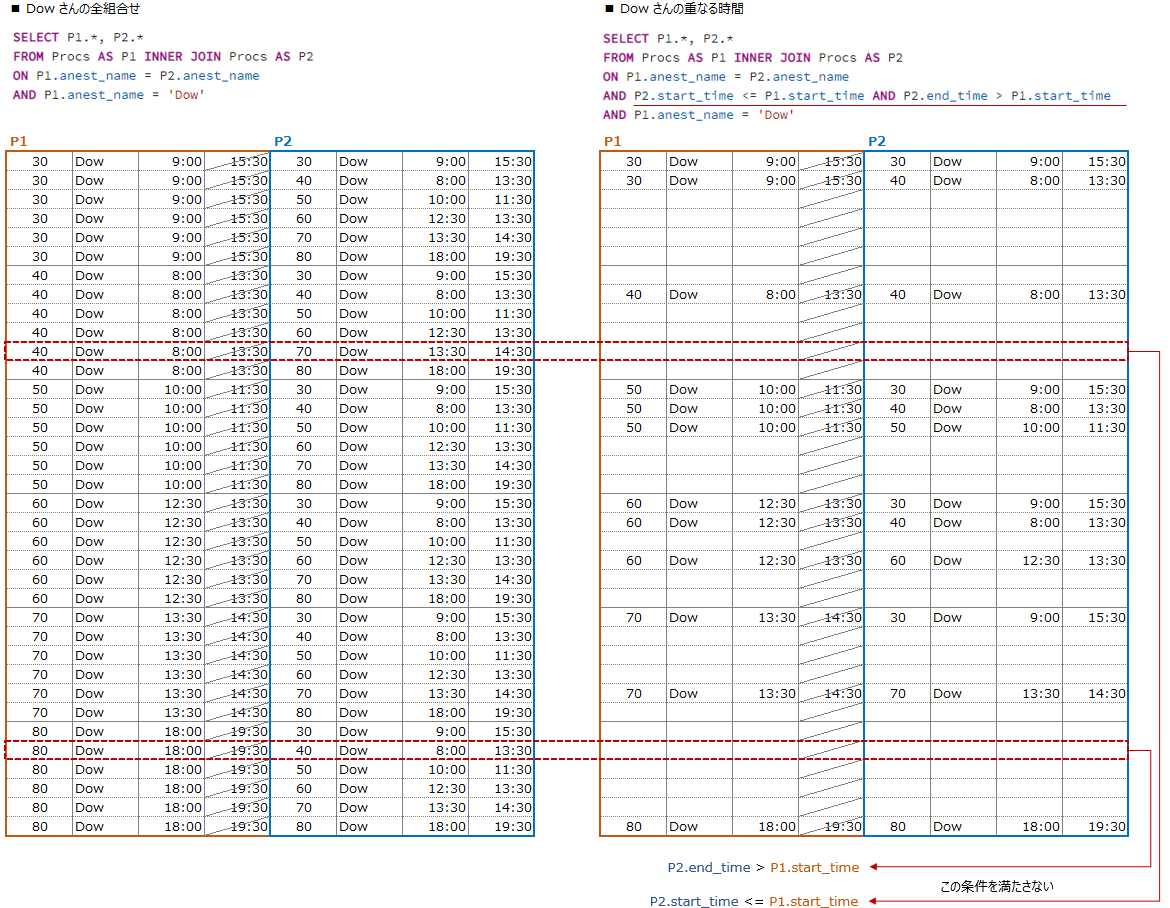
Bakerさんは proc_idが 10,20 2つのお仕事があるので全組合せは 2 x 2 = 4件
Dowさんは proc_idが 30,40,50,60,70,80 6件のお仕事が有るので 6 x 6 = 36件
INNER JOIN を使って全データの組合せを作ります
『その1』と違い、重なる条件が違うので抽出されるデータには少し違いが有ります
最終的な結果は同じになるのですが・・・
重なる時間
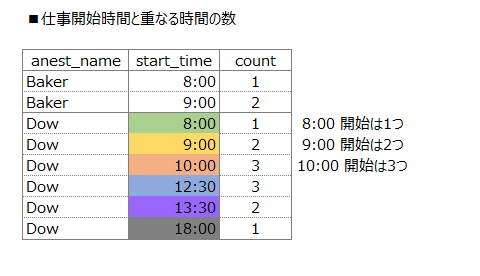
上記で、重なる時間が取出せたので 個人毎にP1の開始時間で集約します
P1.start_time に対して、P2の時間がどれだけ重なっているか?カウントします
-- 仕事開始時間と重なる時間の数
SELECT P1.anest_name, P1.start_time, COUNT(*)
FROM Procs AS P1 INNER JOIN Procs AS P2
ON P1.anest_name = P2.anest_name
AND P2.start_time <= P1.start_time AND P2.end_time > P1.start_time
GROUP BY P1.anest_name, P1.start_time
集計対象となる元データの作成(2回目)
上記で取り出した、各仕事開始時間に対する重なる時間の数のデータに対して
元tableデータである Procs を結合させます
その後、P1開始時間が重なる時間を全組合せから取得します
-- 重なる開始時間に対して、再度開始時間と終了時間の全組合せを作る
SELECT Con.*,P3.*
FROM
(
SELECT P1.anest_name, P1.start_time, COUNT(*)
