目次
1.なぜまとめようと思ったのか
2.前提
3.実際に独学でやったこと
4.感想
なぜまとめようと思ったのか
Kaggleで入門用として有名なお題である"Titanic - Machine Learning from Disaster"をやってみて7日間(1日最長2時間くらい)で上位5.6%(Bronze Medal相当)を達成しました。
Day1〜7までの具体的な取り組みについてのメモははてなブログに書きましたが、自分用でまとめておきたいのと、これからデータサイエンスでpythonを勉強する方にKaggleのコンペは敷居が高そうに見えるけど実際には楽しくできるよ、ってことを伝えたいのでまとめていきたいと思います。
前提
僕のpythonについての能力・学習機会
コーチやメンターがいる訳ではなく独学です。基本はProgateの有料課金コースを終えて、その後はWebサイトで収集できる情報をベースに環境構築をして、写経をしたり、Djangoフレームワークを使って趣味のロードバイクやトレランのレース情報をスクレイピングして一覧表示するサイトをつくったり(Cardio Freaks)できるようになりましたが、駆け出しです。
また、これを書いている2023年3月2日時点で株式会社JDSCの営業を僕の会社として受託して支援しており、その中でデータサイエンティストやエンジニアの仕事を横目で見ることができ、かつコミュニケーションする機会があります。
python x DSという意味では業務での実績がないことに変わりはありません。
pythonではないですがプログラミングでの仕事での実績としては、僕が新卒で入社して一人前の戦略コンサルタントに育ててくれた株式会社野村総合研究所の先輩が立ち上げたD4DR株式会社のプロジェクトにジョインして、Google Spreadsheet上でGPT-3を使って企業情報を収集したくらいです。
今回のチャレンジにおける環境
- 当初:Macbook Air(M1, 8GB/512GB)
- 途中から:Macbooc Air(M2, 24GB/512GB)
- Jupyter Lab
ちなみに、MBAのスペックが途中から上がったのはメモリ8GBのMBAはメモリプレッシャーがすぐに黄色になり、動作がもっさりしたためです。pythonが影響しているというよりは、Jupyter Labを動かしつつ、ブラウザのタブやウィンドウを多数開いたり、普段のコンサルで使うアプリ(Slack, Teams, Messenger等)を多数立ち上げていたことが原因だと思っています。24GBにして快適になりました(FYI)。
独学をやる前にKaggleでやったこと
- KaggleのWebサイトをザッと眺めた
- Kaggle x 初級者 等で検索して日本語サイトを読んだ
- Titanicテーマの動画を見た
- 同、テーマサイトの中身を読んだ(英語は時にDeepLを活用)
- MANAV SHEGAL氏(Gold Medalist)のNotebookを見ながら写経
