はじめに
- 本記事では2024年8月20日にプレビュー公開されましたUiPath AI Trust LayerによるContext-Grounding機能のメリットと利用手順について説明します。
- この機能を利用すると事前にシステム構築を行わずに容易にRAGアーキテクチャーを実装し、コンテキスト検索による質疑応答が実行できるようになります。
UiPath AI Trust Layerとは?
UiPath AI Trust Layerとは、お客様が生成AIを安全に利用するためのフレームワークです。企業のデータプライバシーポリシーと責任あるAI原則にソフトウェア定義のガバナンスを追加することで、ユーザーが生成AIによる自動化を責任を持って拡大できるよう支援するものです。詳細については こちらの記事 をご参照ください。
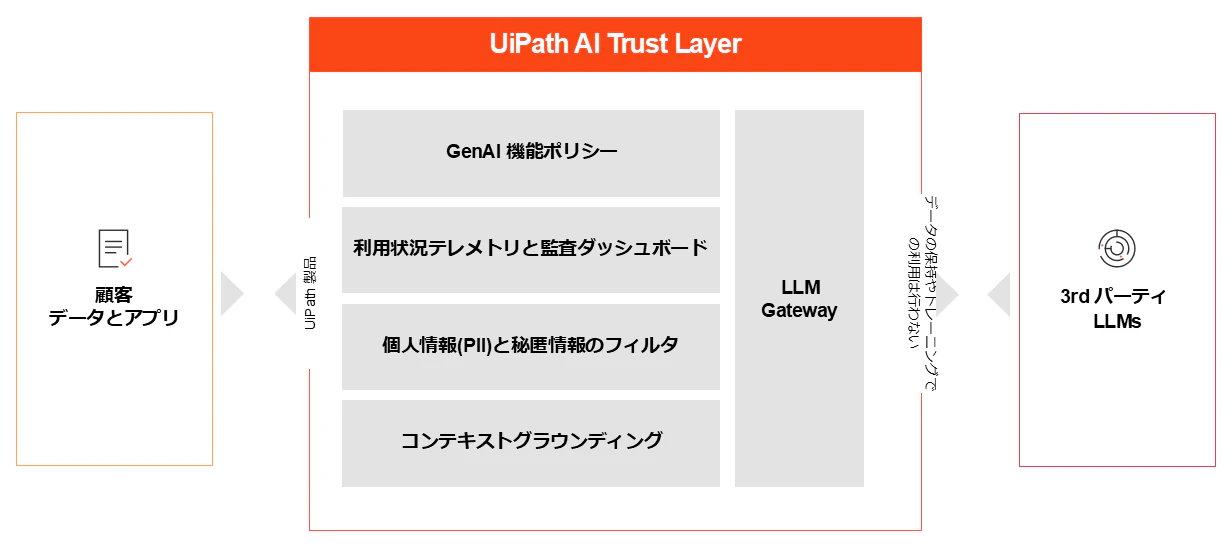
Context-Groundingとは?
- 一般的に大規模言語モデル(LLM: Large Language Models)には次の欠点があります。
- 特定日の情報までしか知らない (ナレッジカットオフ)
- 社内情報や専門分野などのドメイン知識は知らない
- これらの欠点を補うために、質問文に関連情報(Context)を与えて(Grounding)、LLMにそれに基づく回答をするようにシステムを構成します。このような構成による問い合わせを Context-Grounding や RAG (Retrieval-Augmented Generation: 検索拡張生成)と呼びます。
UiPath AI Trust Layerを利用するメリット
UiPath AI Trust Layerを利用するメリットを説明するために、まずはそれを利用しない一般的なRAGアーキテクチャについて説明します。
一般的なRAGアーキテクチャ
- 一般的なRAGアーキテクチャを実装するには、まず次のサービスコンポーネントを準備します。
- ストレージ: 関連文書を保存
- ベクトルDB: 関連文書をベクトル化して保存
