1.やりたいこと
- アクセス統計サイトAlexaで各国TOPアクセスランクが公開されている。(1ページ25位分のHTMLx20ページで500位まで。)
- HTMLページをスクレイピングしてアクセスランクのURLリストを作る。
pyQueryを使ってみた。
Scrapyというライブラリも見つけたけどクローラ込みになっていて面倒そうなので敬遠。
beautifulsoupも良さそうだけど今回はpyQueryを試す。
2.インストール
$ yum install libxml2-devel libxslt-devel
$ pip install pyquery
pyQueryはlibxml2を使っているので先にインストールしておく。
pipが無ければそれもインストールしておく。
3.参考にしたもの(pyQueryサンプル)
pyQueryのサンプルを試す。試しに[ここ][Ref1]のサンプルコードをお借りして地震情報サイトをスクレイピングしてみた。
import pyquery
query = pyquery.PyQuery("http://www.jma.go.jp/jp/quake/quake_local_index.html", parser='html')
for tr in query('.infotable')('tr'):
print query(tr).text()
このコードでclass="infotable"の下層の<tr>タグの中身をforループでprintしている訳ですね。
chromeのデベロッパツールでhtmlの方の構成を調べてみると以下の通りでした。

python pqsample.pyで素直に以下の地震情報が取れた。確かに簡単。
情報発表日時 発生日時 震央地名 マグニチュード 最大震度
平成26年12月03日14時38分 3日14時32分頃 長野県北部 M1.6 震度1
平成26年12月03日06時03分 3日06時00分頃 長野県北部 M2.0 震度1
4.Alexaランキング解析
動くことが判ったので本命のサイトのスクレイピングに着手。
chromeで目的のページを開き、デベロッパーツール(CTRL-Shift-I)のウィンドウから虫眼鏡マークを押して、調べたい要素をクリック。下記の様にDOMツリーが表示される。(firefoxな方はインスペクタで調べられます。)
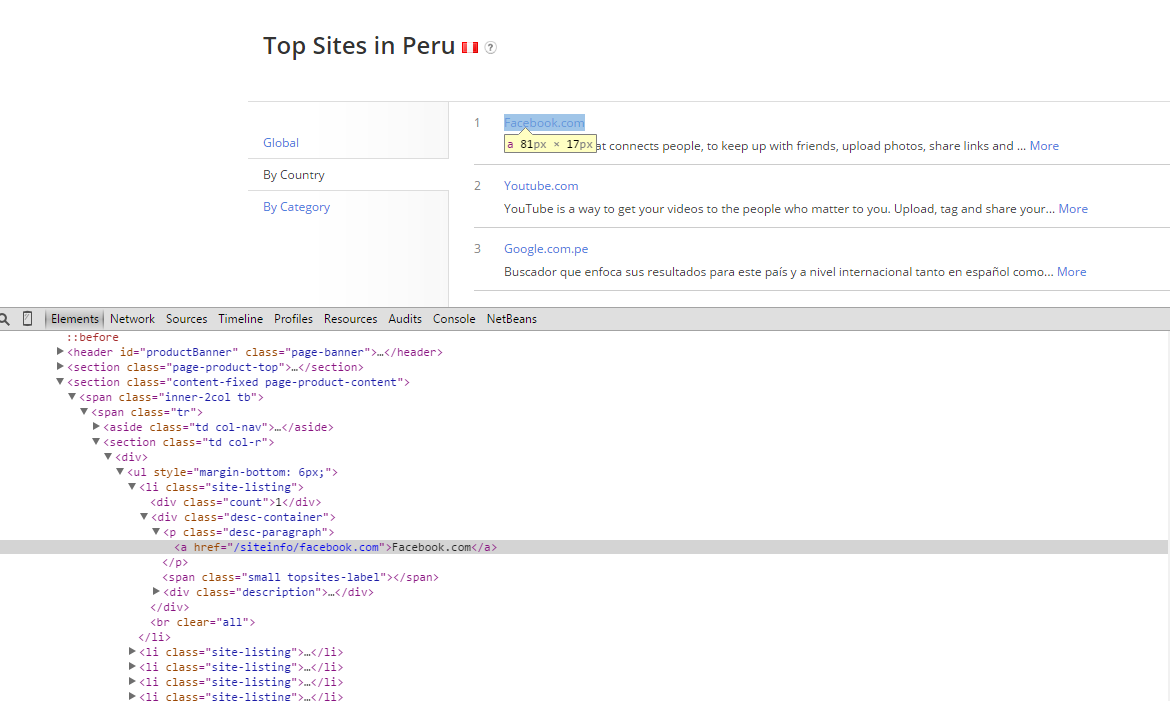
このツリー構成ならclass="site-listing"をキーに<li>タグをリストアップすればいけそう。countに順位が、desc-paragraph下の<a>タグにドメインが入っている。これらをforを回してcsvに出力するコードを書いてみた。
import pyquery
for page in range(20):
query = pyquery.PyQuery("http://www.alexa.com/topsites/countries;" + str(page) + "/PE", parser='html')
for li in query('.site-listing')('li'):
print query(li)('.count').text() + ", " + query(li)('.desc-paragraph')('a').text()
今回はペルーのランクを見る為に国コード/PEのページを指定。ここに国コードを指定すればその国のページが取得できる。日本なら/JP。本コードではHTMLページを20ページ分ループ。python alexa.py。

csvが出来た。NW障害などの際のcurlでの復旧確認などに。
5.まとめ
pyQueryでカット&ペーストしていた情報をスクレイピング可能。
(※頁構成変更のため現在動作しません。)
6.参考サイト