はじめに
Ateam cyma Advent Calendar 2019 の 6日目です。
本日の担当はエイチームのEC事業本部でWebアプリケーションエンジニアをしている@hibiheionです。
業務では主に自転車ECサイトcymaのバックエンドの機能をRailsで書いています。
今年のアドベントカレンダーでは2日目と3日目に続いての登場です。
本題
WebスクレイピングはWebページの情報を自動的に取得する手法です。
RubyはCapybara(※1)やNokogiri(※2)といったRubyGemのおかげでわりと簡単にWebスクレイピングを実現できます。
ですが、夜間に自動でスクレイピングするという場合などには「Webページから情報を取得する」という本来やりたいこと以外にエラーハンドリングやログの出力といったことに手間をかける必要がでてきます。
そういった手間をかけずに高機能なWebスクレイピングを実現できるすばらしいRubyGemがあります。
それが今回ご紹介するKimuraiです。
※1:CapybaraはWebページを操作するためのRubyGem
※2:NokogiriはWebページの要素を解析するためのRubyGem
Kimuraiとは
Kimuraiの公式ドキュメントはこちら
https://github.com/vifreefly/kimuraframework
概要
- Webスクレイピングを目的としたRubyGem
- Webスクレイピングフレームワークという立ち位置で、Kimuraiを入れることでWebスクレイピングに必要な機能がまとめて手に入る
- PythonにScrapyという有名なWebスクレイピングフレームワークがあるのですが、GithubのタグにScrapyが入っているなどRuby版Scrapyを目指しているように感じます
- CapybaraやNokogiriといったRubyでのWebスクレイピングでは定番のRubyGemを使用している
- この記事を公開した2019年12月の時点ではマイナーな存在
- RubyGemsのダウンロード数は9,500くらい
- Githubのスター数は470くらい
- Kimuraiの由来は公式ドキュメントで言及されていないのですが、クモの一種の学名「Heptathela kimurai」ではないかと推測しています
特徴
以下のリストは公式ドキュメントのFeaturesの日本語訳(意訳)です。
https://github.com/vifreefly/kimuraframework#features
- JavaScriptで表示するWebサイトもスクレイピングできる
- ヘッドレスChrome、ヘッドレスFirefox、PhantomJS、HTTPリクエスト(mechanize gem)をドライバとして使用できる
- スクレイピングのコードを書いてから使用するドライバを変更できる
- Capybaraのすべての機能を使用できる
- 次のような項目を設定できる
- デフォルトのヘッダー
- クッキー
- リクエスト間の待ち時間
- プロキシやユーザーエージェントのローテーション
- 以下のようなスクレイピングを簡単にするための機能が備わっている。
- save_to : 結果をJSONやCSVで保存できる
- unique? : 同じデータをスキップする
- リクエストエラーを自動的にハンドリングする
- メモリやリクエストの上限に達したときに自動的にリスタートしてスクレイピングを継続する
- wheneverを使って定期的に実行できる
- (訳注)wheneverは定期的にジョブを実行するRubyGem
- 「in_parallel」というシンプルなメソッドでスクレイピングを並列実行できる
- 2つのモードがある
- 単一ファイルのシンプルなスパイダー
- Scrapyのようなプロジェクト形式
- コンソールでの開発モード・色付けされたロガー・デバッカーといった便利な機能が備わっている。これらはPryやByeBugに対応している。
- ubunt18.04での実行環境の自動セットアップ、Ansibleでのコマンドを使用したデプロイが可能
- コマンドラインからすべてのプロジェクトのスパイダーを動かすことができる。スパイダーはひとつずつ動かすことも並列して動かすこともできる。
Webスクレイピングにあたってあるとうれしい機能が盛りだくさんです。
Kimuraiを導入すると、自分ではほとんど手を動かさずにこれらの機能が手に入るのです。
実に素晴らしいと思いませんか?