- アプリケーションサーバー: ユーザーからの質問(プロンプト)を受け取り、ベクトルDBから関連文書を取得してGPTモデルに問い合わせし、ユーザーに応答を返すサーバー
- GPTモデル: プロンプトに応じた回答を生成するモデル
- 埋め込みモデル: 類似検索のためにベクトル化を行うモデル
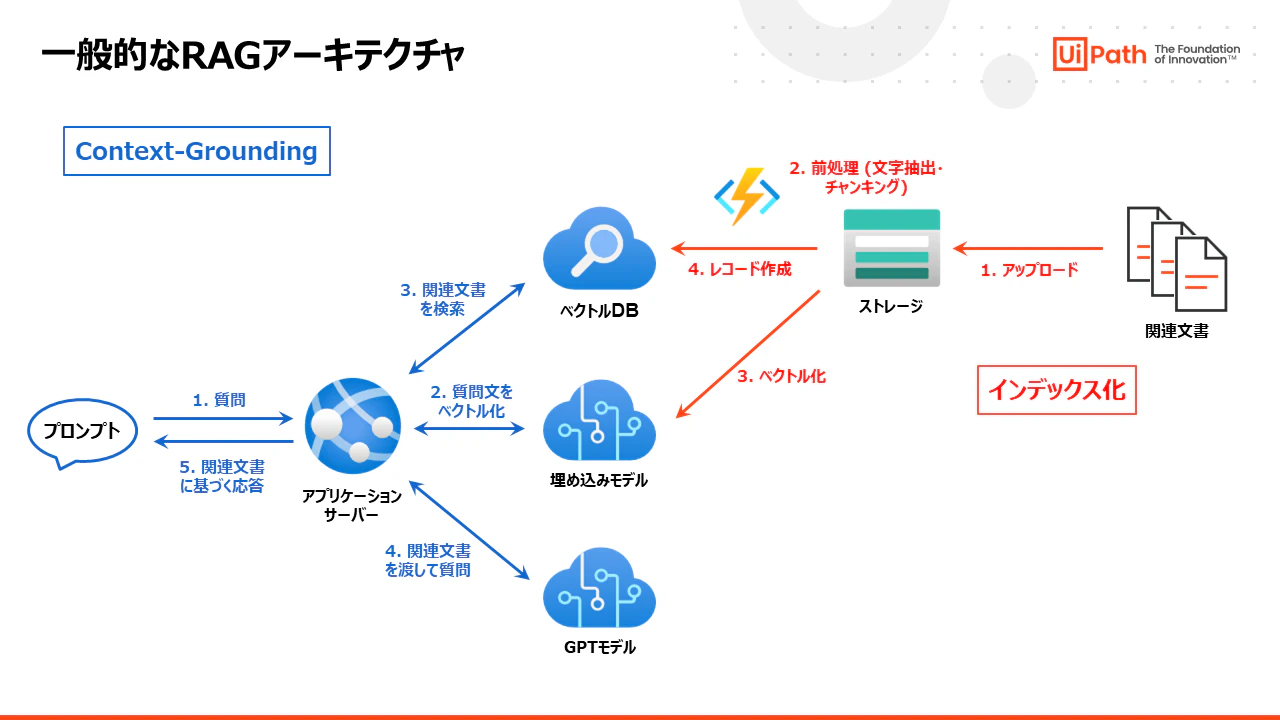
- 次に実装すべき大まかな処理内容としては、事前のインデックス化と関連文書に基づく応答(Context-Grounding)の2つがあります。
-
インデックス化 には下記の処理が必要となり、これらの一部はPythonコードなどによって実装します。
- 関連文書をストレージにアップロードします。
- 文書に対して前処理を行います。PDF文書から文字を抽出したり、長い文書を小さく分割(チャンキング)したりします。チャンキングする理由は、ベクトル化で使用する埋め込みモデルのトークンに上限がある(例: Azure OepnAI Service)ためです。また分割した方が類似検索の精度が良いという ベンチマークデータ もあります。
- チャンキングされた文書を埋め込みモデルに渡してベクトル化します。
- ベクトル化されたデータと元文書をベクトルDBにレコードとして追加します。
-
関連文書に基づく回答(Context-Grounding) をするには下記の処理が必要となり、これらの処理もPythonコードなどによって実装します。
- ユーザーから質問文(プロンプト)を受け取ります。
- 質問文を埋め込みモデルに渡してベクトル化します。
- ベクトルDBに質問文に関連した文書を検索して上位数件の文書を取得します。
- GPTモデルに関連文書と元の質問文を渡し、関連文書を参照して質問に回答するように指示をします。
- 関連文書に基づく応答をユーザーに返します。
-
インデックス化 には下記の処理が必要となり、これらの一部はPythonコードなどによって実装します。
- このようにRAGアーキテクチャを実現するにはサービスコンポーネントとそれぞれのロジック部分の処理においてPythonコードなどによる実装が必要となります。
AI Trust LayerによるContext-Groundingの実装
