各種Tokenize手法に依存したベクトル化手法の比較
TL;DR
以下のベクトル化手法を比較しました。
ベクトル化するための学習データとして日本語Wikipediaを使用しました。
wikipedia2vec
from wikipedia2vec import Wikipedia2Vec
word2vec_filename = 'models/jawiki_20180420_300d.pkl'
word2vec = Wikipedia2Vec.load(word2vec_filename)
test_word = '脂'
print(len(word2vec.dictionary))
print(word2vec.most_similar(word2vec.get_word(test_word), 10))
1593143
[(<Word 脂>, 0.99999994), (<Word 脂肪>, 0.60400623), (<Word 血合>, 0.59330285), (<Word 牛脂>, 0.5907982), (<Word グアヤク>, 0.5891678), (<Word 肪織>, 0.5861825), (<Word グリセリド>, 0.5824453), (<Word ガラスープ>, 0.5739102), (<Word 血合い>, 0.56854814), (<Word 臭み>, 0.5571986)]
sentencepieces + word2vec
from gensim.models.word2vec import Word2Vec
import sentencepiece as spm
sp = spm.SentencePieceProcessor()
sp.Load('models/wikisentence-piece.model')
test_word = '脂'
tokenized = sp.EncodeAsPieces(test_word)
sentencepieced_word2vec_filename = 'models/sentencepieced_word2vec_allwiki.model'
sentencepieced_word2vec = Word2Vec.load(sentencepieced_word2vec_filename)
print(len(sentencepieced_word2vec.wv.vocab))
print(tokenized)
print(sentencepieced_word2vec.most_similar(tokenized[1]))
C:\Users\hidek\Anaconda3\lib\site-packages\gensim\utils.py:1212: UserWarning: detected Windows; aliasing chunkize to chunkize_serial
warnings.warn("detected Windows; aliasing chunkize to chunkize_serial")
171118
['▁', '脂']
C:\Users\hidek\Anaconda3\lib\site-packages\ipykernel_launcher.py:15: DeprecationWarning: Call to deprecated `most_similar` (Method will be removed in 4.0.0, use self.wv.most_similar() instead).
from ipykernel import kernelapp as app
C:\Users\hidek\Anaconda3\lib\site-packages\gensim\matutils.py:737: FutureWarning: Conversion of the second argument of issubdtype from `int` to `np.signedinteger` is deprecated. In future, it will be treated as `np.int32 == np.dtype(int).type`.
if np.issubdtype(vec.dtype, np.int):
[('ニンニク', 0.8067691922187805), ('肉', 0.8009461760520935), ('脂肪', 0.7919986248016357), ('ゼリー', 0.786160945892334), ('ゼラチン', 0.7856716513633728), ('臭', 0.7705897688865662), ('粉末状', 0.7692583799362183), ('苦味', 0.7675473093986511), ('ニンジン', 0.7648000717163086), ('汁', 0.7606260776519775)]
char2vec
from gensim.models.word2vec import Word2Vec
char2vec_filename = 'models/mychar2vec_fromWikiALL.model'
char2vec = Word2Vec.load(char2vec_filename)
test_word = '脂'
print(len(char2vec.wv.vocab))
print(char2vec.most_similar(test_word))
14535
C:\Users\hidek\Anaconda3\lib\site-packages\ipykernel_launcher.py:9: DeprecationWarning: Call to deprecated `most_similar` (Method will be removed in 4.0.0, use self.wv.most_similar() instead).
if __name__ == '__main__':
C:\Users\hidek\Anaconda3\lib\site-packages\gensim\matutils.py:737: FutureWarning: Conversion of the second argument of issubdtype from `int` to `np.signedinteger` is deprecated. In future, it will be treated as `np.int32 == np.dtype(int).type`.