特に5.は重要で、Notebookを公開されている方で詳しく解説をつけているものを見ることは有効でした。
Kaggleでのお題についての理解の仕方、分析の仕方、データの整形、特徴量生成、モデル選択、学習、評価、そしてKaggleへのsubmition(成果ファイルの提出)までの一通りを経験することができます。もちろん理解が追いついていないのですが、独学を終えた今ではそれでもとても有効だと思っています。
実際に独学でやったこと
Day1, 2:データの理解、欠損(null)値の補完
データの理解
写経の時と同じようにまずはデータを可視化するところから始めました。
よく使ったのが下記です。
# pandasのDataFrameの概要を見る
train_df.info()
train_df.shape()
# pandasのDataFrameを眺める
train_df.head()
train_df.head(10)
train_df.tail(5)
train_df.sample(10)
# pandasのDataFrameの要約統計量(max/min, 四分位とか)を眺める
train_df.describe()
train_df.describe(include='all')
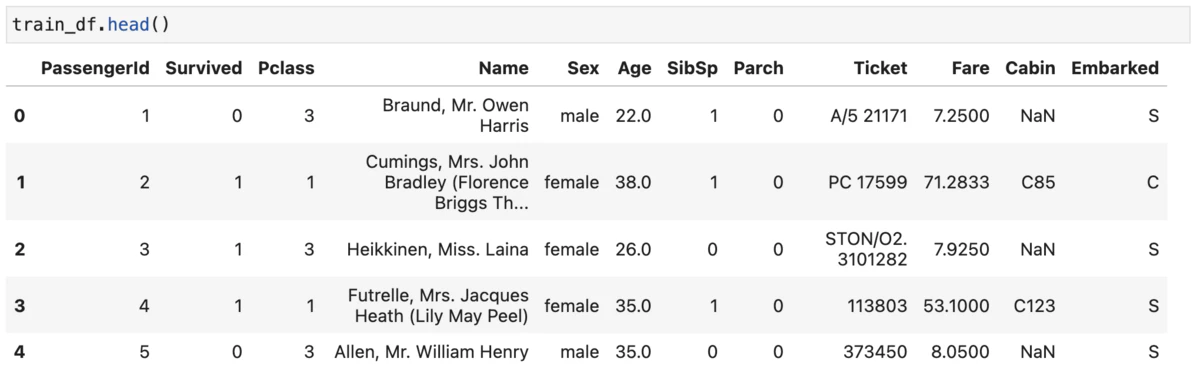
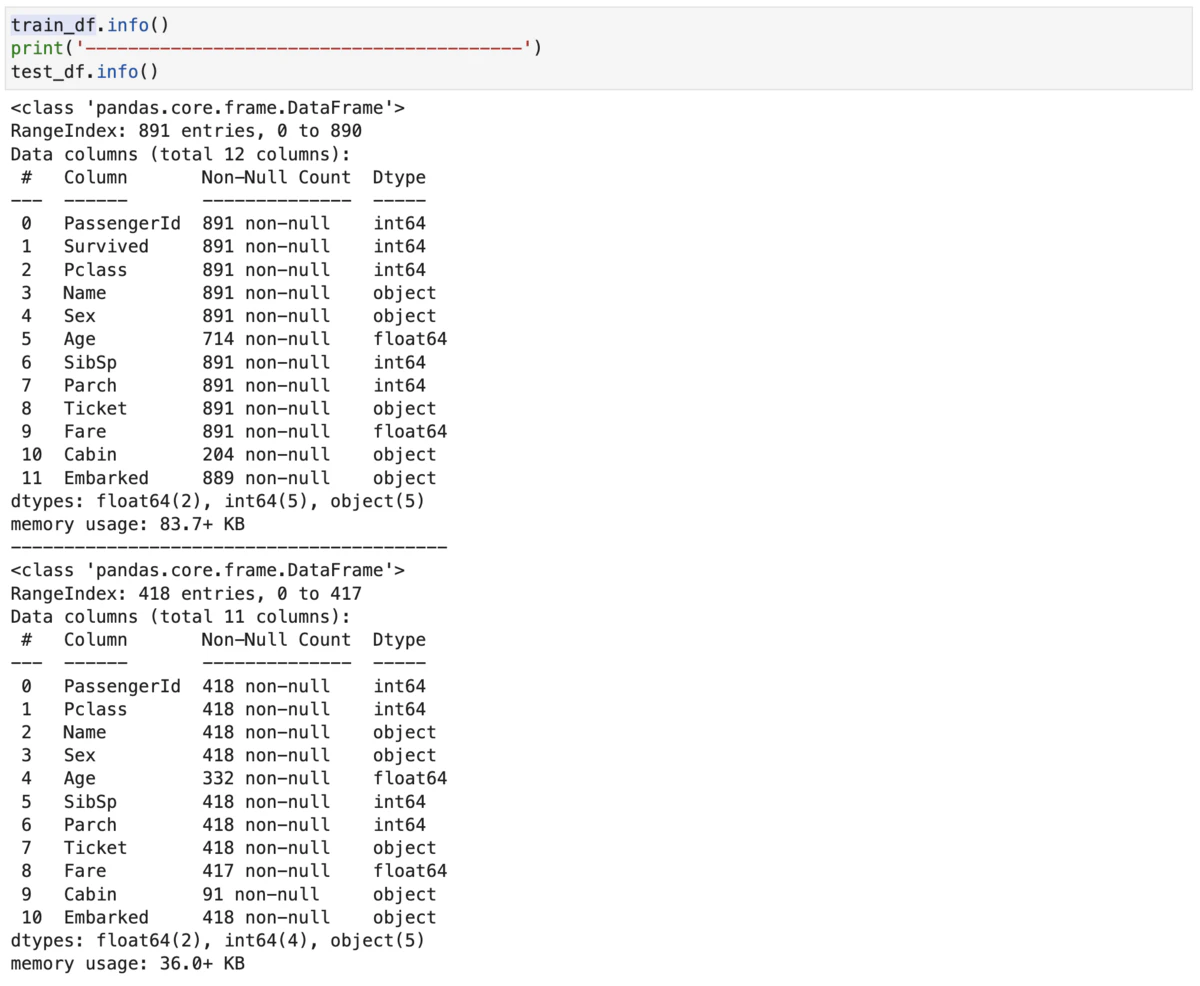
object型の変数があること、いくつかの変数にnull値があることが分かります。機械学習で使用するモデルの大半は(僕の今の理解では)object型、すなわち文字列に近いものは扱えませんし、null値があると処理ができません。ですので、変換、補完が必要です。
変数の型変換
カテゴリー系のobject変数のint型への変換
次にobject型の変数について数値int型に変換しました。
# 学習、テスト用データ双方をfor文で扱うためにcombineを作成
combine = [[train_df], [test_df]]
# 'Sex'についてmale=0, female=1とする
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female':1, 'male':0} ).astype(int)
# 'Embarked'はtrain_dfで2つnull値があるので最頻値freq_portで埋める
freq_port = train_df.Embarked.dropna().mode()[0] # .mode()で最頻値をSeriesで取得
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
# 'Embarked'を文字列型から0/1/2の数値カテゴリ型に変換
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].map( {'S':0, 'C':1, 'Q':2} ).astype(int)
