はじめに
最近ではDeepLearningを使って識別制度が上がったという話をよく耳にするようになりましたよね。
他の機械学習と組み合わせて最強の囲碁ソフトを作ったとか、自動運転に応用するとか、株取引をやらせるとか、最先端の技術はすごいなあと思います。
なので僕もやることにしました。
そもそもDeepLearningが一体何者であるにせよ、我々の生活を豊かにしてくれなければ、どんな凄いことをしても「へーすごいなー」で終わってしまう話です。自分の手元に届かなければ意味がない。なので僕は噂のDeepLearningに、僕自身の生活を豊かにしてもらうことにしました。
結論だけ見たい方は3年目まで飛ばしてください。1、2年目はただの苦労日記です。
概要
僕がやってほしいのは、二次元美少女の抽出作業です。
ツイッターやその他サイトを見ていて常々思っていることがあります。ネットサーフィンをしていると見かける二次元美少女の画像、これを推薦してくれるような仕組みはないものか……と。
今時はAmazonでも商品を推薦してくれますし、画面端に出てくる鬱陶しい広告も自分に合ったものを推薦してくれるような仕組みがあります。
僕の場合は下心を見透かされているのか、エッチな広告ばかり出てくる傾向にあるようですが、それ以外で「おっ、この女の子可愛い」と思ってしまうような画像は向こうからやってきません。
ぐっと来るような画像を探し求めていても、世の中に星ほど存在する美少女の中から自分の好みの美少女を探すのは至難の技といえます。
そういった画像に出会うために、いろいろな方法で検索を行うのですが、僕は絵師を追っていくこと、もう一つは好みのテーマ(作品名など)で検索を行うことをします。
しかし、この方法には問題があります。
前者の方法ではまず”絵師のことを知る”という工程が必要であり、むしろ知らない人のほうが多い場合が多く、かなりの画像を見逃してしまいます。
また後者のように、例えばアニメのキャラ名などで検索を行った場合、いろいろな絵師が書いている場合が多いので、観覧数上位でも自分の好みの絵柄だったり、そうじゃなかったり、観覧数が少ない中にも好みの画像があるので探しに行ったり……と、発掘作業が大変です。
どの場合も、やはり好みの画像に出会うのに相当な労力を必要とするわけですね。
そこで今回は、DeepLearningを用いて好みの画像を識別するという問題を解かせることによって、ネット上から収集してきた膨大な画像から自分に合ったものを推薦してくれるようなシステムを作れないかと考えました。
DeepLearningが流行って以来、世の中では深層学習の研究が数多く行われています。
しかし、こうした「好みの画像」といった曖昧なものを学習させる研究はほとんどありません。
そもそも評価実験やデータセット作りが難しいからか、またはこんな馬鹿馬鹿しいことを真面目にやろうと思う人が少ないためかもしれません。
実際、人間の好みなんてものは極めて曖昧なもので、その時の気分によって大きく変化することを実感しております。一度見た画像は、二度目に見た時には「あれ、こんな絵だっけ?」って思うこともしばしばですし、今日はこれが見たい!と考えた時には、その種類の画像が特に輝いて見えます。
