今年も書きます、アドベントカレンダー。去年に引き続き、データサイエンティスト現場の実情と改善なんかを書きたいと思います。私自身はデータサイエンティストありながら、最近はWebアプリケーション開発とそのマネジメントなんかもしており、データサイエンティストという名前がもはや適切ではないような気もしてきましたが、満足のいく年でした。私自身は、データ分析はやはり現場で使ってもらえて、なんぼだと思います。
昨今、データサイエンスを社会実装だのMLOpsだのそれ用にこのツールを使えば良いだのなんだのとやかく言われていますが、地に足がついているか怪しいものもあるように思います。私は単に、データサイエンティストが正しくpythonを使いこなせていないが割と大きい気がしております。そういうわけで今年は、データサイエンティストのコードを含めたWebアプリケーションを完成させるために、私が不可欠だと考えているデータクラスとその使い方について解説したいと思います。
敢えて機械学習や数理最適化、量子コンピュータといった華やかなテーマから距離を取ったテーマを選びました。ですが、この地味テーマが如何に重要かというのが伝われば嬉しいなと思います。
データサイエンティストは、「受け身」を教えてもらえない。
さて、データクラスについて話す前に、少し抽象度の高い話から始めます。昨今はデータサイエンティストブームによってデータサイエンティストが増えてきましたが、私はこの「ブーム」によって、地に足のついていない人が増えてしまったと思います。まず他の職業と比較して考えてみたいと思います。
柔道家の例:技を覚える前に受け身を学ぶ
プログラマーの例:開発する前に、テストを学ぶ
データサイエンティストの例:今流行っている手法を試したい。

要するに、他の職業は技を覚える前に、受け身を覚えます。試合に出てケガをする危険性をまずは抑えるためです。しかし、データサイエンティストはどうでしょうか?受け身なんて地味なことを考える人は少なく、如何に華やかで注目を浴びそうなテーマに飛びつきます。これも私は流行によって発生した功罪かと思います。さらに取返しが付かないのが、受け身ではなく技から入ってしまった人は今更、受け身なんぞ覚えるモチベーションがありません。
柔道でも、プログラマーでも、はじめにこんなこと覚えてなんの意味があるの?と誰しも思いますが、後々になって、これってこんな重要なことだったのだ!と後で気づきがあります。しかし、データサイエンティストの多くは技から入りますからこういった気づきはほとんどないのです。次ではより具体的に受け身の取れないデータサイエンティストを見ていきましょう。
受け身が取れていない例1~返り値7つ~
def get_sales_data(month, year):
"""その月の売上データを取得する
"""
# SQLとかもろもろ書く
return df_sales, list_product_id, nb_product, total_sales, max_sales, min_sales, median_sales
さて、こんな関数見たことありませんか?年と月を指定して、その期間に売上がある商品のリストや、商品数、売上の最大値、合計、ローデータ等を受け取りたいとしましょう。受け身が取れていないデータサイエンティスト君だとこのように、全ての返り値をベタに書いてしまうのです。関数名のsales_dataというのが抽象的だったり、関数を7つも書きたくないしといったことがあるでしょう。
受け身が取れていない例2~ディクショナリに文字列キーで変数ぶち込み~
さて、上記の問題意識はデータサイエンティスト君にも一応あるようです。ただ、そこでデータサイエンティスト君は以下のような対応を取ります。
def get_sales_data(month, year):
"""その月の売上データを取得する
"""
# SQLとかもろもろ書く
sales_data = {}
sales_data["df_sales"] = df_sales
sales_data["list_product_id"] = list_product_id
sales_data["nb_product"] = nb_product
sales_data["total_sales"] = total_sales
sales_data["max_sales"] = max_sales
sales_data["min_sales"] = min_sales
sales_data["median_sales"] = median_sales
return sales_data
これでスッキリしてよかったと思っている方いませんか?返り値は確かに1つになりました。しかし、これはアウトです。なぜでしょうか?
