下の記事をざっくり読んでみたメモ。
-
Google Cloudは、Google自身がYouTubeやDriveやGmailに用いているのと同じストレージ基盤を用いている。
-
基盤となっているストレージシステムはColossusと呼ばれており、これがGoogleの幅広いストレージサービス群を支えている。Cloud StorageやFirestoreだけでなく、トランザクション処理、データ提供、解析、アーカイブ、ブートディスク、ホームディレクトリなどすべてが、Colossusに支えられている。
Google Cloudがスケールできるのは、Googleがスケールするから
Googleのすべては、一連の共通のスケーラブルなサービスの上に構築されている。このサービスには3つの主要な構成要素があり、それぞれのストレージサービスはこれらを使って構成されている。
-
Colossus: クラスタレベルファイルシステム。Google File System (GFS)の後継。
-
Spanner: グローバルに整合性を維持する関係データベース
-
Borg: スケーラブルなジョブスケジューラ。計算資源もストレージ資源もすべてこれが立ち上げる。Kubernetesの設計と開発に大きな影響を、昔から現在に至るまで与えている。
これら3つの構成要素が、すべてのGoogle Cloudストレージサービスの基盤となっている。Borgが必要な資源をプロビジョニングし、Spannerがアクセス権限やデータの位置を保持し、Colossuがすべてのデータを管理し、保持し、アクセス可能にする。
Colossus の概要
-
GFSの次世代版である。
-
増え続けるアプリケーションからのデータに対する要請に答えるため、ストレージのスケーラビリティを向上させ、可用性を改善するように設計されている。
-
Colossusは分散メタデータモデルを導入した。これにより、よりスケーラブルで可用性の高いメタデータシステムが実現された。
全体としてはどう動くのだろうか?このような多様な用途を一つのファイルシステムで支えられるのだろうか?下図に、Colossusの制御プレーンの主要な構成要素を示す。
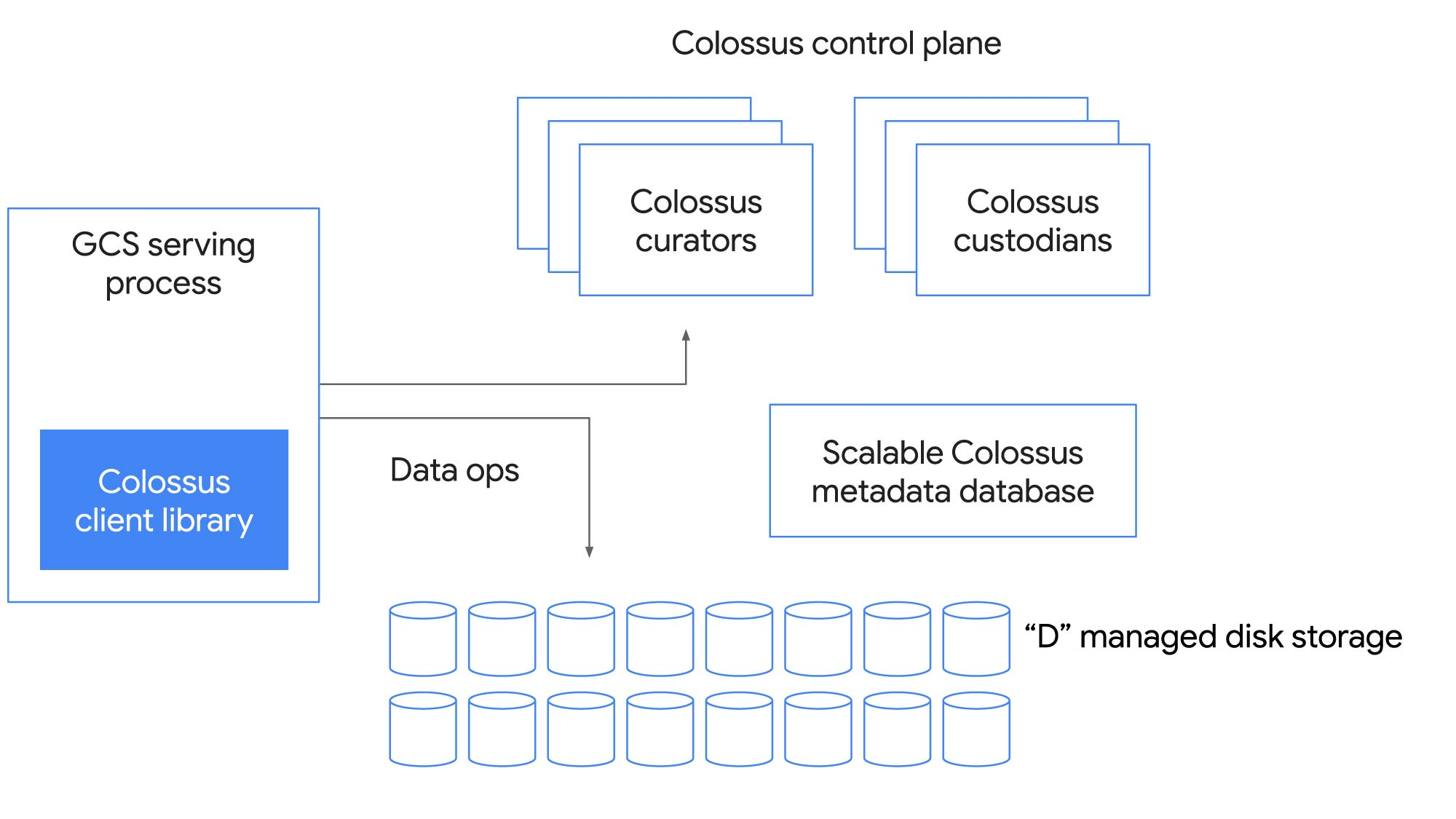
Client ライブラリ
