はじめに
本記事ではベクトルDBとして Pinecone を利用して独自ナレッジを登録し、その内容を元に質疑応答するワークフローをUiPath Automation Cloudで実装します。
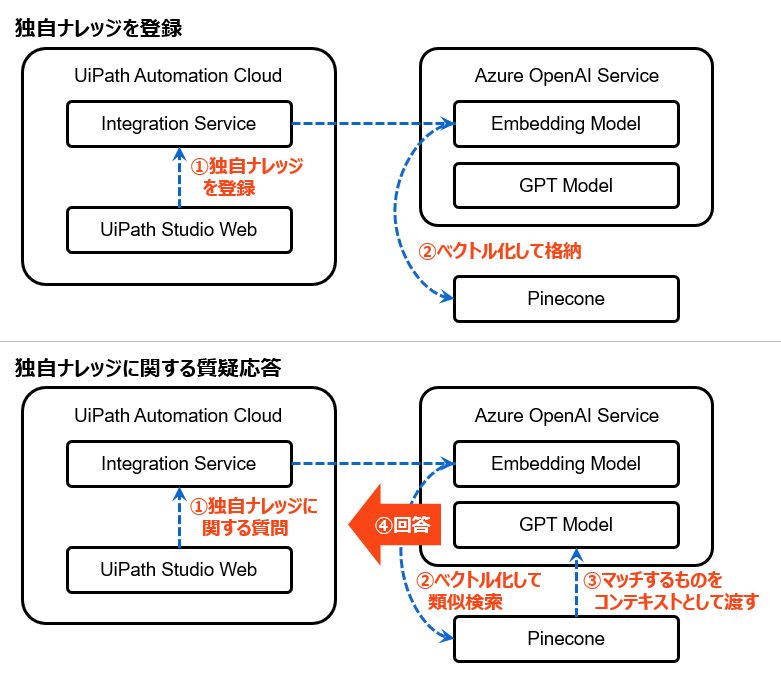
全体構成
- Pinecone: Free版でもOK
- Azure OpenAI Service: GPTモデルとEmbedding(埋め込み)モデルを利用
-
UiPath Automation Cloud: Community版でもOK
- Integration Service: サービス間を連携
- Studio Web: ワークフローを作成
概念の説明
今回実装するワークフローで重要となる概念について簡単に説明します。
- Embedding(埋め込み)モデル は、テキストなどのデータを数値ベクトルに変換するためのモデルで、これによりデータを機械学習アルゴリズムで利用しやすくします。このモデルは文脈を考慮して単語やフレーズの意味を捉え、それらを数値化します。たとえば意味合いが近いフレーズはお互いの距離が近く、意味合いが遠いフレーズは距離が遠くなるようにベクトル化されます。このようなモデルは、テキストの類似性を計算したり、文脈に基づいて単語を予測したりするのに有用です。
- ベクトルDB は、ベクトル形式のデータを保存および検索するためのデータベースです。これは類似性検索や最近傍探索などベクトル間の関係に基づいた操作を高速に行うのに適しています。テキストをEmbeddingモデルによって数値表現された時、ベクトルDBはその情報を効率的に検索しアクセスするのに役立ちます。今回利用するPineconeは人気のあるベクトルDBの一つです。
- EmbeddingモデルとベクトルDBを組み合わせると、大量のテキストデータから意味的に関連する情報を迅速に抽出できます。例えば特定の質問に最も適した回答を検索したり、特定のテキストに類似した他のテキストを見つけるなど、単純なキーワード一致では実現が難しい検索処理を効率的に実行できます。生成AIシステムの構築において、独自データをあらかじめベクトルDBなどに格納して最適な回答を可能にする手法は Grounding / RAG(Retrieval-Augmented Generation) と呼ばれます。Azure環境にRAGアーキテクチャをデプロイする手順については 「UiPathドキュメントポータルの内容をチャットで問い合わせるシステムを作る」 の記事でも説明しておりますが、今回はより手軽に実装する手順について説明したいと思います。
構築手順
大まかな構築の流れ
- PineconeのインデックスとAPIキー作成
- Azure OpenAI Serviceのデプロイ
- Integration Serviceのコネクター設定
- Studio Webで独自ナレッジをPineconeに登録するワークフロー実装
- Studio WebでPineconeを参照して回答するワークフロー実装
1. PineconeのインデックスとAPIキー作成
-
Pinecone にアクセスします。初めて利用する時は [Sign Up Free] をクリックします。
-
サインアップ方式(Google, GitHub, Microsoftアカウントまたはメールアドレスなど)を適宜選択し、アカウントを作成します。