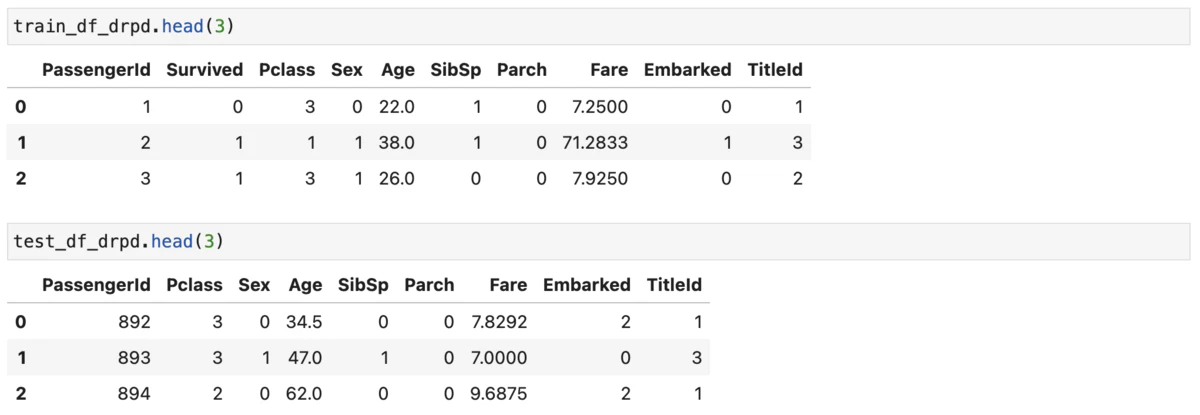
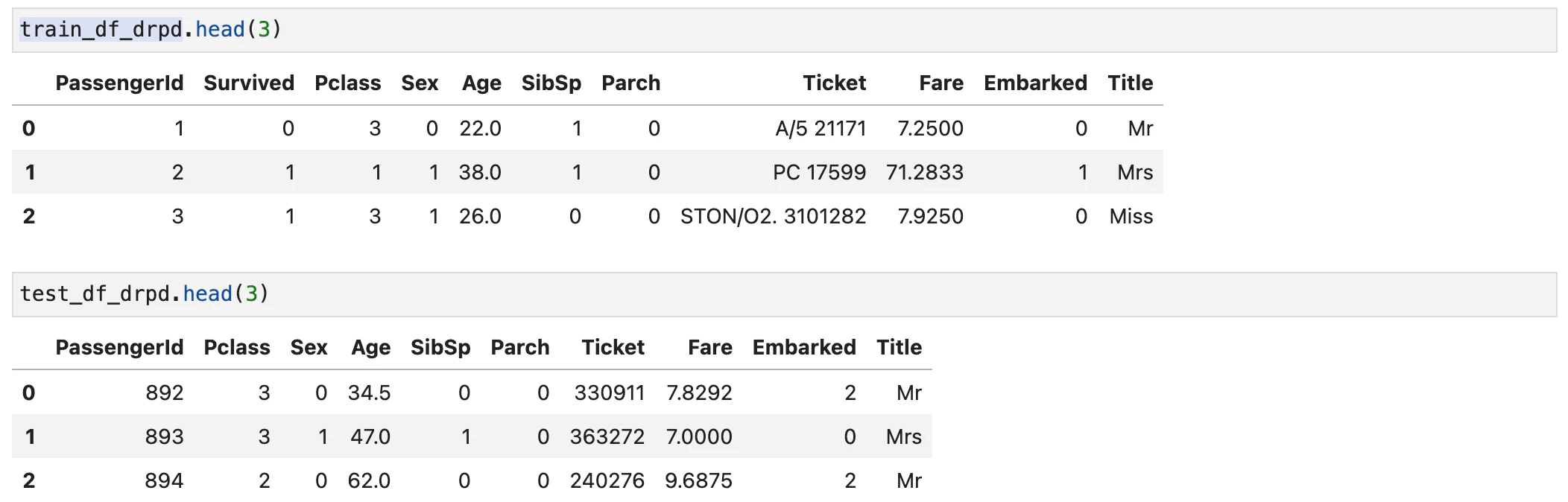
文字列型objectである'Name'の変換
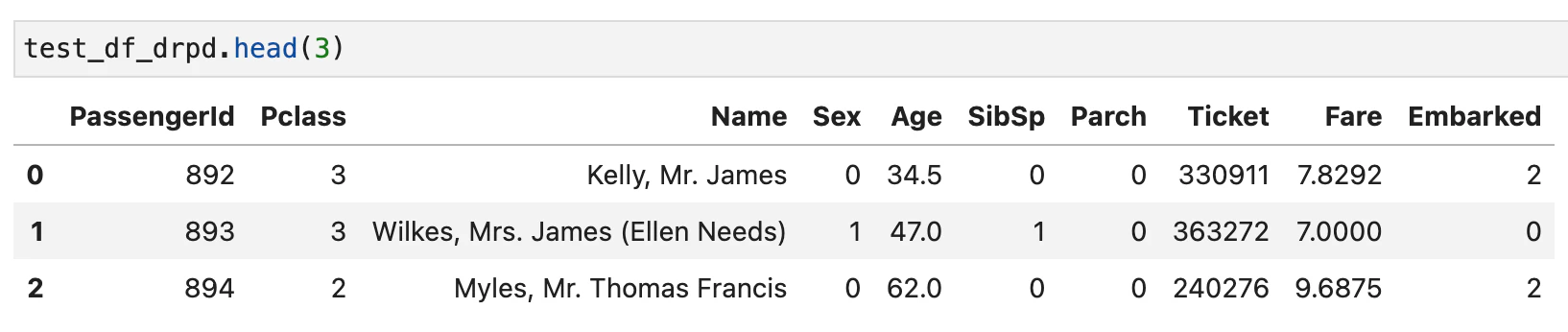
'Name'は文字列なのでそのままでは扱えません。dropさせても良いのですがここは写経の通りにやってみました。まずは正規化表現を用いて肩書部分('Mr'とか)を取り出します。
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.', expand=False)
pd.crosstab(train_df_drpd['Title'], train_df_drpd['Sex'])

次に肩書を一度くくります。ここは写経です。正直英語圏で生活していないと分からないと思います。
or dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess', 'Capt', 'Col', 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train_df_drpd = train_df_drpd.drop(['Name'], axis=1)
test_df_drpd = test_df_drpd.drop(['Name'], axis=1)
combine = [train_df_drpd, test_df_drpd]
同時に'Name'はdorpしてしまいます。
更に数値カテゴリー型にします。
title_mapping = {'Mr': 1, 'Miss': 2, 'Mrs': 3, 'Master': 4, 'Rare': 5}
for dataset in combine:
dataset['TitleId'] = dataset['Title'].map(title_mapping)
dataset['TitleId'] = dataset['TitleId'].fillna(0)
train_df_drpd = train_df_drpd.drop(['Title'], axis=1)
test_df_drpd = test_df_drpd.drop(['Title'], axis=1)
combine = [train_df_drpd, test_df_drpd]
train_df_drpd = train_df_drpd.drop(['Ticket'], axis=1)
test_df_drpd = test_df_drpd.drop(['Ticket'], axis=1)
combine = [train_df_drpd, test_df_drpd]
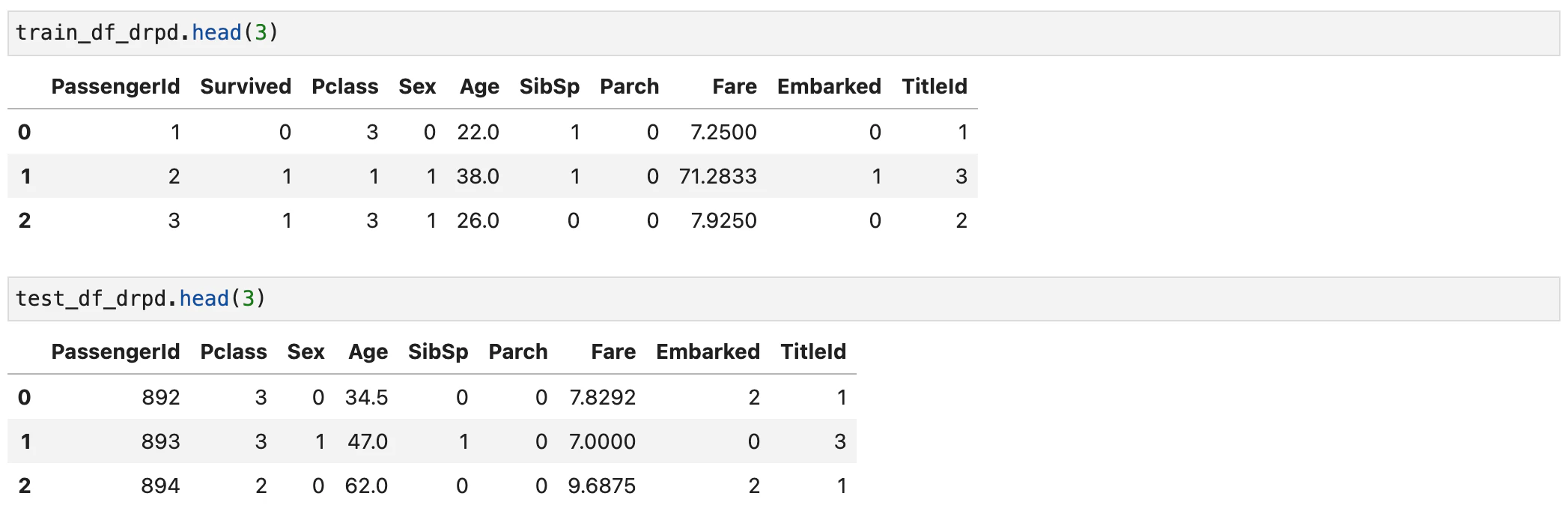
上記では'Ticket'もdropしています。
