はじめに
Amazon PersonalizeがGA(一般提供)を開始しました。
Amazon Personalizeを使うと機械学習の知識がなくてもレコメンド機能を作成できます。
2019年6月27日時点では開発者ガイドのソースコードの言語はPythonのみです。
しかし、RubyのSDKもAmazon Personalizeに対応済みでしたので、Rubyのプログラムから開発者ガイドの開始方法(Getting Started)と同じことをやってみました。
注意事項
Amazon Personalizeは下記の項目に対して料金が発生します。
- データの取り込み
- 学習モデルのトレーニング時間
- 1時間ごとの1秒間あたりのレコメンドの処理回数
そのため、このページの内容を実行するとわずかですが料金が発生する可能性があります
(最初の2か月間は無料枠あり)。
料金の詳細はAmazon Personalizeの公式ページをご確認ください。
https://aws.amazon.com/jp/personalize/pricing/
事前準備
プログラムを実行するためにいくつか事前準備が必要です。
AWSの設定
ユーザーにAmazon Personalizeの権限を設定
-
AWSコンソールでIAMを開く
-
メニューからユーザーを開く
-
ユーザーの追加もしくは既存のユーザーを選択する
-
ユーザーの追加の場合、アクセスの種類に「プログラムによるアクセス」を選択する
-
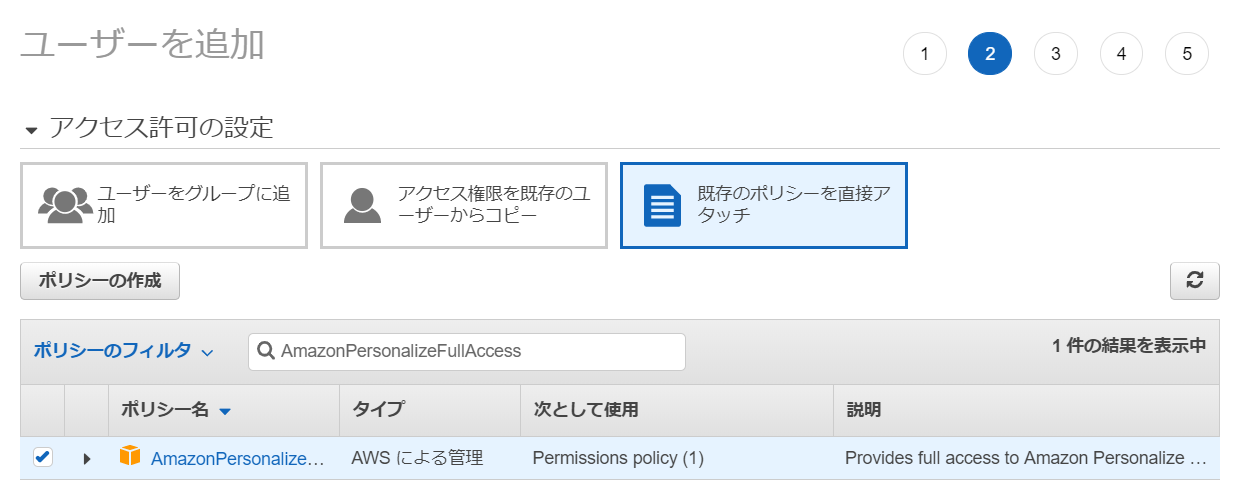
アクセス許可の設定 ⇒ 既存のポリシーを直接アタッチで「AmazonPersonalizeFullAccess」を追加する
-
残りの項目を入力し、ユーザーの追加もしくは更新を完了する
-
認証情報のアクセスキーとシークレットアクセスキーを書き留める。なお、シークレットアクセスキーのほうはユーザーの追加完了時にしか確認できない。
Amazon Personalize用のロールの追加
-
AWSコンソールでIAMを開く
-
メニューからロールを開く
-
ロールの作成を選択する
-
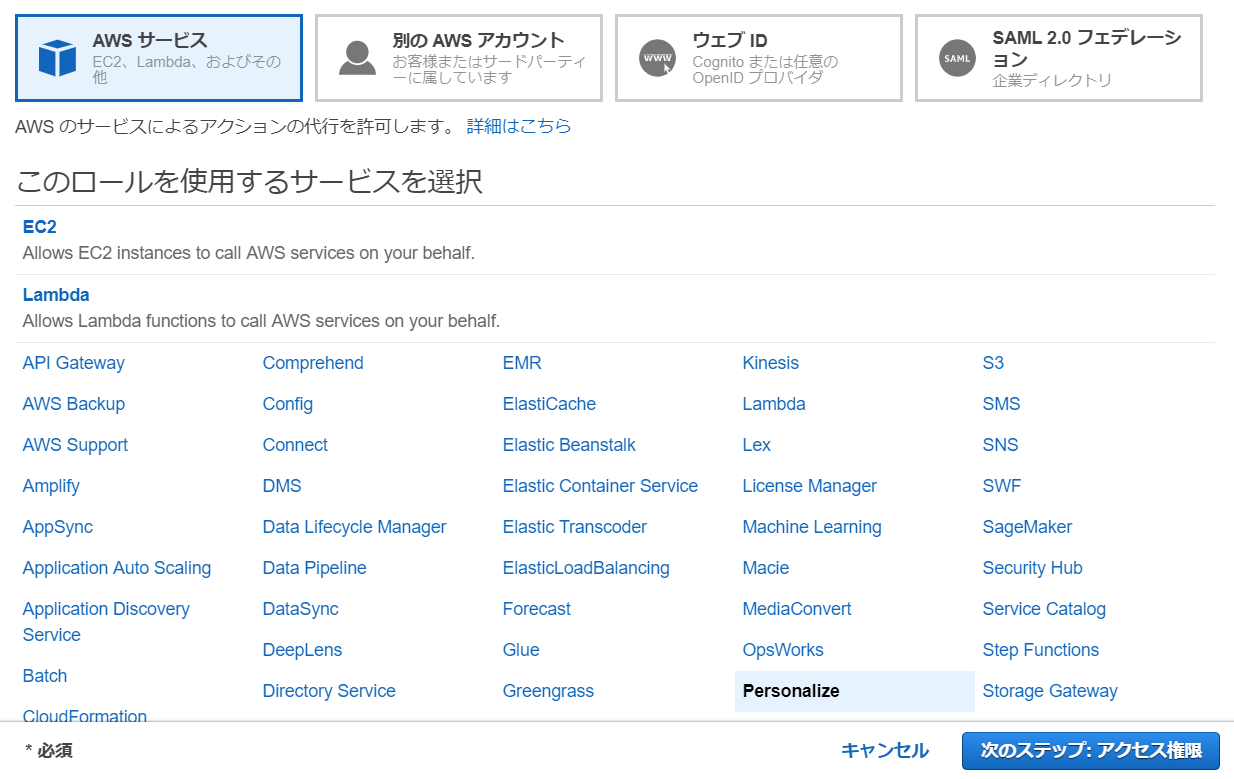
ロールを使用するサービスに「Personalize」を選択する
-
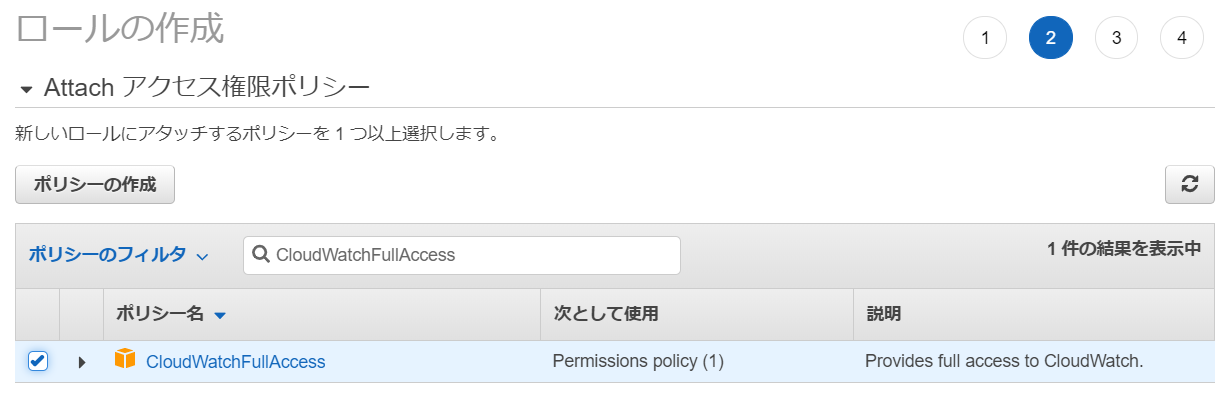
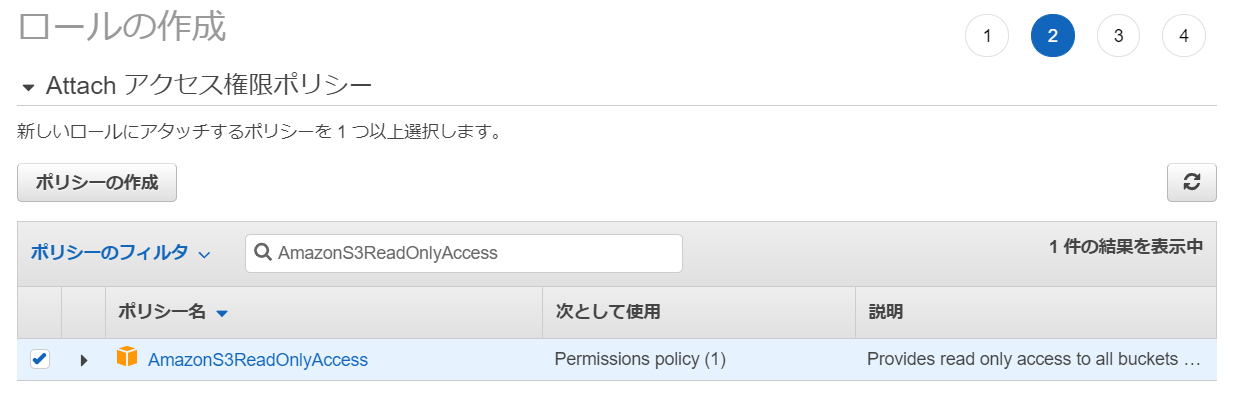
アクセス権限ポリシーとして「CloudWatchFullAccess」と「AmazonS3ReadOnlyAccess」を選択する