最も複雑な部品。ソフトウェアRAIDもこのレイヤで実装される。ワークロードごとに性能とコストのトレードオフをとるために、さまざまなエンコーディングが用いられる。
Colossus 制御プレーン
メタデータサービスは、多数のCuratorで構成される。ClientはCuratorに直接アクセスしてファイル作成などの制御操作を行う。水平にスケールする。
メタデータデータベース
Curatorは、Googleの高性能NoSQL DBであるBigTableにファイルシステムのメタデータを書きこむ。Colossusが作られたのはGFSでは、検索に関連したメタデータアクセスの性能に限界があったから。メタデータをBigTableで管理することで、最大のGFSクラスタよりもさらに100倍以上の規模にスケールできるようになった。
D ファイルサーバ
データホップを最小化するために、クライアントと"D"ファイルサーバ(ネットワークディスク)が通信する。
Custodians
バックグラウンドストレージマネージャ。耐久性と可用性、全体の効率性を維持する。ディスクスペースの均等化やRAIDの再構成などを司る。
Colossusはどのようにして、安定したスケーラブルなストレージを実現しているか
Cloud StorageからColossusを使う様子を見てみよう。
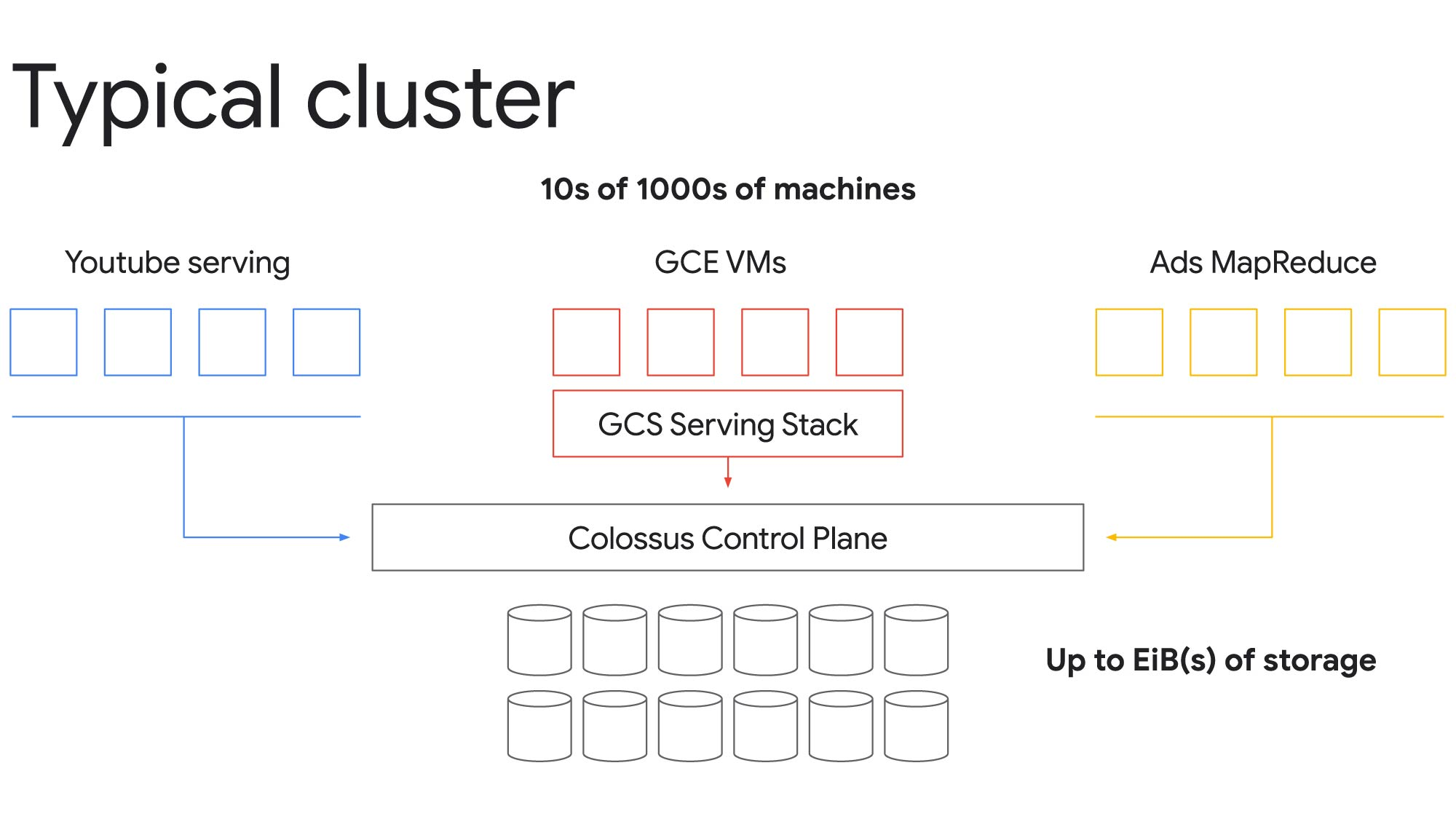
Colossusを使うと、一つのクラスタで数万の計算機と数エクサバイトものストレージにまでスケールできる。上の例では、Compute Engine VMのアクセスするCloudStorage, YouTube, 広告のためのMapReduceノードが単一のファイルシステムを利用している。重要なのは、Colossusの制御ブレーンが、ここのアプリに対して、独立したファイルシステムを提供している家のように見せていることだ。
このように資源を集約しないことで(Disaggregation ここ逆じゃないのか?)価値ある資源の効率的な利用が可能になり、個々のワークロードのコストを低減することができる。YouTubeビデオのような低レイテンシワークロードのピーク需要を満たしつつ、バックグラウンドで解析ワークロードを実行できる。
Colossusには以下のようなメリットも有る。
ハードウェアの複雑さを簡潔にする。