その理由はデータサイエンティストはチーム開発の意識がないためです。このsales_dataを受け取った人が別の人だったとしましょう。さてその人はこの中身を知るためにどうするのでしょうか?中身のキーを毎回確認するのですか?まぁ自分自身でも良いとしましょうか、中身毎回覚えられますか?このディクショナリがファイルをたくさんまたいだとき、中身わかりますか?さらにはキーが文字列のため補完も効きません。最悪です。自分一人でノートブックに殴り書きするならまだ許せますが、アプリケーション化する上では保守の観点から、絶対に削除するべきです。
受け身が取れていない例3~変更に弱い~
データサイエンティストのプロジェクトの進め方はPOCと呼ばれる、設計がなく、とりあえず試してみようという形でプロジェクトが進む場合が多いです。こういった場合、設計書はありませんし、データも後から追加されますし、アウトプットも顧客のフィードバックを得ながら逐次的に変更していく必要があります。いわゆるアジャイル開発に近い形を取りますが、これは後々の変更があるのが当たり前です。その場合に、データの前処理、モデル作成、可視化といったタスクが疎結合であることが重要です。この疎結合という考え方がまだまだデータサイエンティストには浸透していません。次節では、これらをデータクラスで解決する方法を書きます。
データクラスとは?
さて、ここからがデータクラスの解説です。データクラスこそ、私が思うにデータサイエンティストが一番初めに覚えるべき「受け身」です。データクラスとは初心者には、たくさんの変数をホチキスのように止められるよと覚えておけばまずよいです。まずは上の2つの正解を示しましょう。
import pandas as pd
from dataclasses import dataclass
from typing import List
@dataclass(frozen=True)
class SalesData:
df_sales: pd.DataFrame
list_product_id: List[str]
nb_product: int
total_sales: float
max_sales: float
min_sales: float
median_sales: float
def get_sales_data(month, year):
"""その月の売上データを取得する
"""
sales_data = SalesData(
df_sales=df_sales,
list_product_id=list_product_id,
nb_product=nb_product,
total_sales=total_sales,
max_sales=max_sales,
min_sales=min_sales,
median_sales=median_sales
)
return sales_data
はい、こちらが正解です。SalesDataというデータクラスを定義し、そのインスタンスを返しましょう。これは返り値も一つになりますし、辞書と違い、sales_data.min_salesといった形で変数名で中身にアクセスすることができます。文字列ではなく、中身が明文化されるので、これを受け取った人も中身を参照しながら実装を進めることができます。それ以外にも以下のようなメリットがあるようにも思います。
設計を考える癖がつく。
お気づきの方もいるかと思いますが、データサイエンティストには設計という意識がほとんどありません。売上データというオブジェクトは何を持っているべきか、例えば、売上とは関係ない顧客情報などがあった場合、それは別データクラスにした方が管理しやすいかといったデータクラスを軸とした設計が身につくのです。
いやいやそんなこと当たり前でしょと思うエンジニアの皆様、すみません、、データサイエンティストというのはここからなのです。
アルゴリズムのI/Oが明確化される
データサイエンティスト大好き統計モデルに焦点を当てて考えてみましょう。例えば、需要予測モデルを作成するといった際に、LightGBMで予測するのか、Prophetを使うのか、Pytorchを使うのか、いろいろとあるかと思います。これらは最初に述べた技に相当します。さて、これら3つを試すのに、どのような実装が正しいのでしょう。まさかノートブックのファイルを分けて管理しているのでしょうか?時節でも詳しく述べますがこういった際にデータクラスが大活躍するのです。要するに、アルゴリズムの種類がなんであったとしても、データクラスを受け取ってデータクラスを返すような実装にしておけば良いのです。