-
今回は検証目的のためFreeプランで進めます。本番利用の際には 利用規約 を参照し、 適切な料金プラン を選択してください。
-
アカウントやプロジェクトなどを登録します。
-
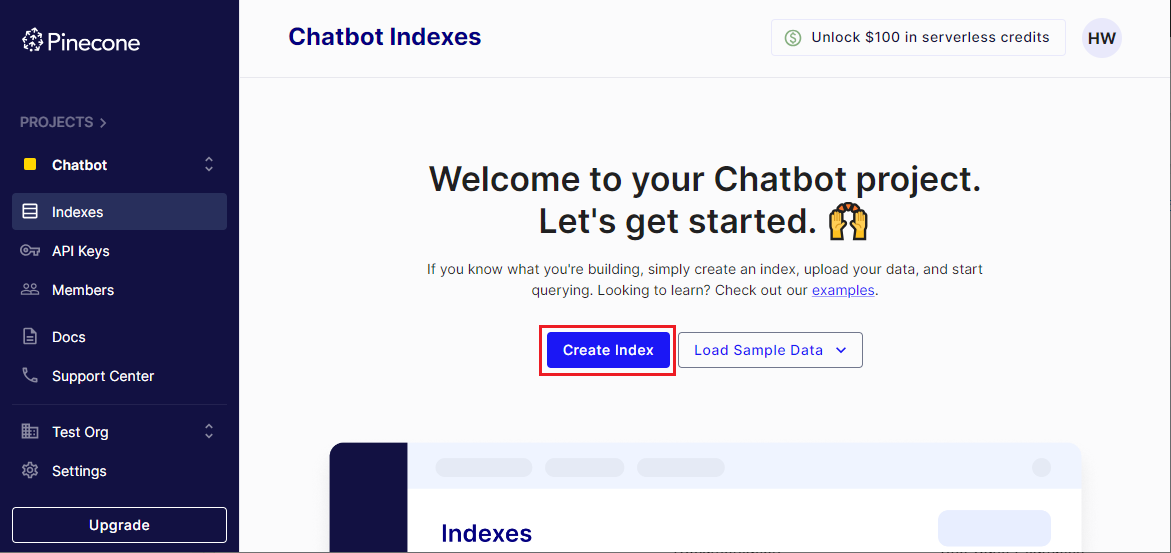
Indexesメニューを選択し [Create Index] をクリックしてインデックスを作成します。
-
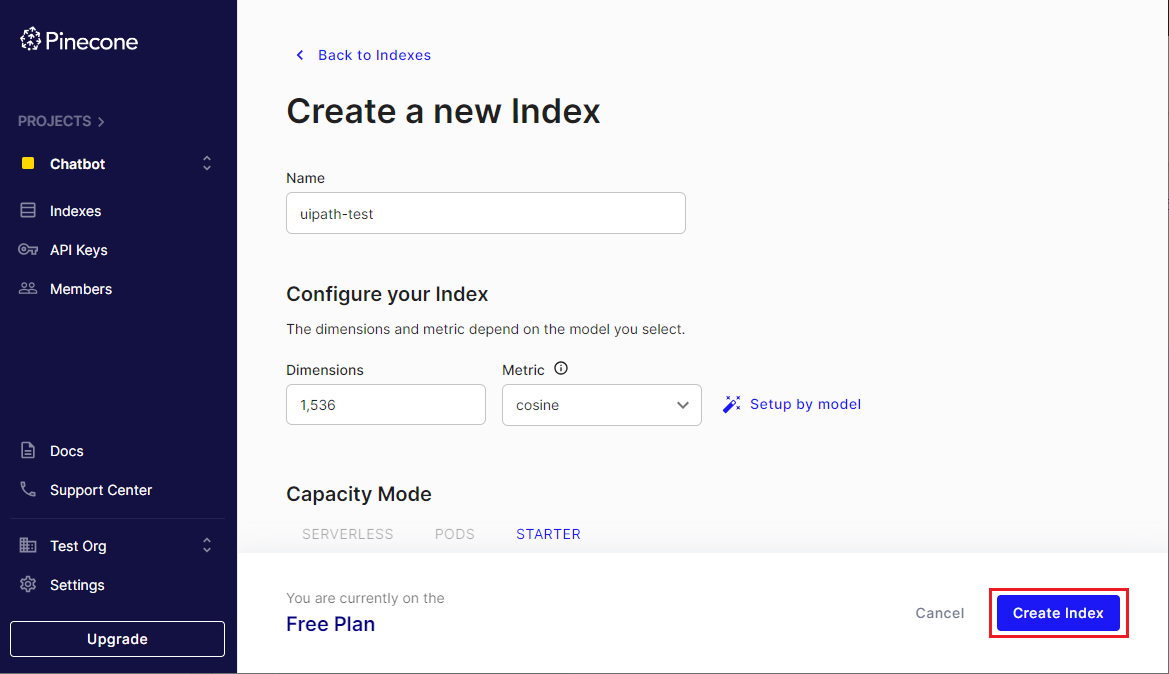
Name: インデックス名は何でも良いですが、本記事では
uipath-testとします。後で使用するためインデックス名をメモします。 -
Dimensions:
1536(Embeddingモデルで使用される次元) -
Metric:
cosine - Capacity Mode: Freeプランでは選択できないため既定値のままとします
- [Create Index] をクリックしてインデックスを作成します。
-
Name: インデックス名は何でも良いですが、本記事では
-
API Keysメニューを選択し [Copy Key Value] アイコンをクリックしてAPIキーをコピーします。後で使用するためにメモします。