-
残りの項目を入力し、ロールの追加を完了する
サンプルデータのアップロード
- MovieLens(https://grouplens.org/datasets/movielens/) から「ml-latest-small.zip」をダウンロードする。このファイルはレコメンドの研究目的の映画のレビュー情報で、ここではユーザーの行動履歴として使用する。
- ダウンロードしたファイルを解凍し、中の「ratings.csv」のヘッダを下記のように書き換える。ファイルサイズが大きいため環境によっては開くときに時間がかかる場合がある。
USER_ID,ITEM_ID,RATING,TIMESTAMP
- AWSコンソールでS3を開く
- 2でヘッダを書き換えたファイルをS3にアップロードする
- ファイルをアップロードしたバケットを開く
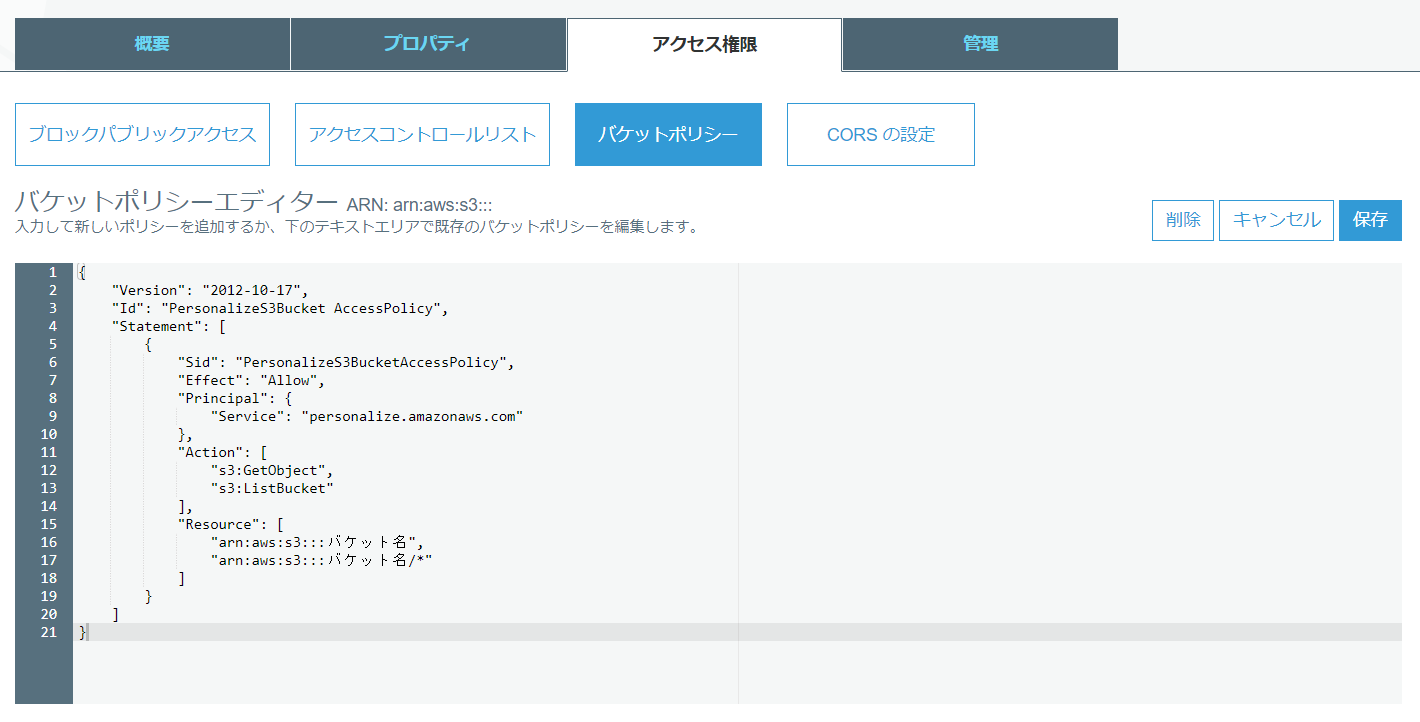
- アクセス権限 ⇒ バケットポリシーに下記の内容を入力し、保存する
{
"Version": "2012-10-17",
"Id": "PersonalizeS3Bucket AccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::バケット名",
"arn:aws:s3:::バケット名/*"
]
}
]
}
Rubyの設定
-
Gemfileに下記の内容を記述する
gem 'aws-sdk-personalize' gem 'aws-sdk-personalizeevents' gem 'aws-sdk-personalizeruntime' -
コマンドラインで「bundle install」を実行する
Amazon Personalizeに関連するGEMファイルの役割は下記のように分かれています。
| GEM名 | 役割 |
|---|---|
| aws-sdk-personalize | レコメンドの設定に関する処理 |
| aws-sdk-personalizeevents | ユーザーの行動履歴のトラッキング |
| aws-sdk-personalizeruntime | レコメンド結果の取得 |
以上で事前準備は完了です。
Rubyでレコメンド情報を取得する
開発者ガイドの開始方法(Getting Started)に沿って次の順に進めます。
- データセットグループの作成
- スキーマの作成
- データセットの作成
- データセットのインポート
- ソリューションの作成
- キャンペーンの作成
- レコメンド情報の取得
