初投稿です。色々と未熟者ですがよろしくお願いいたします。
今回は、乃木坂46の公式ブログから各メンバーの特徴語を抽出してみました。
結果だけ見たい方は、こちらへどうぞ
[python]乃木坂公式ブログから乃木坂メンバーの特徴語を抽出してみた[全メンバーの結果まとめ]
なぜブログから特徴語を抽出しようと思ったのか
3期生の佐藤楓ちゃんのブログを見ていた時、彼女がポケモンファンだということを初めて知りました。
そこで、ブログには乃木坂工事中を見たりライブに行くだけは知ることのできない情報があり、ブログから特徴語を抽出できれば、短時間で各メンバーの趣味や興味を知ることが出来るのではと考え、今回の記事を書くことになりました。
ちなみに推しは伊藤理々杏さんです。日向坂46だと小坂菜緒さんです。
↓きっかけになった記事
イーブイが現実世界にいたらなあ、5匹くらい飼てたなあ 80.
開発
開発環境
windows10(windowsなら10が必須)
python3.6.5
beautifulsoup4 4.6.1
mecab-python-windows 0.996.1
macのほうが楽です。
流れ
今回の流れですが、
- ブログから全メンバーの全記事をスクレイピング
- 記事を形態素解析し固有名詞を抽出
- 固有名詞のTF-IDF計算
以上の流れで進めていきます。
1. ブログから全メンバーの全記事をスクレイピング
全メンバーの全記事をスクレイピングしていきます。
スクレイピングの方法については以下を参考にするといいと思います。
Python による Web スクレイピングにようこそ! — Python で行う Web Scraping ドキュメント
始めに、乃木坂ブログのトップページから全メンバーのページに遷移出来そうか、ページのHTMLを観察してみます。
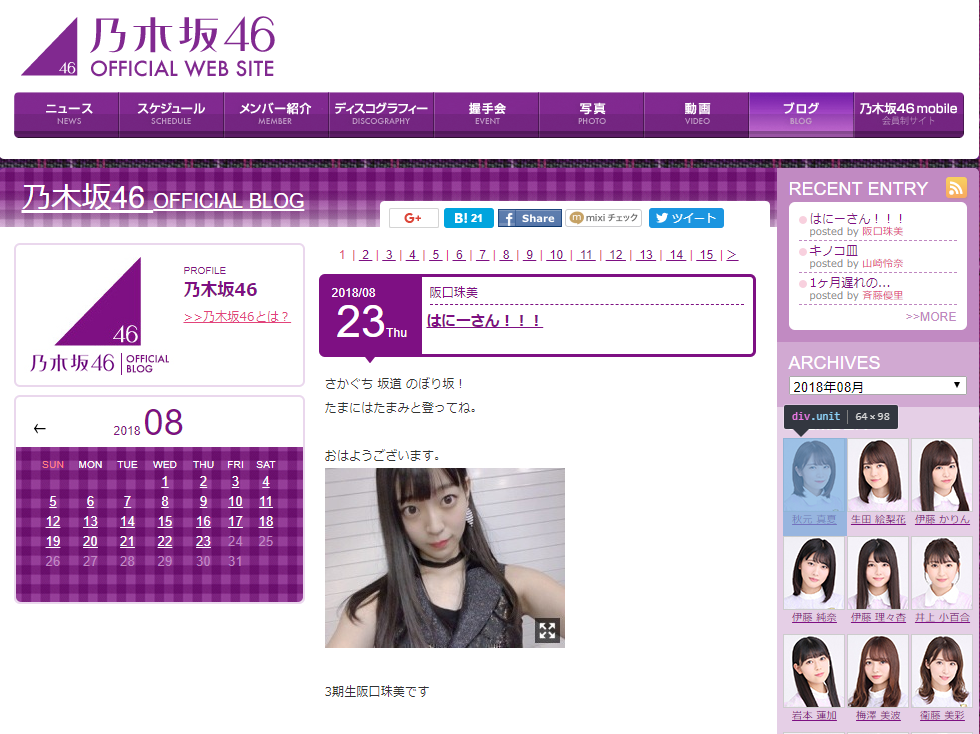
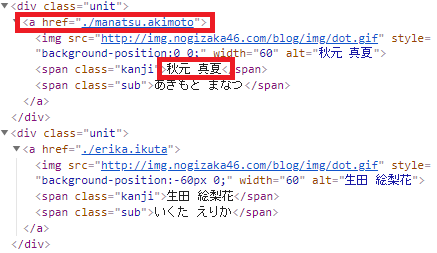
divタグのunitクラス内から、各メンバーのブログURLとメンバーの名前を抽出できそうです。
URLと名前を抽出するコードは以下のようになります。
import requests
from bs4 import BeautifulSoup
import re
# User-Agentの偽装
headers = {'User-Agent':'Mozilla/5.0'}
# 全メンバーの記事を取得
top_url = "http://blog.nogizaka46.com/" #トップページ
bs = BeautifulSoup(requests.get(top_url,headers=headers).content,'html.parser')
members=bs.select('div.unit')
for member in members:
name=member.select_one('span.kanji').text
print(name)
blog_url=top_url+member.select_one('a').attrs["href"]
print(blog_url)
出力は以下のようになります。
秋元 真夏
http://blog.nogizaka46.com/./manatsu.akimoto
生田 絵梨花
http://blog.nogizaka46.com/./erika.ikuta
伊藤 かりん
http://blog.nogizaka46.com/./karin.itou
伊藤 純奈
http://blog.nogizaka46.com/./junna.itou
伊藤 理々杏
http://blog.nogizaka46.com/./riria.itou
井上 小百合
http://blog.nogizaka46.com/./sayuri.inoue
岩本 蓮加
http://blog.nogizaka46.com/./renka.iwamoto
梅澤 美波
http://blog.nogizaka46.com/./minami.umezawa
