1. AmiVoice Cloud Platform
AmiVoice Cloud Platformは、アドバンスト・メディア社が提供する、音声認識APIです。
※ このAPIを使用した書き起こしサンプルプログラムも同社から提供あり。
※ 60分/月は毎月無料でAPIを利用可能。
サンプルプログラムには、実用上以下の課題点があると感じました。
1) 音声認識された結果として1文、2文程度の文章しか表示されない。
2) 音声認識された文章を途中で修正(編集)できない。
3) 後で確認可能な音声データを保存できない。
4) 音声認識はマイクの音声からのみ。
※ TeamsやZoom等の会議音声を直接認識してくれない。
5) あわよくば、会議中のTeamsやZoom等のアプリ画面を録画してくれれば・・
上記の課題点を改善する機能をサンプルプログラムに追加してみました。
2. 改修後のプログラム
上記を改修したプログラムは、こちら。
改修点は以下の通り。
1) 音声認識された結果をすべてテキストエリアに記載
2) テキストエリアの文章は途中でも修正可能に
3) 気になる所の音声データをテキストエリアの右に挿入可能に
4) 音声認識はsystem音声+マイク音声から可能に。
※ マイクはon/off可能に
5) 会議中のTeamsやZoom等のアプリ画面も録画可能に

3. 環境
プログラムはChromeで利用可能です。
※バージョン95にて動作確認実施
4. 使用方法
(1) ACPのサービスID/サービスパスワードの登録
本改修プログラムを利用するには、ACP(AmiVoice Cloud Platform)の登録が必要です。
ただし、60分/月は無料利用が可能なので、お試し利用が比較的容易に可能です。

ACPの登録を行って、マイページの「接続情報」より、
・サービスID
・サービスパスワード
情報を確認したら、改修プログラムの詳細設定欄を開き、該当箇所に入力します。
※この詳細設定欄は、ACPのサンプルプログラムにある設定項目と同じものです。

(2) 事前設定
書き起こし開始の前に、MediaStreamの許可設定をする必要があります。
※ いちいち許可ボタンをクリックするのがChromeの仕様らしく、MediaDevices.getUserMedia()等の許可をプログラム上でうまく記載して許可ボタンをいちいちクリックしなくてもよくなる方法がわかりませんでした。
⓪事前設定の実施
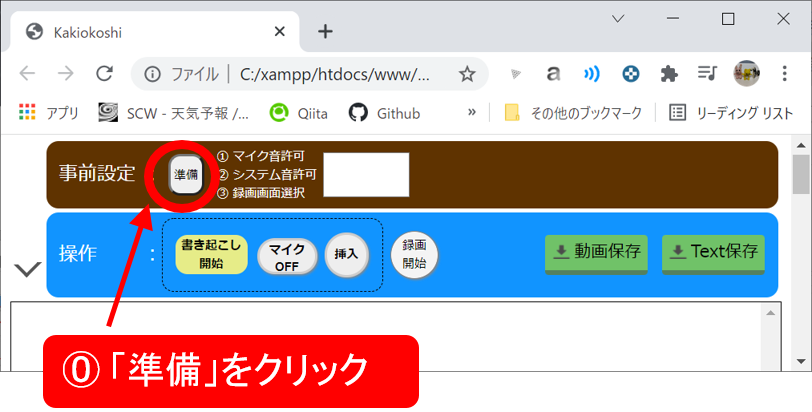
➀マイク音声の許可
マイク音声を拾うための許可をします。ただし、青い帯上にあるマイクのボタンがデフォルトOFF設定なので、ここで許可してもただちに書き起こしされたり、録音されたりはしません。

➁システム音声の許可
システム音声を拾う許可をします。アプリケーションから出る音声に対して音声認識をする方法として、システム音声を拾うことで対応しています。
※個別のアプリケーションの音声をWebRTCでどうすれば拾えるかわからず、システム音声での対応としました。その為、音声認識したいアプリケーション以外の音が発生している場合、ノイズとなってしまいます。(メールのポップアップ通知音等)また、アプリケーションの出力先のスピーカーと、システム音の出力先のスピーカーが同じものである必要があります。

➂ 録画画面の選択

録画する画面を選択。選択した画面を.webm形式で録画します。.webm形式でなくmp4にしたほうが汎用性があるかと思いましたが、現状ではChromeが対応しておらず、FFMPEG.WASMでどうにかmp4にできないか頑張りましたが、ローカルでhtml等のプロクラムをDLするだけで利用できるようにする、というコンセプトでは達成できそうになく、断念しました。