2. Azure OpenAI Serviceのデプロイ
- Azure OpenAI Serviceのデプロイ手順は次の記事をご参照ください。
- Azure OpenAI Serviceの キー1 と リソース名 をそれぞれコピーしてメモします。

-
Azure OpenAI Studio にて次の2つのモデルをデプロイします。
- GPTモデル
-
モデル:
gpt-4(もしくはgpt-35-turbo) -
モデルバージョン:
0613(もしくはより新しいバージョン) -
デプロイ名:
gpt-4 -
詳細設定オプション: 既定値

-
- 埋め込みモデル
-
モデル:
text-embedding-ada-002 -
モデルバージョン:
2 -
デプロイ名:
text-embedding-ada-002(モデル名と同じにする!) -
詳細設定オプション: 既定値

-
モデル:
GPTモデルのデプロイ名は別名でも良いですが、埋め込みモデルのデプロイ名は必ずモデル名と同じにしてください。(理由は後述)
- GPTモデル
3. Integration Serviceのコネクター設定
- Automation Cloud にてPineconeおよびAzure OpenAI Serviceと連携する設定を行います。
- 左メニューにて Integration Service のアイコンをクリックします。

Pinecone
-
コネクターとしてPineconeを選択し [Pineconeに接続] をクリックします。

-
先ほどメモしたAPIキーとインデックス名を指定して [接続] をクリックします。

Azure OpenAI Service
-
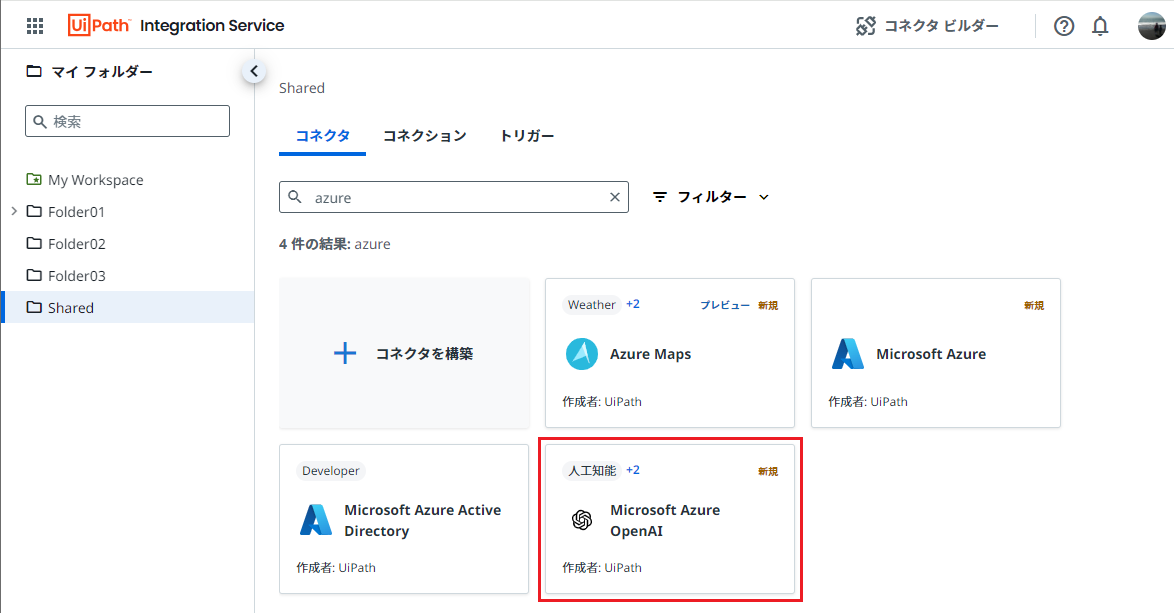
コネクターとしてAzure OpenAIを選択し [Microsoft Azure OpenAIに接続] をクリックします。
-
先ほどメモしたAzure OpenAI Serviceのキーとリソース名を指定して [接続] をクリックします。

4. Studio Webで独自ナレッジをPineconeに登録するワークフロー実装
-
Automation Cloud の左メニューにて Studio のアイコンをクリックします。

-
プロジェクト > [新しいプロジェクト] をクリックします。

-
トリガーは [手動トリガー] を選択します。左上の編集アイコンでプロジェクト名を編集して「Pinecone登録」とします。
-
[引数を追加] をクリックし、独自ナレッジとして追加するテキストを定義します。
-
名前:
in_text -
方向:
入力 -
型:
テキスト - 既定値: 本来は空白として実行時に引数として独自ナレッジのコンテンツを渡すのが望ましいですが、簡易的に検証を行うために値をセットしておきます。今回は UiPath用語集 のコンテンツをコピー&ペーストで入力します。
- [作成] をクリックします。

-
名前:
-
(+) をクリックし、Microsoft Azure OpenAIの 埋め込みを作成 アクティビティを選択します。

-
先ほど作成したAzure OpenAIのコネクションが表示されることを確認し、各フィールドを設定します。
-
モデル:
text-embedding-ada-002を選択します。 -
入力: 引数
in_textを指定します。