- ではAI Trust Layerを利用した場合、どのようにContext-Grounding(RAG)を実装できるでしょうか?
- まずサービスコンポーネントの事前準備は不要です。これらはAI Trust Layerによって準備・管理され、必要な処理が自動的にバックグラウンドで実行されます。またインデックス化やContext-Groundingの実装のためのPythonコードも不要です。
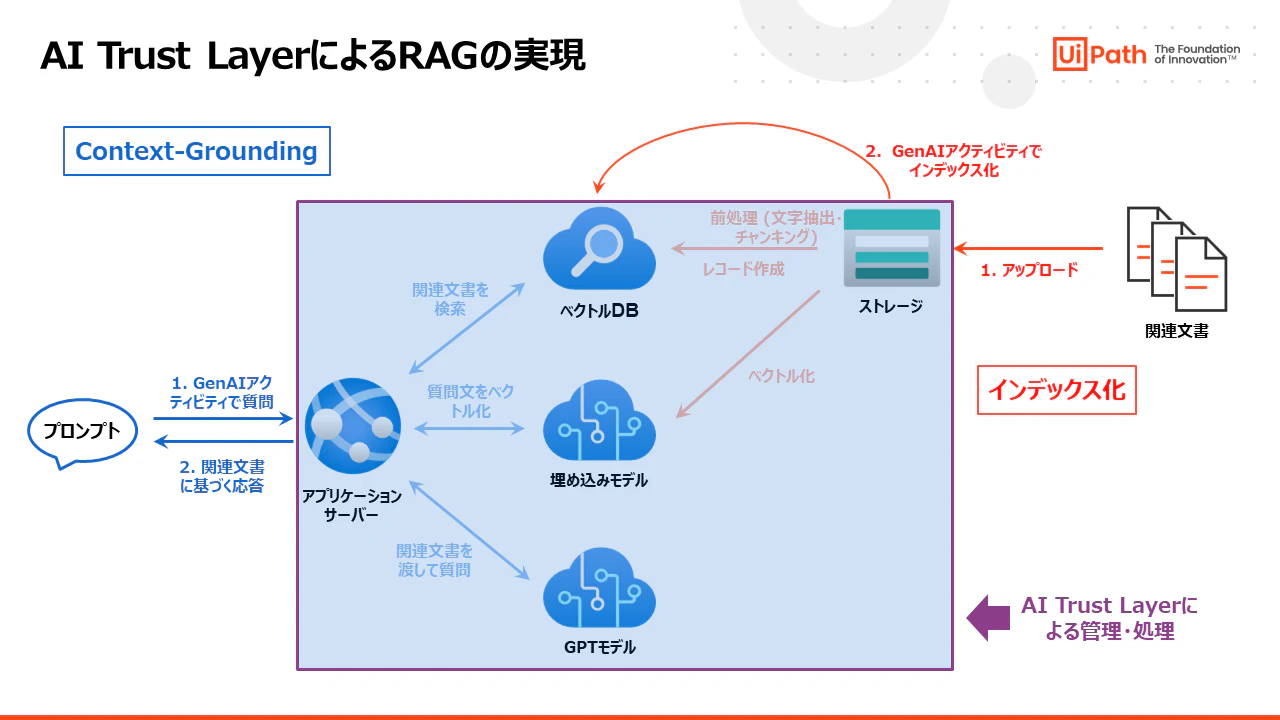
- 各処理の実装はいずれも UiPath GenAIアクティビティ を使用したワークフローで容易に実装できます。
- インデックス化処理
- 関連文書をストレージバケットにアップロードします。
- UiPath GenAIアクティビティを使用してインデックスを作成します。 この時インデックス名を指定します。
- 関連文書に基づく回答(Context-Grounding)
- UiPath GenAIアクティビティを使用し、インデックス名を指定して質問をします。
- インデックスに保存されている関連文書に基づく応答が得られます。
- インデックス化処理
- 実装はたったこれだけです!ベクトル化や関連文書などの処理はUiPath GenAIアクティビティによって自動的に実行されるため、ユーザーが個別に実装する必要はありません。一般的なRAGアーキテクチャと比較すると非常にシンプルに実装できることがお分かりいただけると思います。
Context-Grounding機能を利用するための前提条件
AI Trust LayerによるContext-Grounding機能を利用するためには次の準備が必要となります。
- UiPath Automation Cloud
- プレビュー段階ではCommunity版でもOKです。
- 今後Context-Grounding機能が一般リリースされた後は、AI Unitsなどのライセンスが必要となる可能性がありますが、プレビュー段階では無料でお使いいただけます。
- UiPath Studio WebもしくはUiPath Studio v2024.10以降
