ジャーナルの論文(全部で100報超)から何報かピックアップするということがあって、最初は個別ページからとんでいたのですが、何十回もクリックしている内に虚無を感じたので、いっそ全部画像化して一覧できないか、ということでそのようなスクリプトを組みました。
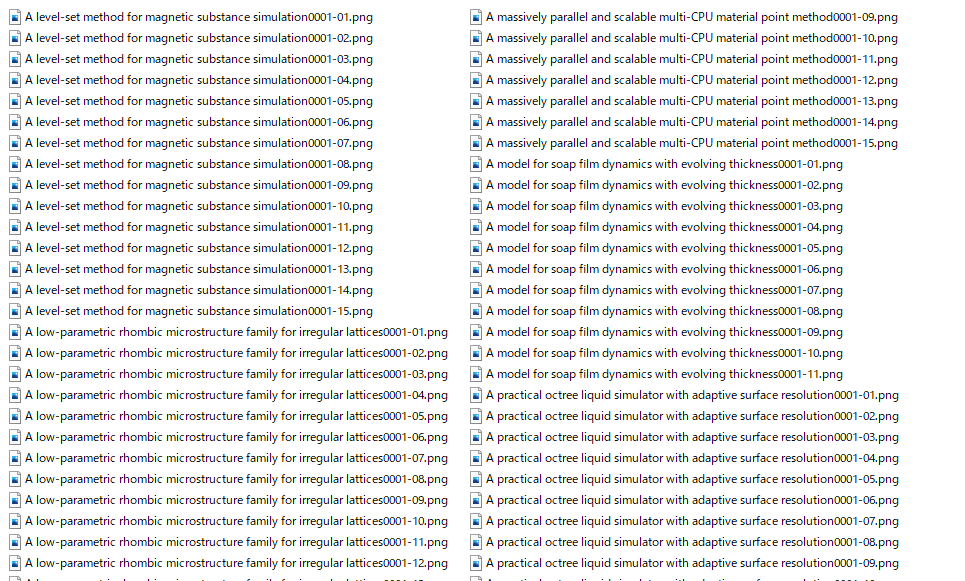

こんな感じで画像を取得した後、とりあえずタイトルと雰囲気だけを掴むために、各論文ごとにこのようなトリミングを行いました。

以下の手順からなっています。
- pdfのダウンロード
- pdfの画像化
- 先頭ページと概要の抽出
- 要覧の作成
pdfのダウンロード
対象としたはのこのページです。
import re
import requests
import pickle
import os
import cv2
import numpy as np
from pdf2image import convert_from_path
from PIL import Image
def source_to_url():
f = open('source.txt', mode='r', encoding='utf-8')
text = f.read()
pattern = r'title="Full Citation in the ACM Digital Library" href="(.*?)">(.*?)</a>'
reseult = re.findall(pattern, text)
f = open('url_title_list.pickle', mode='wb')
pickle.dump(reseult, f)
ソースコードから全論文のURLを抽出します。論文へのリンクは<a class="DLtitleLink" title="Full Citation in the ACM Digital Library" href="https://dl.acm.org/doi/abs/##.####/#######.#######">hoge</a>というhtmlタグで囲われていますので、それにヒットするような正規表現でfindallすればURLのリストが取得できます。別のページでも、正規表現を工夫すれば対応できる範囲かと思われます。
一度スクレイピングしたらpickleでローカルファイルに保存しておきます。
def url_to_pdf():
f = open('url_title_list.pickle', mode='rb')
url_title_list = pickle.load(f)
for url_title in url_title_list:
url = url_title[0]
url = url.replace('/abs/', '/pdf/')
title = url_title[1]
title = title.replace(':', '') # これをしないとファイル名エラーになるので注意
get = requests.get(url)
f = open(f'./pdfs/{title}.pdf', mode='wb')
f.write(get.content)
f.close()
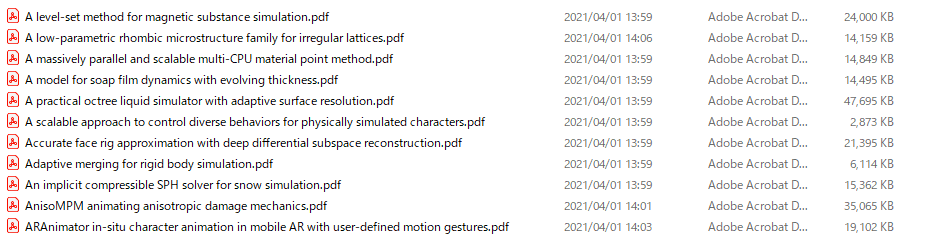
個別ページから論文本体のpdfへのリンクが取得できます。今回は、幸運にも個別ページのabsをpdfに変えるだけでよかったのでそのような処理にしていますが、そうでない場合には正規表現などで抽出します。あらかじめ用意しておいたpdfフォルダに以下のようなファイル達が出力されます。注意点として、:や?はファイル名に使えないのでエスケープしておく必要があります。
- pdfの画像化
pdf2imageというそのものズバリのライブラリがあったので使わせていただきました。参考にしたページでは、popplerというツールも合わせてインストール必要ということでしたが、私の環境ではpip install pdf2imageをするだけでいけました。バージョンは以下の通りです。
Python 3.7.4
pdf2image 1.14.0
pip 21.0.1
def any_exist(title):
current_dir = os.listdir('./pdf_images/')
for c in current_dir:
if title in c:
return True
return False
def pdf_to_image():
pdf_list = os.listdir('./pdfs/')
for pdf_name in pdf_list:
title = pdf_name[:-4]
if any_exist(title):
continue
pdf_path = f'./pdfs/{pdf_name}'
convert_from_path(pdf_path,
output_folder='pdf_images', fmt='png', output_file=pdf_name[:-4])
pdfフォルダにあるpdfファイルに、それぞれconvert_from_path()でファイルを出力していきます。予め用意しておいたpdf_imagesというフォルダに以下のようなpngファイル達が量産されます。
any_existという自作関数は、すでに画像が生成済の場合はスキップするような処理です。スクリプトを試している間に、時間削減のために必要になったので書いたものをそのまま起きましたが、なくてもまあ問題はないと思います。一つの関数内に収めるのも不可能ではないのですが、2重以上のループを遡ってbreakするにはフラグ変数を別に用意したりと結構めんどくさいので、スッキリ書くためにこうしました。
先頭ページと概要の抽出
