
最近、日本の政界も色々騒ぎがありますが、それを受けてTwitterでは安倍首相に関してどんなことが話題になっているのか気になるところです。そこで今日は安倍首相に言及しているTweetデータを使ってテキスト分析してみようと思います。
ここで一つチャレンジなのは、日本語のテキスト分析になると、英語などの言語と違い、単語と単語の間にスペースがないので、単語化(トークナイズ)するのが難しいという点です。Exploratoryでは5.5.3というバージョンから日本語の単語化(トークナイズ)をMeCabなど外部のソフトウェアをインストールしなくてもできるようになりました。
安倍首相に言及しているTweetをTwitterからインポートする。
それではまず、安倍首相に言及しているTweetをTwitterからインポートしましょう。
Tweetをインポート
プロジェクトを開き、画面左側のデータフレームの隣にあるプラスボタンをクリックして、クラウドアプリケーションデータを選択します。
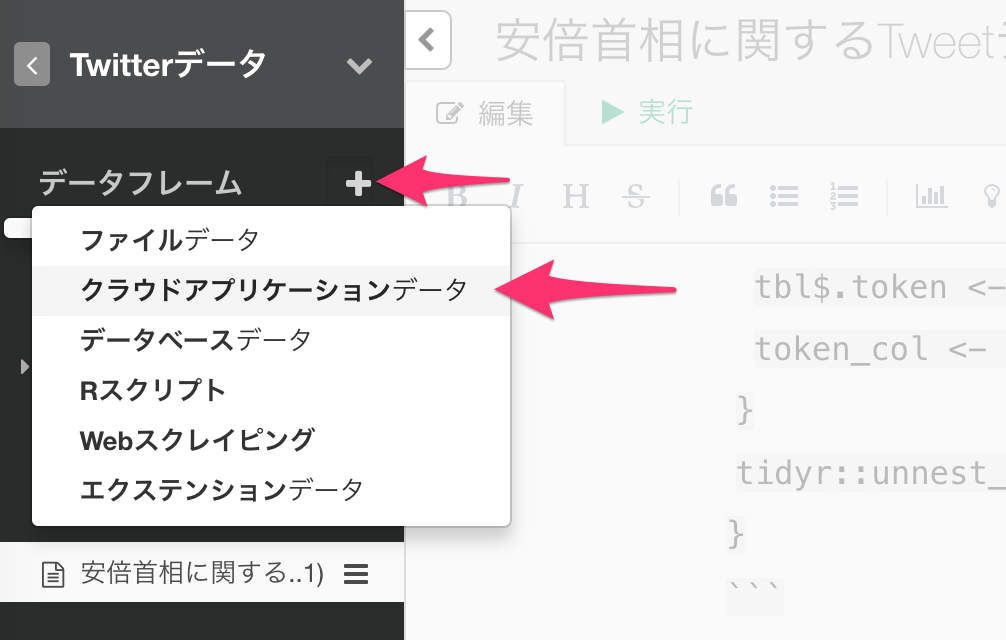
Twitter Searchをリストから選択します。
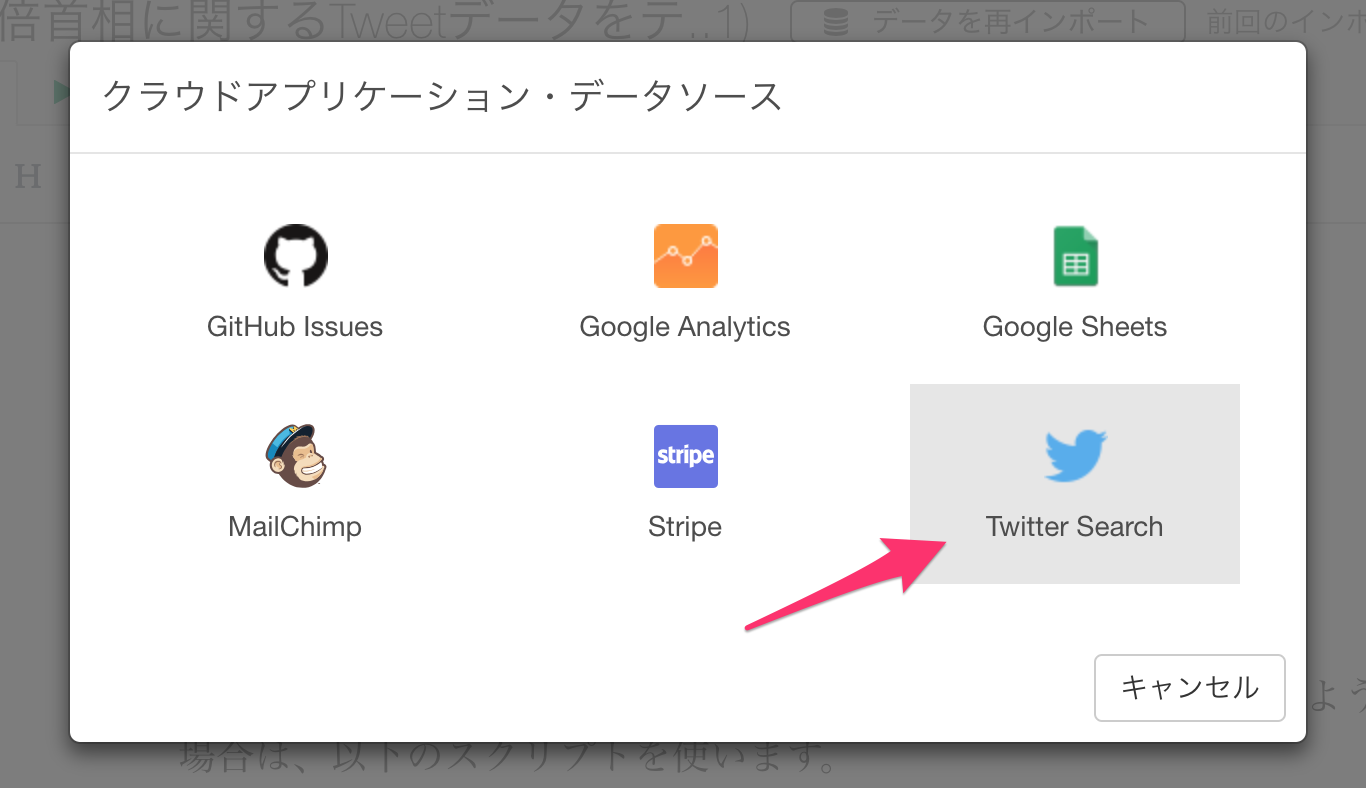
インポートのダイアログで以下のパラメーターを指定します。
- 言語:日本語
- 直近N日間:7
- リツイートを含む:いいえ
- センチメントを計算する:いいえ
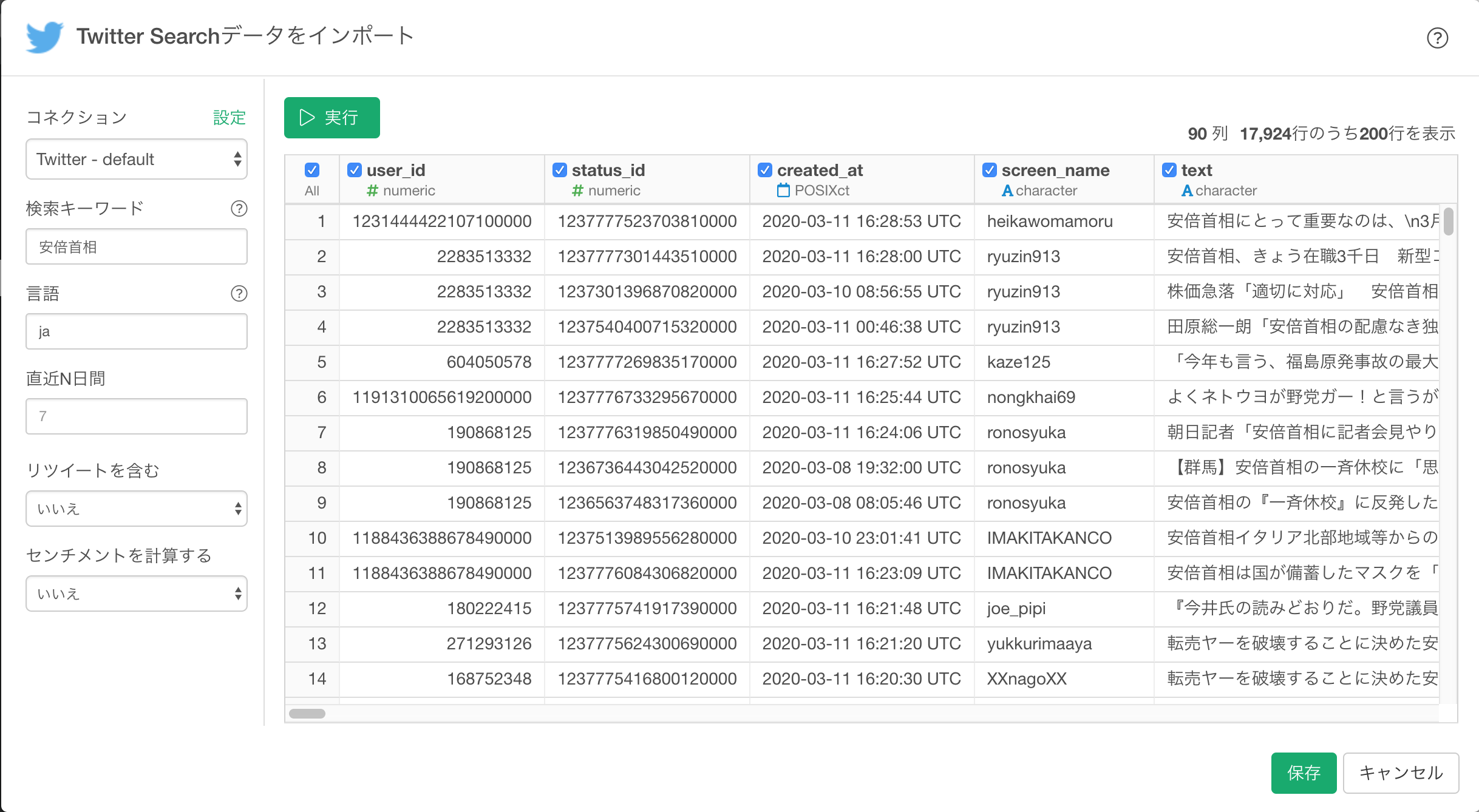
実行 ボタンをクリックします。無事Tweetが表示されたら、次に 保存 ボタンをクリックします。
安倍首相に関するTweetがインポートできました。