- Context-Groundingで関連情報として与える文書
- 現時点ではPDF, CSV, JSON形式のみサポート (今後拡大予定)
Context-Grounding機能の利用手順
- Context-Grounding機能を利用するためには次の手順を順次実行します。
- 関連文書のアップロード
- 関連文書のインデックス化
- インデックスを使用してContext-Groundingを実行
1. 関連文書のアップロード
-
Automation Cloud にサインインして、Orchestratorの管理画面に遷移します。
-
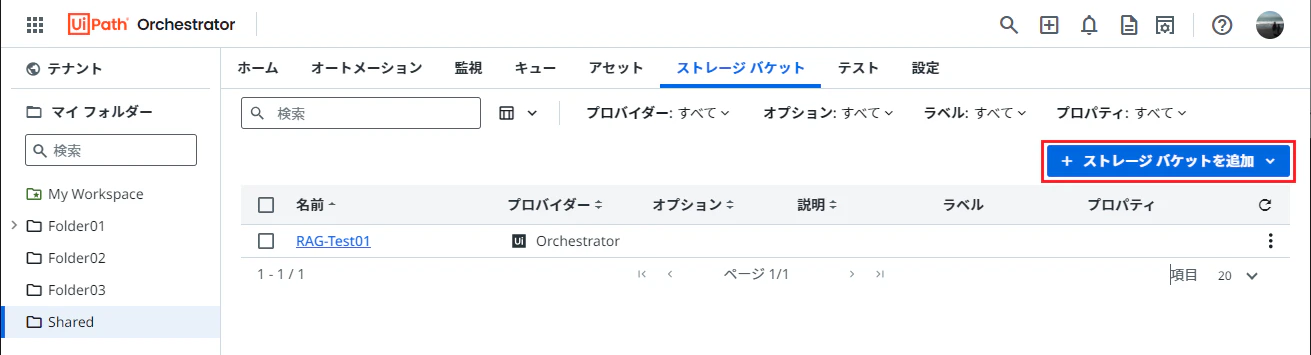
Orchestratorにてストレージバケットを作成します。
-
ストレージバケットは個人用ワークスペースではなく通常のフォルダー内に作成します。
-
-
ストレージバケットに関連情報となる文書をアップロードします。
-
今回は例として UiPath Orchestrator システムの基盤設計・運用ガイド[第3版] のPDFファイル(
UiPathOrchestrator_DesignOperationGuide_Rev3.1.pdf) を使用します。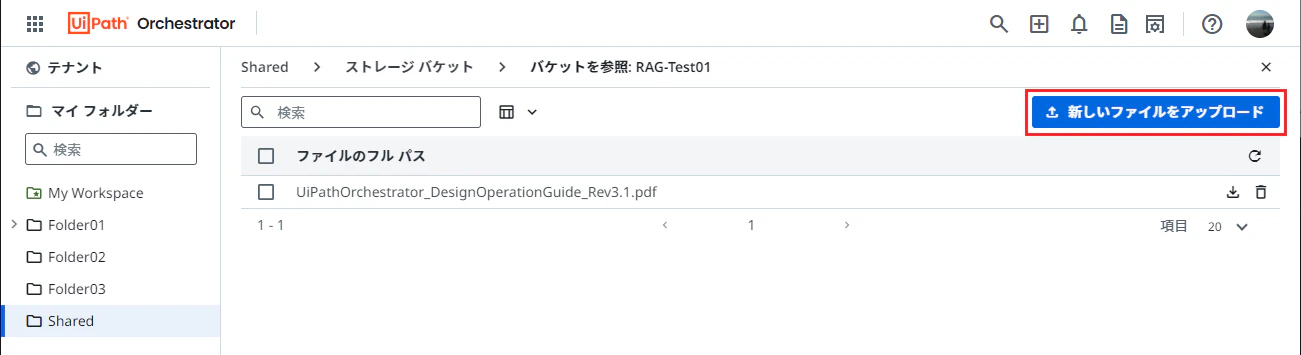
-
2. 関連文書のインデックス化
-
左メニューよりAutomation CloudのIntegration Serviceの管理画面に遷移します。
-
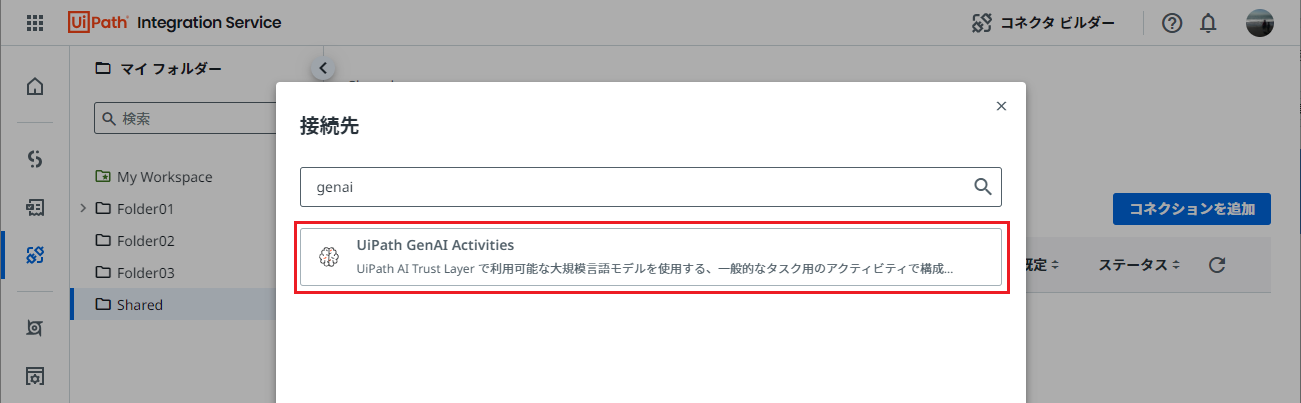
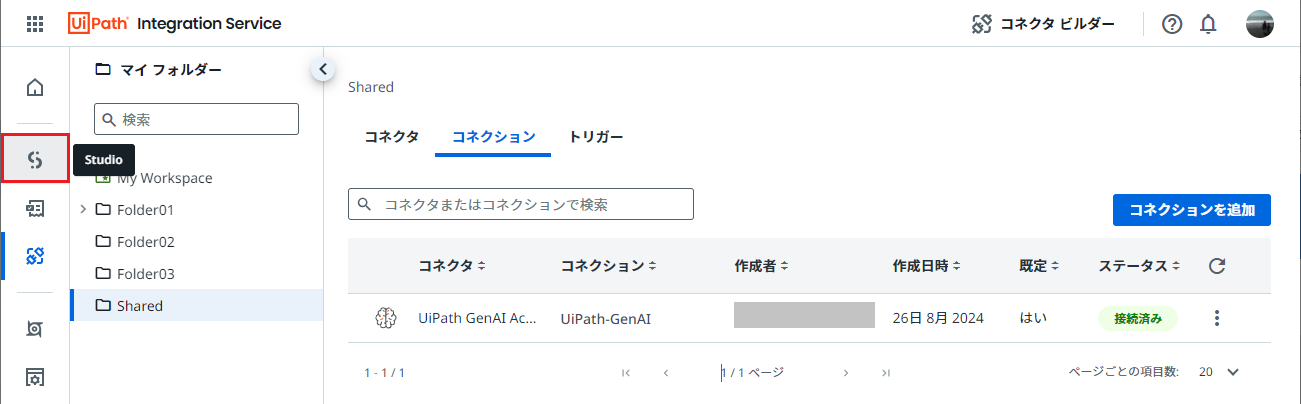
Integration Service > コネクションにて コネクションを追加 をクリックします。

-
UiPath GenAI Activitiesを選択し、接続 をクリックします。

-
左メニューよりStudio Webの管理画面に遷移します。
-
新しいプロジェクト をクリックして、新規ワークフローを作成し、オートメーションのトリガーとして「手動のオートメーション」を選択します。

-