こんな曖昧なものをコンピュータが計算できるのかと言われれば、首を捻らざるをえません。
しかし、勝算もあると考えています。
wikipediaのCNN(畳み込みニューラルネットワーク)の説明にはこう記されています。
特に2次元の畳込みニューラルネットワークは人間の視覚野のニューロンの結合と似たニューラルネットワークであり、人間の認知とよく似た学習が行われることが期待される。
人間の認知に似た学習が行われることが期待されているのです。
人間の認知に似た学習ができるなら、自分好みの美少女を人工知能が探してきてくれることも夢ではないのではと考えました。
研究者が「そんなデータセットも作れない上、不明瞭で評価もできないような実験できるわけない」と、男の夢も追わずに、何やら高尚なことばかり研究して見むきもしないというなら、僕が全力でやるしかありません。
データセット作成
さっそく機械学習を調教していくまえに、やるべきことがあります。
この煩悩の塊であるシステムを実現するために、どのような手段で、どのような識別を行わせるかを考えなければなりません。
CNNは画像を入れれば出力を出してくれるので、”好み”を学習させて、自動仕分けをしてくれるような仕組みを最終目標とします。
そこで問題になるのはどういう学習にするか、という点です。集めるデータセットは「二次元の女の子の画像」ですが、「何を出力してほしいのか?」が決まっていません。
そこでCNNの学習方法に注目します。CNNは「猫か犬か」という分類だけでなく「どのくらい猫に近いか、犬に近いか」という数値を出力することもできます(前者がいわゆる分類問題、後者を回帰問題といいます)。猫か犬か、0か1かときっぱり区切るのではなく、犬っぽさ30%、猫っぽさ70%みたいな風に、割合的な学習を行わせることができます。つまり「女の子がどのくらい自分の好みか」を数値化して、点数(パーセンテージ)を出力する。そんなデータセットを作成すれば目的を達成できると考えて、データセットの作成にとりかかりました。
深層学習を行う上で、もっとも大切なのがデータセットの量です。
どういうことかと言いますと、「犬」と「猫」を学習させるために、それぞれ一枚の画像を用意します。しかしCNNは犬猫に種類があるという概念どころか、生物の概念も何も知りません。
生まれたばかりの赤ちゃんがいたとします。仮に「これは犬かな、猫かな」と2択で質問しても、あてずっぽうに指を指すまで待つしかありません。正しい答えを出すためには、犬と猫の画像をいっぱい見せて、どちらが犬か猫かを教える必要があります。
深層学習も人間の脳細胞を真似したアルゴリズムを使っているだけあって、たくさんの画像を見せないと、うまく識別させることができません。まして今回の対象は「二次元の女の子の可愛さ」という、非常にふわっとした、本人にしかわかりえないものです。山のような画像が必要になるでしょう。
同じ女の子でも、人によって感じ方が違う。そんなものを学習させることができるのか。
この記事をご覧の皆様も半信半疑でしょうが、言い出しっぺは僕ですので、目標達成のためにデータセットを山のように集めて検証を行っていきます。
設定としては、まず二次元の女の子に1~5点と、整数の点数を割り振ることにしました。CNNにはその数値を学習させます。
