はじめに
最近、Amazon Elasticsearch Serivce(以下、Elasticsearch)を使う機会があるんですが、障害が発生したときに太刀打ち出来ないと感じたので対応方法を調べました。
今回は、AWSが推奨しているアラームが発生したことを想定して対応方法を考えます。(と言いつつドキュメントに書いてあることをまとめるだけです。)
Amazon ElasticsearCloudWatch Service の推奨アラーム - Amazon Elasticsearch Service
Elasticsearchの物理的な概念
Elasticsearchの物理的な概念を把握出来ていないとドキュメントを読み解くことが出来ないので、自分の理解出来ている範囲で説明します。すでに把握されている方は飛ばしてください。
全体図
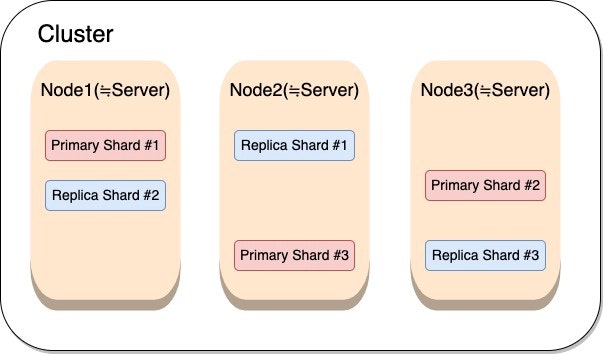
クラスター
Elasticsearchでは複数のノード(≒サーバ)を起動するとデータを分散して保持します。
この、ノードグループのことをクラスターと呼びます。
AWSではドメインとも呼ばれています。
ノード
Elasticsearchが起動しているサーバのことをノードと呼びます。
以下のコマンドを実行するとノードリストを確認出来ます。
$ curl -XGET 'http://{ESのエンドポイント}/_cat/nodes?v'
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.23.0.2 43 96 0 0.14 0.06 0.01 mdi * ******
Elasticsearchにはいくつかのノードが存在します。1つのノードで複数の役割を担うことも出来ますが、基本的に専用のノードとして役割を持ちます。
今回は、マスターノードとデータノードについて説明します。
マスターノード
**マスターノードとはクラスター管理を行うノードです。**クラスター1つにつき、1つ以上のマスターノードを持つ必要があります。
マスターノードは以下の役割を持ちます。
- ノードの管理
- 全ノードに対してpingを送って生死を確認する
- シャードの割当と再配置
- 新しいシャードの割当や、既存のシャードの再配置を行う
マスターノードが停止するとクラスター自体が停止してしまいます。
そのため、可用性を高めるために候補となるノードを3台以上の奇数で設定することが推奨されています。(偶数台で構成する場合はスプリットブレインが起きる可能性があります。解説は省略します。)
また、CPU使用率が50%を超えたタイミングでスケールアップすることが推奨されています。
データノード
データの格納、クエリへの応答、インデックスのマージを行います。
シャード
Elasticsearchではインデックスのデータを分割してノードごとに分散保持することが出来ます。
この、分散保持した部分をシャードと呼びます。
インデックスとはElasticsearchにおける論理的な概念です。RDBでいうとデータベースに相当します。
レプリカシャード
ノードの可用性を高めるために、各シャードを自動的に複製する仕組みがあります。この複製されたシャードのことをレプリカシャードと呼びます。
一方で、元となるオリジナルのシャードをプライマリシャードと呼びます。
AWSの推奨アラームに対する対応
本編です。AWSの推奨アラームへの対応方法をまとめます。
Amazon ElasticsearCloudWatch Service の推奨アラーム - Amazon Elasticsearch Service
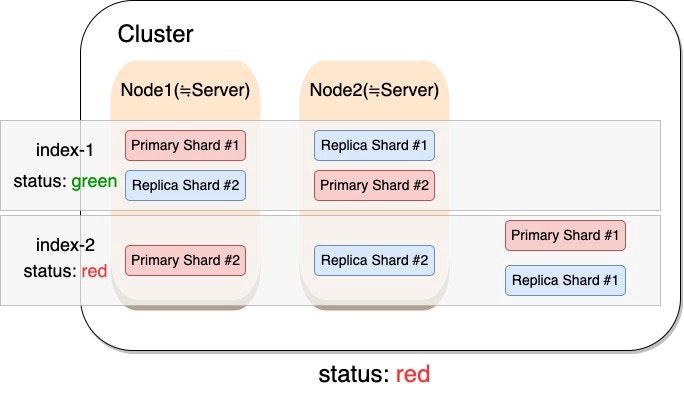
クラスターのステータスが赤色
概要
1つ以上のプライマリーシャードとそのレプリカシャードがノードに割り当てられないことを意味します。
割り当てられない原因の多くは、高負荷によってノードが使用不可能になることです。
アラーム
ClusterStatus.red maximum is >= 1 for 1 minute, 1 consecutive time
解消方法
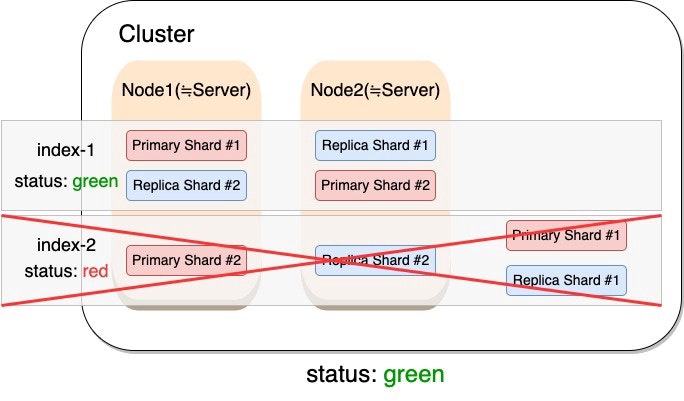
まずはクラスターのステータスを緑色に戻すことを目指します。そのための最速の方法は赤色のインデックスを削除することです。
GET _cat/indicesでインデックスごとの、ステータスを確認で出来ます。
$ curl -i -X GET 'http://{ESのエンドポイント}/_cat/indices?v'
HTTP/1.1 200 OK
content-type: text/plain; charset=UTF-8
content-length: 412
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana 1Fe90g7sQ-e_3oWm_85-TQ 1 0 3 1 14.5kb 14.5kb
green open index-1 3D-wOa8GQA-WSks-_jaKMg 5 1 2 0 8.2kb 8.2kb
red open index-2 glQcO_fXRrmV7zZcGXE-2A 5 1 2 0 11.2kb 11.2kb
次に、DELETE /{インデックス名}を使用することでインデックスを削除することが出来ます。
$ curl -XDELETE 'http://{ESのエンドポイント}/index-2'
{"acknowledged":true}
これでステータスは緑色になるはずです。
インデックスを削除出来ない場合
- スナップショットを復元する
- 別のクラスターに向き先を変える
- 他のインデックスを削除してディスク容量を解放する
などの選択肢もあるようです。
スナップショットの復元方法は以下に記述されているので、必要であれば御覧ください。