if np.issubdtype(vec.dtype, np.int):
[('糖', 0.9036800861358643), ('繊', 0.7795820832252502), ('剤', 0.7757814526557922), ('汁', 0.7682333588600159), ('酢', 0.7667589783668518), ('塩', 0.7649936676025391), ('酸', 0.7632763981819153), ('粉', 0.7586979269981384), ('菌', 0.751047670841217), ('臭', 0.7475357055664062)]
ベンチマーク用データ
京都大学情報学研究科--NTTコミュニケーション科学基礎研究所 共同研究ユニットが提供するブログの記事に関するデータセットを利用しました。 このデータセットでは、ブログの記事に対して以下の4つの分類がされています。
- グルメ
- 携帯電話
- 京都
- スポーツ
import pandas as pd
gourmet_df = pd.read_csv('data/KNBC_v1.0_090925/corpus2/Gourmet.tsv', delimiter='\t', header=None).drop(columns=[0, 2, 3, 4, 5])
keitai_df = pd.read_csv('data/KNBC_v1.0_090925/corpus2/Keitai.tsv', delimiter='\t', header=None).drop(columns=[0, 2, 3, 4, 5])
kyoto_df = pd.read_csv('data/KNBC_v1.0_090925/corpus2/Kyoto.tsv', delimiter='\t', header=None).drop(columns=[0, 2, 3, 4, 5])
sports_df = pd.read_csv('data/KNBC_v1.0_090925/corpus2/Sports.tsv', delimiter='\t', header=None).drop(columns=[0, 2, 3, 4, 5])
gourmet_df['label'] = 'グルメ'
keitai_df['label'] = '携帯電話'
kyoto_df['label'] = '京都'
sports_df['label'] = 'スポーツ'
display(gourmet_df.head())
display(keitai_df.head())
display(kyoto_df.head())
display(sports_df.head())
| 1 | label | |
|---|---|---|
| 0 | [グルメ]烏丸六角のおかき屋さん | グルメ |
| 1 | 六角堂の前にある、蕪村庵というお店に行ってきた。 | グルメ |
| 2 | おかきやせんべいの店なのだが、これがオイシイ。 | グルメ |
| 3 | のれんをくぐると小さな庭があり、その先に町屋風の店内がある。 | グルメ |
| 4 | せんべいの箱はデパートみたいな山積みではなく、間隔をあけて陳列されているのがまた良い。 | グルメ |
| 1 | label | |
|---|---|---|
| 0 | [携帯電話]プリペイドカード携帯布教。 | 携帯電話 |
| 1 | もはや’今さら’だが、という接頭句で始めるしかないほど今さらだが、私はプリペイド携帯をずっと... | 携帯電話 |
| 2 | 犯罪に用いられるなどによりかなりイメージを悪化させてしまったプリペイド携帯だが、一ユーザーと... | 携帯電話 |
| 3 | かつてはこのような話を友人に振っても、「携帯電話の料金は親が払っているから別に...」という... | 携帯電話 |
| 4 | そこで、携帯電話の料金を自分の身銭で払わざる得ない、あるいは得なくなったが所得が少ない、或い... | 携帯電話 |
| 1 | label | |
|---|---|---|
| 0 | [京都観光]時雨殿に行った。 | 京都 |
| 1 | しぐれでん | 京都 |
| 2 | 2006年10月09日。 | 京都 |
| 3 | 時雨殿に行った。 | 京都 |
| 4 | 8月に嵐山へドクターフィシュ体験で行った時に残念ながら閉館していたのでいつか行こうと思ってい... | 京都 |
| 1 | label | |
|---|---|---|
| 0 | [スポーツ]私の生きがい | スポーツ |
| 1 | 入部3ヶ月目にはじめてのレースを経験した。 | スポーツ |
| 2 | 今の1回生では1番漕暦が浅いのに持ち前の体力と精神力でレース出場権を手にした。 | スポーツ |
| 3 | そのレースは東大戦。 | スポーツ |
| 4 | 2回生の中に混じっての初レース。 | スポーツ |
features_readable = []
labels = []
for p in gourmet_df.values:
features_readable.append(p[0])
labels.append([1, 0, 0, 0])
for p in keitai_df.values:
features_readable.append(p[0])
labels.append([0, 1, 0, 0])
for p in kyoto_df.values:
features_readable.append(p[0])
labels.append([0, 0, 1, 0])
for p in sports_df.values:
features_readable.append(p[0])
labels.append([0, 0, 0, 1])
print(len(features_readable))
print(len(labels))
4186
4186
ベクトル化
wordのベクトル化
Tokenize
word単位のtokenizeはjanomeを使用しました。NEologdを使用しました。組み込み手順として以下を参考にさせて頂きました。
- (very experimental) NEologd 辞書を内包した janome をビルドする方法
ベクトル化
wikipedia2vecを使用しました。
from janome.tokenizer import Tokenizer
import re
import pandas as pd
tokenizer = Tokenizer(mmap=True)
def get_word_tokens(df):
all_tokens = []
for sentence in df[:][0]:
tokens = tokenizer.tokenize(sentence)
base_forms = [token.base_form for token in tokens]
all_tokens.append(base_forms)
return all_tokens
word_tokenized_features = get_word_tokens(pd.DataFrame(features_readable))
display(pd.DataFrame(word_tokenized_features).head(5))