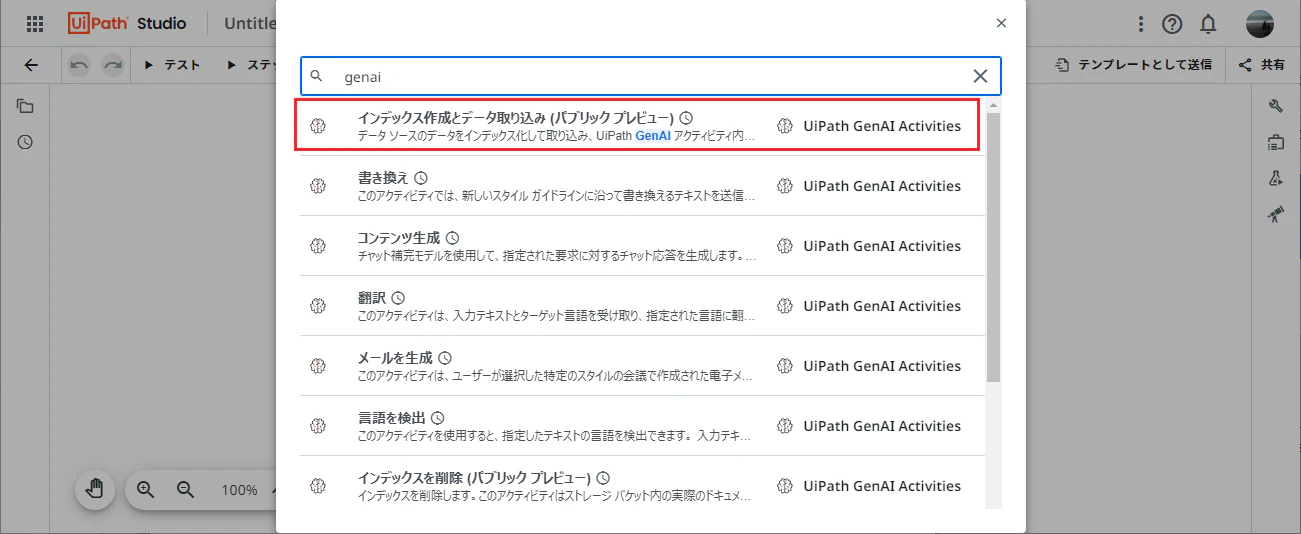
(+)をクリックし、UiPath GenAI Activitiesの インデックス作成とデータ取り込み を選択します。
-
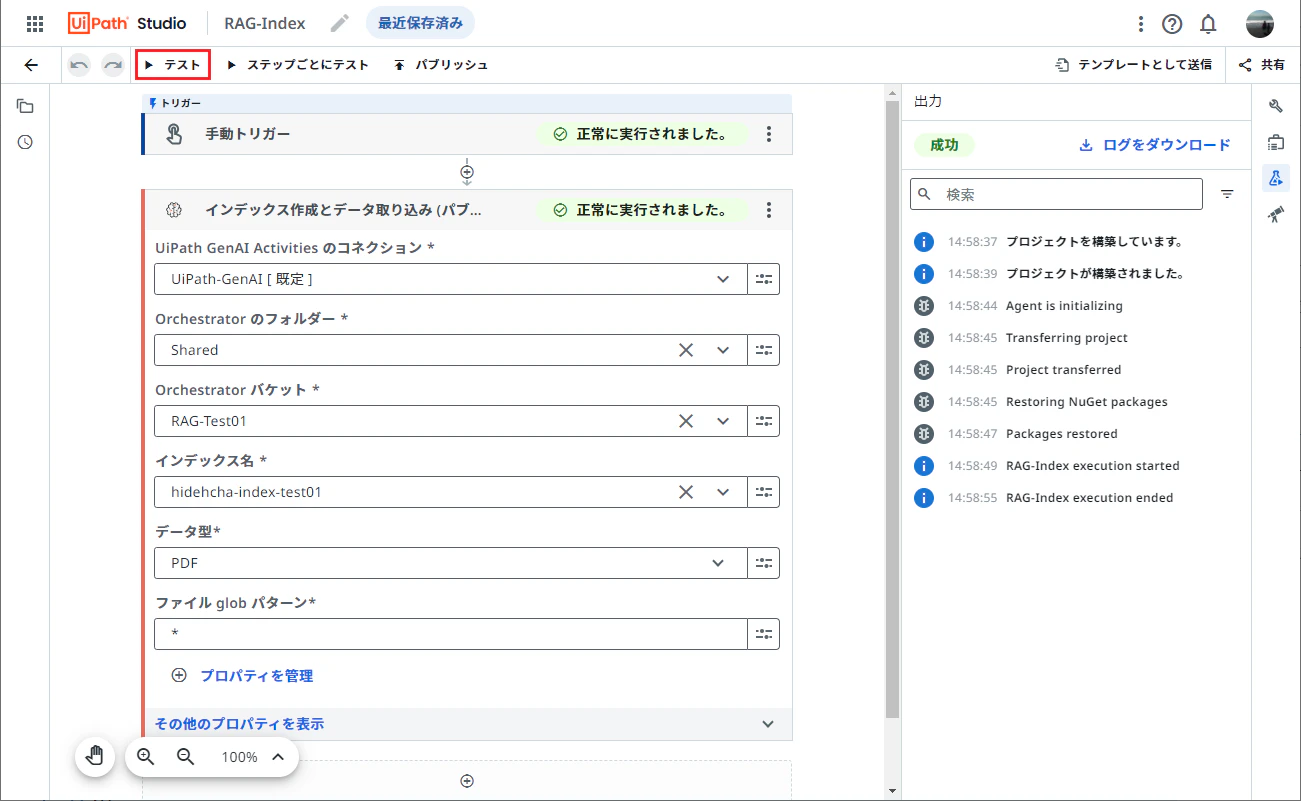
インデックス作成とデータ取り込み にて、各パラメーターを設定します。
- Orchestratorのフォルダー: ストレージバケットを作成したOrchestratorフォルダーを選択します。
- Orchestratorバケット: ストレージバケットを選択します。一覧より選択できない場合には 強制更新 をクリックします。それでも選択できない場合は [式エディター]を開く をクリックし、
"<ストレージバケット名>"を直接入力します。 - インデックス名: 新規作成するインデックスの名前を入力します。
- データ型: 関連文書の形式に応じてPDF, CSVまたはJSONを選択します。(今回は
PDFを選択) - ファイルglobパターン: インデックス化を行うファイルの拡張子を選択します。(今回は
*のままとします)

-
テスト をクリックして、ワークフローを実行し、エラーが発生しないことを確認します。
インデックス作成処理は非同期で実行されます。文書の量が多い場合にはインデックス作成完了までに時間を要することがあります。Webガイド によると、各ドキュメントが 1 MB 以下であると仮定して、通常は次の時間待機することが推奨されています。
- <10分: 10ドキュメント以下の場合
- <30分: 50ドキュメント以下の場合
- 最大 2時間: 50 以上のドキュメントの場合
3. インデックスを使用してContext-Groundingを実行
-
Studio Webにて別のワークフローを新規作成し、オートメーションのトリガーとして「手動のオートメーション」を選択します。
-
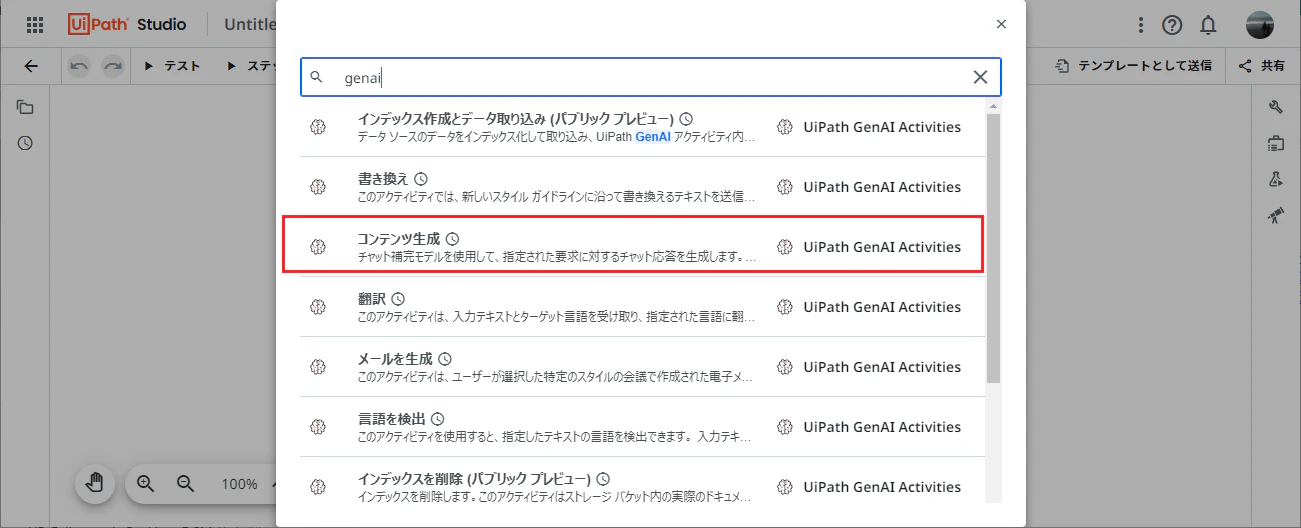
(+)をクリックし、UiPath GenAI Activitiesの コンテンツ生成 を選択します。
-
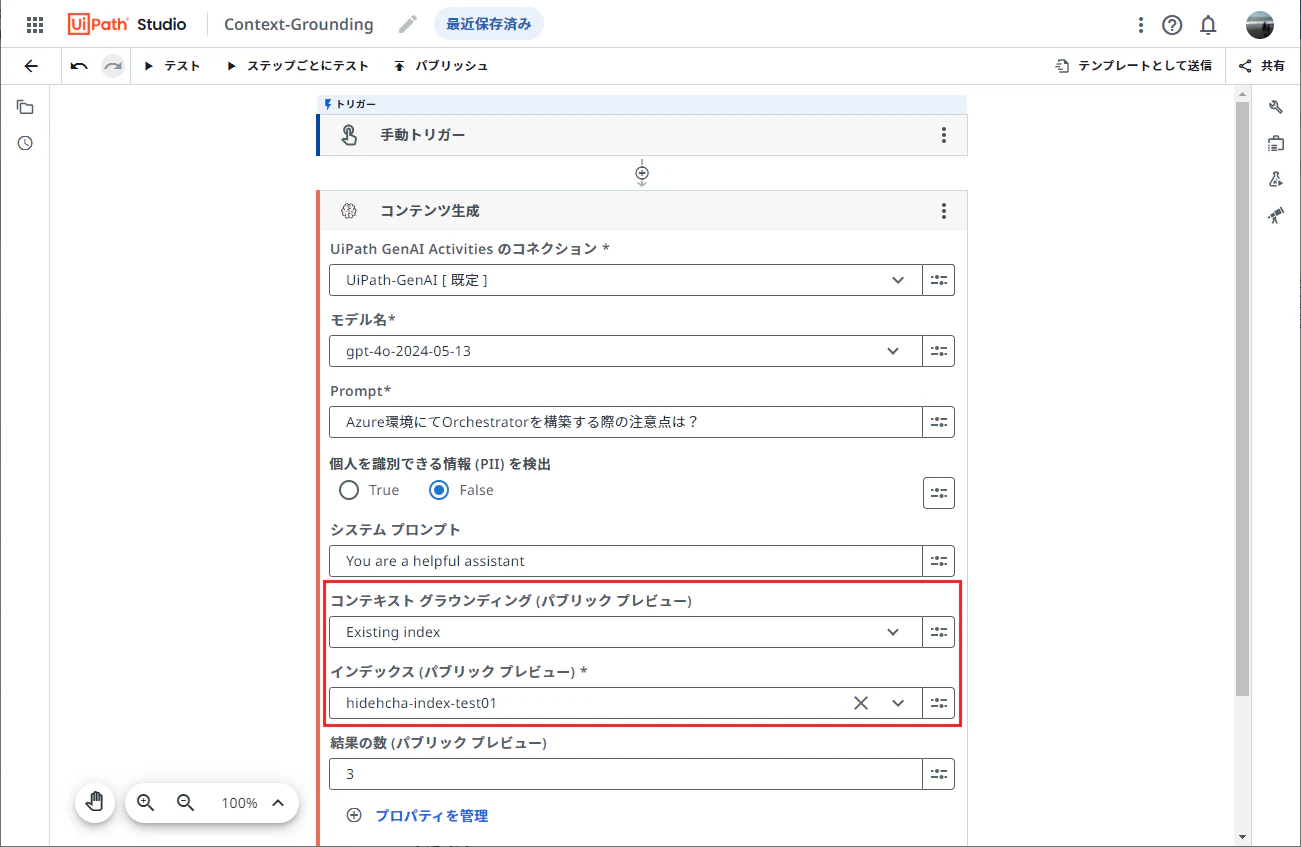