null値の補完
'Age'の補完
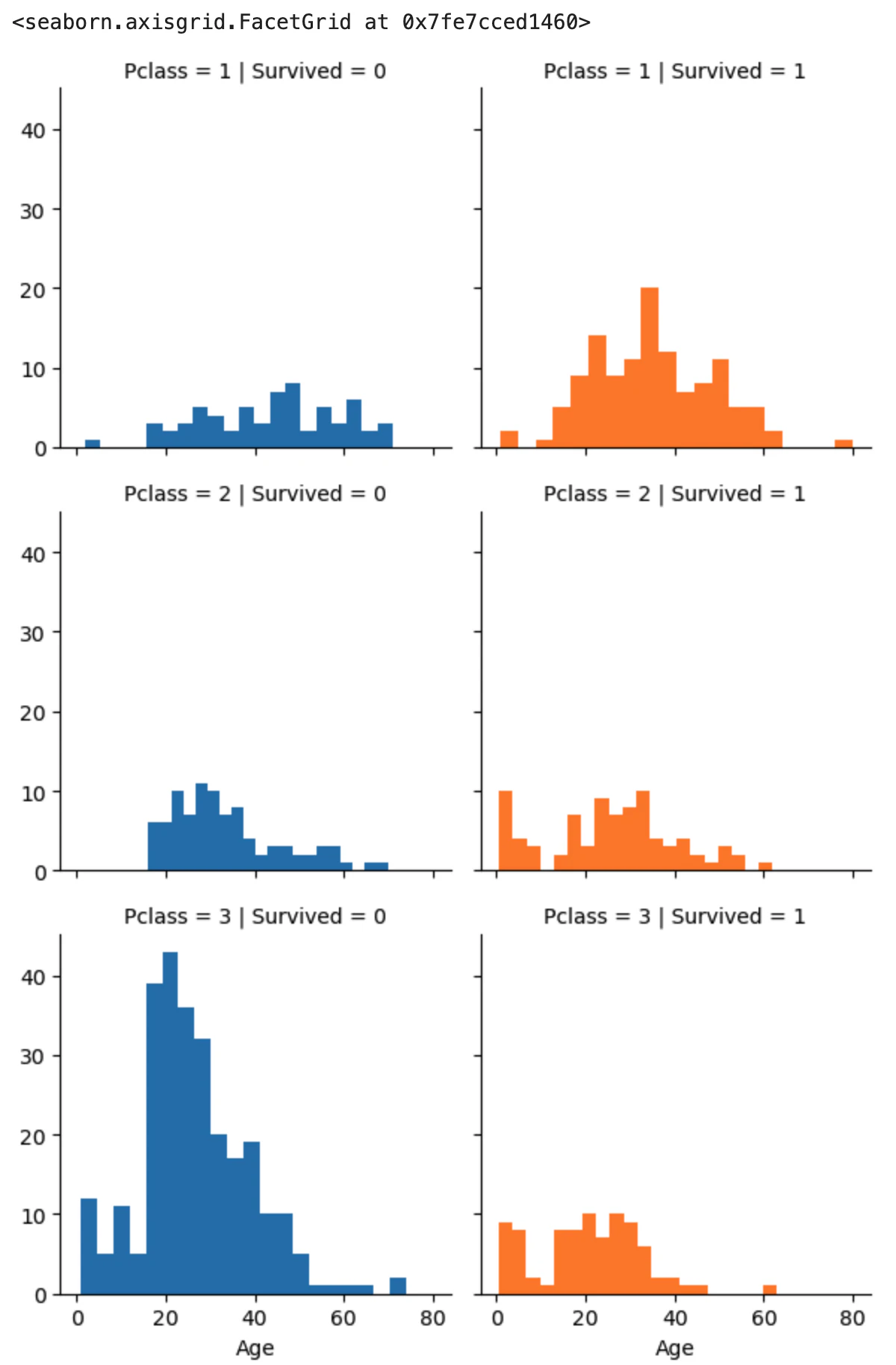
まずnull値の多い'Age'を補完します。傾向が見たいのでseabornのFacegrid関数を使って3(Pclass)x2(Survived)のグリッドを作成、グリッドの中にmatplotlibのhist関数で'Age'のヒストグラムを表示させてみます。
%matplotlib inline
grid = sns.FacetGrid(train_df_drpd, row='Pclass', col='Survived', hue='Survived') # col=''で指定した属性で分けてグラフを表示
grid.map(plt.hist, 'Age', bins=20) # Ageを軸として20分割(棒の数)でヒストグラム表示(この場合80歳/20なので4歳刻み)
ちなみにseabornとかmatplotlibを使う際に%matplotlib inlineをいちいち書かないと2度目の実行からはグラフが出力されないということがありました。ですので、おまじないのように書いてます。
同様に'Survived'と'Sex'を入れ替えて描画。
%matplotlib inline
grid = sns.FacetGrid(train_df_drpd, row='Pclass', col='Sex', hue='Sex') # col=''で指定した属性で分けてグラフを表示
grid.map(plt.hist, 'Age', bins=20) # Ageを軸として20分割(棒の数)でヒストグラム表示(この場合80歳/20なので4歳刻み)
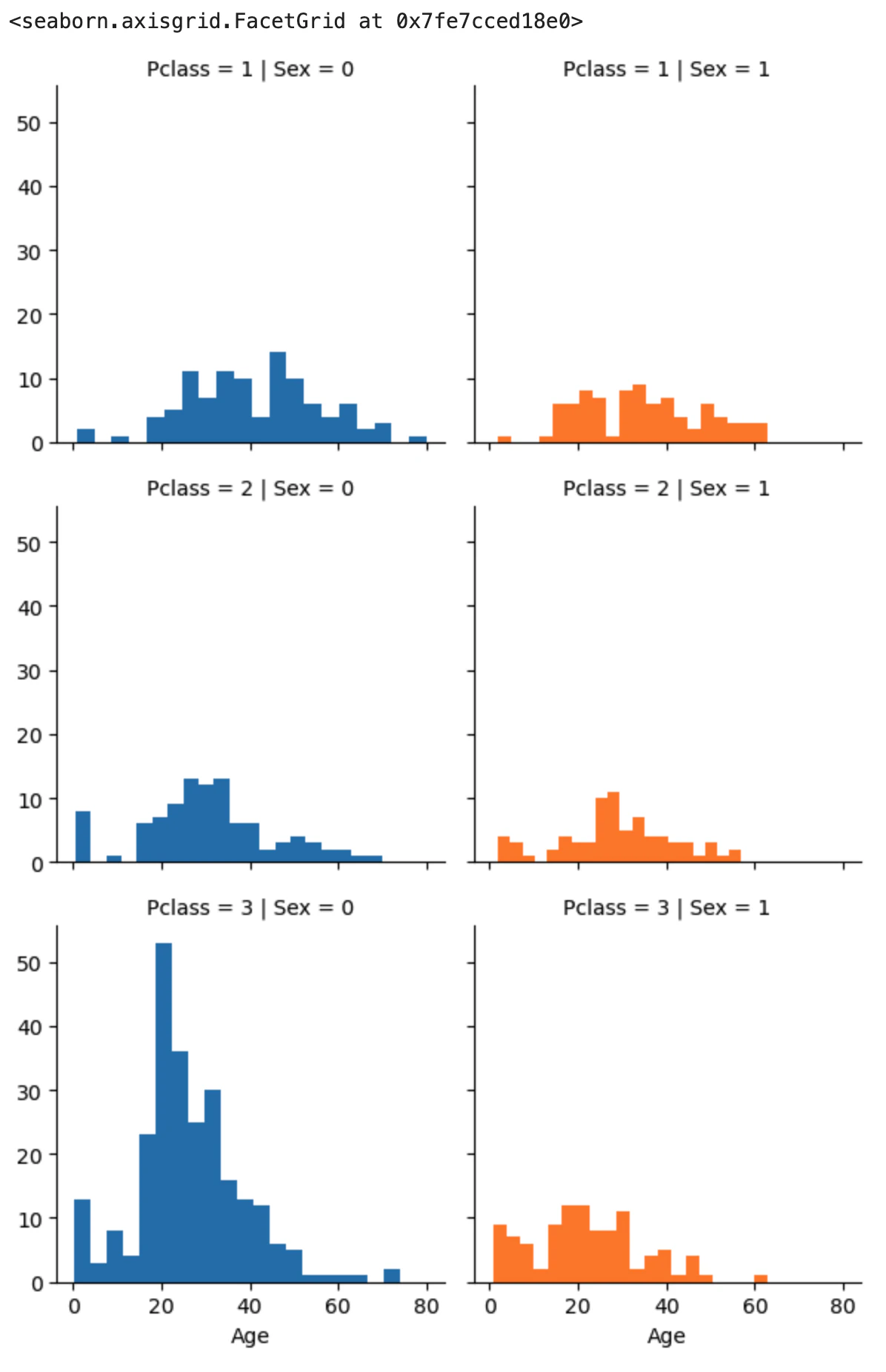
'Age'は'Pclass'とも相関していますし、'Sex'によって中央値・平均値が微妙にずれています。ですので'Pclass'と'Sex'のマトリクスを作って中央値Median()で補完することとしました。
# まず'Sex', 'Pclass'で行列を準備
guess_ages = np.zeros((2, 3))
# 行列'guess_ages'に'Sex', 'Pclass'における'Age'の中央値を代入
for dataset in combine:
for i in range(0, 2):
for j in range(0, 3):
# 'Sex'がiで'Pclass'がj+1のレコードをDataFrameとして抽出
guess_df = dataset[(dataset['Sex'] == i) &
(dataset['Pclass'] == j+1)]['Age'].dropna()
# 中央値を算出
age_guess = guess_df.median()
# 行列(i, j)に中央値を代入
guess_ages[i, j] = int(age_guess/0.5 + 0.5) * 0.5 # ここは分からない…職人技?