Googleデータセンターには様々な種類のストレージがある。アプリケーションの要求もさまざまだ。Colossusにはさまざまなサービスティアが用意されている。アプリケーションは、I/O、可用性、耐久性を指定して適切なティアを利用する。
Googleのようなスケールではハードウェアは常に壊れ続ける。信頼性が低いせいではなくただただ数が多いからだ。障害は運用の一部なのでファイルシステムが耐故障性を持ち、透過的にリカバできることが重要だ。Colossusは障害時のアクセスを処理し、高速なバックグラウンドリカバリを実現する。
ストレージの効率性の最大化
オーバプロビジョニングせずに、必要なときにストレージを提供するには魔法が必要だと思うかもしれない。Colossusは様々なアプリのアクセスパターンや頻度が多様であることを利用して、フラッシュとHDDの混成で対応している。
ホットなデータはフラッシュに置く。HDDは十分なだけ買っておく。適切に混成することで、効率を最大化する。
ディスクストレージに関しても常にビジーにしておきたい。このために、Colossusは新しく書かれたデータ(ホットなデータ)をすべてのディスクに書き込む。その後、データが古く、コールド担ってきたら、大容量のディスクに移す。解析タスクにはこの方法が非常に適している。
大規模にスケールすることが実践検証済み
Google Cloudをつかえば、Googleが使っているのと同じ基盤をつかうことができる。基盤の改良をGoogleが続けているので、ユーザは改良する必要がない。
Google Cloudのストレージアーキテクチャについてもっと知りたければ2020年のセッションビデオ[A peek at the Google Storage infrastructure behind the VM]
(https://www.youtube.com/watch?v=q4WC_6SzBz4)や、
[cloud storage website]
(https://cloud.google.com/products/storage)を見てほしい。
所感
Dファイルサーバとはなんぞ。FPGAかなんかで作った最低限のコントローラの先にディスクがぶら下がってるのかな?そもそもIPつかってんのかな。
BigTableが使われているのは意外だった。BigTableはたしかGFS上に構築されていたとおもうのだけど、その部分だけ小規模なGFSがあったりするんだろうか。