コンテンツ生成 アクティビティにて次のように値をセットします。
- モデル名:
gpt-4o-2024-05-13 - Prompt: 質問文を入力します。今回の例ではOrchestrator設定・運用ガイドに記載の内容について質問してみます。
「Azure環境にてOrchestratorを構築する際の注意点は?」 - コンテキストグラウンディング: Existing Index を選択します。
- インデックス: 先ほどインデックス作成処理にて指定したインデックス名を選択します。
- モデル名:
-
(+)をクリックし、メッセージをログ を選択します。
- メッセージとして、変数を使用 > コンテンツ生成 > Text を選択します。これによって関連文書に基づく応答が表示されます。
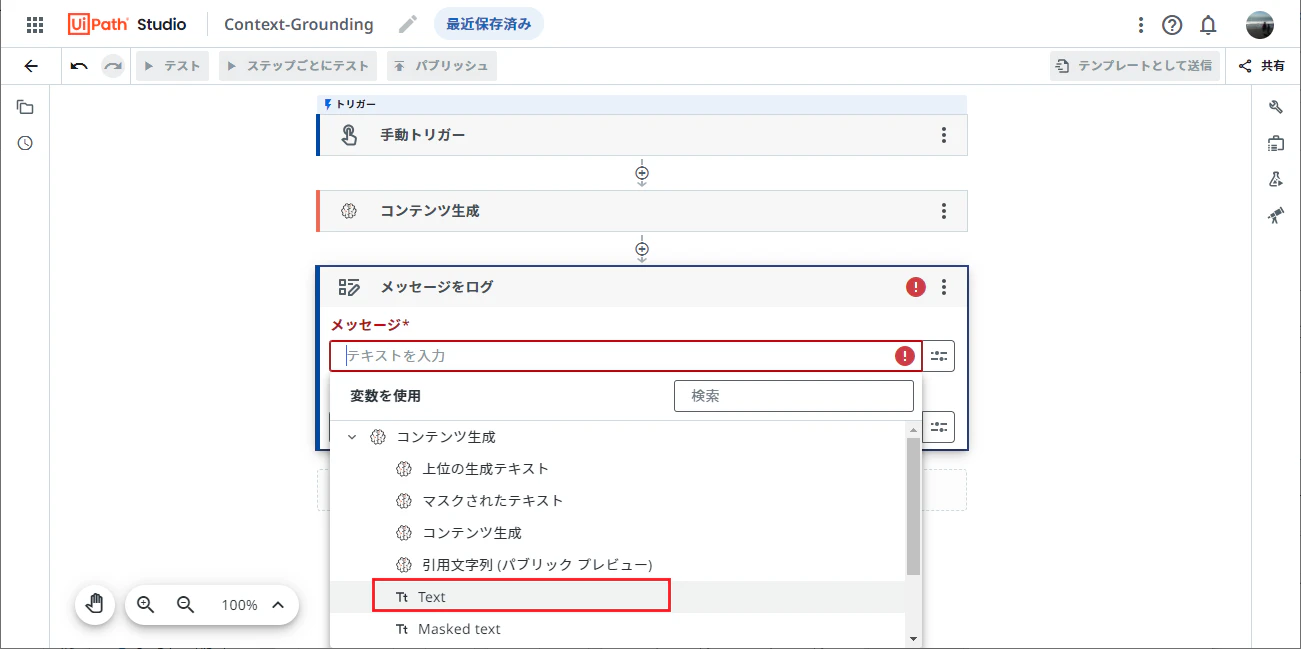
- メッセージとして、変数を使用 > コンテンツ生成 > Text を選択します。これによって関連文書に基づく応答が表示されます。
-
もう一度(+)をクリックし、メッセージをログ を選択します。
- メッセージとして、変数を使用 > コンテンツ生成 > Context grounding citations string を選択します。これによって応答が参照した関連文書の情報が表示されます。
-
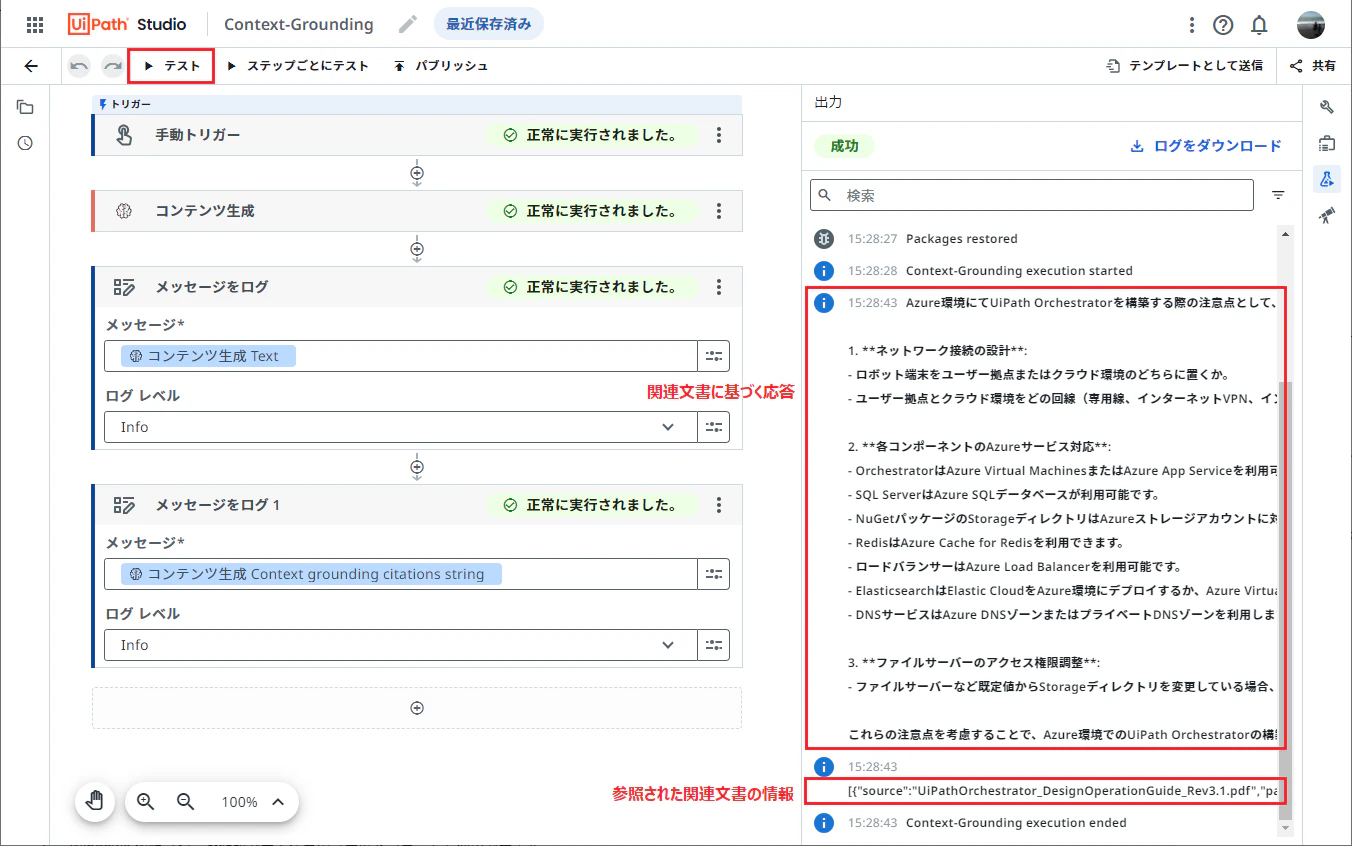
テスト をクリックして、ワークフローを実行します。
-
関連文書に基づく次のような応答が得られることを確認します。
Azure環境にてUiPath Orchestratorを構築する際の注意点として、以下の点が挙げられます: 1. **ネットワーク接続の設計**: - ロボット端末をユーザー拠点またはクラウド環境のどちらに置くか。 - ユーザー拠点とクラウド環境をどの回線(専用線、インターネットVPN、インターネット)で接続するかを決定する必要があります。また、もしユーザー拠点にロボット端末を置く場合、接続の方向はロボット端末からOrchestratorへの一方向となります[1]。 