for i in range(0, 2):
for j in range(0, 3):
dataset.loc[(dataset.Age.isnull()) & (dataset.Sex == i) &
(dataset.Pclass == j+1), 'Age'] = guess_ages[i, j]
dataset['Age'] = dataset['Age'].astype(int)
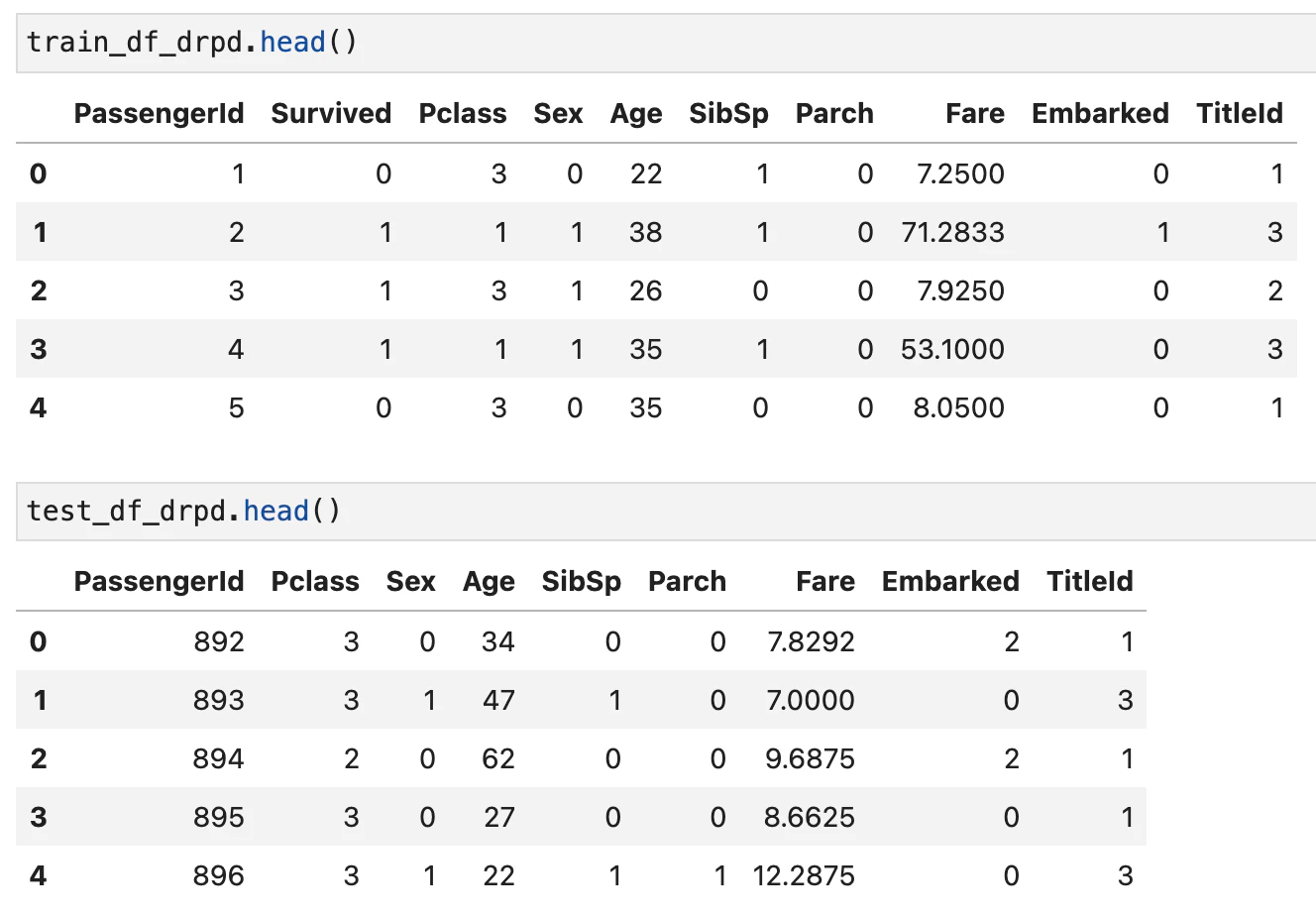
'Fare'の補完
テスト用データであるpandas DataFrameのtest_df_drpdの'Fare'に1つだけnull値があるのでそれを中央値で補完しました。
test_df_drpd['Fare'].fillna(test_df_drpd['Fare'].dropna().median(), inplace=True)
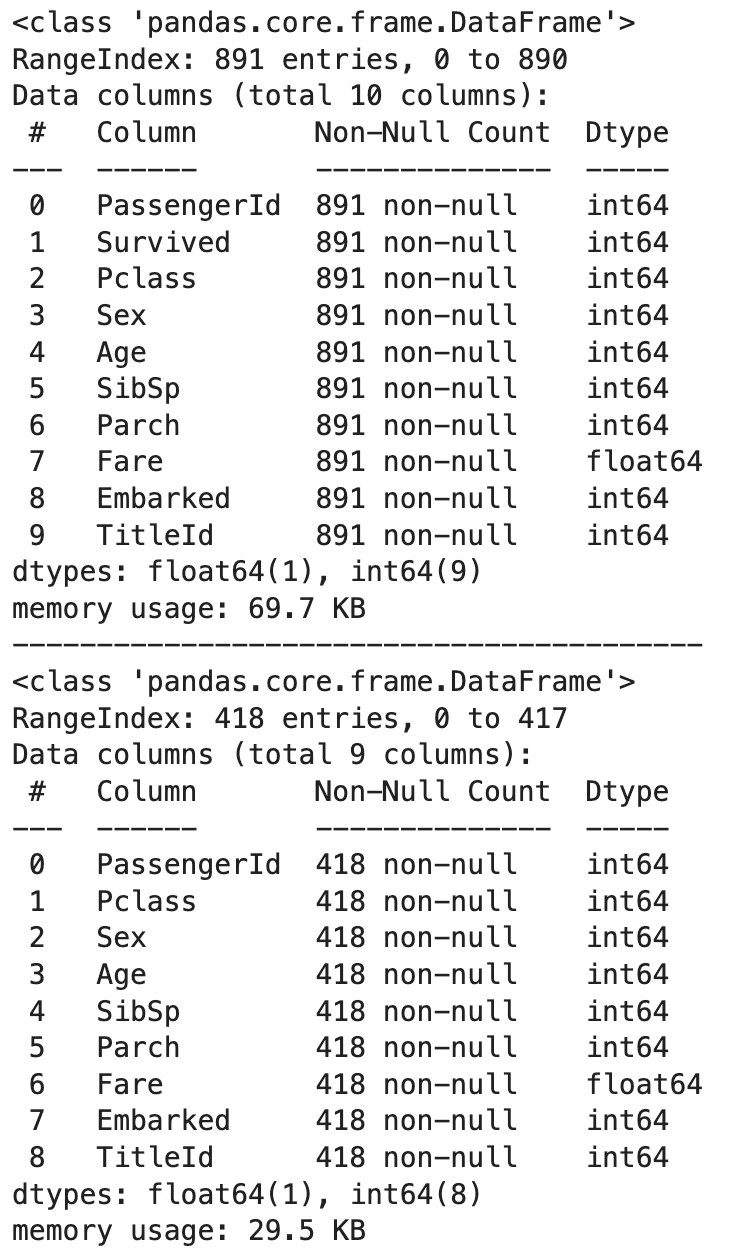
これにて全てがint64 / float64という数値型の変数、特徴量となりました。データのクレンジングが終わったということですね。ここまででDay1,2でした。
目的変数と説明変数、説明変数同士の相関関係の把握
変数同士の相関係数をマトリクスで可視化
train_df_drpd_corr = train_df_drpd.corr()
print(train_df_drpd_corr)
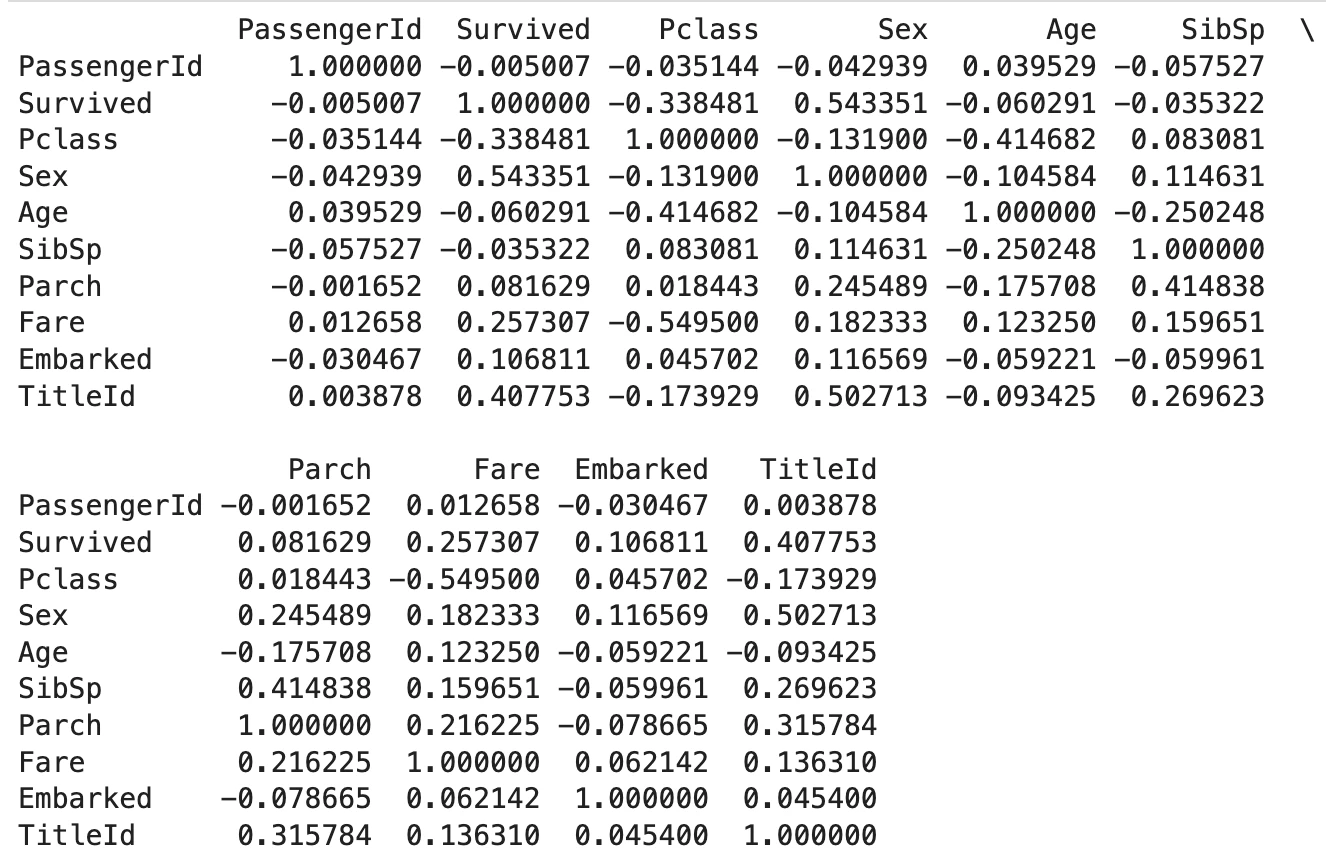
相関係数の表はよく使いました。これを見ながら目的変数である'Survived'との相関度が高い変数をピックアップしました。
- 'Survived'と相関が高いのは'Sex', 'TitleId', 'Pclass', 'Fare'
- 'Sex'と'TitleId'は相関度が高い
- 'Pclass'と’Fare', 'Age'も相関度が高い
- 'SibSp'と’Parch'は相関度が高い
- 'Embarked'は特に何も相関していない
あたりが分かったので、説明変数同士の相関(多重共線性)を排除することを意識して、単純に’Sex'と'Pclass'のみでモデリングしてみることにしました。
モデリングと評価
Day3:1st Submission
機械学習モデルについては写経の時にRandom Forestが一番効いているのが分かったので、今回の独学ではRandom Forest一択としています。
from sklearn.ensemble import RandomForestClassifier
t = train_df_drpd['Survived'].values
x = train_df_drpd[['Sex', 'Pclass']].values
x_test = test_df_drpd[['Sex', 'Pclass']].values
rf = RandomForestClassifier()
rf.fit(x, t)
pred_rf = rf.predict(x_test)
rf.score(x, t)
submission = pd.DataFrame({