Amazon Personalizeの専門用語がいくつか出てきていますが、それぞれの意味は下記のような認識です。
| 単語 | 意味 |
|---|---|
| データセットグループ | データセットの集まり。DBMSのデータベースのようなもの |
| スキーマ | データセットの形式。DBMSのテーブル定義のようなもの |
| データセット | 学習に使うデータの入れ物。DBMSのテーブルのようなもの |
| ソリューション | データセットをもとに機械学習を行って作成したレコメンドの学習済みモデル |
| キャンペーン | ソリューションを使用してレコメンドを取得するための窓口 |
データセットグループの作成
データセットグループを作成します。
下記のソースコードではAWS.config.updateで明示的に認証情報とリージョンを設定していますが、他のAWSのSDKと同様に設定ファイルや環境変数があれば省略可能です。
以降のソースコードでは認証情報とリージョンの設定は省略します。
require 'aws-sdk-personalize'
# 認証情報とリージョンの設定(省略可能)
Aws.config.update({
credentials: Aws::Credentials.new('設定したユーザーのアクセスキー', '設定したユーザーのシークレットアクセスキー'),
region: 'ap-northeast-1'
})
client = Aws::Personalize::Client.new
resp = client.create_dataset_group(name: 'ratings-dataset-group')
# 作成したデータセットグループのARNがレスポンスから取得できる
puts resp.dataset_group_arn
スキーマの作成
ユーザーの行動履歴のスキーマを作成します。
require 'aws-sdk-personalize'
client = Aws::Personalize::Client.new
# スキーマはJSON形式
schema = JSON({
type: 'record',
name: 'Interactions',
namespace: 'com.amazonaws.personalize.schema',
fields: [
{ name: 'USER_ID', type: 'string' },
{ name: 'ITEM_ID', type: 'string' },
{ name: 'RATING', type: 'string' },