2. **各コンポーネントのAzureサービス対応**: - OrchestratorはAzure Virtual MachinesまたはAzure App Serviceを利用可能です。App Serviceの場合は、インストールスクリプトを用いて構築します。 - SQL ServerはAzure SQLデータベースが利用可能です。 - NuGetパッケージのStorageディレクトリはAzureストレージアカウントに対応し、BlobまたはFilesを利用可能です。 - RedisはAzure Cache for Redisを利用できます。 - ロードバランサーはAzure Load Balancerを利用可能です。 - ElasticsearchはElastic CloudをAzure環境にデプロイするか、Azure Virtual Machines (Windows ServerまたはLinux)にインストールして利用できます。 - DNSサービスはAzure DNSゾーンまたはプライベートDNSゾーンを利用します[1]。 3. **ファイルサーバーのアクセス権限調整**: - ファイルサーバーなど既定値からStorageディレクトリを変更している場合、アクセス権限に注意が必要です。OrchestratorをアプリケーションプールIDで動作させている場合、ビルトインアカウント(例: IIS AppPool\UiPath Orchestrator)を変更先ディレクトリに割り当てて、変更権限を付与します。また、AWS環境のAmazon FSxやAzure環境のAzure Filesを利用する場合も同様に、アプリケーションプールIDのディレクトリへの変更権限に注意が必要です[2]。 これらの注意点を考慮することで、Azure環境でのUiPath Orchestratorの構築と運用がスムーズに行えます。 -
上の応答で[1]や[2]は参照した関連文書の情報を指しています。Context grounding citations string の出力は次のようなJSON形式となっており、[1]がガイドのp51、[2]がガイドのp59を参照していることが分かります。