そして、僕はデータセットを作る日々に明け暮れました。あらゆる女の子の画像を集め、そしてそれに点数を割り振りました。点数付けは本当にそのときの感覚で行ったため、明確に説明できません。(ここが、この実験が研究として行われることはない理由だと思います)
そして一ヶ月ほどかけて、作ったデータセットの枚数は、約12000枚。
pythonのBeautifulSoupライブラリを使ってWebクローラーなどのプログラムを組んだり、ツイッターでうまく収集したりしたので、収集自体は楽でした。しかし点数によってファイル分けをする作業はまさに地獄。もういいよ、と思いながら二次元美少女たちの海に溺れる日々にノイローゼ気味になったのは一生の思い出です。
特に3000枚タグ付けした頃が疲労のピークで、心が折れそうになりましたが、やめるわけにはいきませんでした。
なぜなら僕はこれを実装したいがために、深層学習を勉強したと言っても過言ではないからです。学習対象が二次元の女の子でなければ、とっくに心は折れていたに違いありません。
深層学習を研究にされる方は、学習対象とするもののデータセットが楽に作れるかどうかという点も考慮したほうがいいかもしれませんね。
Webクローラーやツイッターの情報収集方法に関しては、詳細は省かせていただきます。ですが自動収集は必ず導入したほがいいです。手作業でのデータセット収集は1000枚くらいでやる気が失せるのでお勧めしません(1敗)。
そして、12000枚の画像すべてに割り振りが完了しました。
ここまでくれば、あとは深層学習に放り投げるだけですので、苦労は報われ、未知の二次元美少女の笑顔に囲まれた生活が始まると、この時の僕は信じていました。
1年目 TensorFlowを用いた9層CNNの調教 〜失敗編〜
僕はCNNを使うために、まずゼロ知識の状態からTensorFlowを勉強することにしました。理由は、Googleが作っているライブラリで強そうだったからです。
このとき勉強した内容は別に記事にしたので、興味があればどうぞ。
学習にはpython2.7、OSはUbuntu16.04、GPUはGTX1080を使って学習を行いました。
CNNの構造は以下の通りとなっています。
NUM_CLASSES = 1
IMAGE_HEIGHT= 96
IMAGE_WIDTH = 144
IMAGE_PIXELS = IMAGE_HEIGHT*IMAGE_WIDTH*3
def inference(images_placeholder, keep_prob):
x_image = tf.reshape(images_placeholder, [-1, IMAGE_HEIGHT, IMAGE_WIDTH, 3])
### 畳み込み層1の作成
with tf.name_scope('conv1') as scope:
W_conv1 = weight_variable([5, 5, 3, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
### プーリング層1の作成
with tf.name_scope('pool1') as scope:
h_pool1 = max_pool_2x2(h_conv1)
### 畳み込み層2の作成
with tf.name_scope('conv2') as scope:
W_conv2 = weight_variable([5, 5, 32, 32])
b_conv2 = bias_variable([32])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
### プーリング層2の作成
with tf.name_scope('pool2') as scope:
h_pool2 = max_pool_2x2(h_conv2)
### 畳み込み層3の作成
with tf.name_scope('conv3') as scope:
W_conv3 = weight_variable([5, 5, 32, 64])
b_conv3 = bias_variable([64])
h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3) + b_conv3)
### プーリング層3の作成
with tf.name_scope('pool3') as scope:
h_pool3 = max_pool_2x2(h_conv3)
### 全結合層1の作成
with tf.name_scope('fc1') as scope:
W_fc1 = weight_variable([(IMAGE_HEIGHT/8)*(IMAGE_WIDTH/8)*64, 128])
b_fc1 = bias_variable([128])
h_pool2_flat = tf.reshape(h_pool3, [-1, (IMAGE_HEIGHT/8)*(IMAGE_WIDTH/8)*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
w_hist = tf.histogram_summary("W_fc1", W_fc1)
b_hist = tf.histogram_summary("b_fc1", b_fc1)
### 全結合層2の作成
with tf.name_scope('fc2') as scope:
W_fc2 = weight_variable([128, NUM_CLASSES])
b_fc2 = bias_variable([NUM_CLASSES])
w_hist = tf.histogram_summary("W_fc2", W_fc2)
b_hist = tf.histogram_summary("b_fc2", b_fc2)
僕の行った学習やり方としては、12000枚の画像を一気に学習させることがGPUメモリの関係でどうしてもできませんでしたので、さらに12000枚の中からランダムに100枚程度を抽出してオンライン学習を行わせることでCNNにそれぞれ50回づつ学習させます。
この時点で嫌な予感がした方が大勢いらっしゃると思います。