衛藤 美彩
http://blog.nogizaka46.com/./misa.eto
大園 桃子
http://blog.nogizaka46.com/./momoko.oozono
川後 陽菜
http://blog.nogizaka46.com/./hina.kawago
北野 日奈子
http://blog.nogizaka46.com/./hinako.kitano
久保 史緒里
http://blog.nogizaka46.com/./shiori.kubo
齋藤 飛鳥
http://blog.nogizaka46.com/./asuka.saito
斉藤 優里
http://blog.nogizaka46.com/./yuuri.saito
阪口 珠美
http://blog.nogizaka46.com/./tamami.sakaguchi
桜井 玲香
http://blog.nogizaka46.com/./reika.sakurai
佐々木 琴子
http://blog.nogizaka46.com/./kotoko.sasaki
佐藤 楓
http://blog.nogizaka46.com/./kaede.satou
白石 麻衣
http://blog.nogizaka46.com/./mai.shiraishi
新内 眞衣
http://blog.nogizaka46.com/./mai.shinuchi
鈴木 絢音
http://blog.nogizaka46.com/./ayane.suzuki
高山 一実
http://blog.nogizaka46.com/./kazumi.takayama
寺田 蘭世
http://blog.nogizaka46.com/./ranze.terada
中田 花奈
http://blog.nogizaka46.com/./kana.nakada
中村 麗乃
http://blog.nogizaka46.com/./reno.nakamura
西野 七瀬
http://blog.nogizaka46.com/./nanase.nishino
能條 愛未
http://blog.nogizaka46.com/./ami.noujo
樋口 日奈
http://blog.nogizaka46.com/./hina.higuchi
星野 みなみ
http://blog.nogizaka46.com/./minami.hoshino
堀 未央奈
http://blog.nogizaka46.com/./miona.hori
松村 沙友理
http://blog.nogizaka46.com/./sayuri.matsumura
向井 葉月
http://blog.nogizaka46.com/./hazuki.mukai
山崎 怜奈
http://blog.nogizaka46.com/./rena.yamazaki
山下 美月
http://blog.nogizaka46.com/./mizuki.yamashita
吉田 綾乃 クリスティー
http://blog.nogizaka46.com/./ayanochristie.yoshida
与田 祐希
http://blog.nogizaka46.com/./yuuki.yoda
若月 佑美
http://blog.nogizaka46.com/./yumi.wakatsuki
渡辺 みり愛
http://blog.nogizaka46.com/./miria.watanabe
和田 まあや
http://blog.nogizaka46.com/./maaya.wada
URLを取得できれば、各メンバーのブログのページに遷移し、全ブログを収集できそうです。
次に、ページ遷移した後の本文抽出について考えていきます。
各メンバーのブログページを確認したところ、1つのページに5記事掲載され、それが複数のページにわたって存在するみたいです。
(説明が下手でごめんなさい。よかったら自分の目で確認してみてください。)
乃木坂46 伊藤理々杏 公式ブログ
ブログのHTMLを観察していきます。