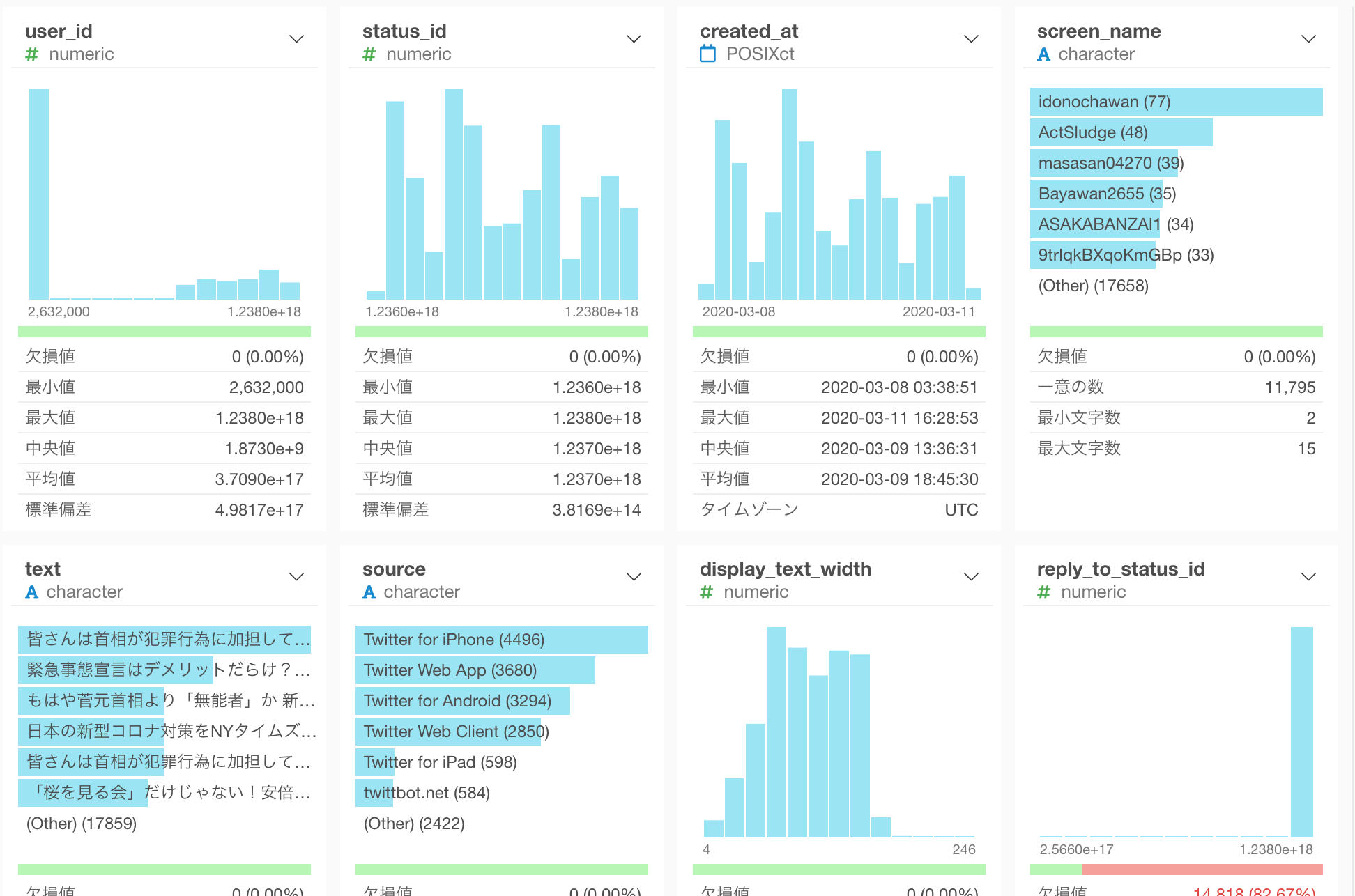
テキスト分析をする
では早速Tweetデータを分析してみましょう。
データ数を絞る
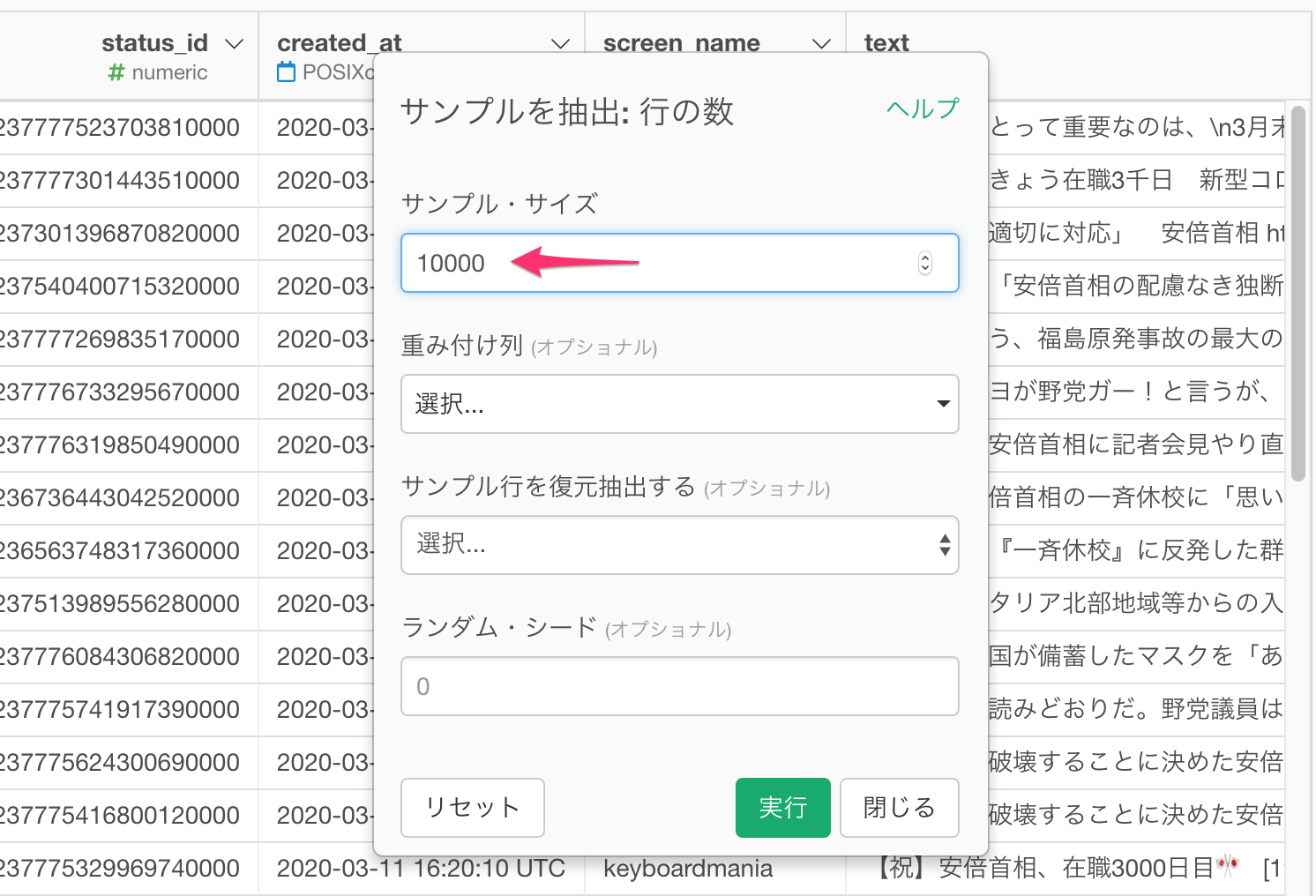
取得したTweet数が多い場合、処理が終わらないことがありますので、まずは10,000件に行数を絞ってみましょう。
画面右側の上にあるプラスボタンを押すと、メニューが出て来るのでサンプルを抽出を選び、行の数を選択します。
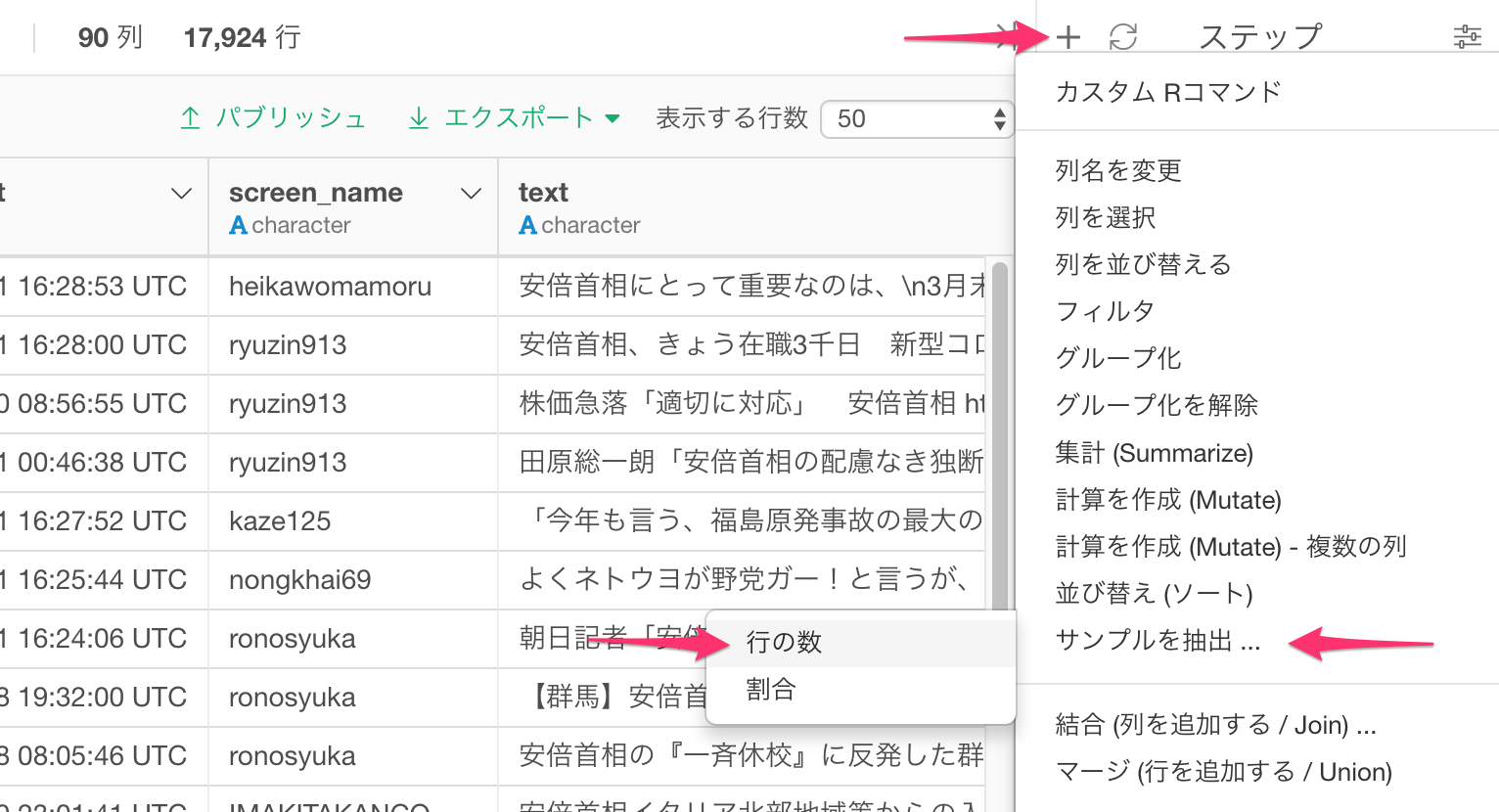
サンプル・サイズを10000にします。
単語化(トークナイズ)する
text列の列ヘッダーメニューより、テキストデータの加工(UI) -> 文章の単語化 (日本語) を選択します。