まず元画像のサイズはどれも少なくとも96*144の8倍はありますので、縮小化によってかなり情報が失われてしまっています。またメモリの関係で一気に学習が行えない点も、それはどうなの?って感じです。しかしメモリ8GBのGPUで、一度に読み込める縮小画像の限界枚数が100枚程度だったので、妥協せざるをえませんでした。
さて、この結果で誤差は小さくなるのかというのが問題ですが、結果から言えば誤差は小さくなりました。
上記の試行を3000回繰り返すことで、最初は誤差率1.3とかを出し続けていたのが、最終的には0.45程度まで減少しました。さらに1000回ほど学習を行わせましたが、誤差は減らなかったのでここで学習をストップさせました。
結果は…語るまでもなく、ダメでした。
2年目 Chainerに二次元美少女を放り投げた話 〜転移学習編〜
実はこのプロジェクトを始めて2年目のこの頃、僕は大学院生になりました。
進学理由は「深層学習を勉強したいから」です。それだけ聞くと意識高えーって感じですが、省略せずにいうと「未知の二次元美少女に楽して出会いたいから大学院に進学する」です。
・・・
さて、一年目の失敗を生かし、改めてどのようなアプローチで深層学習を訓練していけばよいかを考えることにしました。そして、失敗の原因は以下のようなところにあると考えました。
1.リサイズによって元画像が小さくなりすぎている(例:102412803 → 961443)
2.そもそもCNNを1から学習させるのは無謀
まず1についてですが、これはいうまでもなく画像の情報が落ちすぎています。画像を1/10程度に縮小していたわけですが、そんなことをした日には、いくら元が「何をしても可愛ければ許される」と評判の美少女といえども、CNNが見るのは何がなんだかわからないモザイク画像です。
実際にリサイズして見て確かめましたが、人間でも無理ですよあんなの振り分けるの。
先ほども少し話しましたが、僕のやろうとしている方法ではGPUメモリが不足してしまい、訓練プログラムを動かすことさえできませんでした。そのため、いろいろな部分を落としに落として、あのネットワーク構造になったわけです。
なので、仮にこのまま続けるならば、この問題を解決しなければ前には進めません。
次に2についてですが、深層学習系の先行研究を見ていると、それぞれ専用の特化したネットワークを使ってオリジナルの学習を行なっている例が多数見受けられました。
Googlenetやらlenetやら、さまざまな学習済みネットワークが存在します。
これは簡単にいうと、僕らのような個人が手に入らないような大量のリソースを割いて、大量のデータセットから訓練を行い、特徴抽出を行なったあとのネットワークを公開してくれている優しい企業からの贈り物というわけです。
使って良いよと言ってくださっているので、僕は使います。まだ見ぬ美少女に出会うために。
今年の学習にはAlexNetを用いることにしました。
こちらは2012年のILSVRCという画像認識のコンペで優勝した超すごいネットワークです。ネットワークの詳細に関しては、既に解説してくれている方が大勢いらっしゃるので省かせていただきます。
こちらを使おうと思った理由として、新しく大学院生になった時に研究室の先輩が使っていたので、一番簡単に教えてもらえそうだったからです。
この場をお借りして、某先輩にお礼申し上げます。色々とありがとうございました。