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 118 | 119 | 120 | 121 | 122 | 123 | 124 | 125 | 126 | 127 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | [ | グルメ | ] | 烏丸 | 六角 | の | おかき | 屋 | さん | None | ... | None | None | None | None | None | None | None | None | None | None |
| 1 | 六角堂 | の | 前 | に | ある | 、 | 蕪村 | 庵 | という | お | ... | None | None | None | None | None | None | None | None | None | None |
| 2 | おかき | や | せんべい | の | 店 | だ | の | だ | が | 、 | ... | None | None | None | None | None | None | None | None | None | None |
| 3 | のれん | を | くぐる | と | 小さな | 庭 | が | ある | 、 | その | ... | None | None | None | None | None | None | None | None | None | None |
| 4 | せんべい | の | 箱 | は | デパート | みたい | だ | 山積み | で | は | ... | None | None | None | None | None | None | None | None | None | None |
5 rows × 128 columns
import logging
import numpy as np
words_maxlen = len(max(word_tokenized_features, key = (lambda x: len(x))))
word_features_vector = np.zeros((len(word_tokenized_features), words_maxlen, word2vec.get_word_vector('脂').shape[0]), dtype = np.float32)
for i, tokens in enumerate(word_tokenized_features):
for t, token in enumerate(tokens):
if not token or token == ' ':
continue
try:
word_features_vector[i, t] = word2vec.get_word_vector(token.lower())
except:
#logging.warn(f'{token} is skipped.')
continue
print(word_features_vector.shape)
(4186, 128, 300)
sentencepieceのベクトル化
Tokenize
sentencepiece + word2vecを使用しました。
sentencepieceの学習には日本語Wikipediaを使用しています。
ベクトル化
sentencepiecesでtokenizeした上で、日本語Wikipediaを対象にword2vecで学習しました。
import sentencepiece as spm
def get_sentencepieced_word_tokens(df):
all_tokens = []
for sentence in df[:][0]:
tokens = sp.EncodeAsPieces(sentence)
all_tokens.append(tokens)
return all_tokens
sentencepieced_word_tokenized_features = get_sentencepieced_word_tokens(pd.DataFrame(features_readable))
display(pd.DataFrame(sentencepieced_word_tokenized_features).head(5))
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 86 | 87 | 88 | 89 | 90 | 91 | 92 | 93 | 94 | 95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ▁[ | グルメ | ] | 烏丸 | 六角 | のお | かき | 屋さん | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 1 | ▁ | 六角 | 堂 | の前 | にある | 、 | 蕪 | 村 | 庵 | という | ... | None | None | None | None | None | None | None | None | None | None |
| 2 | ▁ | おか | き | や | せんべい | の | 店 | な | のだが | 、 | ... | None | None | None | None | None | None | None | None | None | None |
| 3 | ▁ | の | れん | をくぐる | と | 小さな | 庭 | があり | 、 | その先に | ... | None | None | None | None | None | None | None | None | None | None |
| 4 | ▁ | せんべい | の | 箱 | は | デパート | みたいな | 山 | 積み | ではなく | ... | None | None | None | None | None | None | None | None | None | None |
5 rows × 96 columns
import logging
sentencepieced_word_maxlen = len(max(sentencepieced_word_tokenized_features, key = (lambda x: len(x))))
sentencepieced_word_features = np.zeros((len(sentencepieced_word_tokenized_features), sentencepieced_word_maxlen, sentencepieced_word2vec.wv.vectors.shape[1]), dtype = np.float32)
for i, tokens in enumerate(sentencepieced_word_tokenized_features):
for t, token in enumerate(tokens):
if not token or token == ' ' :
continue
try:
sentencepieced_word_features[i, t] = sentencepieced_word2vec[token.lower()]
except:
#logging.warn(f'{type(token)}->{token} is skipped.')