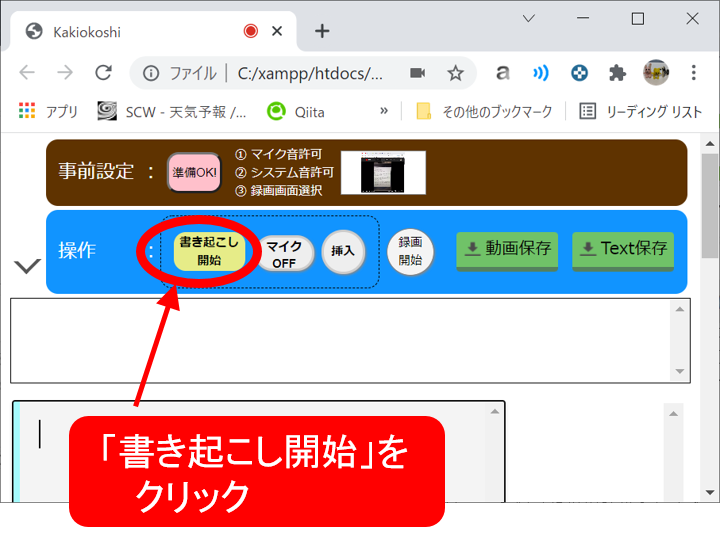
(3) 書き起こしの実施
書き起こししたいタイミングで「書き起こし開始」ボタンをクリックします。すると、再度マイクの許可が求められますので、許可を行い、音声の書き起こしを開始します。
※事前設定でマイクの許可を行ってますが、録画を継続的に行うために開始する際にも許可をクリックする必要があり、どうしてもなくせませんでした。
※無音声期間が数十秒続くとACPへの接続が切れる仕様で、切れるとボタンが黄色に戻るので、もう一度クリックして音声認識を再開させる必要があります。

操作帯(青色帯)のその他のボタン
・マイクON/OFF:マイクの音声認識のON/OFF切り替え
・挿入 :音声認識が怪しい箇所で、あとで音声を聞いて修正可能なように、
押下時の時間をテキストエリアに記載し、それまでの音声データを
テキストエリアの横に追加
・録画開始/停止:録画の開始、停止ボタン
・動画保存 :録画した動画をダウンロードフォルダに保存
・TEXT保存 :テキストエリアに記載されている文章をダウンロードフォルダに保存
5. その他
改修プログラムは、自分でも利用しながら実用に耐えうるのかを検証中で、改善点の修正&検証のトライ&エラー中です。
音声認識の精度は、100%近いものを期待しちゃいますので、そこにはやはり到達していません。
GoogleのSpeech to textの認識結果を並列して、精度の高いほうを選択可能なように、とも考えましたが、Googleのほうは会議時間でよくある30分や1時間の使用はできないよう。。Teamsでも日本語の音声認識や話者認識もできるようになったので、ACPの優位性が脅かされつつありますが、
・日本語に特化した「えーっと」とか「あのー」とかの認識削除機能がACPにはある
・Teamsの音声認識や録画は利用が相手にばれるのでこっそり利用できない反面、ACPの場合はこっそり利用可能
の点は優れているのかなと。
ACPの利用金額も、0.025円/秒とかで。結構使っても数百円/月額なのでお気軽に利用可能です。それで会議の議事起こし作業が楽になるなら願ったり・・。
また、内容が初見の場合や、議論で置いてけぼりになった際には、後で文章見ながら、気になる所を音声で再度聞く、っていうのもジミに役立ちます。
もし改修プログラムのカスタマイズや設定サポート等ございましたら、
hicarfter.d@gmail.com
までお気軽にお問合せいただけると幸いです。
6. 改修内容
Hr1.1:
・挿入ボタンについて、テキストエリアで記載中は「Alt」+「1」でショートカット可能なように。
・「挿入」ボタンを押した際に、テキストエリアに時間の記載だけでなくて、その時点での直前音声認識文章も赤字で挿入。
・ダウンロードするテキストのファイル名称から[~text.txt]のtextの文字を削除
Hr1.2:
・メモの冒頭に会議の日時を自動インプット
・マイクラベルを表記+音量を可視化