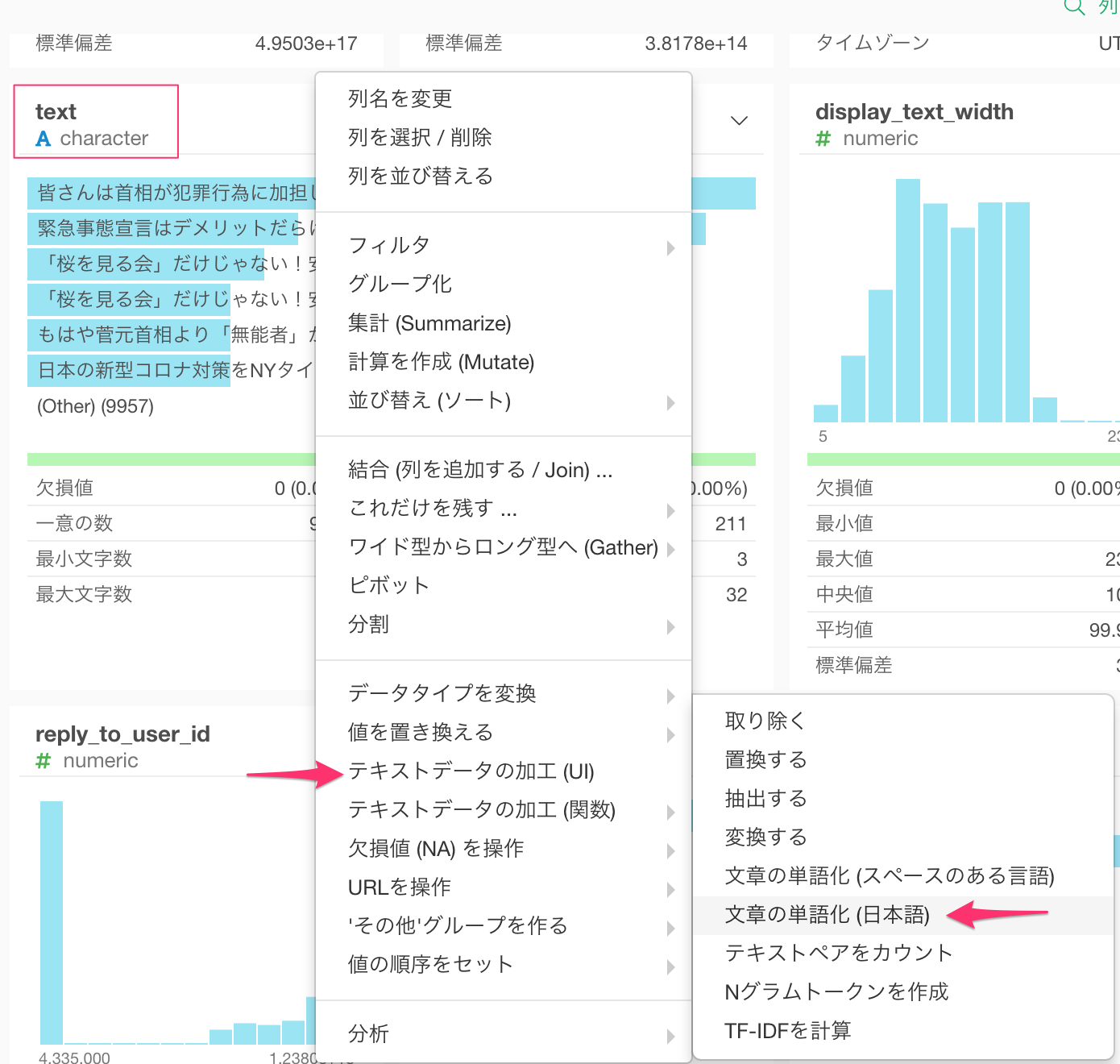
すると次のようなダイアログが開きます。
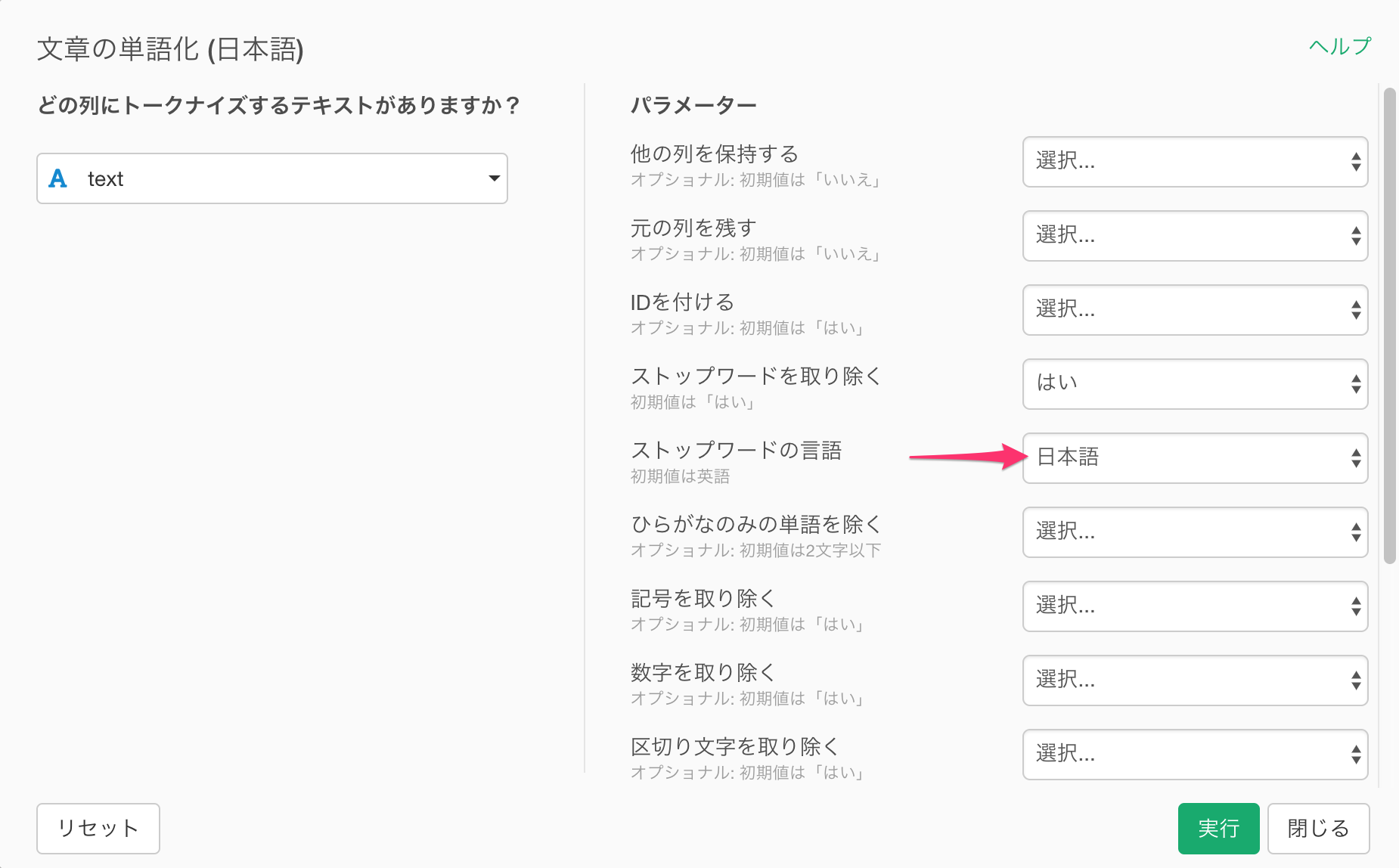
ストップ・ワード(stopwords)を取り除く
単語化する際に、問題となるのは、あまりに一般的な「は」「の」「です」などのストップワードが含まれてしまうことです。このダイアログの右側にあるストップワードの言語で「日本語」を選択し、こうした日本語のストップワードを取り除いた形で単語化します。 実行ボタンをクリックします。
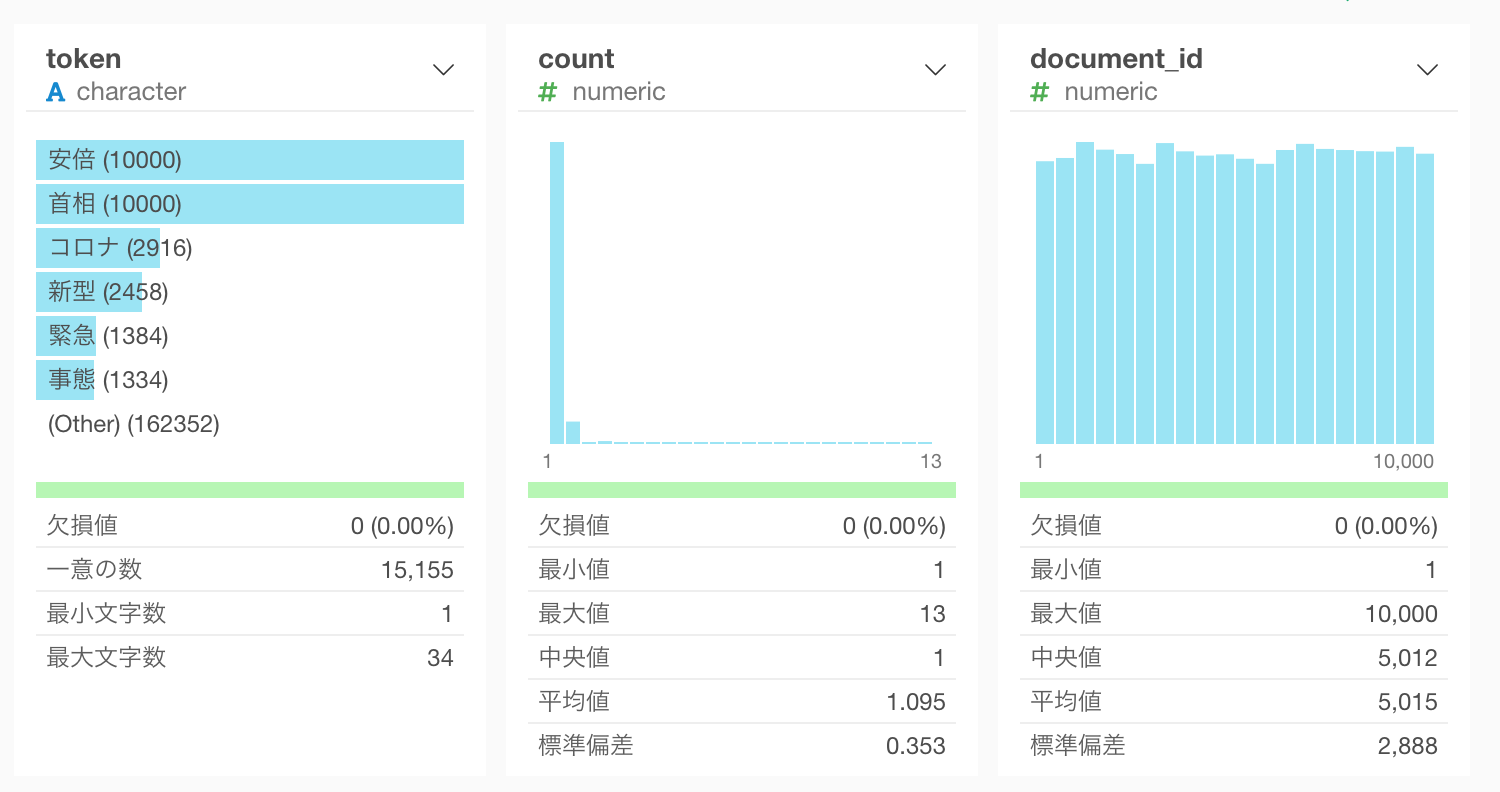
するとこのように、tweet毎に単語化されたデータがtokenという列に入っているのが分かります。
さらに不要なデータを取り除く