'PassengerId':test_df_drpd['PassengerId'],
'Survived':pred_rf
})
- モデルスコア:0.7867564534231201
- テストスコア:0.77511
参加者の中で下位30%くらいだったかと思います。ここまでがDay3です。
その後、上記の仮説で出した特徴量を色々と組み合わせてテストしますが、この0.77511をなかなか超えられず一度目の壁にぶつかります。
Day4,5:'IsInfant'をモデルに組み込み上位7.2%を達成
下記の特徴量を作ってみました。
- FamilySize:家族構成人数で'SibSp'と'Parch'を加算したもの
- IsSmallFamily:'FamilySize'<=3の人
- IsSingle:'FamilySize'=0の人
- IsInfant:'Age'が7歳未満の人
# FamilySize
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch']
train_df_drpd[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='FamilySize', ascending=True)
# IsSmallFamily
for dataset in combine:
dataset.loc[(dataset['FamilySize'] >= 1) & (dataset['FamilySize'] <= 3), 'IsSmallFamily'] = 1
dataset.loc[(dataset['FamilySize'] < 1) | (dataset['FamilySize'] >= 4), 'IsSmallFamily'] = 0
train_df_drpd['IsSmallFamily'] = train_df_drpd['IsSmallFamily'].astype(int)
test_df_drpd['IsSmallFamily'] = test_df_drpd['IsSmallFamily'].astype(int)
combine = [train_df_drpd, test_df_drpd]
# IsSingle
for dataset in combine:
dataset.loc[dataset['FamilySize'] == 0, 'IsSingle'] = 1
dataset.loc[dataset['FamilySize'] != 0, 'IsSingle'] = 0
train_df_drpd['IsSingle'] = train_df_drpd['IsSingle'].astype(int)
test_df_drpd['IsSingle'] = test_df_drpd['IsSingle'].astype(int)
combine = [train_df_drpd, test_df_drpd]
# IsInfant
for dataset in combine:
dataset.loc[dataset['Age'] < 7, 'IsInfant'] = 1
dataset.loc[dataset['Age'] >= 7, 'IsInfant'] = 0