...あとこんなクソ企画のためにリソースをたびたび割かせてしまいすみませんでした。
今回の学習環境は去年と同じで、今度はChainerを用いることとしました。
転移学習(既存のネットワークを読み込んで、その上からオリジナルの学習を行う方法)にはkerasあるいはchainerを用いるのがいいようです。他でもできないことはないのですが、既存のやり方を書いている人が大勢いるのでとても楽です。
そしてAlexNetを使うことで1の問題は解決しました。理屈はわかりませんが、とにかくGPUメモリの問題は発生せず、学習を進めることができるようになりました。
そして今回はalexnetの導入によって、画像の入力層のサイズを3606403も確保することができるようになりました。全結合層中間層は1024、出力は同じく1、回帰問題を解かせる形としました。
class Alex(chainer.Chain):
def __init__(self, xy_weight=1.0, cs_weight=1.0):
initializer = chainer.initializers.HeNormal()
super(Alex, self).__init__(
conv1=L.Convolution2D(3, 96, 11, stride=4),
conv2=L.Convolution2D(96, 256, 5, pad=2),
conv3=L.Convolution2D(256, 384, 3, pad=1),
conv4=L.Convolution2D(384, 384, 3, pad=1),
conv5=L.Convolution2D(384, 256, 3, pad=1),
fc6_=L.Linear(53504, 4096, initialW=initializer),
fc7_=L.Linear(4096, 4096, initialW=initializer),
fc_pose_xy=L.Linear(4096, 1, initialW=initializer),
)
self.train = True
self.xy_weight = xy_weight
学習回数は50回。しかし誤差率の平均おおよそ0.01程度まで下がっていたため、これはもういけただろう...と、思い込んでいました。
最強のネットワーク。最高の先輩。そして手元にはデータセット。
そして当のAlexnetはというと。
ぼく「この女の子かわいくない?」
alexnet「???」
収束はしたのですが、結果はダメでした。てんでバラバラです。
そして僕は敗北の原因を全て打ち砕かれ、そして気力を失って一年間寝込むことになります。
(嘘です、研究したり遊んだりしてました)
3年目 darknetを用いたアニメ顔認識 & AlexNetを用いたアニメ顔スコアリング 〜卒業編〜
さて修士も2年目を迎え、就職活動も終わった頃になって僕は新しいネットワークに出会うことになります。
ある日のことです。後輩が深層学習をやらなければならなくなり、そのためにyoloという新しいネットワークの学習を始めたのを耳にしました。
「なんか聞いたことあるけどyoloってどんなネットワークだ? 物体認識に強いって聞いたことある気がする」