continue
print(sentencepieced_word_features.shape)
C:\Users\hidek\Anaconda3\lib\site-packages\ipykernel_launcher.py:11: DeprecationWarning: Call to deprecated `__getitem__` (Method will be removed in 4.0.0, use self.wv.__getitem__() instead).
# This is added back by InteractiveShellApp.init_path()
(4186, 96, 50)
characterのベクトル化
Tokenize
単純に1文字ずつ分解しました。
ベクトル化
char2vecを参考に、日本語Wikipediaを対象にword2vecで学習しました。
import logging
chars_maxlen = len(max(features_readable, key = (lambda x: len(x))))
char_features_vector = np.zeros((len(features_readable), chars_maxlen, char2vec.wv.vectors.shape[1]), dtype = np.float32)
for i, text in enumerate(features_readable):
for t, token in enumerate(text):
if token == ' ':
continue
try:
char_features_vector[i, t] = char2vec[token.lower()]
except:
#logging.warn(f'{char} is skipped.')
continue
print(char_features_vector.shape)
C:\Users\hidek\Anaconda3\lib\site-packages\ipykernel_launcher.py:11: DeprecationWarning: Call to deprecated `__getitem__` (Method will be removed in 4.0.0, use self.wv.__getitem__() instead).
# This is added back by InteractiveShellApp.init_path()
(4186, 228, 30)
学習データと検証データの分割
from sklearn.model_selection import train_test_split
idx_features = range(len(features_readable))
idx_labels = range(len(labels))
tmp_data = train_test_split(idx_features, idx_labels, train_size = 0.9, test_size = 0.1)
train_char_features = np.array([char_features_vector[i] for i in tmp_data[0]])
valid_char_features = np.array([char_features_vector[i] for i in tmp_data[1]])
train_word_features = np.array([word_features_vector[i] for i in tmp_data[0]])
valid_word_features = np.array([word_features_vector[i] for i in tmp_data[1]])
train_sentencepieced_word_features = np.array([sentencepieced_word_features[i] for i in tmp_data[0]])
valid_sentencepieced_word_features = np.array([sentencepieced_word_features[i] for i in tmp_data[1]])
train_labels = np.array([labels[i] for i in tmp_data[2]])
valid_labels = np.array([labels[i] for i in tmp_data[3]])
print(train_word_features.shape)
print(valid_word_features.shape)
print(train_sentencepieced_word_features.shape)
print(valid_sentencepieced_word_features.shape)
print(train_char_features.shape)
print(valid_char_features.shape)
print(train_labels.shape)
print(valid_labels.shape)
(3767, 128, 300)
(419, 128, 300)
(3767, 96, 50)
(419, 96, 50)
(3767, 228, 30)
(419, 228, 30)
(3767, 4)
(419, 4)
ネットワーク設計
比較できるようにBi-LSTM+全結合で統一しました。
from keras.layers import Dense, Dropout, LSTM, Bidirectional
from keras import Input, Model
def create_model(train_features):
class_count = 4
input_tensor = Input(train_features[0].shape)
x1 = Bidirectional(LSTM(512))(input_tensor)
x1 = Dense(2048)(x1)
x1 = Dropout(0.5)(x1)
output_tensor = Dense(class_count, activation='softmax')(x1)
model = Model(input_tensor, output_tensor)
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['mae'])
model.summary()
return model
C:\Users\hidek\Anaconda3\lib\site-packages\h5py\__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Using TensorFlow backend.