train_df_drpd['IsInfant'] = train_df_drpd['IsInfant'].astype(int)
test_df_drpd['IsInfant'] = test_df_drpd['IsInfant'].astype(int)
combine = [train_df_drpd, test_df_drpd]
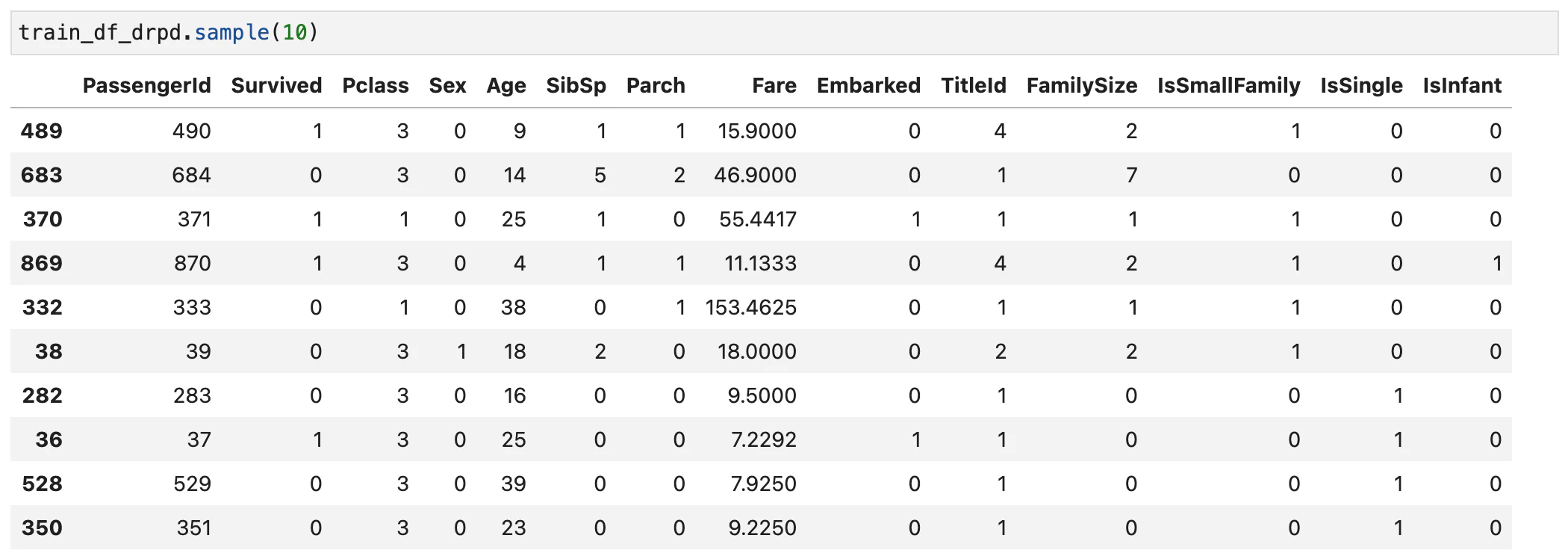
それで色々と特徴量を組み合わせてみました。
t = train_df_drpd['Survived'].values
x = train_df_drpd[['Sex', 'Pclass', 'IsInfant']].values
x_test = test_df_drpd[['Sex', 'Pclass', 'IsInfant']].values
rf.fit(x, t)
pred_rf = rf.predict(x_test)
rf.score(x, t)
- モデルスコア:0.8058361391694725
- テストスコア:0.77751
ベストスコアを更新。順位も3,745/14,205と上位26.4%と大躍進しました。
ここまでがDay4です。
Day5ではDay4で作成したモデルに更に’TitleId’を追加して学習させました。
t = train_df_drpd['Survived'].values
x = train_df_drpd[['Sex', 'Pclass', 'IsInfant', 'TitleId']].values
x_test = test_df_drpd[['Sex', 'Pclass', 'IsInfant', 'TitleId']].values
rf.fit(x, t)
pred_rf = rf.predict(x_test)
rf.score(x, t)
- モデルスコア:0.8080808080808081
- テストスコア:0.78947
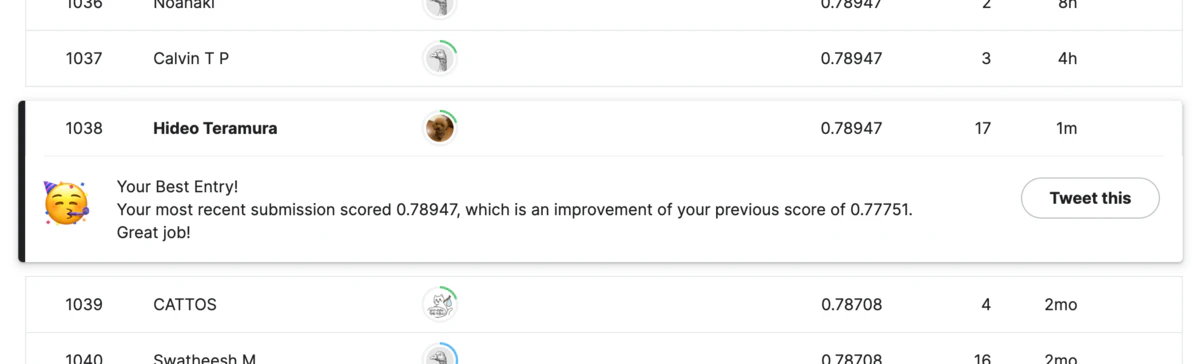
結果'Sex', 'Pclass', 'IsInfant', 'TitleId'の組み合わせとなりましたが、これでベストスコアを更新し1,038 / 14,269で上位7.2%を記録することができました。
Day6,7:'Fare'に関する特徴量を組み込み、上位5.6%を達成
その後伸び悩み、一度基本に立ち返るということで学習用データを眺めてみました。
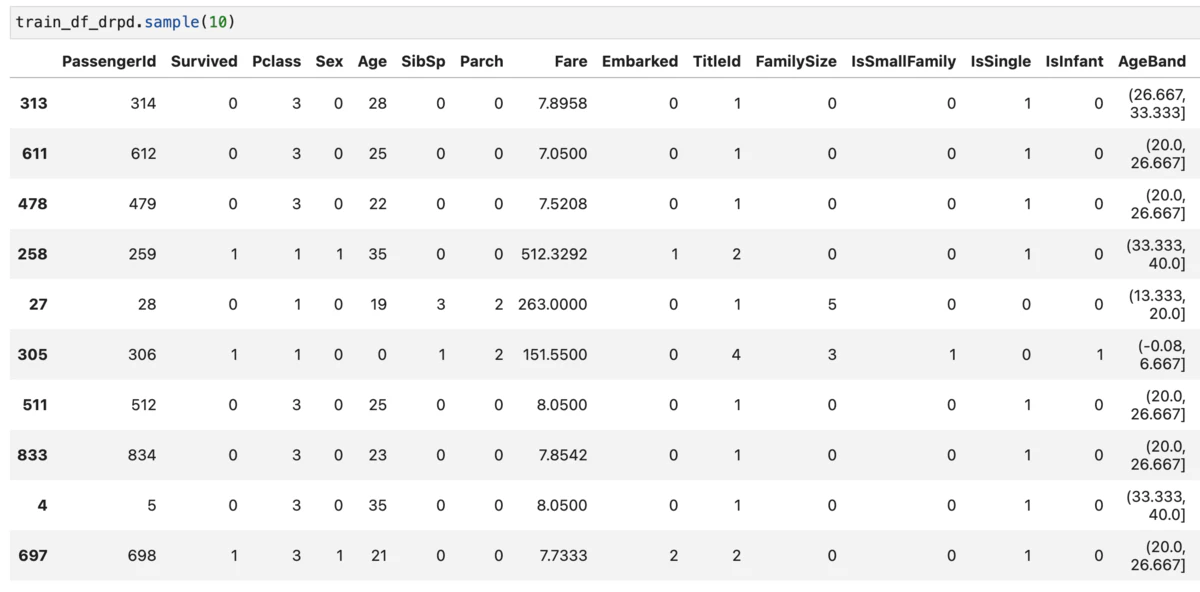
Day5でのBest Scoreを叩き出したモデルの特徴量は'Sex', 'Pclass', 'TitleId', 'IsInfant'の4つ。性別、階級、家族的な要素が含まれたものになっていることに気づきました。
そして’Fare'については特徴量化していない。’Fare'も’Survived'と相関係数はまあまあ高いもののこれもモデルに入れると過学習が起こり、テストスコアが下がることも分かっていました。
更にもう一度テーブルを眺めてみて、'Fare'を'FamiliSize(+1)'で割って'UnitFare'としてみたらどうだろうかと思いつきました。