{ name: 'TIMESTAMP', type: 'long' }
],
version: '1.0'
})
resp = client.create_schema({ name: 'ratings-schema', schema: schema })
# 作成したスキーマのARNがレスポンスから取得できる
puts resp.schema_arn
データセットの作成
ユーザーの行動履歴を格納するデータセットを作成します。
require 'aws-sdk-personalize'
client = Aws::Personalize::Client.new
resp = client.create_dataset({
name: 'ratings',
schema_arn: '作成したスキーマのARN',
dataset_group_arn: '作成したデータセットグループのARN',
dataset_type: 'Interactions'
})
# 作成したデータセットのARNがレスポンスから取得できる
puts resp.dataset_arn
データセットのインポート
S3にアップロードしたサンプルデータをユーザーの行動履歴としてインポートします。
インポートの完了まで10分程度かかります。
これ以降、完了までに時間がかかる処理がいくつかでてきますが、完了したかどうかはAWSコンソールのAmazon Personalizeの画面で確認できます。
require 'aws-sdk-personalize'
client = Aws::Personalize::Client.new
resp = client.create_dataset_import_job({
job_name: 'ratings-dsimport-job',
dataset_arn: '作成したデータセットのARN',
data_source: {
data_location: 's3://バケット名/事前準備で作成したサンプルデータのパス',
},
role_arn: '事前準備で作成したロールのARN'
})
# 作成したデータセットインポートジョブのARNがレスポンスから取得できる
puts resp.dataset_import_job_arn
ソリューションの作成
ソリューションを作成します。
もとの開発者ガイドではAuto MLを使用しているのですが、Auto MLを使用したところソリューションの作成が完了するまで10時間以上かかりました。
時間がかかる理由はAuto MLが最良の結果を出すために学習を繰り返すためです。
そのため、ここではAuto MLは使用せずに機械学習の手法を直接指定しています。