使い方
ここからはKimuraiの使い方を説明します。
特徴のところで書いたように2つのモード(単一ファイルとプロジェクト形式)があるのですが、ここでの説明は単一ファイルのモードについてのみです。
準備
Kimuraiを使用するためには次のような準備が必要です。
- ruby2.50以降のインストール
- Kimuraiのインストール(gemをインストールするだけ)
- ブラウザと対応したWebドライバーのインストール
公式ドキュメントにインストール手順がコマンドと一緒に載っているのでそちらを参考にしてください。
https://github.com/vifreefly/kimuraframework#installation
スクレイピングの実行
作成したプログラムをrubyコマンドから動かすだけです。
ruby spider.rb
サンプルコード
Kimuraiを使用しない場合と使用した場合の2パターンでサンプルコードを作成しました。
サンプルコードでは弊社の自転車ECサイトcymaをスクレイピングして自転車の情報を取得しています。
具体的には次のようなことをしています。
- トップページに訪れる
- ナビゲーションからカテゴリページのリンクを取得する
- カテゴリページに移動する
- カテゴリページで商品名、最低価格、最高価格を取得する
- 4で取得した情報をCSVファイルに出力する
サンプルコードの途中でCSSセレクタが出てきますが、それぞれ下記の位置を示しています。
■トップページの「#nav-global ul li a」

■カテゴリページの「#cy-products .cy-product-list .product」
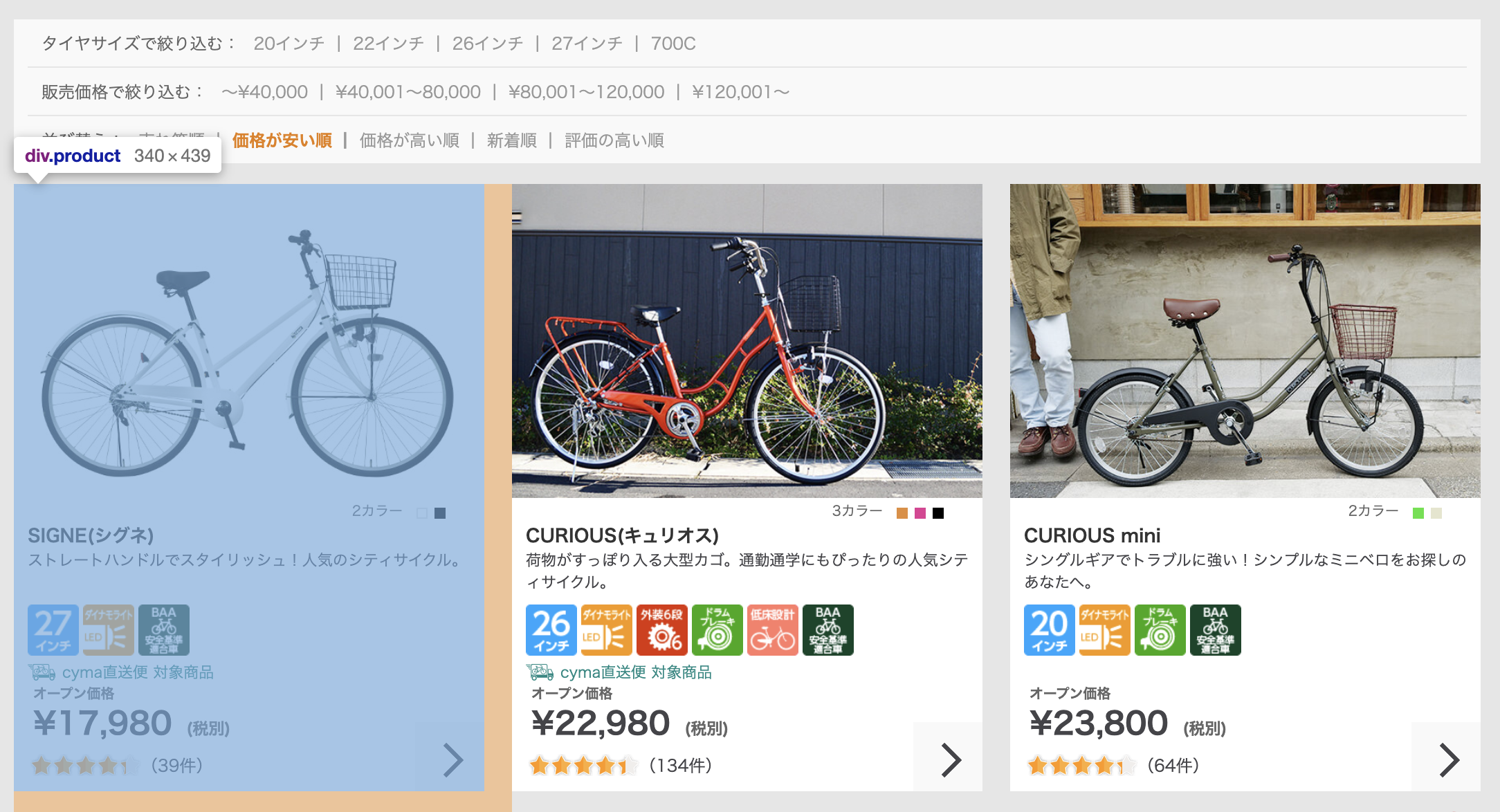
なお、記事の公開時点ではサンプルコードの動作を確認していますが、サイトの変更により今後動かなく可能性があります。
Kimurai未使用
まずはKimuraiを使用しないプログラムです。
Webスクレイピングを実行するCapybaraSpiderクラスでスクレイピングの入り口になるメソッドはcrawl!です。
# 動作確認する際は以下のRubyGemのインストールが必要
require "capybara"
require "nokogiri"
require "selenium-webdriver"
require "csv"
# Webスクレイピング実行クラス
class CapybaraSpider
# トップページのURL
CYMA_HOME = "https://cyclemarket.jp".freeze
# ドライバの接続情報
@session = nil
# ドライバを初期化する
def initialize
Capybara.register_driver :selenium do |app|
Capybara::Selenium::Driver.new(app,
browser: :chrome,
desired_capabilities: Selenium::WebDriver::Remote::Capabilities.chrome(
chrome_options: {
args: %w(headless disable-gpu window-size=1280,800),
}
)
)
end
Capybara.javascript_driver = :selenium
@session = Capybara::Session.new(:selenium)
end
# スクレイピングを実行する
def crawl!