学習と評価
word単位のベクトル化
from keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard
model = create_model(train_word_features)
history = model.fit(train_word_features,
train_labels,
epochs = 100,
batch_size = 128,
validation_split = 0.1,
verbose = 0,
callbacks = [
TensorBoard(log_dir = 'tflogs'),
EarlyStopping(patience=3, monitor='val_mean_absolute_error'),
])
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 128, 300) 0
_________________________________________________________________
bidirectional_1 (Bidirection (None, 1024) 3330048
_________________________________________________________________
dense_1 (Dense) (None, 2048) 2099200
_________________________________________________________________
dropout_1 (Dropout) (None, 2048) 0
_________________________________________________________________
dense_2 (Dense) (None, 4) 8196
=================================================================
Total params: 5,437,444
Trainable params: 5,437,444
Non-trainable params: 0
_________________________________________________________________
df = pd.DataFrame(history.history)
display(df)
| val_loss | val_mean_absolute_error | loss | mean_absolute_error | |
|---|---|---|---|---|
| 0 | 1.207464 | 0.276164 | 1.345946 | 0.326653 |
| 1 | 0.981745 | 0.248911 | 1.033764 | 0.270818 |
| 2 | 0.985636 | 0.246861 | 0.950192 | 0.243584 |
| 3 | 0.958608 | 0.208711 | 0.821692 | 0.217474 |
| 4 | 0.940028 | 0.208070 | 0.817665 | 0.209816 |
| 5 | 0.998767 | 0.216945 | 0.744832 | 0.195718 |
| 6 | 1.183153 | 0.247409 | 0.620412 | 0.166929 |
| 7 | 0.802547 | 0.193151 | 0.614557 | 0.163338 |
| 8 | 0.804815 | 0.186113 | 0.648118 | 0.157116 |
| 9 | 0.947861 | 0.196694 | 0.489098 | 0.137335 |
| 10 | 1.173078 | 0.185279 | 0.451178 | 0.125243 |
| 11 | 1.015319 | 0.165389 | 0.409986 | 0.113144 |
| 12 | 1.140270 | 0.164665 | 0.348950 | 0.096174 |
| 13 | 1.183256 | 0.170436 | 0.310988 | 0.086190 |
| 14 | 1.341658 | 0.164859 | 0.256395 | 0.074341 |
| 15 | 1.390065 | 0.179953 | 0.260767 | 0.071800 |
クラシフィケーションレポート
from sklearn.metrics import classification_report, confusion_matrix
predicted_valid_labels = model.predict(valid_word_features).argmax(axis=1)
numeric_valid_labels = np.array(valid_labels).argmax(axis=1)
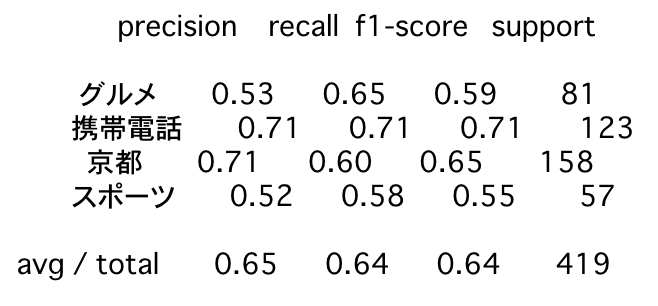
print(classification_report(numeric_valid_labels, predicted_valid_labels, target_names = ['グルメ', '携帯電話', '京都', 'スポーツ']))
precision recall f1-score support
グルメ 0.53 0.65 0.59 81
携帯電話 0.71 0.71 0.71 123
京都 0.71 0.60 0.65 158
スポーツ 0.52 0.58 0.55 57
avg / total 0.65 0.64 0.64 419
sentencepiece単位のベクトル化
from keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard
model = create_model(train_sentencepieced_word_features)
history = model.fit(train_sentencepieced_word_features,
train_labels,