次に、論文の雰囲気がひと目でわかるようにタイトルからメインの図(大体の場合は、論文の最初にある)を含む部分を抽出するようにしました。
def triming_top(img):
img_hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
for h in range(2200):
for w in range(1700):
if img[h][w][2] < 255:
print(h)
return h
return 550 #白黒のみだった場合は適当に4分の1
def triming_bottom(img):
img = img[::-1, :, :]
img_hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
for h in range(2200):
for w in range(1700):
if img_hsv[h][w][1] > 0:
print(2200-h)
return 2200-h
print(h)
return 550 #白黒のみだった場合は適当に4分の1
def extract_initial_pages():
image_list = os.listdir('./pdf_images')
for img_name in image_list:
if img_name[-6:-4] != '01' and img_name[-6:-4] != '-1':
continue
img = Image.open(f'./pdf_images/{img_name}')
img = np.array(img)
img = img[triming_top(img):triming_bottom(img), :, ::-1]
if img_name[-6:-4] != '01':
title = img_name[:-10]
else:
title = img_name[:-11]
print(title)
cv2.imwrite(f'./initial_pages/{title}.png', img)
pdf_imagesフォルダにが、1論文あたり大量の画像が生成されているので、その中から先頭ページを見つけ出す必要があります。pdf2imageの仕様から~0001-01.pngとなっているのでそれを抽出すればよい……とはならずに、出力枚数が10枚未満の場合、0001-1.pngとなってしまうので場合分けする必要があります。最初これに気づかずに一部の論文をロストしていました。システム的な親切が裏目に出てしまった。勝手に流用しているこちらに文句を言える義理はないのですが。
対策としては、マジックナンバーを使った愚直なif分岐でやりましたが、もっとかっこよく書けるような気もします。これを書いた時はけっこう疲れていたので動けばいいや精神でやりました。
抽出部分の上端と下端については、それぞれtriming_topとtriming_bottomという自作関数を用意しました。
triming_topでは、上の余白を削りたいので、画像を行→列を舐めていって、明度が255以下になるようなピクセルを検出した時点でその行をトリミング開始地点とします。triming_bottomでは、メインの図を含む部分から下を削りたいので、メインの図が終わる行を検出したいです。下の行から行→列を舐めていって、彩度が0以上になるようなピクセルを検出した時点でその行をトリミング終了地点とします。
以上のような処理をOpenCVを使って行っています。forで二重ループを回しているので、秒単位ですがけっこう時間がかかります。恐らくよりスマートに書く手段があると思われますが、これを書いた時はけっこう疲れていたので動けばいいや精神でやりました。
ところで、OpenCVだけを使えば済むような状態でわざわざPILを使って画像を読み込んでいるのは、cv2.imreadで特定の文字が読み取れないというエラーが起こるためです。日本語の文字が使えないのは有名ですが、なんと今回はフランス語でもエラーが出ました。具体的には、ベジェ曲線(B é zier curve)でエラーが起こりました。OpenCVは結構好きなのですが、このようなことが続くと嫌いになりそうです。
結果として、予め用意したinitial_pagesフォルダに、以下のようなpng達が出力されます。
脚注等に色付きの文字がある場合は、ほぼページ全てを抽出してしまいますが、おおむねいい感じにできています。
要覧の作成
ここまできたらやりたいことはほぼ100%できていますが、せっかく画像が出来たので、タイトルと抽出画像を並べて要覧化します。自分が見られればいいので、適当にhtmlファイルを生成します。
def make_html():
f = open('url_title_list.pickle', mode='rb')
url_title_list = pickle.load(f)
text = ""
for url_title in url_title_list:
title = url_title[1]
title = title.replace(':', '')
print(title)
text += f'<p>{title}</p>'
text += f'<p><img src="./initial_pages/{title}.png" width="100%" height="77%">'
f = open('index.html',mode='w',encoding='utf-8')
f.write(text)
以下のようなhtmlファイルが生成されます。

後はこれを高速スクロールしていけば、とりあえず論文の雰囲気だけは総覧できます。
ソースコード全文
import re