# トップページからカテゴリページへのリンクを取得する
categories = parse_top_page
sleep 2
# カテゴリページから商品情報を取得する
products = []
categories.each do |category|
products += parse_category_page(category)
sleep 2
end
# CSV出力
CSV.open("results.csv", "wb") do |csv|
csv << %w[name category_name min_price max_price]
products.each { |product| csv << [product[:name], product[:category_name], product[:min_price], product[:max_price]] }
end
end
private
# トップページを解析する
# @return [Array] カテゴリページへのリンク
def parse_top_page
# トップページを訪問し、HTMLを解析する
@session.visit CYMA_HOME
response = Nokogiri::HTML.parse(@session.html)
categories = []
# CSSセレクタを使ってヘッダのナビゲーションを取得する
response.css("#nav-global ul li a").each do |menu|
# HTMLのクラスを見てカテゴリページ以外は除外する
next if menu[:class].include?("outlet") || menu[:class].include?("parts")
# ナビゲーションからカテゴリページへのリンクを取得する
category_name = menu.css(".caption").text
category_url = "#{CYMA_HOME}#{menu[:href]}"
categories << { category_name: category_name, category_url: category_url }
end
categories
end
# カテゴリページを解析する
# @param [Array] category カテゴリページへのリンク
# @return [Array] 商品情報
def parse_category_page(category)
# カテゴリページを訪問し、HTMLを解析する
@session.visit category[:category_url]
response = Nokogiri::HTML.parse(@session.html)
products = []
response.css("#cy-products .cy-product-list .product a").each do |product|
# CSV出力のために1件ごとにハッシュに入れる
row = {}
row[:name] = product_name(product.css(".body .title").text.strip)
row[:category_name] = category[:category_name]
row[:min_price] = product.css(".min-price").text.strip.delete("^0-9")
row[:max_price] = product.css(".max-price").text.strip.delete("^0-9")
products << row
end
products
end
# 商品名にメーカー名がついている場合はメーカー名を取り除く
# @param [String] base_name 元の商品名
# @return [String] メーカー名を取り除いた商品名
def product_name(base_name)
base_name.include?("\n") ? base_name.split("\n")[1].strip : base_name
end
end
# スクレイピングを開始する
spider = CapybaraSpider.new
spider.crawl!
Kimurai使用
次にKimuraiを使用したプログラムです。
説明のためにプログラム中のコメントを多めにしています。
基本的な使い方はこのサンプルコードで書いた内容で十分だと思います。
Webスクレイピングを実行するKimuraiSpiderクラスは以下の手順でスクレイピングを開始します。
- 継承しているKimurai::Baseクラスの
crawl!メソッドを呼び出す -
crawl!メソッドからKimuraiSpiderクラスのparseメソッドを呼び出す
require "kimurai"
# Webスクレイピング実行クラス
# Kimurai::Baseを継承する
class KimuraiSpider < Kimurai::Base
# 名前
@name = "kimurai_spider"
# スクレイピングに使用するドライバ
@engine = :selenium_chrome
# 最初に訪れるURL。配列で複数設定することも可能。
@start_urls = ["https://cyclemarket.jp"]
@config = {
# ユーザーエージェント
user_agent: "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36",
# ページを開く前に2秒待つ
before_request: { delay: 2 }
}
# starts_urlsのページを解析する
# 継承しているKimurai::Baseのcrawl!メソッドから呼ばれる
# @param [Nokogiri::HTML::Document] response 対象ページを対象としたNokogiri::HTML.parseの結果
# @param [String] url 対象ページのURL
# @param [Hash] data 前ページからの引数
def parse(response, url:, data: {})
# CSSセレクタを使ってヘッダのナビゲーションを取得する
# 項目の取得には「css」や「xpath」といったNokogiriの検索系メソッドが使用できる
response.css("#nav-global ul li a").each do |menu|