FROM Procs AS P1 INNER JOIN Procs AS P2
ON P1.anest_name = P2.anest_name
AND P2.start_time <= P1.start_time AND P2.end_time > P1.start_time
GROUP BY P1.anest_name, P1.start_time
) AS Con(anest_name, start_time, tally)
INNER JOIN Procs AS P3 ON Con.anest_name = P3.anest_name
-- 重なる時間
SELECT Con.*,P3.*
FROM
(
SELECT P1.anest_name, P1.start_time, COUNT(*)
FROM Procs AS P1 INNER JOIN Procs AS P2
ON P1.anest_name = P2.anest_name
AND P2.start_time <= P1.start_time AND P2.end_time > P1.start_time
GROUP BY P1.anest_name, P1.start_time
) AS Con(anest_name, start_time, tally)
INNER JOIN Procs AS P3 ON Con.anest_name = P3.anest_name
AND P3.start_time <= Con.start_time AND P3.end_time > Con.start_time -- 重なる条件
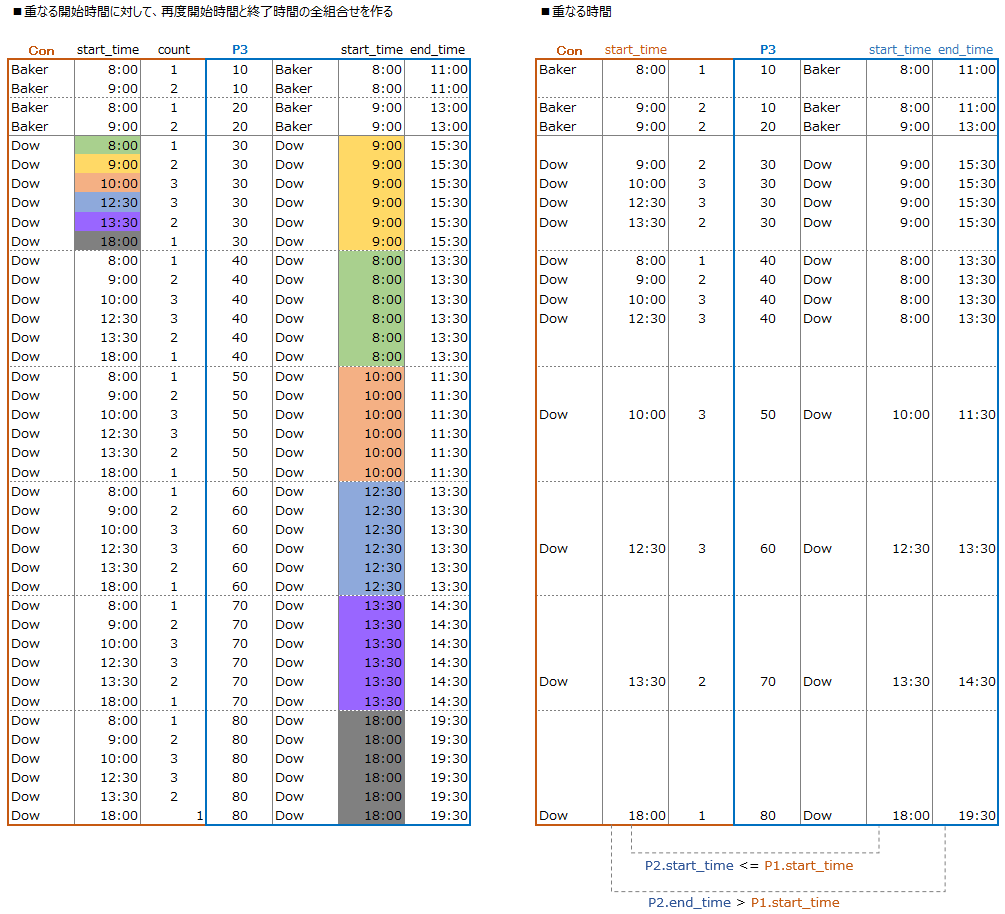
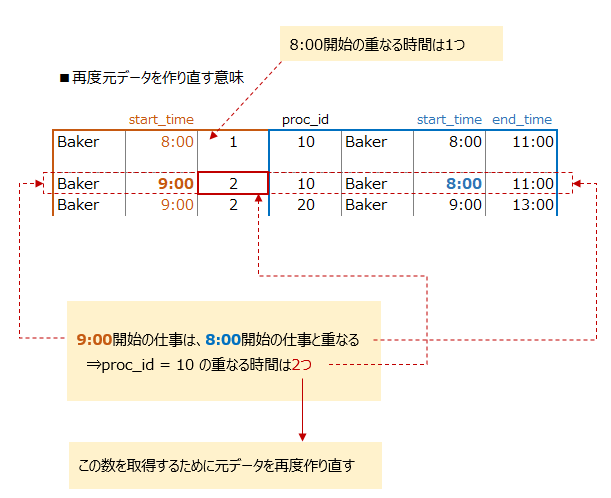
何故、集計元となるデータを2回作るのか?
各開始時間はどれだけの仕事と時間が重なるか?は取得できている・・・が
