この記事は、dev.toに公開されているAnthony Morris氏によって書かれた英語記事の日本語訳です。

最新の、特定分野の、あるいはプライベートなデータを用いて生成型AI(Generative AI)のアプリケーションを強化すると、その能力は飛躍的に向上します。この手法は「Retrieval Augmented Generation(RAG)」と呼ばれています。
本記事では、StripeDocs Reader(StripeドキュメンテーションをPineconeでベクトル化するLlamaIndex上のローダー)を使用してPythonスクリプトを構築します。このスクリプトにより、ユーザはOpenAI(この場合はLLM)に対してStripe Docsについての質問を投げると、生成された応答を受け取ることができます。
必要要件
このサンプルでは、OpenAIとPineconeの両方のアカウントとAPIキーが必要です。OpenAIは、質問に基づいて出力を生成するためのLLMを提供します。そしてPineconeは、ベクトルデータベースを提供します。これを使ってLLMプロンプトへ注入する前に、関連するStripeドキュメンテーションを検索することができます。
セットアップ
このプロジェクトではPythonを使用します。PythonはAI開発用に非常に人気のある言語です。
PINECONE_API_KEY=abc_12345
OPENAI_API_KEY=abc_12345
4.次の依存関係を持つrequirements.txtファイルを作成します:
llama-hub==0.0.77
llama-index==0.9.40
pinecone-client==3.0.2
python-dotenv==1.0.1
5.依存関係をインストールします:
pip install -r requirements.txt
ベクトルストアとインデックスの構築
ユーザーの質問に関連するStripe Docsを決定するためには、まずPinecone内でベクトルストアとインデックスを作成する必要があります。第一歩として、Stripeドキュメンテーション全体からEmbedding化したベクトルデータを作成しましょう。後半のステップで、ユーザーの質問に関連するドキュメントを取得するための検索に利用します。
Stripe Docs全体を解析し、それらをEmbedding化するのは決して容易な作業ではありません。しかし、StripeDocsReaderを使用すればこの全プロセスを気にする必要はなくなります。
このローダーはStripeのサイトマップを利用して、Stripeの全ドキュメンテーションを再帰的にロードします。ロードしたデータを処理することで、ドキュメンテーションからのEmbeddingを手軽に行えるようになります。
Pineconeのインデックスを作成するにはかなり時間がかかります。インデックス作成処理を実行する間、コーヒーブレイクを取って待ちましょう。
訳者注: Pineconeの無料で試せるプラン(スターター)を使った場合、40-50分程度かかりました。
1. build.pyファイルを作成し、適切なパッケージと環境変数をロードします。
import os
from pinecone import Pinecone, PodSpec
from llama_index import VectorStoreIndex, download_loader, StorageContext
from llama_index.vector_stores import PineconeVectorStore
from dotenv import load_dotenv
load_dotenv()
PINECONE_API_KEY = os.getenv("PINECONE_API_KEY")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
# APIキーが正確にロードされたことを確認します
if not OPENAI_API_KEY:
raise Exception("OPENAI_API_KEY environment not set")