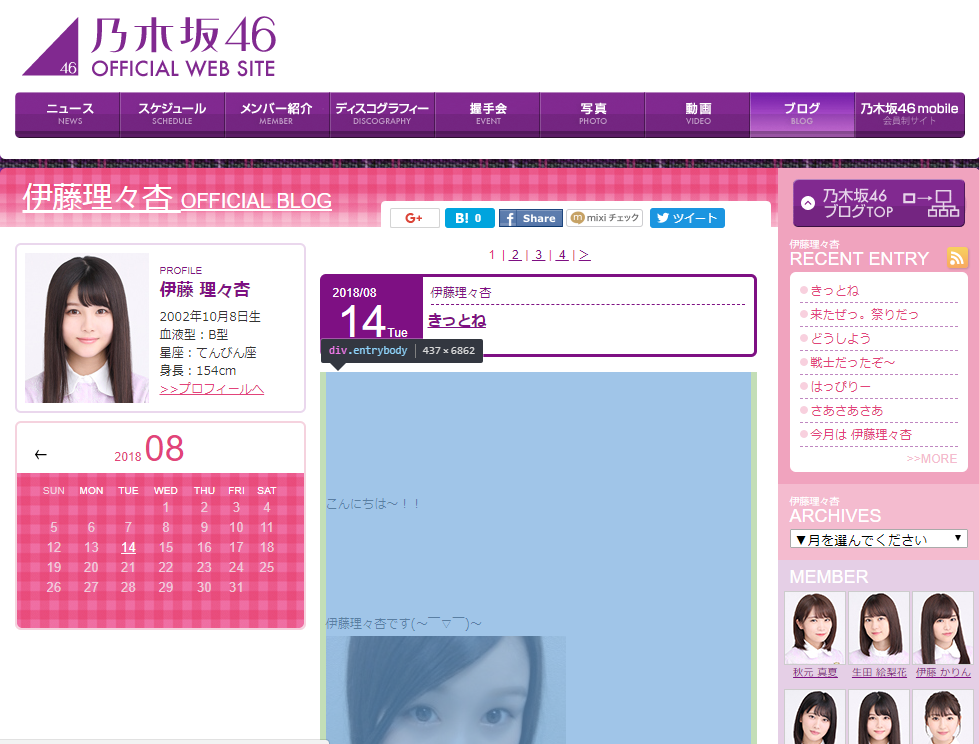
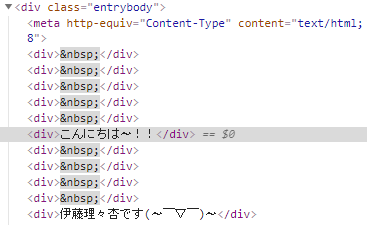
どうやらdivタグのentrybodyクラスからテキストを抽出できれば、本文を抽出できそうです。
先ほど載せたコードと合わせて、全メンバーの全ブログをデータベースに保存するコードを載せます。めちゃくちゃなコードですがお許しください。
import requests
from bs4 import BeautifulSoup
import re
import sqlite3
from contextlib import closing
# User-Agentの偽装
headers = {'User-Agent':'Mozilla/5.0'}
dbname = 'Nogizaka.db' #DB名
with closing(sqlite3.connect(dbname)) as conn:
c = conn.cursor()
#メンバー一覧テーブル作成
create_sql = 'create table member_tbl (member_id int, member_name text,blogs_num int)'
c.execute(create_sql)
#ブログ一覧テーブル作成
create_sql = 'create table blog_tbl (blog_id int,member_id int, blog_title text, blog_content text)'
c.execute(create_sql)
#全メンバーの記事を取得
top_url = "http://blog.nogizaka46.com/" #トップページ
bs = BeautifulSoup(requests.get(top_url,headers=headers).content,'html.parser')
members=bs.select('div.unit')
member_id=1
for member in members:
#メンバーの名前を一人取得
name=member.select_one('span.kanji').text
# メンバー一覧テーブルにメンバーを追加
insert_sql = 'insert into member_tbl (member_id,member_name) values (?,?)'
member_info = (member_id,name)
c.execute(insert_sql, member_info)
conn.commit()
blog_url=top_url+member.select_one('a').attrs["href"]
bs = BeautifulSoup(requests.get(blog_url, headers=headers).content, 'html.parser')
ar_page = 1 # 現記事のページ数
while 1:
titles = bs.select('span.entrytitle') # 5記事文のタイトルを抽出
contents = bs.select('div.entrybody') # 5記事文の本文を抽出
# 1ページ5記事分
for ar in range(5):
blog_id=(ar_page - 1) * 5 + (ar + 1)
print(blog_id)
try:
title = titles[ar].select_one('a').text # 1記事文のタイトルを抽出
print(title)
content = contents[ar].text # 1記事文の本文抽出
content = re.sub('\n', "", content) # 改行を削除
# ブログ一覧テーブルにブログを追加
insert_sql = 'insert into blog_tbl (blog_id,member_id,blog_title,blog_content) values (?,?,?,?)'