下記イメージ画像の様に
開始時間が他の仕事(proc_id)と重なっている場合を考慮する必要が有ります
何故なら、このクイズでの課題は
各仕事(proc_id)での重なる時間の最大数を求める為です
回答:重なり合う時間の最大数
このクイズの回答は下記となります(各proc_id に対する、最大の掛持ちの個数)
最後に INNER JOIN した Procsテーブル(P3) の proc_id で集約しているのがポイント
-- 各proc_id に対する、最大の掛持ちの個数
SELECT P3.proc_id, MAX(Con.tally)
FROM
(
SELECT P1.anest_name, P1.start_time, COUNT(*) AS tally
FROM Procs AS P1 INNER JOIN Procs AS P2
ON P1.anest_name = P2.anest_name
AND P2.start_time <= P1.start_time AND P2.end_time > P1.start_time
GROUP BY P1.anest_name, P1.start_time
) AS Con(anest_name, start_time, tally)
INNER JOIN Procs AS P3 ON Con.anest_name = P3.anest_name
AND P3.start_time <= Con.start_time AND P3.end_time > Con.start_time
GROUP BY P3.proc_id -- ここが大事 青色の枠内
| proc_id | max |
|---|---|
| 10 | 2 |
| 20 | 2 |
| 30 | 3 |
| 40 | 3 |
| 50 | 3 |
| 60 | 3 |
| 70 | 2 |
| 80 | 1 |