if not PINECONE_API_KEY:
raise Exception("PINECONE_API_KEY environment not set")
# Open AI APIキーをセットします
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
2. LlamaIndexからStripeDocsReaderローダーをセットアップします。
StripeDocsReader = download_loader("StripeDocsReader")
loader = StripeDocsReader()
# StripeDocsReaderを利用してStripe Docs全体を探索します
documents = loader.load_data()
StripeDocsReaderにfiltersパラメータを渡すことで、コーパスをStripe Docsの一部のみに絞り込むことができます。使用例についてはStripeDocsReaderドキュメンテーションを参照してください。
3. 関連するStripeドキュメンテーションを検索するために使用されるPineconeインデックスを初期化します。
# Pinecone indexを初期化します
# https://docs.llamaindex.ai/en/stable/examples/vector_stores/PineconeIndexDemo.html
pc = Pinecone(api_key=PINECONE_API_KEY)
if "stripe-docs" not in pc.list_indexes().names():
pc.create_index(
name="stripe-docs",
dimension=1536,
metric='euclidean',
spec=PodSpec(
pod_type='starter',
environment='gcp-starter'
)
)
pinecone_index = pc.Index("stripe-docs")
4. 自身のPineconeインデックスとベクトルストアを作成し、Stripe Docsを追加します。
# ベクトルストアとインデックスを作成します
# https://docs.llamaindex.ai/en/stable/understanding/indexing/indexing.html
vector_store = PineconeVectorStore(pinecone_index=pinecone_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, show_progress=True, storage_context=storage_context)
5. buildスクリプトを実行します:
python build.py
StripeドキュメンテーションとRAGの活用
Pinecone上にあるベクトルストアに対して、Stripeのドキュメンテーションからインデックスを作成したら、次にインデックスへクエリを投げる処理を作ります。LlamaIndexを使ってユーザーの質問に答える際、ライブラリは自動的に関連するStripe Docsを検索・処理し、それらをChatGPTへのプロンプトとともに送信します。
1. query.pyファイルを作成し、適切なパッケージと環境変数をロードします。
import os
import pinecone
from llama_index import VectorStoreIndex, download_loader, StorageContext
from llama_index.vector_stores import PineconeVectorStore
from dotenv import load_dotenv
load_dotenv()
PINECONE_API_KEY = os.getenv("PINECONE_API_KEY")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