epochs = 100,
batch_size = 128,
validation_split = 0.1,
verbose = 0,
callbacks = [
TensorBoard(log_dir = 'tflogs'),
EarlyStopping(patience=3, monitor='val_mean_absolute_error'),
])
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 96, 50) 0
_________________________________________________________________
bidirectional_2 (Bidirection (None, 1024) 2306048
_________________________________________________________________
dense_3 (Dense) (None, 2048) 2099200
_________________________________________________________________
dropout_2 (Dropout) (None, 2048) 0
_________________________________________________________________
dense_4 (Dense) (None, 4) 8196
=================================================================
Total params: 4,413,444
Trainable params: 4,413,444
Non-trainable params: 0
_________________________________________________________________
df = pd.DataFrame(history.history)
display(df)
| val_loss | val_mean_absolute_error | loss | mean_absolute_error | |
|---|---|---|---|---|
| 0 | 0.981924 | 0.225036 | 1.412470 | 0.248839 |
| 1 | 0.812226 | 0.183087 | 0.715505 | 0.182059 |
| 2 | 0.897991 | 0.201606 | 0.587846 | 0.151420 |
| 3 | 0.839604 | 0.169194 | 0.476369 | 0.125096 |
| 4 | 0.872412 | 0.165859 | 0.365053 | 0.096792 |
| 5 | 1.683439 | 0.222042 | 0.220963 | 0.060716 |
| 6 | 1.385759 | 0.174349 | 0.186714 | 0.048699 |
| 7 | 1.239616 | 0.156966 | 0.120487 | 0.031168 |
| 8 | 1.064627 | 0.140925 | 0.139941 | 0.029395 |
| 9 | 1.321537 | 0.144991 | 0.035579 | 0.011306 |
| 10 | 1.354807 | 0.139662 | 0.081770 | 0.015940 |
| 11 | 1.435030 | 0.146897 | 0.051363 | 0.010653 |
| 12 | 1.370385 | 0.139031 | 0.102884 | 0.017993 |
| 13 | 1.682676 | 0.145551 | 0.018069 | 0.004990 |
| 14 | 1.613921 | 0.146687 | 0.068362 | 0.011012 |
| 15 | 1.809527 | 0.139845 | 0.025406 | 0.006684 |
クラシフィケーションレポート
from sklearn.metrics import classification_report, confusion_matrix
predicted_valid_labels = model.predict(valid_sentencepieced_word_features).argmax(axis=1)
numeric_valid_labels = np.array(valid_labels).argmax(axis=1)
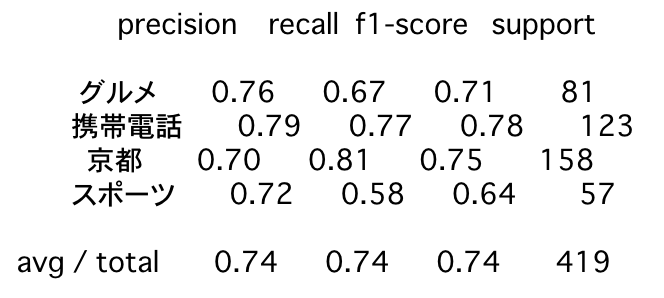
print(classification_report(numeric_valid_labels, predicted_valid_labels, target_names = ['グルメ', '携帯電話', '京都', 'スポーツ']))
precision recall f1-score support
グルメ 0.76 0.67 0.71 81
携帯電話 0.79 0.77 0.78 123
京都 0.70 0.81 0.75 158
スポーツ 0.72 0.58 0.64 57
avg / total 0.74 0.74 0.74 419
character単位のベクトル化
from keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard
model = create_model(train_char_features)
history = model.fit(train_char_features,
train_labels,
epochs = 100,
batch_size = 128,
validation_split = 0.1,
verbose = 0,
callbacks = [
TensorBoard(log_dir = 'tflogs'),
EarlyStopping(patience=3, monitor='val_mean_absolute_error'),
])