-
モデル:
-
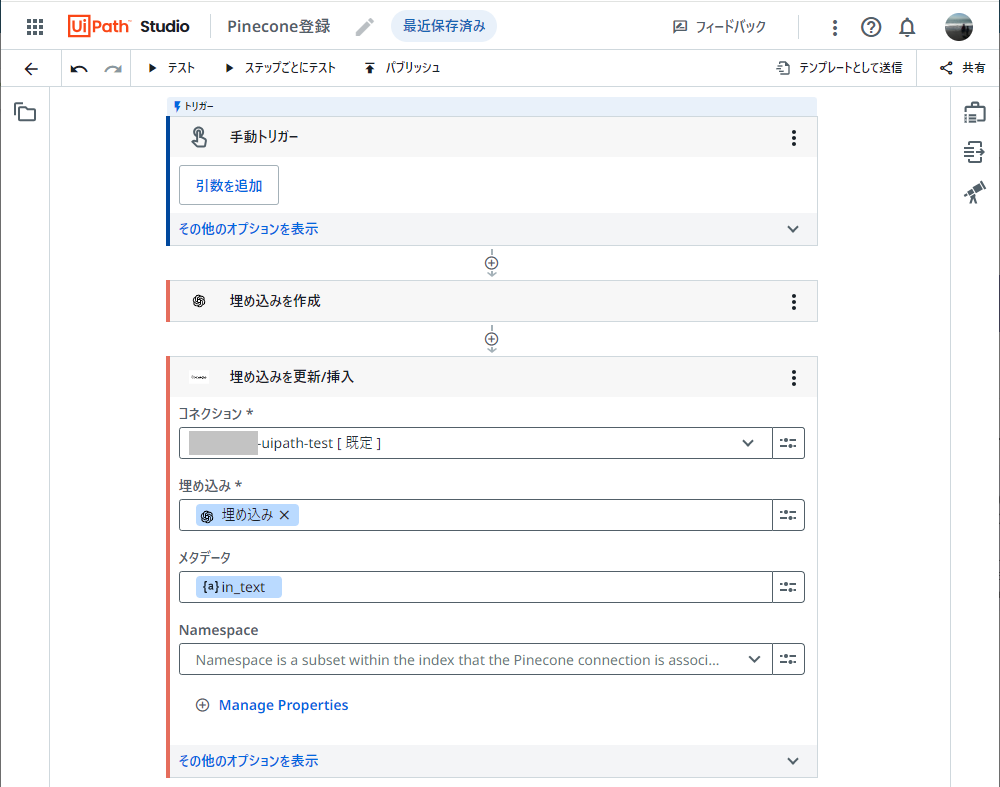
(+) をクリックし、Pineconeの 埋め込みを更新/挿入 アクティビティを選択します。

-
先ほど作成したPineconeのコネクションが表示されることを確認し、各フィールドを設定します。
-
埋め込み: 右の[その他を表示]アイコン→[変数を使用]→[埋め込みを作成]→
埋め込みを順にクリックして変数を選択します。 -
メタデータ: 引数
in_textを指定します。 -
Namespace: Pineconeでインデックス内のレコードを論理的に分離する時に使用します。今回は空白(Default)のままとします。
-
埋め込み: 右の[その他を表示]アイコン→[変数を使用]→[埋め込みを作成]→
-
[テスト] をクリックして実行してエラーが発生しないことを確認します。