安倍や首相と言った単語は自明すぎるので、フィルタを使って取り除きます。これには
どれにも等しくないというフィルタの条件が使えます。
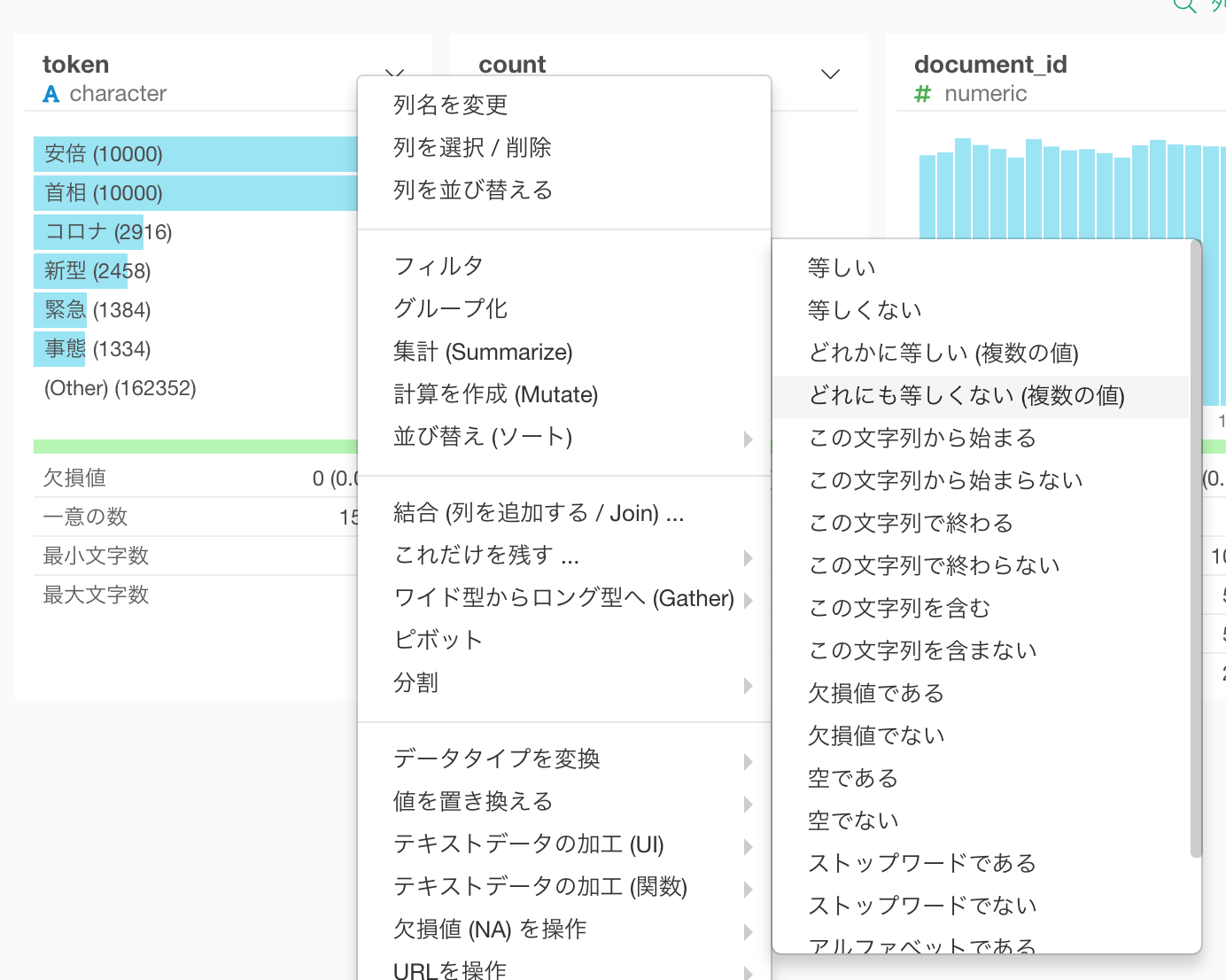
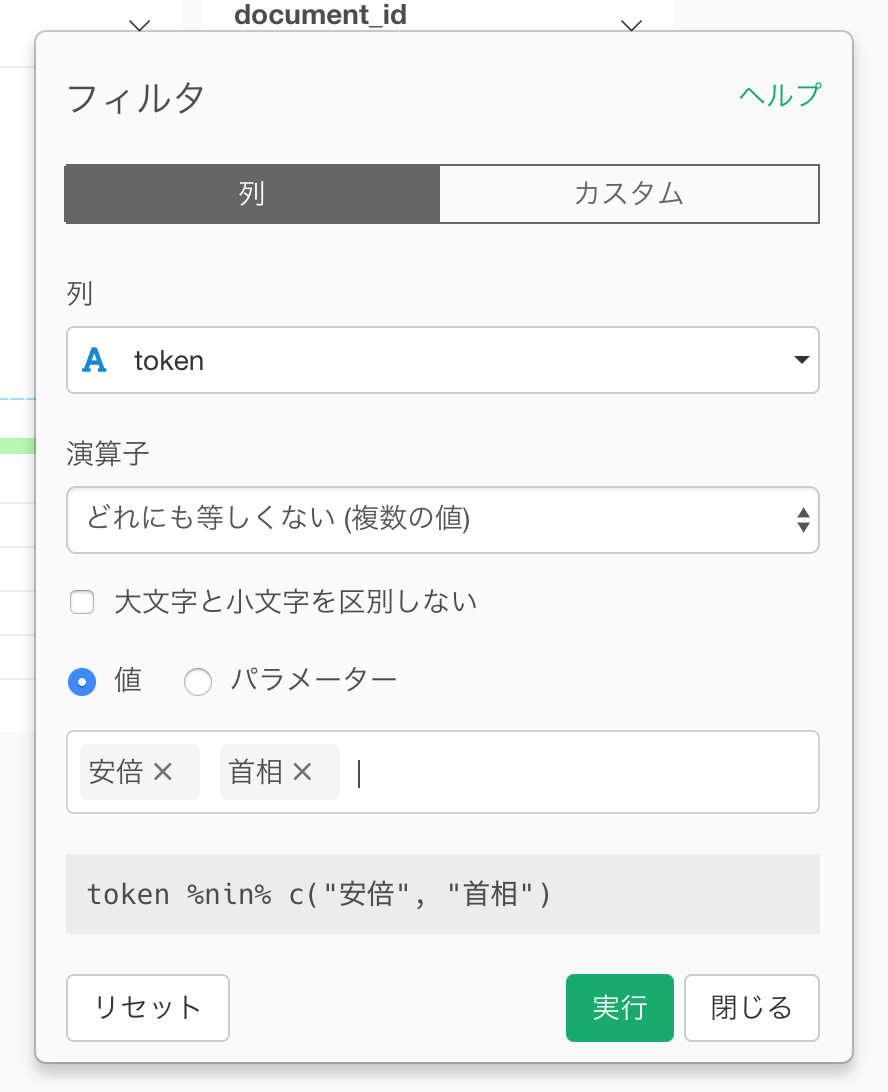
すると次のようなフィルタのダイアログが表示されるので、安倍と首相を選択します。
これで不要な単語を取り除くことができました。
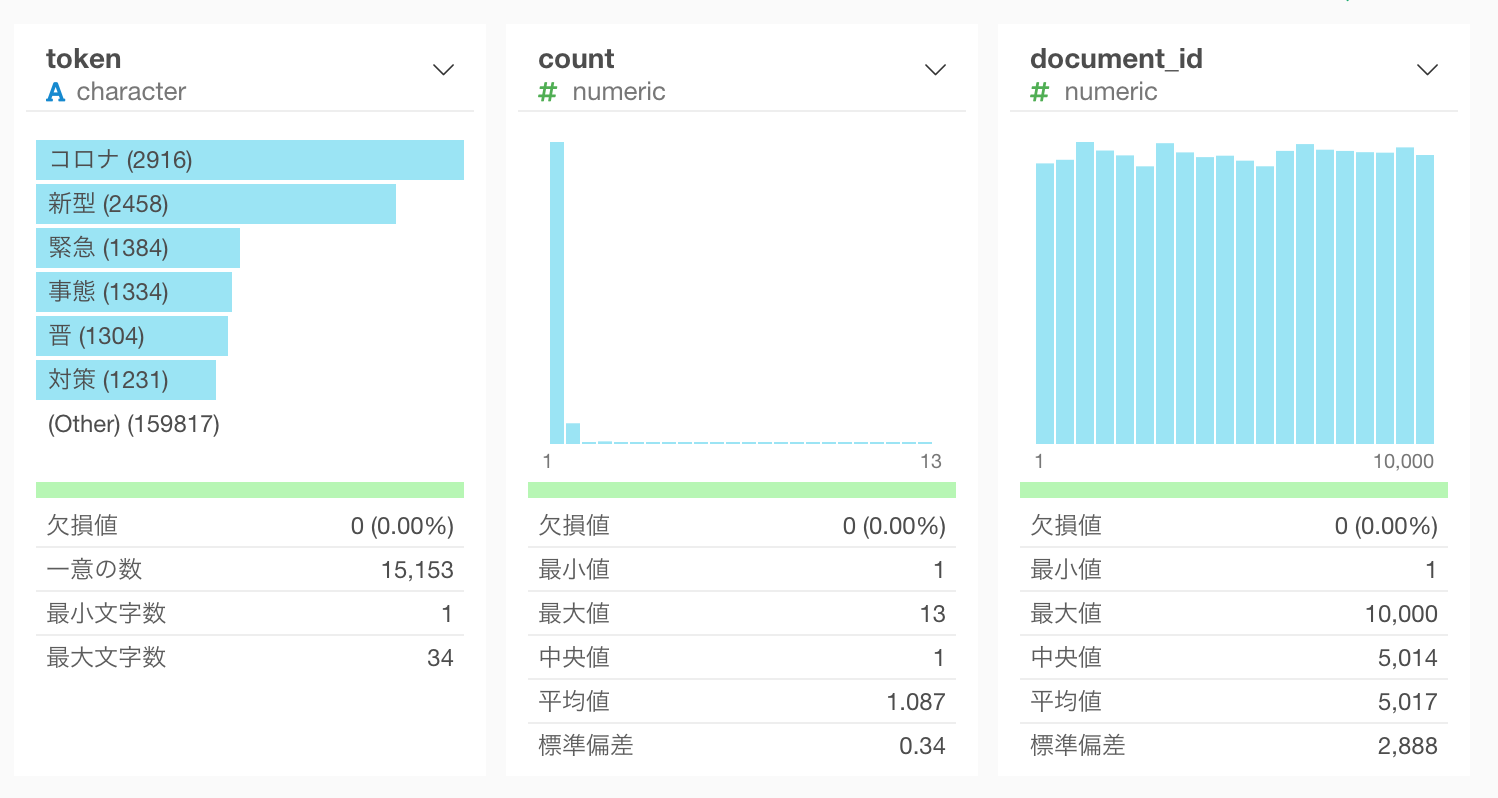
頻出単語を調べる
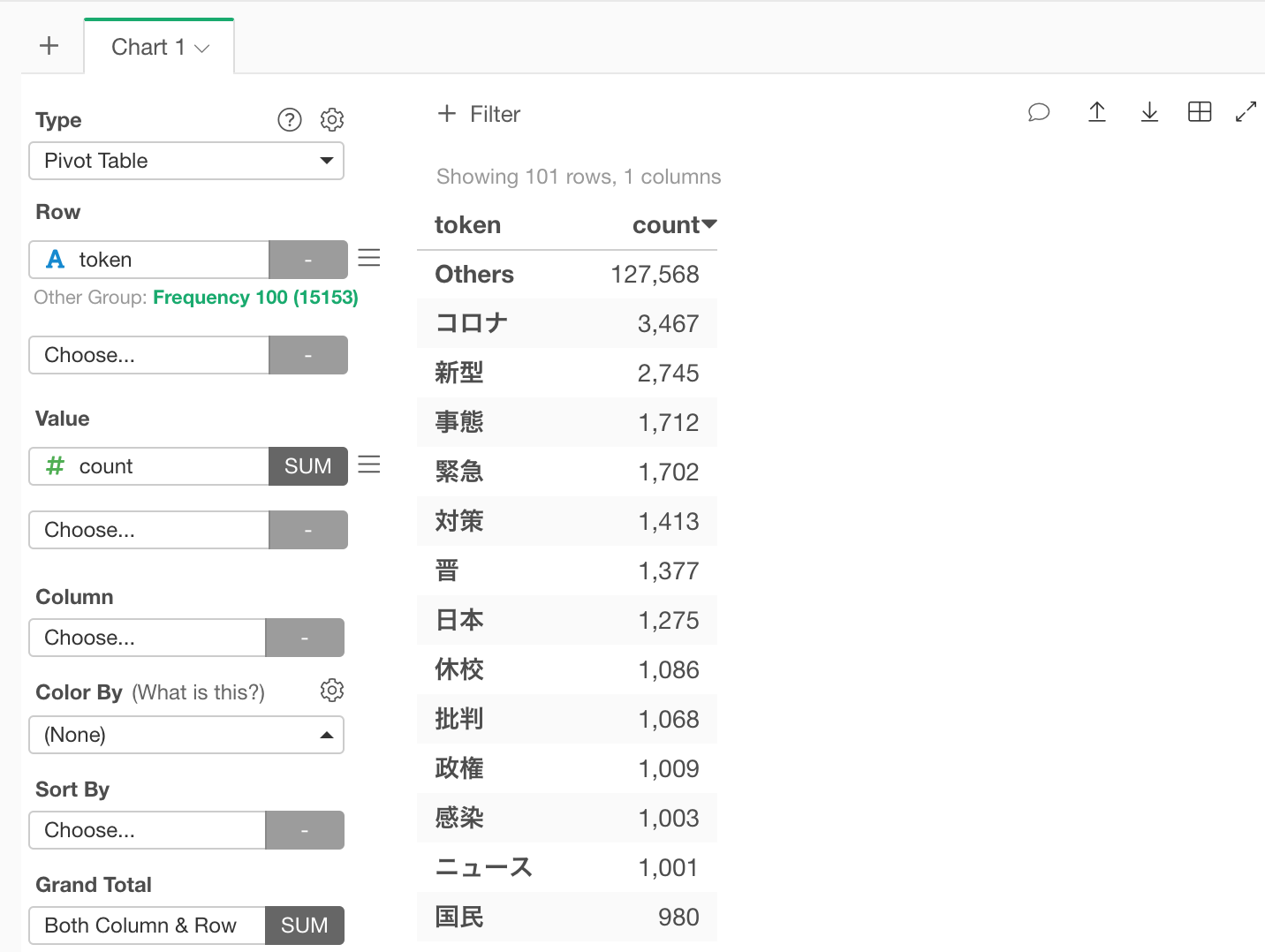
それではまず、最もよく頻出している単語を見てみましょう。チャートのビューに行って、ピボットテーブルを作ります。