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) (None, 228, 30) 0
_________________________________________________________________
bidirectional_3 (Bidirection (None, 1024) 2224128
_________________________________________________________________
dense_5 (Dense) (None, 2048) 2099200
_________________________________________________________________
dropout_3 (Dropout) (None, 2048) 0
_________________________________________________________________
dense_6 (Dense) (None, 4) 8196
=================================================================
Total params: 4,331,524
Trainable params: 4,331,524
Non-trainable params: 0
_________________________________________________________________
df = pd.DataFrame(history.history)
display(df)
| val_loss | val_mean_absolute_error | loss | mean_absolute_error | |
|---|---|---|---|---|
| 0 | 1.213003 | 0.288650 | 1.466107 | 0.295818 |
| 1 | 1.171639 | 0.251361 | 0.888587 | 0.225342 |
| 2 | 1.132296 | 0.221131 | 0.701668 | 0.178148 |
| 3 | 1.162182 | 0.229053 | 0.570244 | 0.144374 |
| 4 | 1.351509 | 0.225116 | 0.420535 | 0.111450 |
| 5 | 1.513968 | 0.208743 | 0.297211 | 0.079006 |
| 6 | 1.669821 | 0.218852 | 0.226855 | 0.058338 |
| 7 | 1.900534 | 0.207223 | 0.160443 | 0.040320 |
| 8 | 2.199897 | 0.206606 | 0.127803 | 0.029902 |
| 9 | 2.142587 | 0.211019 | 0.094395 | 0.021337 |
| 10 | 2.125271 | 0.199587 | 0.075933 | 0.016797 |
| 11 | 1.919156 | 0.187987 | 0.100046 | 0.018867 |
| 12 | 2.132756 | 0.195224 | 0.086103 | 0.013790 |
| 13 | 1.906969 | 0.203895 | 0.672039 | 0.055926 |
| 14 | 1.915199 | 0.186711 | 0.054997 | 0.012123 |
| 15 | 2.000887 | 0.203794 | 0.120228 | 0.020637 |
| 16 | 2.237101 | 0.199090 | 0.065000 | 0.013173 |
| 17 | 2.491051 | 0.200367 | 0.048307 | 0.009193 |
クラシフィケーションレポート
from sklearn.metrics import classification_report, confusion_matrix
predicted_valid_labels = model.predict(valid_char_features).argmax(axis=1)
numeric_valid_labels = np.array(valid_labels).argmax(axis=1)
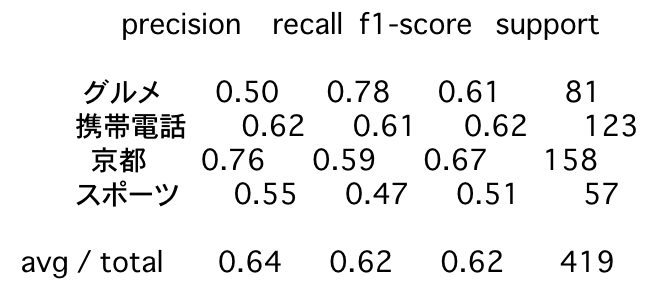
print(classification_report(numeric_valid_labels, predicted_valid_labels, target_names = ['グルメ', '携帯電話', '京都', 'スポーツ']))
precision recall f1-score support
グルメ 0.50 0.78 0.61 81
携帯電話 0.62 0.61 0.62 123
京都 0.76 0.59 0.67 158
スポーツ 0.55 0.47 0.51 57
avg / total 0.64 0.62 0.62 419
総括
それぞれクラシフィケーションレポートの結果は以下の通りです。
今回の結果からはsentencepieceの優位性が確認できました。
word、characterの順になっているところも直感的な理解と合致します。
word
sentencepiece
character
ToDo
国立国語研究所のコーパスを使って比較してみたいと考えています。
良い結果が得られるようであれば、学習済みモデルも公開したいです。
参考文献
- wikipedia2vec
- sentencepieces + word2vec
- char2vec
- janome
- NEologd
- (very experimental) NEologd 辞書を内包した janome をビルドする方法
Jupyter Notebook
Editor's Note
2018/12/06
入力ベクトルを初期化する際にint32としていたためword2vecでベクトル化した値がほとんど0になっていました。
このため、float32にするように修正したところ、wordについても適切に学習が進むようになりました。