# APIキーが正確にロードされたことを確認します
if not OPENAI_API_KEY:
raise Exception("OPENAI_API_KEY environment not set")
if not PINECONE_API_KEY:
raise Exception("PINECONE_API_KEY environment not set")
# Open APIキーをセットします
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
2. 作成済みのPineconeインデックスを初期化します。
# Pinecone indexを初期化します
pc = Pinecone(api_key=PINECONE_API_KEY)
pinecone_index = pc.Index("stripe-docs")
3. Pineconeのベクトルストアからクエリエンジンを初期化します。
# ベクトルストアとインデックスを作成します
vector_store = PineconeVectorStore(pinecone_index=pinecone_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_vector_store(vector_store, show_progress=True, storage_context=storage_context)
# クエリエンジンを作成します
query_engine = index.as_query_engine(response_mode="refine")
詳細なレスポンスを作成するために、response_mode=”refine”を使用します。
4. ユーザー入力を元に、クエリエンジンにクエリを投げます。
print("今日は何をお手伝いしましょうか?")
q = input()
# クエリは以下のステップを含みます:
# 1. インデックスからドキュメントを検索
# 2. ドキュメントの後処理
# 3. プロンプト + ドキュメントをLLMに送信
# https://docs.llamaindex.ai/en/stable/understanding/querying/querying.html
res = query_engine.query(f"""
Stripeのインテグレーションに関する正真正銘のエキスパートです。あなたの仕事は、StripeユーザーがStripeと製品を統合するのを助けるための詳細な回答を提供することです。関連のあるStripeドキュメンテーションを提供しますので、あなたは質問に対して詳細な答えを提供します。
ドキュメンテーションを読んだり、Stripeのサポートに連絡したりするようにユーザーに伝えることは絶対にしないでください。いつでも直接答えを提供してください。
可能な場合は引用を使用します。
適用可能な場合は実際のコード例を使用します。
次の質問があなたに尋ねられました: {q}""")
print(f"{res}\n")
5. スクリプトを実行します:
python query.py
このコマンドを実行すると、入力した質問文に対する回答文を、Stripe Docsにある情報に基づいて生成します。
以下は元記事にある、英語のデモ動画です。
訳者注: 日本語で質問したり、回答文を取得することも可能です。
以下はGoogle Colabを利用して動作させた例のキャプチャーです。
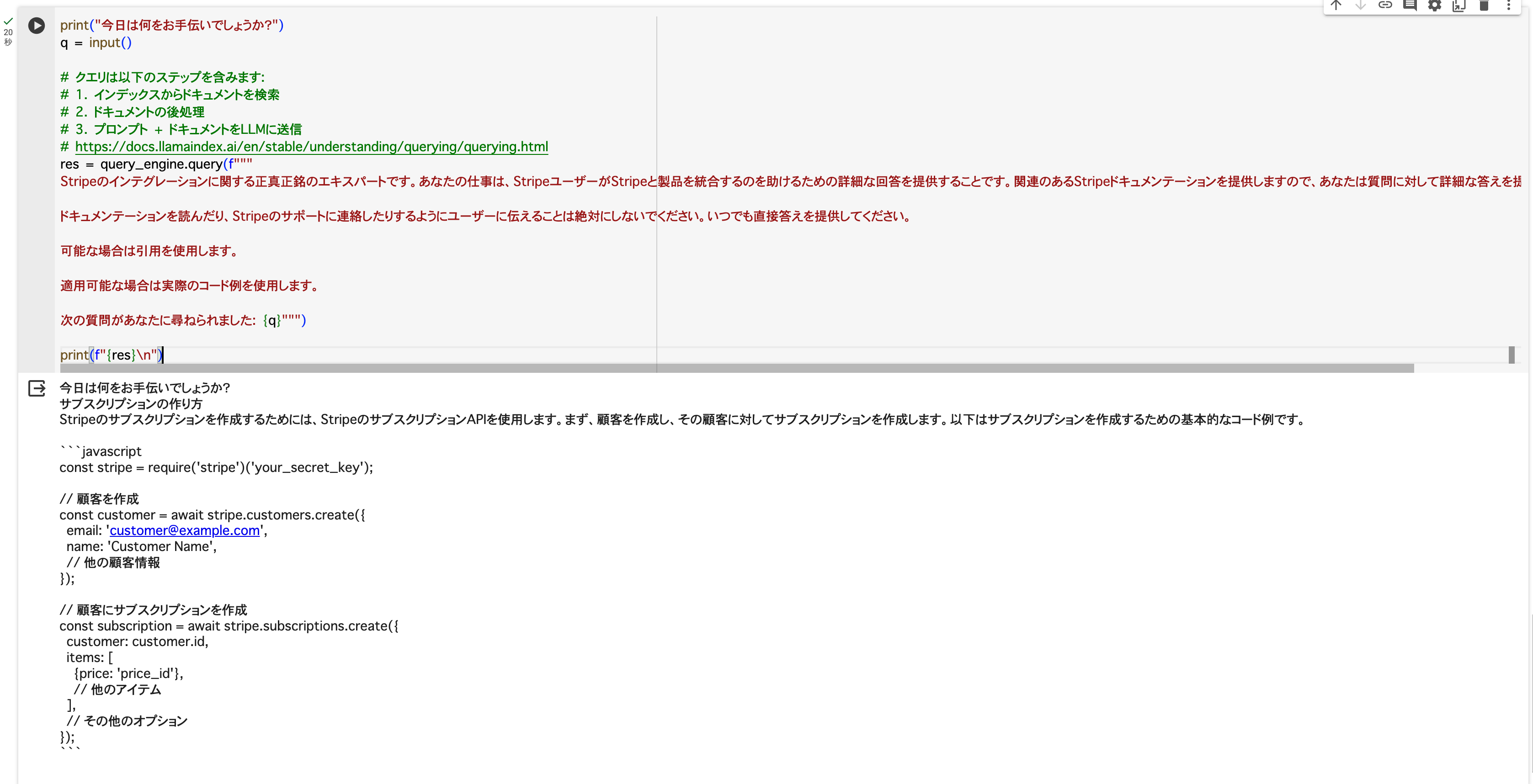
結論
この記事では、Stripeのドキュメンテーションを使用して生成型AIアプリケーションを強化する方法(RAG)について説明しました。RAGは複雑なプロセスではありますが、LlamaIndexやStripeDocsReaderローダーの使用によって始めやすくなっています。ドキュメントの切り出し、取得、クエリに対してデフォルト設定を使用しても、Stripe Docs AIに似たものを作成することができます。レスポンスの品質は、LlamaIndexが提供するパラメータを微調整することで大きく改善できます。
このGitHubリポジトリでのコードを参照してみてください。