行にtoken列を割り当てて、値にcount列を割り当てます。count列をクリックして多い順にソートすると、コロナ、新型、事態などの単語が多く使われていることがわかります。(この記事は2020年3月11日時点のデータを使っています。)
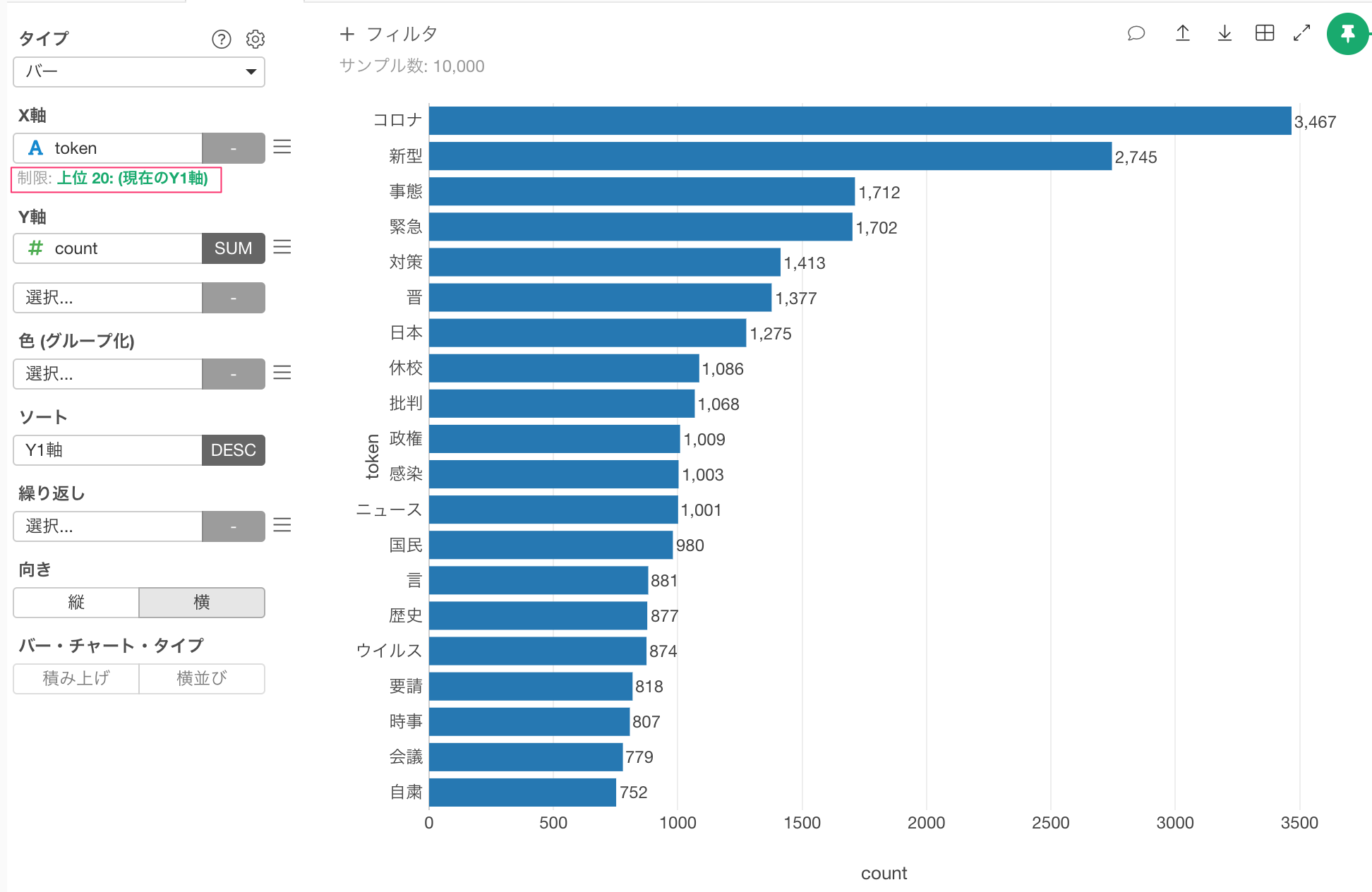
バーチャートで同じく頻出順に上位20を並べると、次のようになります。
ワードクラウド
上記のような頻出単語のようなテキストをもっと見やすくするために使われる可視化の手法として、ワードクラウドというのがあります。Exploratoryではチャートの一つとしてサポートしております。新規にチャートを追加し、タイプにワード・クラウド、単語にtoken列を指定し、色に分割にcountを指定します。