データクラスの使い方~実践編~
さて、ここからはより実践的な内容に入っていきたいと思います。私が実際にデータサイエンティストのアルゴリズムをWebアプリケーションにするために取っている方法を紹介したいと思います。
心構え~1人3役~
まずはじめに、1人で実装していたとしても、以下のように3人の人間がいると仮定します。この3人はそれぞれ別のスキルセットを持っているとします。
・Aさん→データ加工担当(問題定義)
・Bさん→アルゴリズム担当(問題回答)
・Cさん→可視化担当(採点)
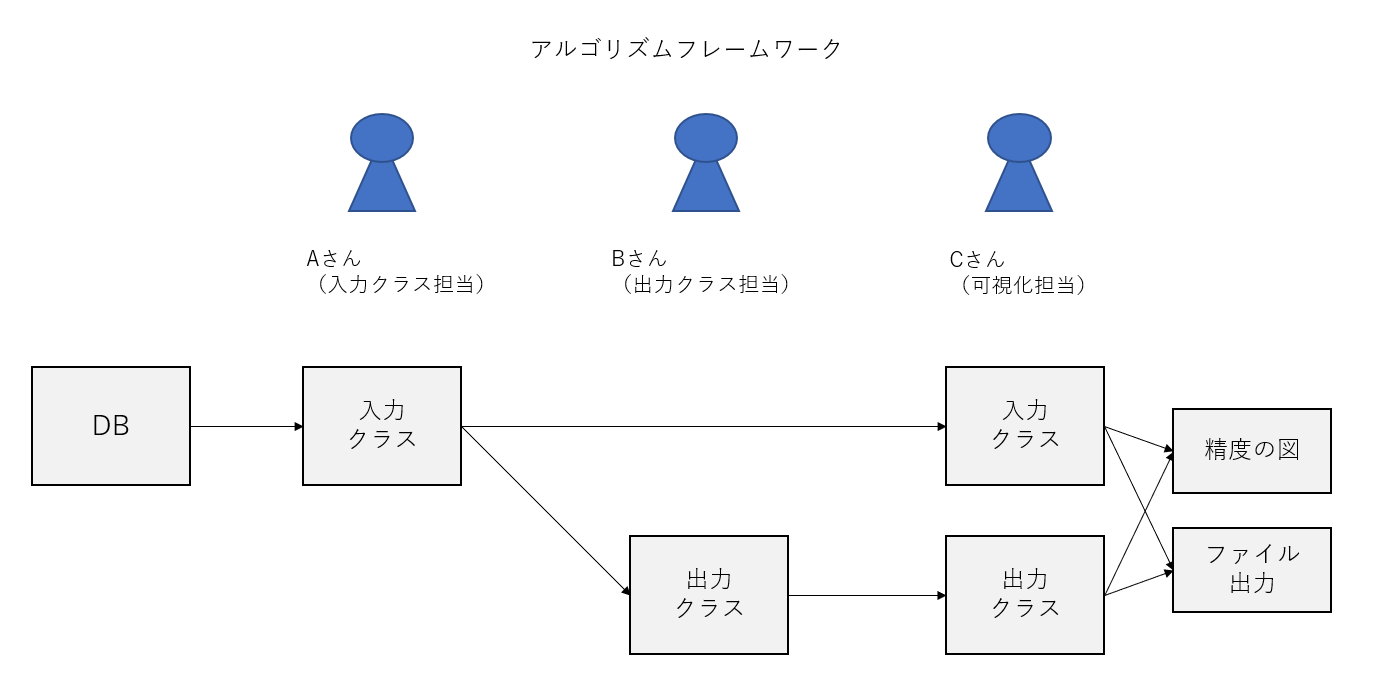
こういった3項目を疎結合にして1本につなげることを考えます。そのために、この3人をデータクラスによって、つなぎ合わせることを考えます。
1. アルゴリズム入力用のデータクラスを作成する
import pandas as pd
from dataclasses import dataclass
from typing import List
from sklearn.base import BaseEstimator
@dataclass(frozen=True)
class PredictionInputData:
"""予測アルゴリズム入力クラス
list_fold_id: クロスバリデーションのFoldを特定するためのidのリスト
list_target_col_name: 目的変数の列名のリスト
list_train_col_name: 説明変数の列名のリスト
datamart: pd.DataFrame: 説明変数と目的変数がまとまったデータマート
fold_id_map_list_train_idx: Fold-idとデータマートの学習データのindexのリスト
fold_id_map_list_test_idx: Fold-idとデータマートの予測データのindexのリスト
"""
list_fold_id: List[int]
list_target_col_name: List[str]
list_train_col_name: List[str]
datamart: pd.DataFrame
fold_id_map_list_train_idx: Dict[int, List[int]]
fold_id_map_list_test_idx: Dict[int, List[int]]
@dataclass(frozen=True)
class PredictionOutputData:
"""予測アルゴリズム出力クラス
regressor: 全データによる学習済みのモデル
fold_id_map_mean_absolute_error: Fold-idと平均絶対誤差の辞書
datamart_with_predict: 予測列が付与されたデータマート
"""
regressor: BaseEstimator
fold_id_map_mean_absolute_error: Dict[int, float]
datamart_with_predict: pd.DataFrame
このデータクラスに対し、Aさんの行うことはPredictionInputDataを作成します。
def make_prediciton_input_data(db_engine):
df_row_data = pd.read_sql("""select * ...""", db_engine)
# もろもろ加工
return PredictionInputData(
list_fold_id=list_fold_id,
list_target_col_name=list_target_col_name,
list_train_col_name=list_train_col_name,
datamart=datamart,
fold_id_map_list_train_idx=fold_id_map_list_train_idx,