blog_info = (blog_id,member_id,title,content)
c.execute(insert_sql, blog_info)
conn.commit()
except IndexError:
break
# 次のページurlを取得
next_urls = bs.select_one('div.paginate')
#1ページしかないメンバーの場合例外処理をする
try:
next_url_a = next_urls.select('a')
if ar_page == 1:
next_url = blog_url + next_url_a[0].attrs["href"]
else:
try:
next_url = blog_url + next_url_a[ar_page].attrs["href"]
except IndexError:
break
bs = BeautifulSoup(requests.get(next_url, headers=headers).content, 'html.parser')
ar_page += 1
except AttributeError:
break
update_sql='update member_tbl set blogs_num=? where member_id=?'
c.execute(update_sql,[blog_id,member_id])
conn.commit()
member_id+=1
抽出した結果の一部は以下のようになります。
これで、全メンバーのブログを取得できました。
2. 記事を形態素解析し固有名詞を抽出
次に、ブログの本文を形態素解析を行い固有名詞を抽出します。
形態素解析とは、文書を品詞ごとに分解する作業です。
今回は、オープンソースの形態素解析エンジンMeCabをpython上で使用し、固有名詞を抽出していきます。
また、辞書としてmecab-ipadic-NEologdを用いることで新語に対応できるようにします。
↓windowsの環境設定で参考になったサイト
PythonとMeCabで形態素解析(on Windows)
windows 10 64bit で python + mecab
Windowsでmecab-ipadic-NEologdの導入
固有名詞抽出のサンプルコードを載せます。
import MeCab
tagger = MeCab.Tagger(r" -d C:\Users\(ユーザー名)\mecab-ipadic-neologd\build\mecab-ipadic-2.7.0-20070801-neologd-20180723")
content='みなさんこんばんはヽ(。・ω・。)ノ写真がたまってたまってどうしようなのでまた更新しちゃいます♪この前の隅田川花火大会めちゃくちゃ綺麗すぎました〜!!いくちゃんと素で楽しんでしまった♡いくちゃんは私の100倍くらい素だったけどね笑花火を見たいっていう今年の夏の目標がとても豪華な形で達成できて幸せでした♪この前もあったんだけど未だによくやっちゃう東京の電車の乗り換えミス笑中1から乗ってるからたぶんかれこれ13年くらい電車使ってるのになんで覚えられないんだろ〜(>_<)トンチンカンってなかなか直らにゃい。笑お花が鮮やか♡8/6に放送の『人生を諦める技術』のMCを務めさせていただきますっ♪すごいタイトル!笑この前収録して来たんだけどなんだかかなりかなり珍しい形態で楽しかったのでぜひたくさんの方に見てもらいたいです♡ジコチューのMV撮影〜この前余り物を詰め込んで作った餃子のどアップ小さめサイズにしたからぺろっと食べちゃった♡8/23発売のBRODYに出させていただきまーす♪誕生日後すぐだね!今晩、まいちゅんのオールナイトニッポン0にもお邪魔させていただくのでぜひ夜更かしの準備を〜♡それではまた(^^)'
node = tagger.parseToNode(content) # 形態素解析
target_parts_of_speech = ('固有名詞')
while node:
if node.feature.split(',')[1] in target_parts_of_speech: # 固有名詞の時
print(node.surface.lower())
node = node.next
隅田川花火大会
いく
いく
100倍
笑
東京
笑
13年
トンチンカン
笑
mc
笑
ジコチュー
mv
23発
まーす
誕生日
まいちゅん
オールナイトニッポン
データベース内の全ての本文から、固有名詞を抽出します。
3. 固有名詞のTF-IDF計算
ここでは、メンバーごとの特徴的な固有名詞を抽出していきます。今回は特徴語抽出の際に一般的に用いられる、TF-IDFを用いて、メンバーが高頻度で使用するかつ、ほかのメンバーがあまり使わない単語を特徴語として抽出していきます。
数式など、知りたい方は以下を参考にしてください。
TF-IDFで文書内の単語の重み付け
結果
結果の一部を載せます。
大きくなっているほど、TF-IDFが高くなっています。要するにそのメンバーにとって、特徴的な言葉だといえます。
佐藤楓の特徴語

イーブイやアローラロコンという単語が出てくるあたり、やはりポケモンが好きなんでしょう。
また、これを見る限り、三期生の中で坂口珠美ちゃんと仲が良いことがわかります。
まとめ
今回は、乃木坂公式ブログからブログを収集し、それぞれのメンバーから特徴的な言葉を抽出することで、各メンバーの活動や趣味、仲の良いメンバーを一目で知ることが出来ました。
結果のまとめは以下の記事にまとめてあります。
[python]乃木坂公式ブログから乃木坂メンバーの特徴語を抽出してみた[全メンバーの結果まとめ]
気が向いたら、欅坂46やけやき坂46の特徴語も抽出してみようと思います。
おかしなところ、間違っているところ、ございましたらコメントいただけると幸いです。閲覧していただきありがとうございました。