これが、この頃の僕の認識でした。
ちなみにYoloというのはリアルタイムでオブジェクト認識を行うことのできる、darknetというフレームワークを利用したネットワークです。
https://pjreddie.com/darknet/yolo/
そして、そのネットワークに関する話を既に触り始めた後輩に色々聞いているうちに、僕はふと思いついたのです。
今まで気づかなかった問題点。
それは僕が二次元美少女の「画像を丸ごと放り投げてしまっている」点です。
通常、二次元美少女画像には女の子だけが写っているわけではありません。例えば複数の女の子や、男が映っていたり、背景にめちゃくちゃバリエーションがあったり……とにかく一枚の画像から得られる情報が多すぎたのではないか、と思い至りました。
あまりに情報が複雑すぎると、教えられる側はどこを見ていいかわからないというも無理のない話。
そこで思いついたのが「あれ、俺どこを見て画像の良し悪しを判断しているんだ?」という話。
教えるべき場所を絞って与えてやりさえすれば……
「当然、女の子は顔だよな!」
最低ともとられかねない発言ですが、非実在少女に対する発言なので、ご容赦いただけると助かります。許してください。当たり前ですが三次元の場合は違いますから。
つまり何が言いたいかというと「二次元美少女の顔だけを切り抜いてネットワークにぶちこめば、うまくいくんじゃないか?」と考えたわけです。
試す価値はありそうだと判断した単純な僕は、早速ネットで二次元美少女の顔切り抜きについて検索しました。
Opencvの、カスケードによるアニメ顔検出機が一番有名でした。
https://github.com/nagadomi/lbpcascade_animeface
他にはあまり見つからず、またyoloを使った記事はほとんどアニメキャラの識別のためにアノテーションを行なっており、汎用の顔識別機を作っている前例はありませんでした。
なので、まあopencvでできるんだったらいいかと、試しに例の12000枚のデータセット全てに顔認識をかけて、どの程度顔が認識されるのか試しました。
結果…おおよそ2割程度。
しかも2割は認識したと思いきや、実際は顔以外も認識してしまっていたので、最終的には1割半程度。
これを実際に使うとすると、つまり土俵にあがる前に8割程度の画像を見逃すということ。残念ながらこのままでは使えません。
なので僕はまず汎用のアニメ顔検出機を作ることにしました。
Yoloのネットワークについて軽く勉強したのですが、これがめちゃくちゃ簡単にできてしまいます。yoloのネットワークをそのまま用いますが、学習済みパラメータを読み込まずに学習を行いました。
さて、アニメ顔検出のために僕は再びデータセット作りに勤しみました。
具体的には12000枚の画像から顔の位置情報をtxtに書き込む、地獄のアノテーション作業の始まりです。出力のためのタグはanime_faceという1種類に限りました。
やりました。
最初は1000枚を、先ほどのopencvの顔認識による自動アノテーション+手動アノテーションでxywhの座標値を記した.txtを生成して、学習をかける。