-
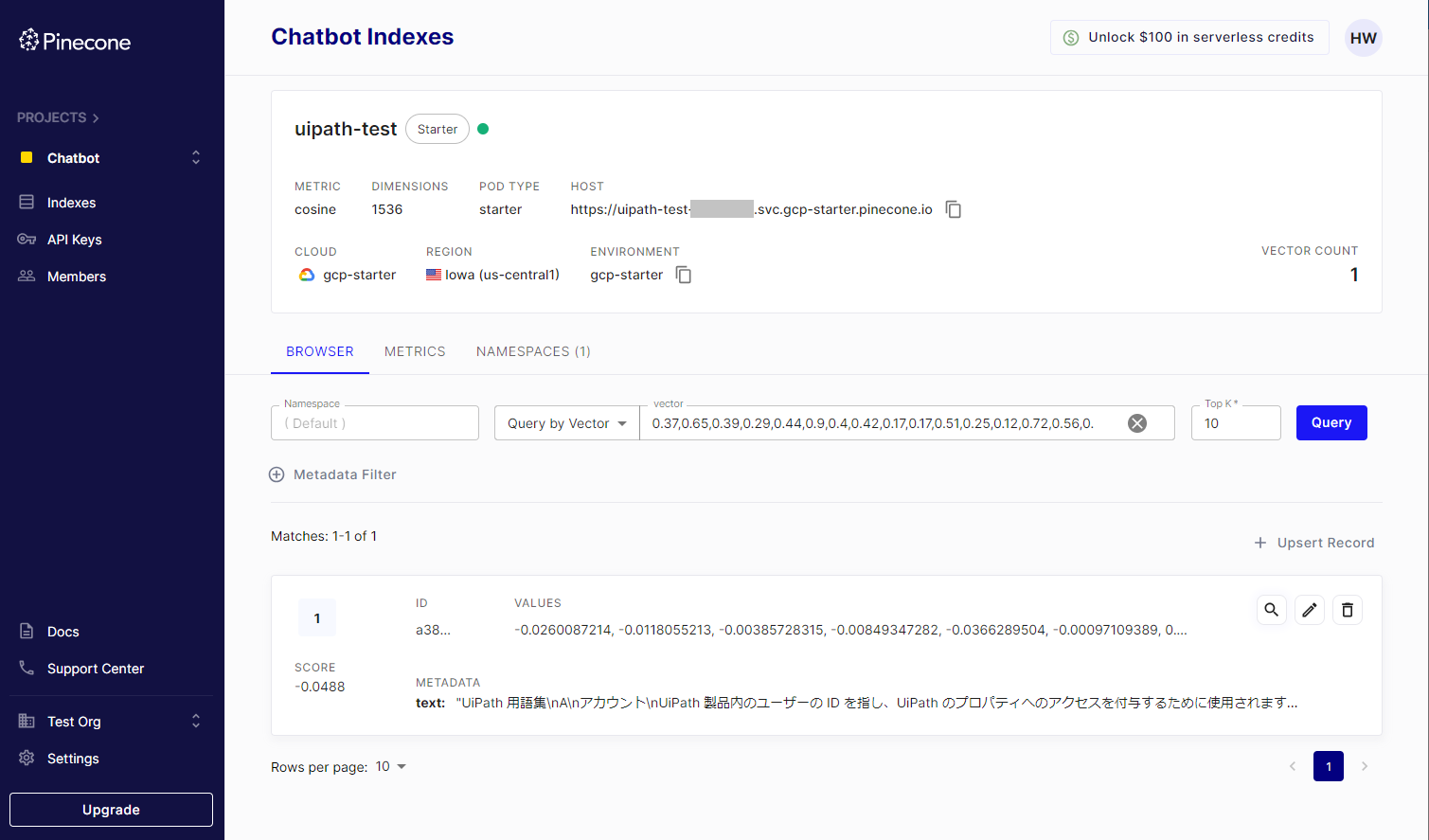
Pineconeの管理画面にアクセスし、
uipath-testインデックスにて [Query] をクリックし、先ほど作成したレコードが表示されることを確認します。
5. Studio WebでPineconeを参照して回答するワークフロー実装
-
Studio Webにて新しいワークフローのプロジェクトを作成します。今回も手動トリガーを選択します。プロジェクト名は「Pineconeチャット」とします。

-
[引数を追加] をクリックし、独自ナレッジに問い合わせる質問文を定義します。
-
名前:
in_question -
方向:
入力 -
型:
テキスト - 既定値: 本来は空白として実行時に質問内容を引数として渡すのが望ましいですが、簡易的に検証を行うために値をセットしておきます。今回は「Studioで使用されるローカルフィードとは何ですか?」と入力してみます。
- [作成] をクリックします。