Amazon Elasticsearch Serviceでスナップショットを復元する方法 - Qiita
その他役立つ情報
シャードが割当できない原因の特定
GET _cluster/allocation/explainを使用することで、シャードが割り当てられない原因を調べることが出来ます。
今回の例は、1ノード構成でレプリカシャードが割り当てられずyellowになっていましたが、explanationに原因が記述されていました。
$ curl -i -X GET 'http://{ESのエンドポイント}/_cluster/allocation/explain?pretty'
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 1081
{
"index" : "library",
"shard" : 1,
...(省略)
"allocate_explanation" : "cannot allocate because allocation is not permitted to any of the nodes",
"node_allocation_decisions" : [
{
"node_id" : "EUZFjPJQSZyLSXaziAJmRw",
...(省略)
"node_decision" : "no",
"deciders" : [
{
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "the shard cannot be allocated to the same node on which a copy of the shard already exists [[library][1], node[EUZFjPJQSZyLSXaziAJmRw], [P], s[STARTED], a[id=a-p0n6XoSlqmBMIr2LD5Vw]]"
}
]
}
]
}
負荷の確認
クラスター障害の原因が高負荷によるものかを判断するときは以下のメトリクスを確認します。
- JVMMemoryPressure
- CPUUtilization
- ノード数
必要によって、スケールアップやスケールアウトを行います。
クラスターのステータスが黄色
概要
1つ以上のレプリカシャードがノードに割り当てられないことを意味します。
1ノード構成の場合は、レプリカシャードを割り当てるノードが無いためスタータスは黄色になります。1ノード構成ではない場合は、赤色の場合と同様の原因になります。

アラーム
ClusterStatus.yellow maximum is >= 1 for 1 minute, 1 consecutive time
解消方法
1ノード構成の場合は、レプリカシャードを削除する、もしくは2ノード以上の構成にしてください。
空きストレージ容量の不足
概要
シャードの移動に必要なストレージ領域を持つノードが無ければ、それ以降のドキュメントの追加やインデックスの作成に失敗する可能性があります。
そのため、各ノードのストレージ容量の25%を下回った段階でアラームを出すことが推奨されています。
アラーム
FreeStorageSpace minimum is <= 20480 for 1 minute, 1 consecutive time
解消方法
解消方法としては、以下のアプローチがあります。
- インデックスを削除してストレージ領域を解放する
- より大きなEBSをアタッチする
- インスタンスタイプごとにアタッチ出来るEBSのサイズが決まっている
- 必要であればインスタンスタイプを変更する
高いCPU使用率が継続するとき
概要
ノードのCPU使用率が一時的に100%になることは珍しくありません。
しかし、CPU使用率が高い状態が継続するときには解消する必要があります。
アラーム
CPUUtilizationまたはWarmCPUUtilizationmaximum is >= 80% for 15 minutes, 3 consecutive times
解消方法
より大規模なインスタンスタイプのノードを使用するか、ノードの追加を行います。
メモリ使用率増加
概要
メモリ使用率が増加している状態です。
アラーム
JVMMemoryPressureまたはWarmJVMMemoryPressuremaximum is >= 80% for 5 minutes, 3 consecutive times
解消方法
より大規模なインスタンスタイプに変更します。
64MBのメモリを使用しても改善しないときはノードの追加を行います。
マスターノードのCPU使用率とメモリ使用率の増加
概要
マスターノードのCPU使用率とメモリ使用率が増加しています。
マスターノードが停止してしまうとクラスター全体の機能が停止してしまうので、50%のCPU使用率でアラームを出すことが推奨されています。
アラーム
MasterCPUUtilization maximum is >= 50% for 15 minutes, 3 consecutive times
MasterJVMMemoryPressure maximum is >= 80% for 15 minutes, 1 consecutive time
解消方法
より大規模なインスタンスタイプの専用マスターノードを使用します。
最後に
今回は、Elasticsearchで障害が起きた時の対応方法を調べました。
まだまだ運用経験が不足しているので、ノウハウが溜まり次第記事の更新をしていきます。
内容が間違っているなどありましたらコメントをお願いいたします。閲覧ありがとうございました!
参考
Amazon ElasticsearCloudWatch Service の推奨アラーム - Amazon Elasticsearch Service
Amazon Elasticsearch Service - Amazon Elasticsearch Service