fold_id_map_list_test_idx=fold_id_map_list_test_idx,
)
入力クラスのポイントは、アルゴリズムの問題設定がなされているだけで、解いてはいないということです。datamartと、それをクロスバリデーションを用いて予測精度を検証するための分割条件が指定されています。あとはこれをアルゴリズム大好きデータサイエンティストのBさんに解いてもらえれば良いわけです。ただし、Bさんは解答用紙に好き放題書いてよいわけではなく、必ず出力クラスという解答用紙に書いてもらいます。要するに、大学入試でいう2次試験のような自由記述問題ではなく、センター試験のような穴埋め形式で解答させることで、複雑なアルゴリズムをコントロールするのが狙いです。データクラスによってI/Oがきちんと定義されます。
少し補足すると、dataframeを使っている箇所はどうしても列名がわからなくなってしまうため、panderaで列名を定義するのが良いです。
2. アルゴリズム出力用のデータクラスを作成するBさん
Bさんは入力クラスを受け取って、出力クラスを返す関数を1つ作成するだけで良いです。しっかり、出力クラスという形式に穴埋めします。
def execute_prediction(prediction_input_data):
datamart = prediction_input_data.datamart
# もろもろアルゴリズム
return PredictionOutputData(
regressor=regressor,
fold_id_map_mean_absolute_error=fold_id_map_mean_absolute_error,
datamart_with_predict=datamart_with_predict
)
ここでのポイントはBさんは、結果の可視化はないことです。予測タスクにおいては、実績と予測の誤差がわかるような45度plotを作成しますが、それはBさんにはさせません。Bさんのタスクはあくまで予測のデータを用意させることで、それを可視化するのは、別のCさんが行います。これによって、アルゴリズムと結果の可視化を疎結合にすることが狙いです。
3. 入力クラスと出力クラスを受け取って結果を可視化するCさん
最後に、Cさんは入力クラスと出力クラスを受け取って結果を可視化します。
import plotly.express as px
import pandas as pd
def draw_45_plot(forecast_input_data, forecast_ouput_data):
"""実績vs予測の45度plotの図を作成する
"""
list_figure = []
# もろもろ可視化のコード
return list_figure
def draw_summary_file(excel_file_path, forecast_input_data, forecast_ouput_data):
"""予測精度のサマリをExcelファイルで出力する
"""
writer = pd.ExcelWriter(excel_file_path)
# もろもろ加工
writer.save()
Cさんは問題設定とその回答の2つを受け取り、可視化の図を作成したり、精度をサマリしてエクセルファイルに出力したりします。
CさんはアルゴリズムがLightGBMだのProphetだのを気にする必要はありません。単に精度を表示するただそれだけに集中することができます。
4. 全体をつなぎ合わせる
最後に、全体をつなぎ合わせたスクリプトを見てみましょう。
import os
import plotly.express as px
from models.make_prediction_data import make_prediction_input_data
from models.execute import execute_prediction
from models.draw_output import draw_45_plot, draw_summary_file
from dataclasses import dataclass
from typing import List
@dataclass(frozen=True)
class PredictionBatchOutput:
"""バッチ処理の出力データクラス
"""
list_45_figures: List[px.Figure]
summary_excel_path: str
def main(output_dir, db_engine):
"""アルゴリズムの実行関数
output_dir, 結果ファイルを出力するフォルダのパス
db_engine: データベースの接続情報
"""
# 問題設定
prediction_input_data = make_prediciton_input_data(db_engine)
# 問題解答
prediction_output_data = execute_prediction(prediction_input_data)
# 結果の可視化
list_45_figures = draw_45_plot(prediction_input_data, prediction_output_data)
excel_path = os.path.join(output_dir, "summary_file.xlsx")
draw_summary_file(excel_path, predition_input_data, prediction_output_data)
return PredictionBatchOutput(
list_45_figures=list_45_figures,
summary_excel_path=excel_path
)
全体のスクリプトを見て疎結合であることが伝われば、幸いです。問いの設定と解くためのモデルの作成と結果の可視化が3ステップで疎結合になっております。そのコミュニケーションツールとしてデータクラスが機能しているのです。このような分離を予め考えておけば、最初に述べた変更に強くなります。例えば、POSデータが増えたのであれば、1ステップ目の入力クラスの設計を変えれば良いですし、可視化の見方を変えたいのであれば、3ステップ目の可視化でdraw_hogehogeな関数を新たに1つ作成すれば良いだけです。また、強化学習で試してみたいのであれば、2ステップ目で強化学習で解くような関数を作成すれば良いでしょう。ただし、返り値は出力クラスで固定化されているため、可視化側になんの影響も与えません。めでたし。
今回は、Webアプリケーションの部分は書ききれなかったのですが、Webアプリケーションにするときは、最後のmain関数をアプリケーション側から、非同期にバッチ実行すれば良いだけです。非同期処理ができる実行ボタンを作成しても良いですし、crontabを使ってスケジュールバッチを組んでも良いと思います。そうすれば、毎朝9時に自動実行される予測アプリケーションが出来上がります。この辺は必ず非同期処理ができるアプリケーションのフレームワークを選ぶようにします。pythonならワーカーはCelery、ブローカーはRedisを使うのがおすすめです。また、このような設計にしておくことで、アプリケーション側のボタンから実行しなくとも、デバッグ用にスクリプト実行してモデルの動きを試すこともできます。アプリケーション側との分離もできます。アプリケーション側に結果を返す場合は、mainの返り値にまた別のデータクラスを定義すれば良いだけ(上記のPredictionBatchOutput)です。こうすることでアプリケーションとアルゴリズムを疎結合にできます。
まとめ
いかがだったでしょうか?データサイエンティストのスキルセットからはじまり、アプリケーションにインプリメントするまでをざっとですが、解説してみました。この辺は、人によって考え方が違うことがあることは十分わかっていますが、このやり方を使うと例えば、外部のワークフローツールなるものを使わずともpython+SQLだけで、アルゴリズムとアプリケーションをミックスした疎結合な開発ができます。何より、1つのリポジトリでアプリケーションとアルゴリズムが管理できる点はとても良いです。今回はアプリケーションの部分はあまり解説しませんでしたが、また機会があれば、Webアプリケーションのフレームワークと今回のアルゴリズムフレームワークを結合させる解説もしたいと思います。
それでは、2023年はデータサイエンティストがデータクラスを使いこなせることを願って、よいお年を!