-
名前:
独自ナレッジを参照しない問い合わせ
-
比較のため、まずは独自ナレッジを参照せずにGPT-4に問い合わせをしてみます。
-
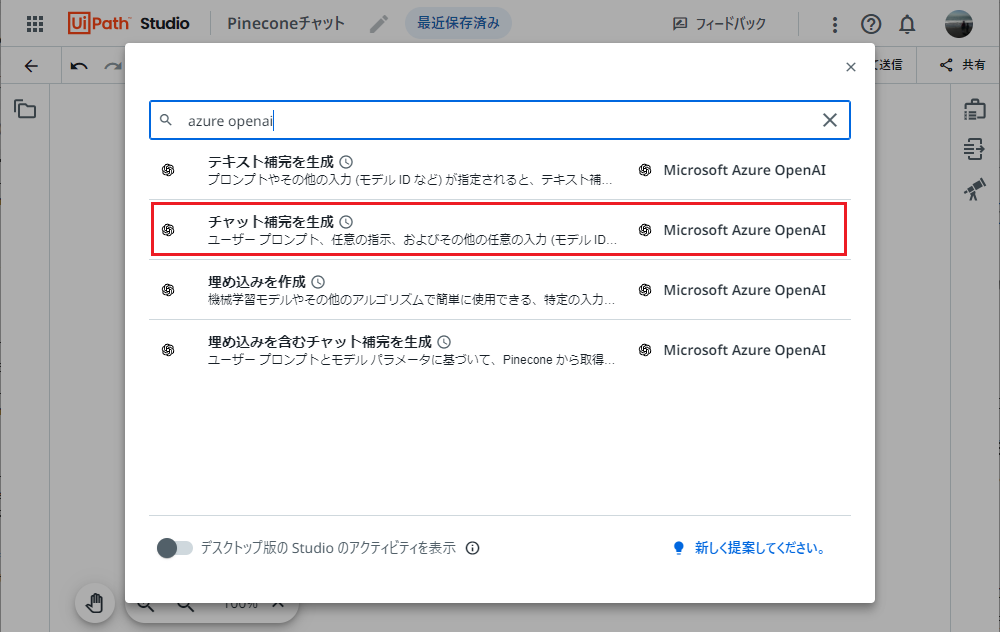
Microsoft Azure OpenAIの チャット補完を生成 アクティビティを選択します。
-
Azure OpenAIのコネクションが表示されることを確認し、各フィールドに値をセットします。
-
プロンプト: 引数
in_question - コンテキスト: 空白
-
モデル:
gpt-4(Azure OpenAI ServiceでのGPTモデルのデプロイ名)

-
プロンプト: 引数
-
(+) をクリックし、 メッセージをログ アクティビティを選択します。

-
メッセージ: チャット補完を生成 →
上位の生成テキスト変数を選択します。 -
ログレベル:
Info
-
メッセージ: チャット補完を生成 →
-
左上の [テスト] をクリックして実行します。質問内容では単に"Studio"と述べていますのでUiPath Studioと結びつかない回答が返ってきます。
Studioでは、`ローカルフィード`とは、あなたの興味に基づくコンテンツが配信されるフィードのことを 指します。ユーザーが最も頻繁に閲覧または操作する種類のコンテンツほど優先的に表示されます。文章の 作成や編集、コメントの投稿などの行動は、このフィードに表示されるコンテンツをカスタマイズする上で 影響を及ぼします。ユーザーに関連するお気に入りのプロジェクトや最新のニュース、ヒントなどの情報も 含まれます。 ただし、OpenAIのGPT-3などのAIモデルは、個々のユーザーやユーザーのプライバシー情報にアクセスする 能力はありません。入力される情報を特定のユーザーや以前のリクエストと関連付けることはありません。 -
独自ナレッジを参照する問い合わせ
-
次に独自ナレッジを参照してGPT-4に問い合わせをしてみます。
-
チャット補完を生成 アクティビティの縦三点リーダーをクリックし、無効化します。

-
(+) をクリックし、Microsoft Azure OpenAI の 埋め込みを含むチャット補完を生成 をクリックします。

-
Azure OpenAIのコネクションが表示されることを確認し、各フィールドに値をセットします。
-
入力: 引数
in_question -
モデル:
gpt-4(Azure OpenAI ServiceでのGPTモデルのデプロイ名) - Pinecone APIキー: メモしたPinecone APIキー
-
Pinecone環境:
gcp-starter -
Pineconeのインデックス:
uipath-test -
Pinecone namespace: 空白