出力結果は以下のようになります。コロナ、新型といった頻出回数の多い単語が大きめのフォントサイズで表示されていることが確認できます。

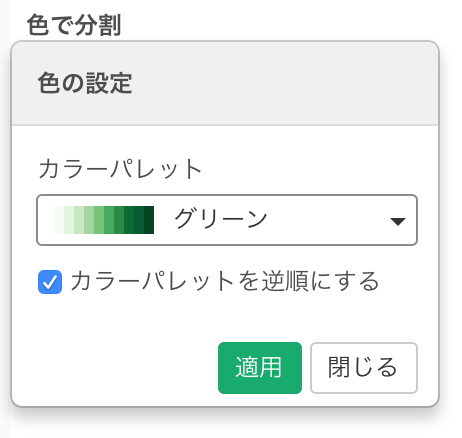
色を変えたいときは、色で分割のメニューからカラーパレットを変えることもできます。
例えば、緑色の濃淡で表現したい場合は、以下のように設定します。濃い色をより頻度の高い単語に割り当てるにはカラーパレットを逆順にするにチェックを入れます。
また、ある程度以上の頻度の単語を表示させたり、横向にしたい単語の割合を設定することもできます。
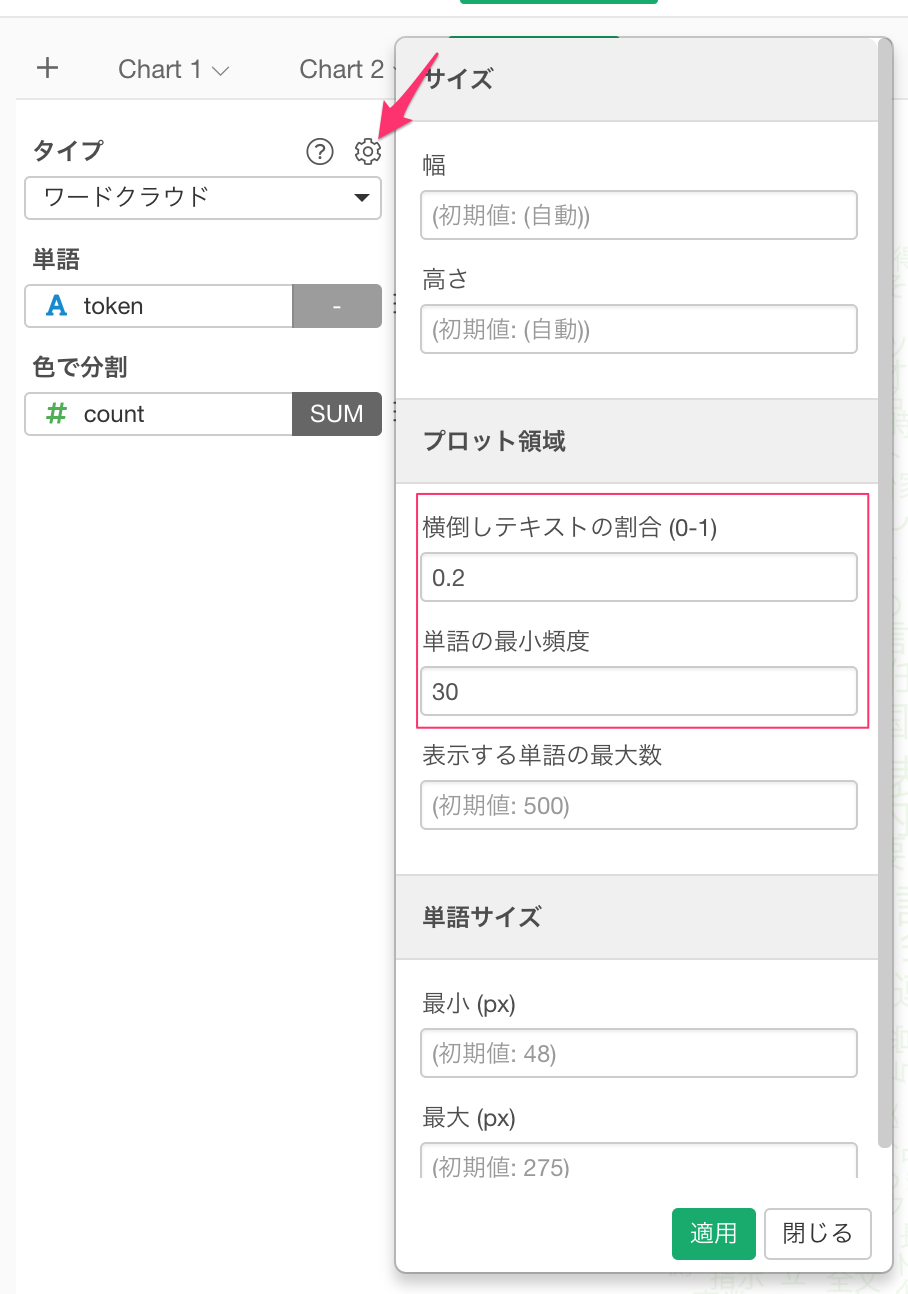
すると、表示結果が以下のように変わります。

長くなってきたのでは、Part 1はここまでにして、Part 2ではトークンからNグラムを作成し、TF-IDF、クラスタリングとさらにテキスト分析をしてみます。
まとめ
今日はTwitterから安倍首相に言及されたTweetをインポートし、日本語を単語化(トークナイズ)して、ストップ・ワード等を取り除き、頻出する単語が何かを確認するところまで見てきました。
まだExploratory Desktopをお持ちでない場合は、こちらから30日間無料でお試しいただけます。
データサイエンスを本格的に学んでみたいという方へ
Exploratory社がシリコンバレーで行っているトレーニングプログラムを日本向けにした、データサイエンス・ブートキャンプを定期的に東京で行っております。データサイエンスの手法を基礎から体系的に、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に、参加を検討してみてください。