そして学習したネットワークにさらに12000枚の画像を入れて顔認識を行い、そこから得られたアノテーションデータから手動で追加、消去を繰り返して再学習する。
これにより大規模データセットを作成し、非常に精度の高いアニメ顔検出機を作成しました。
以下に認識を行なった画像例を示します。
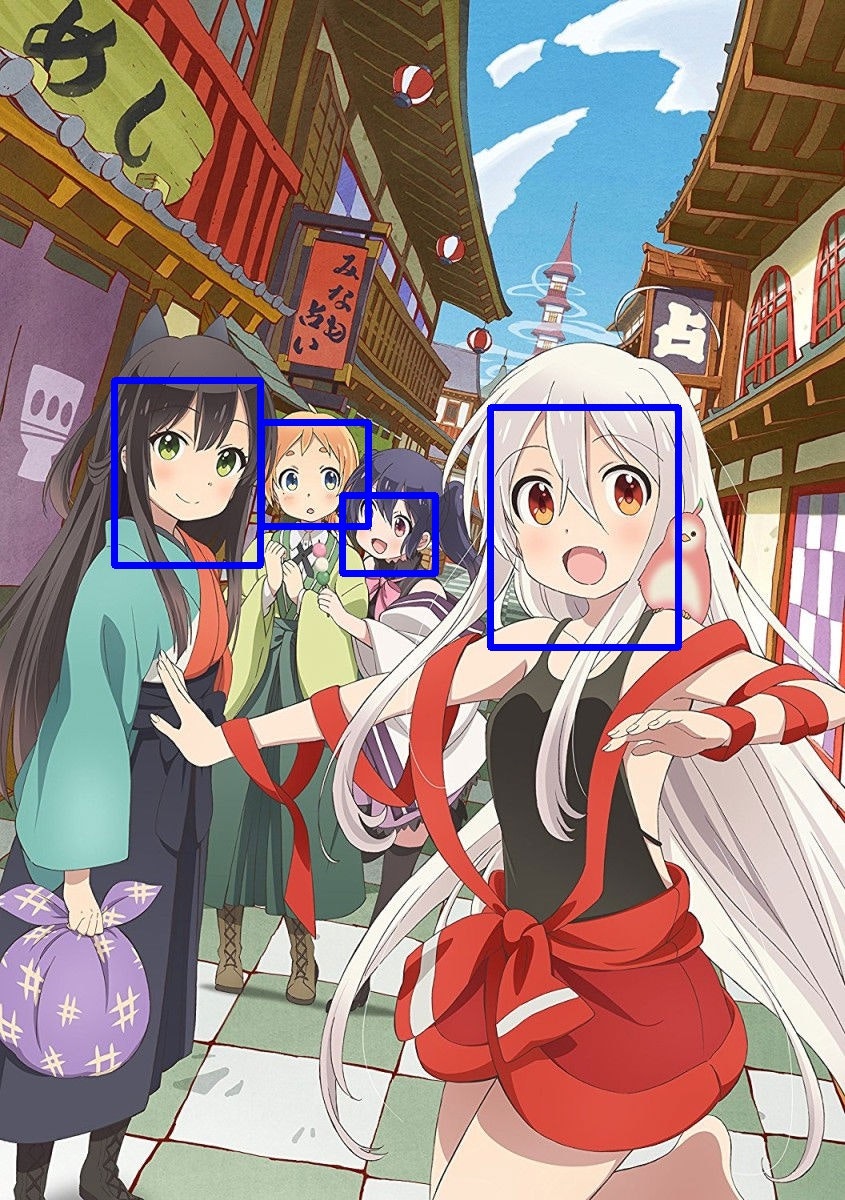


(きららアニメじゃなくても、かなりうまくいきます)
未知画像でもyoloから顔を切り出すことができるようになったため、まず3年目計画の前段階は完了したといえます。
そしていよいよ最後はこの顔データをalexnetで学習させるだけです。
入力層では顔画像を3603603にリサイズし、出力層は2年目と同じものを使用します。学習回数は50回。誤差率の平均もおおよそ0.01程度まで下がりました。
こうして完成したネットワークのテストを行います。
今回のテストでは1〜5の点数を割り振った500枚のデータセットを用います。内訳はそれぞれの点数の画像が100枚づつです。これらは、学習に使った12000枚の画像に含まれていません。
これをdarknetで顔切り出しを行って、alexnetでスコアを出力した、その結果の分布を以下に示します。
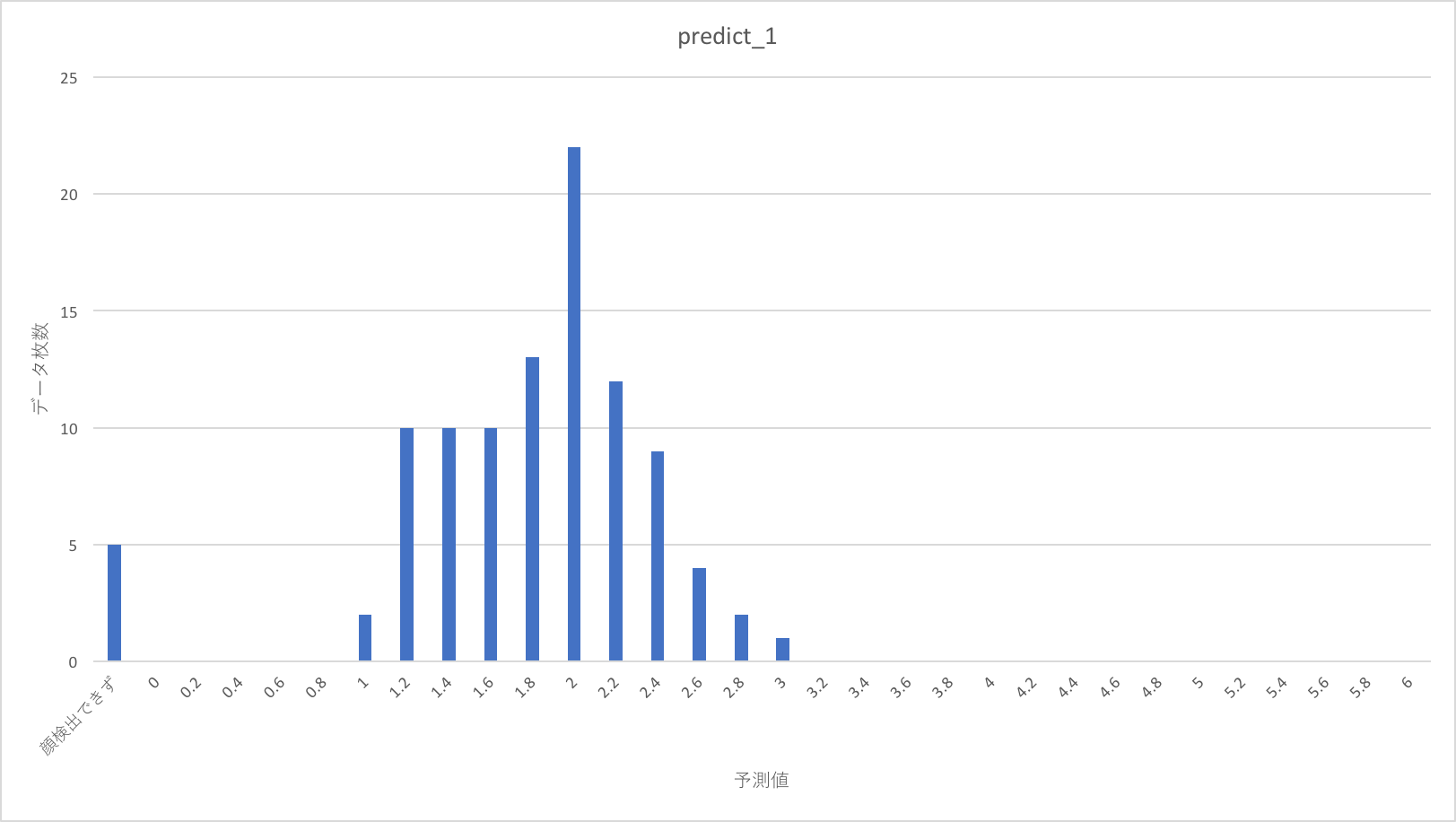
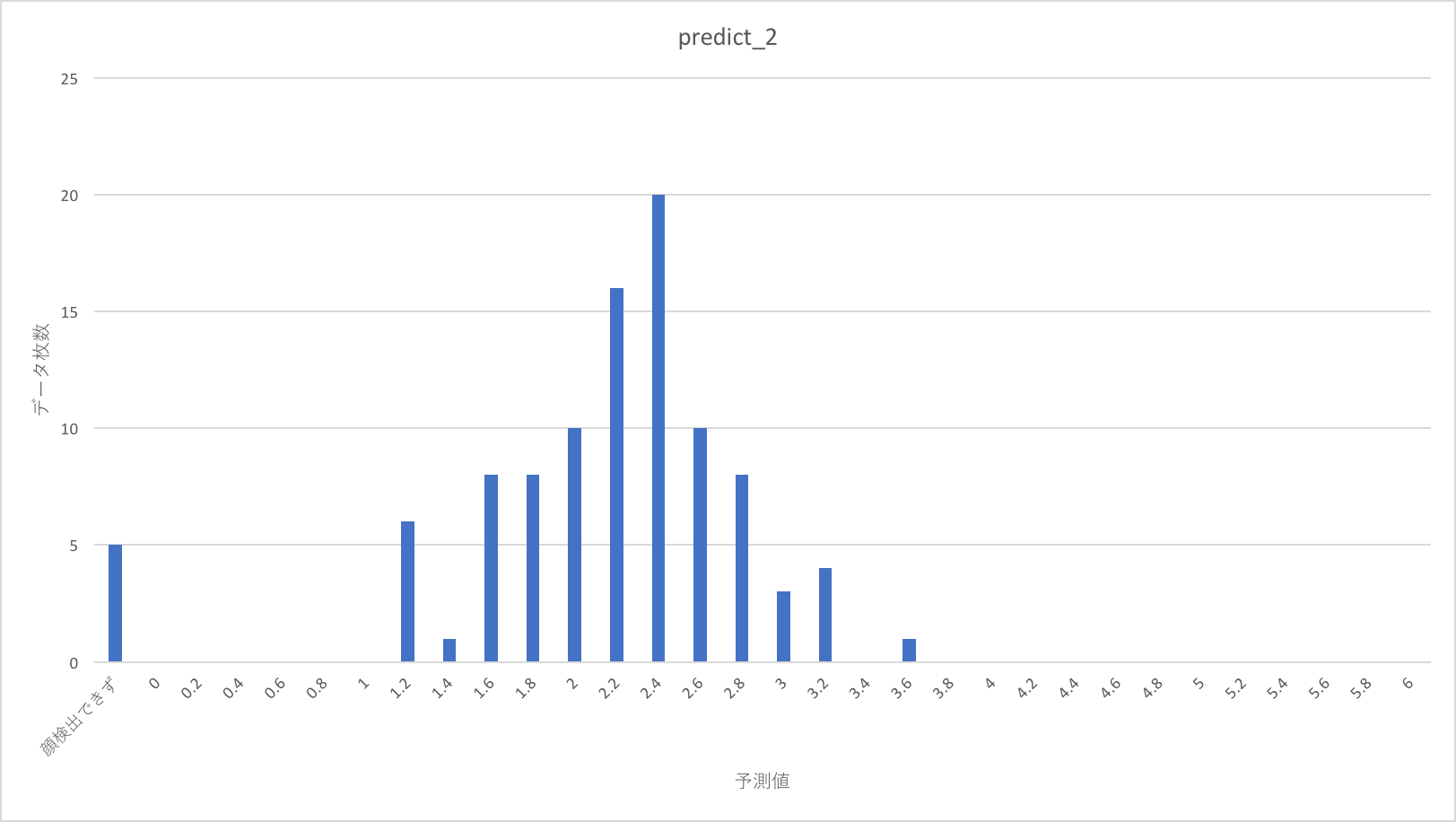
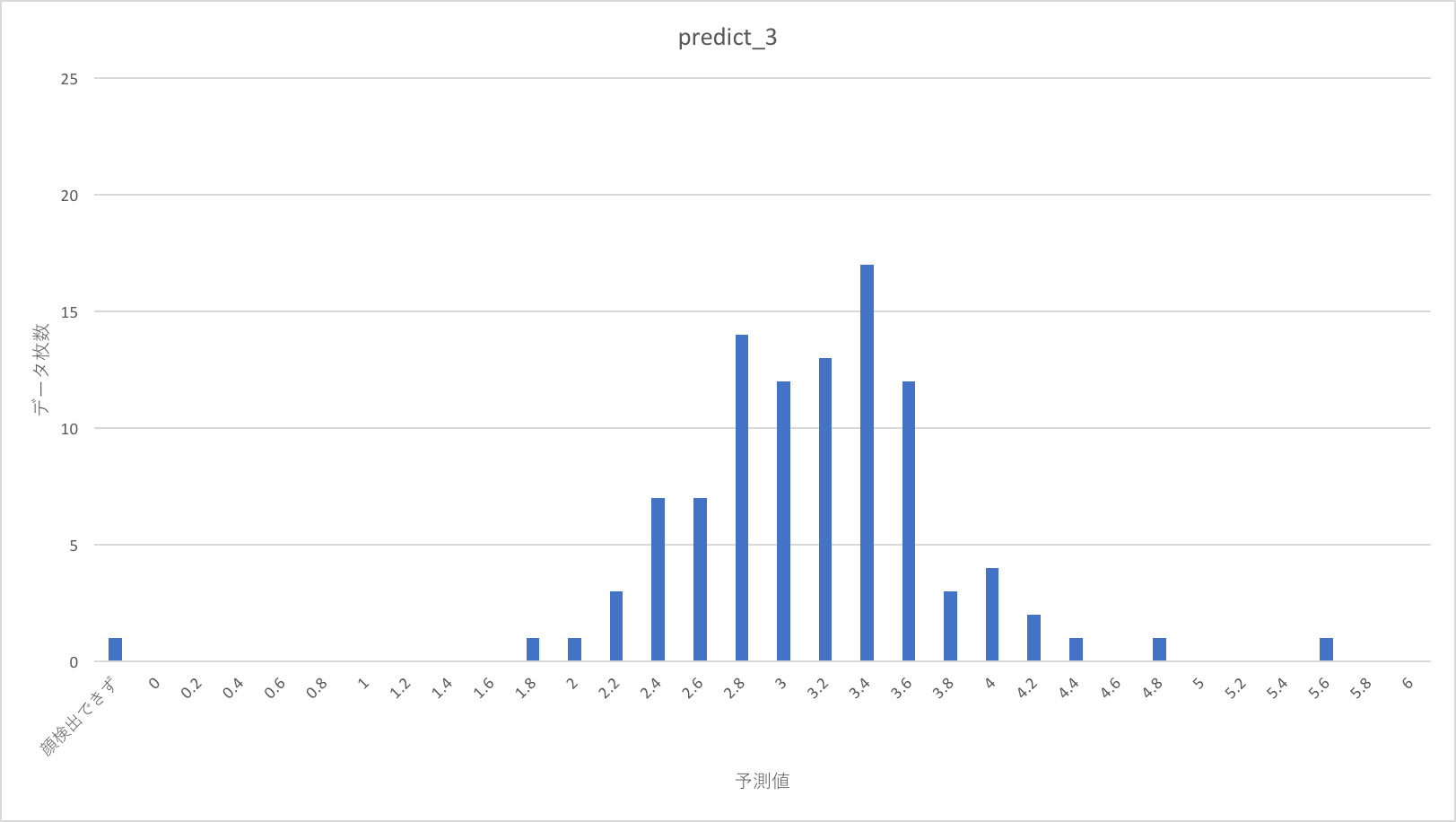
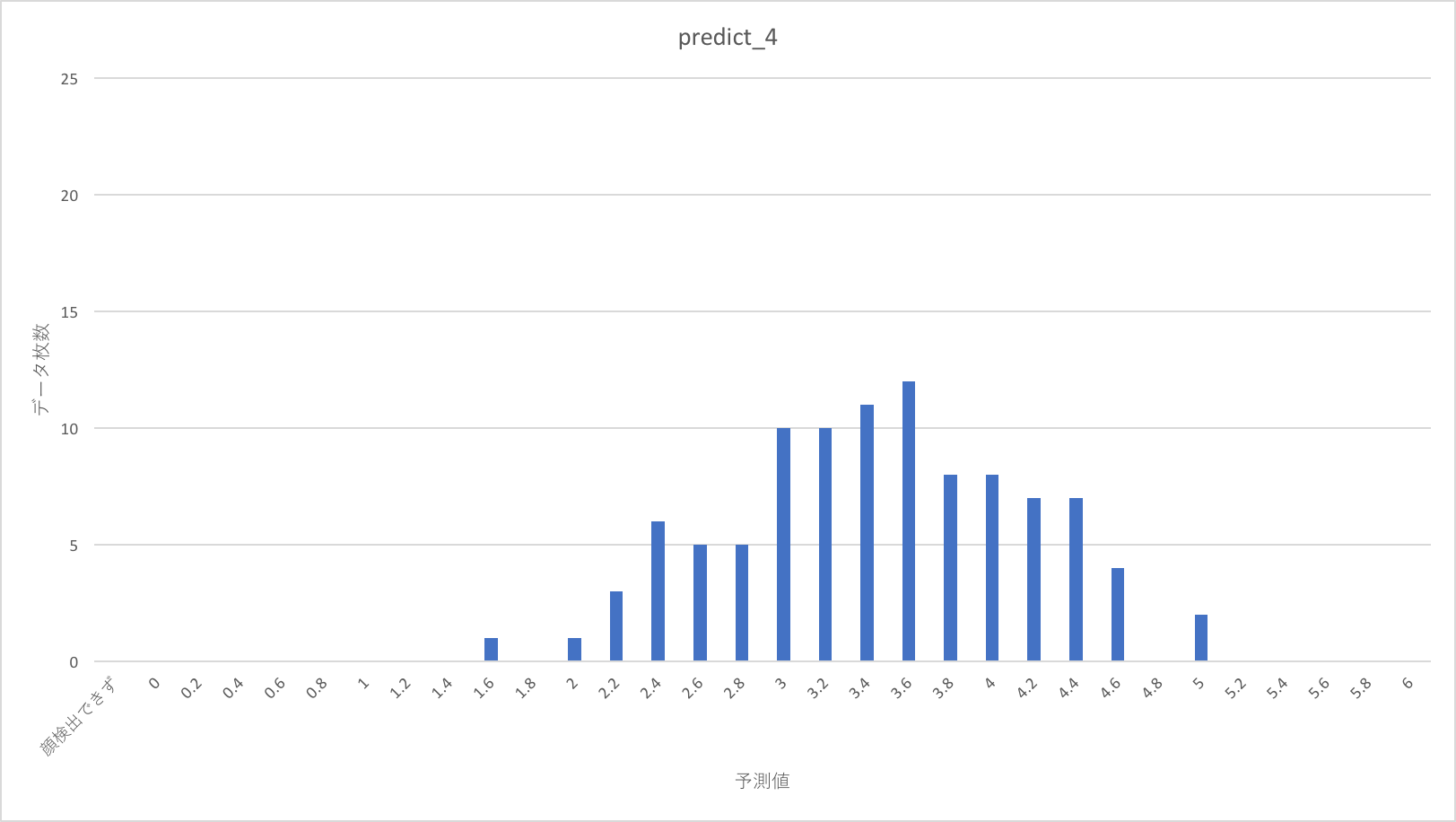
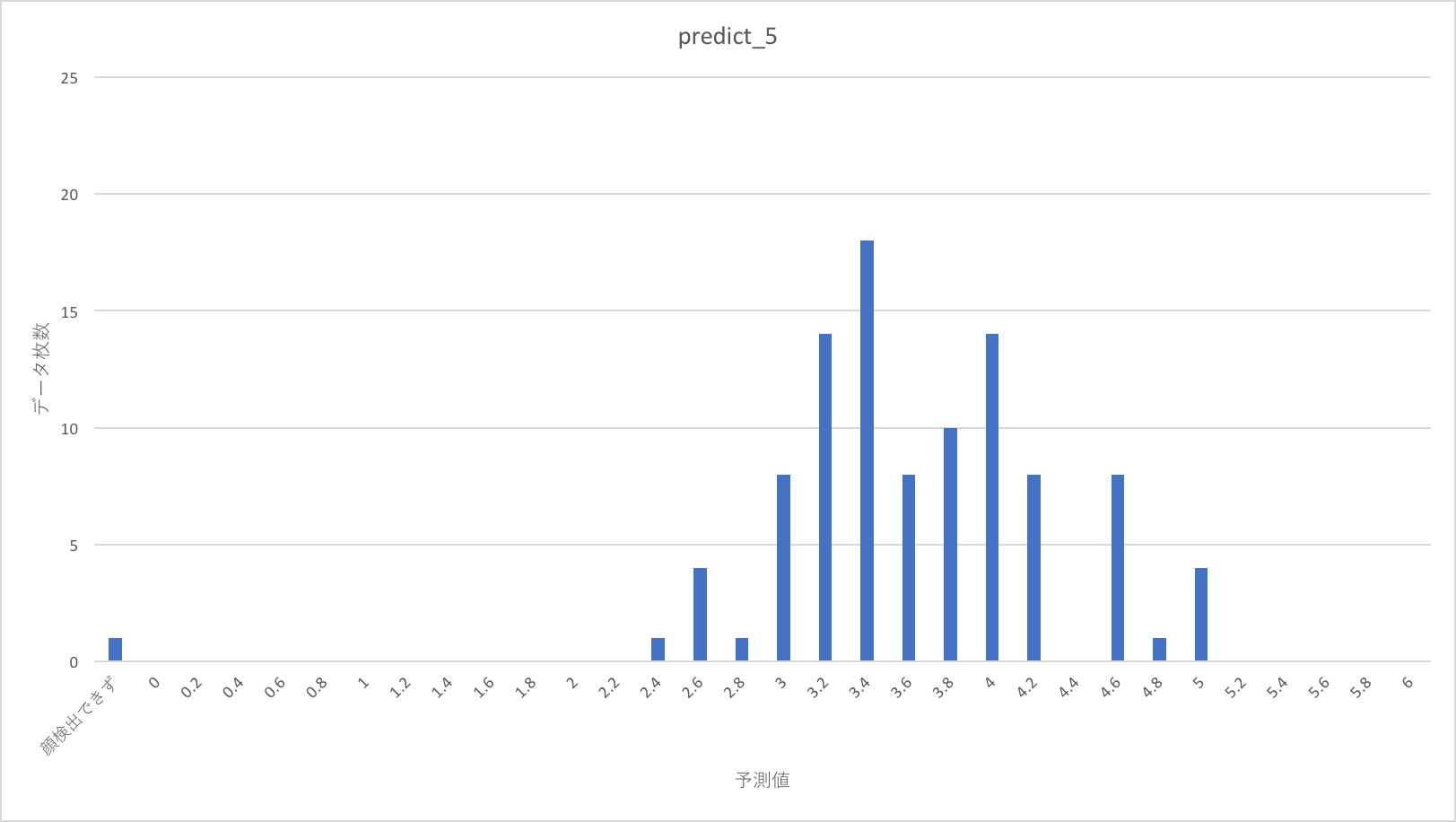
点数の分布はまばらに見えますが、1、2年目のように明らかにバラバラというわけではなさそうです。
教師スコアが上がるほど、予測スコア分布が、より高い点に移動する傾向があるように見えます。
おわりに
3年目にしてようやく、ある程度は目標を実現することができました。特に顔検出は超うまくいきました。
時間をかけただけあって、光明が見えたので正直めちゃくちゃ嬉しいです。スコアを上位に限って抽出するようにすれば、それなりに好きな画像のみを推薦してくれるシステムが作れるようになったわけですね。
分布から見ればまだまだ改善の余地はあります。例えば、やはり美少女を見るときは顔だけではなく、髪型や服、胸の大きさや体つき、背景の雰囲気や、あるいは思いいれ(既に知っている作品の場合)なども、データセット作りの際に考慮していたと考えています。バラツキの原因はそうしたところにあるのではないでしょうか。
今回は特に顔が重要と考えて実験しましたが、今後の方針としては顔のみを考慮したスコアリングを改めて行なったり、darknetで胸の検出機を作ってスコアに加えてみたり、色々とやりたいことがあるので、それを加えて精度を上げていこうと思います。
何はともあれ、これで心おきなく大学院を卒業できます。
それでは最後に。
同じように二次元美少女推薦システムが作りたいと思ったそこのあなた、スコアリング頑張ってください。
僕は一足先に画面の向こうの女の子たちと幸せになります。
うらら迷路帖だいすき。
以上です。