# HTMLのクラスを見てカテゴリページ以外は除外する
# ノードのアクセスでもNokogiriと同じメソッドを使用できる
next if menu[:class].include?("outlet") || menu[:class].include?("parts")
# ナビゲーションからカテゴリページの情報を取得する
category_name = menu.css(".caption").text
category_url = absolute_url(menu[:href], base: url)
# 「request_to」メソッドでカテゴリページに移動し、カテゴリページを解析する。引数は下記の通り。
# ・第1引数は移動先のページの解析に使うメソッド
# ・キーワード引数の「url」は移動先のページのURL
# ・キーワード引数の「data」は移動先のページの解析に使うメソッドへの引数
request_to :parse_category_page, url: category_url, data: { category_name: category_name }
end
end
# カテゴリページを解析する
# @param [Nokogiri::HTML::Document] response 対象ページを対象としたNokogiri::HTML.parseの結果
# @param [String] url 対象ページのURL
# @param [Hash] data 前ページからの引数
def parse_category_page(response, url:, data: {})
# 商品情報を取得する
response.css("#cy-products .cy-product-list .product a").each do |product|
# CSV出力のために1件ごとにハッシュに入れる
row = {}
row[:name] = product_name(product.css(".body .title").text.strip)
row[:category_name] = data[:category_name]
row[:min_price] = product.css(".min-price").text.strip.delete("^0-9")
row[:max_price] = product.css(".max-price").text.strip.delete("^0-9")
# CSVファイルに出力する
save_to "results.csv", row, format: :csv
end
end
private
# 商品名にメーカー名がついている場合はメーカー名を取り除く
# @param [String] base_name 元の商品名
# @return [String] メーカー名を取り除いた商品名
def product_name(base_name)
base_name.include?("\n") ? base_name.split("\n")[1].strip : base_name
end
end
# スクレイピングを開始する
KimuraiSpider.crawl!
こちらはドライバの初期化などが不要なのでスッキリして見えると思います。
ソースコードが短いほど良いというものでもないですが、コメントと空行を除いた行数を比較するとKimurai未使用が67行、Kimurai使用が33行とほぼ半減しています。
所感
実際の運用ではここに書いたサンプルコードよりいくらか複雑なことをしています。
その中で感じた良かった点と気になった点は下記の通りです。
良かった点
- 「Webページから情報を取得する」という本来やりたいことに集中できる
- エラーハンドリングやCSVファイルの制御などを書かなくても良い
- CapybaraやNokogiriのメソッドをそのまま使うことができる
- すでにRubyでWebスクレイピングを行っている場合、慣れ親しんだ仕組みを活用できるので移行しやすい
- 別ページに移動する際に
request_toメソッドを呼ぶ必要があるため、HTMLを解析するメソッドが自然とページごとに分かれる- ページの構成が変わったときの影響が限定されるので良い設計だと思う
- 公式ドキュメントが充実している
- まだ有名ではないRubyGemだとソースコードを見ないと使い方がわからないことも珍しくないが、Kimuraiは公式ドキュメントだけで使い方を理解できた
気になった点
- Kimuraiの想定から外れた使い方はしにくい
- スタート地点にあたるstart_urlsからWebページをたどっていくような使い方を想定している
- start_urlsを変更する仕組みが公式にはないため、商品コードのリストをもとにURLのリストを組み立てて特定の商品ページだけから情報を取得するいうことはやりにくい
- できないわけでなくて、今の運用では下記のようなメソッドをクラス内に書いてstart_urlsを動的に書き換えている
def self.build_start_urls
start_urls = []
%w[1 2 4 8 16 32 64].each { |n| start_urls << "https://cyclemarket.jp/product/category_#{n}/" }
@start_urls = start_urls
end
- 今の段階だと日本語の情報がないに等しい
- とはいえ、公式ドキュメントの英語はわかりやすい
まとめ
Kimuraiの基本的な使い方を身に付けるのはそれほど難しくなく、使い方を身に付ければ効率良くWebスクレイピング機能を実装できます。
この記事で少しでもKimuraiに興味を持っていただければうれしいです。
最後になりましたが、開発者のVictor Afanasevさん、素晴らしいRubyGemを作っていただきありがとうございます!
次回予告
Ateam cyma Advent Calendar 2019 の 6日目の記事は以上です。
7日目はエンジニアの@namedpythonさんが担当します。
内容はPythonに関するもの、ではなくデータの可視化に関するものです。
さいごに
株式会社エイチームでは、一緒に働けるチャレンジ精神旺盛な仲間を募集しています。
エンジニアで興味を持った方はcymaのQiita Jobsをご覧ください。
そのほかの職種は、エイチームグループ採用サイトをご覧ください。