それでもソリューションの作成が完了するまで1時間30分程度かかりましたので、気長に待ちましょう。
require 'aws-sdk-personalize'
client = Aws::Personalize::Client.new
# aws-hrnnという手法を使う
resp = client.create_solution({
name: 'ratings-solution',
recipe_arn: 'arn:aws:personalize:::recipe/aws-hrnn',
dataset_group_arn: '作成したデータセットグループのARN'
})
# 作成したソリューションのARNがレスポンスから取得できる
puts resp.solution_arn
# ソリューションを作成しただけでは使えないので、ソリューションを使った学習を開始する
solution_arn = resp.solution_arn
resp = client.create_solution_version(solution_arn: solution_arn)
# 学習を開始したソリューションのバージョンのARNがレスポンスから取得できる
puts resp.solution_version_arn
キャンペーンの作成
キャンペーンを作成します。
キャンペーンを作成するとレコメンド情報を取得できるようになります。
キャンペーンの作成が完了するまで10分程度かかります。
なお、キャンペーンが有効な状態にしておくと料金が発生しますので、不要になったら削除することを推奨します。
require 'aws-sdk-personalize'
client = Aws::Personalize::Client.new
# min_provisioned_tpsは1秒間あたりの処理件数の下限(transaction per second)
resp = client.create_campaign({
name: 'ratings-campaign',
solution_version_arn: '作成したソリューションのバージョンのARN',
min_provisioned_tps: 1
})
# 作成したキャンペーンのARNがレスポンスから取得できる
puts resp.campaign_arn
レコメンド情報の取得
いよいよレコメンド情報が取得できます。
require 'aws-sdk-personalizeruntime'
client = Aws::PersonalizeRuntime::Client.new