train_df_drpd['UnitFareBand'] = pd.cut(train_df_drpd['UnitFare'], 10)
train_df_drpd[['UnitFareBand', 'Survived']].groupby(['UnitFareBand'], as_index=False).mean().sort_values(by='UnitFareBand', ascending=True)
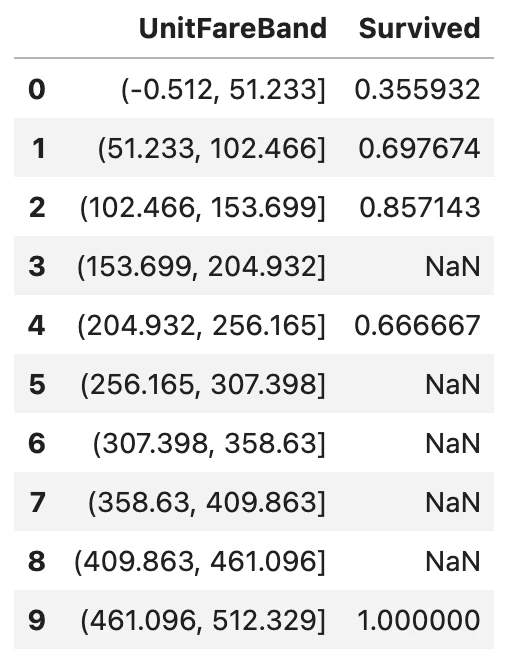
pandasの.cut()の変数を色々と変えて'Survived'の平均値を見てみたところ、'UnitFare'<50あたりで生存率が35%前後と極めて低くなることが分かりました。
要するに1人あたりのチケット金額が50を超えている人は生き残る確率が高いということですね。ということで’IsLowUnitPrice'という特徴量を生成しました。
for dataset in combine:
dataset.loc[dataset['UnitFare'] < 50, 'IsLowUnitFare'] = 0
dataset.loc[dataset['UnitFare'] >= 50, 'IsLowUnitFare'] = 1
train_df_drpd['IsLowUnitFare'] = train_df_drpd['IsLowUnitFare'].astype(int)
test_df_drpd['IsLowUnitFare'] = test_df_drpd['IsLowUnitFare'].astype(int)
combine = [train_df_drpd, test_df_drpd]
- モデルスコア:0.8114478114478114
- テストスコア:0.79186
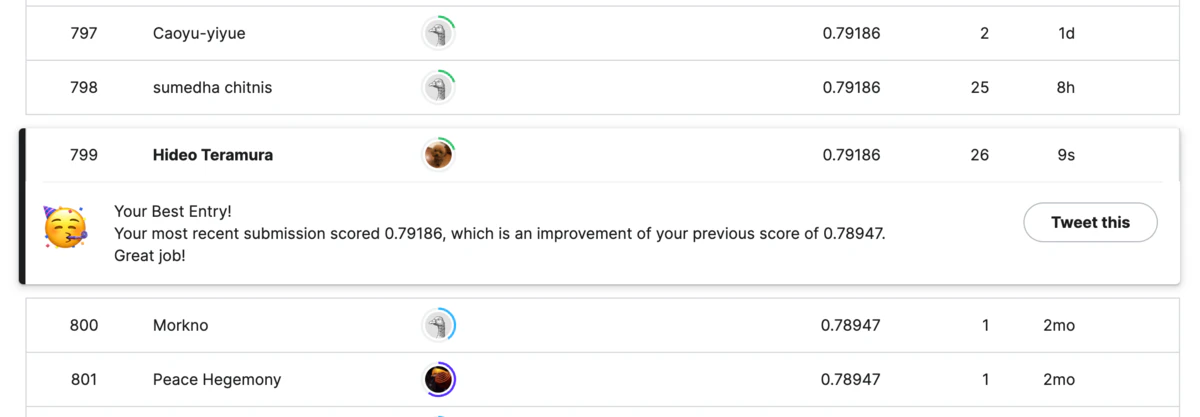
これで799位 / 14,182人で上位5.6%を達成しました。独学を始めてDay7のことでした。
感想
- Day1,2:データクレンジング
- Day3:モデリング開始と最初のサブミッションで下位30%からスタート
- Day4:特徴量生成とモデリングにより上位26.4%
- Day5:特徴量の組み合わせを変更して上位7.2%
- Day6:ベストモデルに変数、特徴量を追加して低迷
- Day7:触っていなかった変数から新特徴量を生成して上位5.6%を達成
こんな感じになりました。
ここからの学びとしては、
- 変数、特徴量で目的変数への相関係数0.3以上をモデルに組み込むことが基本
- 上記に達していないものでも独立性の高い変数、特徴量は精度向上に寄与する
- 上記でスタックした場合には使っていない独立性の高い変数から特徴量を生成しモデルに組み込むことでブレイクスルーできる可能性がある
というあたりです。再現性のないやり方をしている初心者なのでもっと効率よく特徴量エンジニアリング、モデリングをしたいです。そのためにmatplotlibやseaborn等を活用してデータのビジュアライズを瞬時にできるように熟練する、というのが目下の課題です。
長文、乱文にお付き合いいただき、ありがとうございました。