[ { "source": "UiPathOrchestrator_DesignOperationGuide_Rev3.1.pdf", "page_number": "51" }, { "source": "UiPathOrchestrator_DesignOperationGuide_Rev3.1.pdf", "page_number": "59" } ]
インデックスのライフサイクル
- インデックスの新規作成手順については既に説明をしましたが、インデックスの更新および削除は次の手順で実行します。
更新
- ドキュメントを追加して既存インデックスを更新するには、まずストレージバケットに文書を追加します。次に インデックス作成とデータ取り込み にて既存のインデックス名を指定し、ワークフローを再実行します。
- 基本的には新規インデックス作成時のワークフローの内容を変更する必要はありません。
削除
- 不要なインデックスを削除するには、UiPath GenAIアクティビティの インデックスを削除 を使用し、既存のインデックス名を指定してワークフローを実行します。
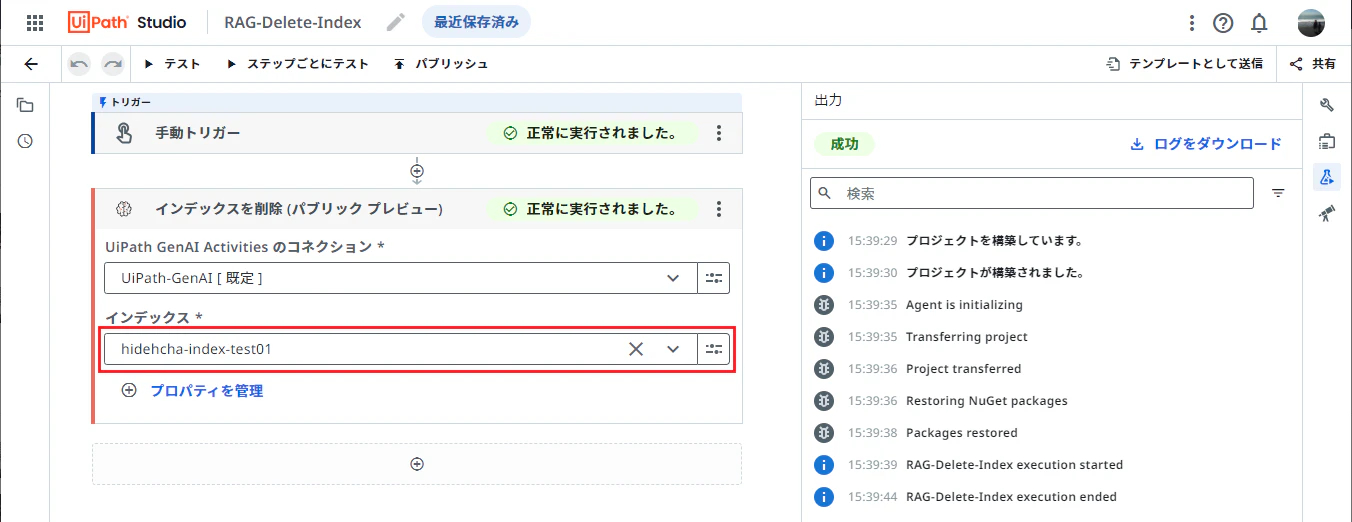
Webガイド によると、インデックスは1テナントあたり10個までという制限があります。この上限に達する場合には不要なインデックスを削除します。
インデックス管理上の注意点
- 現時点ではインデックスに含まれるレコードを参照したり、特定のレコードを変更・削除する機能はありません。
- 不要な文書がインデックスに混入してしまった場合には、一旦インデックスを削除し、正しい文書のセットを使用してインデックスを再作成する必要があります。この点は今後の改善に期待したいと思います。
おわりに
本記事ではUiPath AI Trust LayerによるContext-Grounding機能を実装するメリットと利用手順について説明しました。このようにUiPath GenAIアクティビティを使用することによって、AI Trust Layerが管理するサービスコンポーネントを利用して容易にContext-Groundingを実装できることがお分かりいただけたと思います。皆さまも是非お試しください!