import requests
import pickle
import os
import cv2
import numpy as np
from pdf2image import convert_from_path
from PIL import Image
def source_to_url():
f = open('source.txt', mode='r', encoding='utf-8')
text = f.read()
pattern = r'title="Full Citation in the ACM Digital Library" href="(.*?)">(.*?)</a>'
reseult = re.findall(pattern, text)
f = open('url_title_list.pickle', mode='wb')
pickle.dump(reseult, f)
def url_to_pdf():
f = open('url_title_list.pickle', mode='rb')
url_title_list = pickle.load(f)
for url_title in url_title_list:
url = url_title[0]
url = url.replace('/abs/', '/pdf/')
title = url_title[1]
title = title.replace(':', '') # これをしないとファイル名エラーになるので注意
get = requests.get(url)
f = open(f'./pdfs/{title}.pdf', mode='wb')
f.write(get.content)
f.close()
def any_exist(title):
current_dir = os.listdir('./pdf_images/')
for c in current_dir:
if title in c:
return True
return False
def pdf_to_image():
pdf_list = os.listdir('./pdfs/')
for pdf_name in pdf_list:
title = pdf_name[:-4]
if any_exist(title):
continue
pdf_path = f'./pdfs/{pdf_name}'
print(pdf_path)
convert_from_path(pdf_path,
output_folder='pdf_images', fmt='png', output_file=pdf_name[:-4])
def triming_top(img):
img = img[:, :, :]
img_hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
for h in range(2200):
for w in range(1700):
if img[h][w][2] < 255:
print(h)
return h
return 550 #白黒のみだった場合は適当に4分の1
def triming_bottom(img):
img = img[::-1, :, :]
img_hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
for h in range(2200):
for w in range(1700):
if img_hsv[h][w][1] > 0:
print(2200-h)
return 2200-h
print(h)
return 550 #白黒のみだった場合は適当に4分の1
def extract_initial_pages():
image_list = os.listdir('./pdf_images')
for img_name in image_list:
if img_name[-6:-4] != '01' and img_name[-6:-4] != '-1':
continue
img = Image.open(f'./pdf_images/{img_name}')
img = np.array(img)
img = img[triming_top(img):triming_bottom(img), :, ::-1]
if img_name[-6:-4] != '01':
title = img_name[:-10]
else:
title = img_name[:-11]
print(title)
cv2.imwrite(f'./initial_pages/{title}.png', img)
def make_html():
f = open('url_title_list.pickle', mode='rb')
url_title_list = pickle.load(f)
text = ""
for url_title in url_title_list:
title = url_title[1]
title = title.replace(':', '')
print(title)
text += f'<p>{title}</p>'
text += f'<p><img src="./initial_pages/{title}.png" width="100%" height="77%">'
f = open('index.html',mode='w',encoding='utf-8')
f.write(text)
source_to_url()
url_to_pdf()
pdf_to_image()
extract_initial_pages()
make_html()