-
入力: 引数
現在のところ下記の制約があります。(今後の改善に期待したいと思います)
- Pineconeのコネクションは選択できないためAPIキーなどを手動で指定します。
- Azure OpenAI ServiceでのEmbeddingモデルのデプロイ名は指定できません。デプロイ名はモデル名と同じ
text-embedding-ada-002として作成しておく必要があります。別名にすると実行時にエラーになります。
-
-
メッセージをログ アクティビティのメッセージを 埋め込みを含むチャット補完を生成 →
上位の生成テキスト変数に変更します。 -
左上の [テスト] をクリックして実行します。今回は独自ナレッジとしてUiPath用語集を参照するワークフローになっていますのでUiPath Studioに関連した回答が返ってきます。
ローカルフィードは、アクティビティパッケージのローカルリポジトリを指します。これは、Studio またはRobotによってデフォルトで「%ProgramFiles(x86)%\UiPath\Studio\Packages」にインストール されます。このフィードは、インストールしないように選択することも、Studioの「パッケージを管理」 ウィンドウで後から無効化することも可能です。
応用例
PDFファイルの登録
- 先ほどの実装例では独自ナレッジのテキストを入力引数で直接指定しましたが、OneDriveに配置されたPDFファイルからテキストを読み込むこともできます。これを実装するには「Pinecone登録」ワークフローを下記のように変更します。
- Microsoft 365の ファイルをダウンロード アクティビティを使用します。
- Microsoft 365のコネクターを作成します。
- OneDriveに配置したPDFファイルを選択します。ここでは日本ディープラーニング協会(JDLA)が公開している 生成AIの利用ガイドライン → 「生成AIの利用ガイドライン【条項のみ】(第1.1版, 2023年10月公開)」をPDF化したものを使用します。
読み込みに使用するPDFファイルの文字数には注意が必要です。今回使用している Embeddingモデルの最大トークン数は8,191 です。日本語ではおおよそ1文字あたり1トークンとなります (正確には Tokenizer を使って調べることができます)。よって約8,000文字を超えるPDFファイルは一度には扱えないため分割(チャンク)して処理する必要があります。
-
PDFのテキストを抽出 アクティビティを使用し、ファイルをダウンロード → [ダウンロードされるファイル] 変数を指定します。

-
埋め込みを作成 アクティビティの入力フィールドに、PDFのテキストを抽出 →
抽出テキスト変数を指定します。 -
埋め込みを更新/挿入 アクティビティの入力フィールドにも同様に、PDFのテキストを抽出 →
抽出テキスト変数を指定します。

-
[テスト] をクリックして実行し、Pineconeのインデックスに新たにレコードが追加されていることを確認します。
-
「Pineconeチャット」ワークフローにて生成AIガイドラインの内容に沿った質問 (例:「生成AIによる生成物が著作権侵害に該当しないようにするためにはどのようなことに留意すれば良いですか?」) を実行します。もしトークンの上限に達してしまう場合にはAzure OpenAI Serviceにて
gpt-4-32kなど多くのトークンを利用できるモデルをデプロイして利用します。
Studioでの実装
-
今回は主にStudio Webで実装しましたが、UiPath Studioでももちろん実装できますので、既存の自動化処理に組み込むことも可能になります。
- Integration Serviceアクティビティのバージョンは現時点で最新の
1.2.0を使用します。 - 下記のアクティビティをそれぞれ使用します。
- Microsoft Azure OpenAI → 埋め込みを作成, 埋め込みを含むチャット補完を生成
- Pinecone → 埋め込みを更新/挿入

- Integration Serviceアクティビティのバージョンは現時点で最新の
おわりに
今回はPineconeをベクトルDBとして独自ナレッジの登録と問い合わせを行うワークフローの実装例について説明しました。社内の独自ナレッジを登録して文脈に即した回答が可能になりますので、ぜひ様々なシステムの自動化に組み込んで利用してみてください。現在のところはまだ他のベクトルDB (Azure AI Search・Chromaなど) は対応しておりませんが、今後の拡張に期待したいと思います。