resp = client.get_recommendations({
campaign_arn: '作成したキャンペーンのARN',
user_id: '1'
})
# レコメンド情報をレスポンスから取得できる
puts resp.item_list
以下のようなレコメンド情報が取得できます。
{:item_id=>"3997"}
{:item_id=>"3877"}
{:item_id=>"546"}
{:item_id=>"4133"}
{:item_id=>"2162"}
{:item_id=>"6996"}
{:item_id=>"2450"}
{:item_id=>"3889"}
{:item_id=>"3440"}
{:item_id=>"5999"}
{:item_id=>"3439"}
{:item_id=>"327"}
{:item_id=>"3190"}
{:item_id=>"2054"}
{:item_id=>"2701"}
{:item_id=>"2643"}
{:item_id=>"5523"}
{:item_id=>"2720"}
{:item_id=>"5419"}
{:item_id=>"66"}
{:item_id=>"2253"}
{:item_id=>"1882"}
{:item_id=>"3593"}
{:item_id=>"5171"}
{:item_id=>"3438"}
まとめ
上記のソースコードでRubyからAmazon Personalizeの操作ができました。
このように機械学習の知識を使用せずにレコメンド情報の作成と取得ができます。
ここではすべての操作をRubyのプログラムから実行していますが、正直なところAWSコンソールのAmazon Personalizeの画面から操作するほうが手軽でわかりやすいと思います。
通常の運用ではキャンペーンの作成まではAWSコンソールで行い、レコメンド情報の取得はプログラムから実行するという形になりそうです。
参考資料
| サイト | URL |
|---|---|
| Amazon Personalize 開発者ガイド | https://docs.aws.amazon.com/ja_jp/personalize/latest/dg/what-is-personalize.html |
| GitHub - aws/aws-sdk-ruby | https://github.com/aws/aws-sdk-ruby |
| MovieLens | GroupLens | https://grouplens.org/datasets/movielens/ |