誰でも楽しく法律が読める《法令.app》というWebアプリを作っています。
今回は「図表」の扱いについてです。「民法」、「健康保険法」といった主だった法律を読むと、「テキストのみ」で構成されているように見えます。一方で、各省庁が作る「省令・施行規則」では、細かな現場での運用を定めていることから、多くの表や画像が載っています。PDFファイルが添付されていることもあります。
多くの「六法アプリ」では図表が省略されていました。法律は「本則」→「附則」→「別表(など)」の順で書かれていますが、ほとんどのユーザーは「本則の条文」を読みたくて使っているので、開発の優先順位としてはどうしても下になるんだと思います。
E-Gov法令検索 での「表」の表示

《法令.app》 表示の工夫は特にしていません。「表」を含む「別表セクション」には、まだバグが多く、手をつけられていません(このシンプルな表でも、1行目の「第六条関係」がアプリに反映されてません)

個人的に「別表」は、図が多くて面白い法令が多いと思います。また紹介したいと思います。
 最大の「表」は、どの法令にある?
最大の「表」は、どの法令にある?
記事を書くにあたって「ネタ不足」がいなめないため、今回もスクリプトを書いてみました。世の中のあらゆることを文書に落とし込んでいる法令は、捉える角度は違っても「百科事典」の一種と言えるかもしれません。改めて調べると、その規模に圧倒されました。
各ファイルの table タグ、tdタグをカウントするスクリプト
# cli 引数1:table個数の上限、引数2:td個数の下限
# > python count_tables.py 3 3000
import glob
import re
glob_q = '# データフォルダ #/*-a.html'
th_l = [int(sys.argv[1]), int(sys.argv[2])]
pat_table = re.compile('<table')
pat_td = re.compile('<td')
global c0
c0= 0
def count( m ):
global c0
c0 += 1
file_count = 0
for path in glob.glob(glob_q):
c0 = 0
res = []
with open(path) as f:
txt = f.read()
pat_table.sub(count, txt)
res.append(c0)
pat_td.sub(count, txt)
res.append(c0)
if(
(th_l[0] < 0 or res[0] <= th_l[0])
and
(th_l[1] < 1 or res[1] >= th_l[1]) ):
file_count += 1
print(f'\n{path}\n{res}')
print('files: ', file_count)
![]() 1つの表で「表の要素数」が一番多いのは、
1つの表で「表の要素数」が一番多いのは、
商標法施行規則《別表など》 の 3,011個 でした。
![]() 大きな表がたくさん入った法令は
大きな表がたくさん入った法令は
獣医療法施行規則《別表など》 の「表の数」5つの中に 13,539 の要素でした。
![]() 要素数のトップは、
要素数のトップは、
関税定率法《別表など》 の表の数 224 の中に 33,395 の要素がありました。どの程度実務で使うのか分かりませんが、税金関係を扱う通関士さんや税理士さんは大変ですね。。
空の要素もあるので、全てにデータが入っているわけではありませんが、1万というオーダーがぞろぞろあります。全てが巨大すぎて感覚がマヒします。「DX」は必至だな、とつくづく思います。「データベース」で扱うオーダーで、テキストで追える量ではないですね。
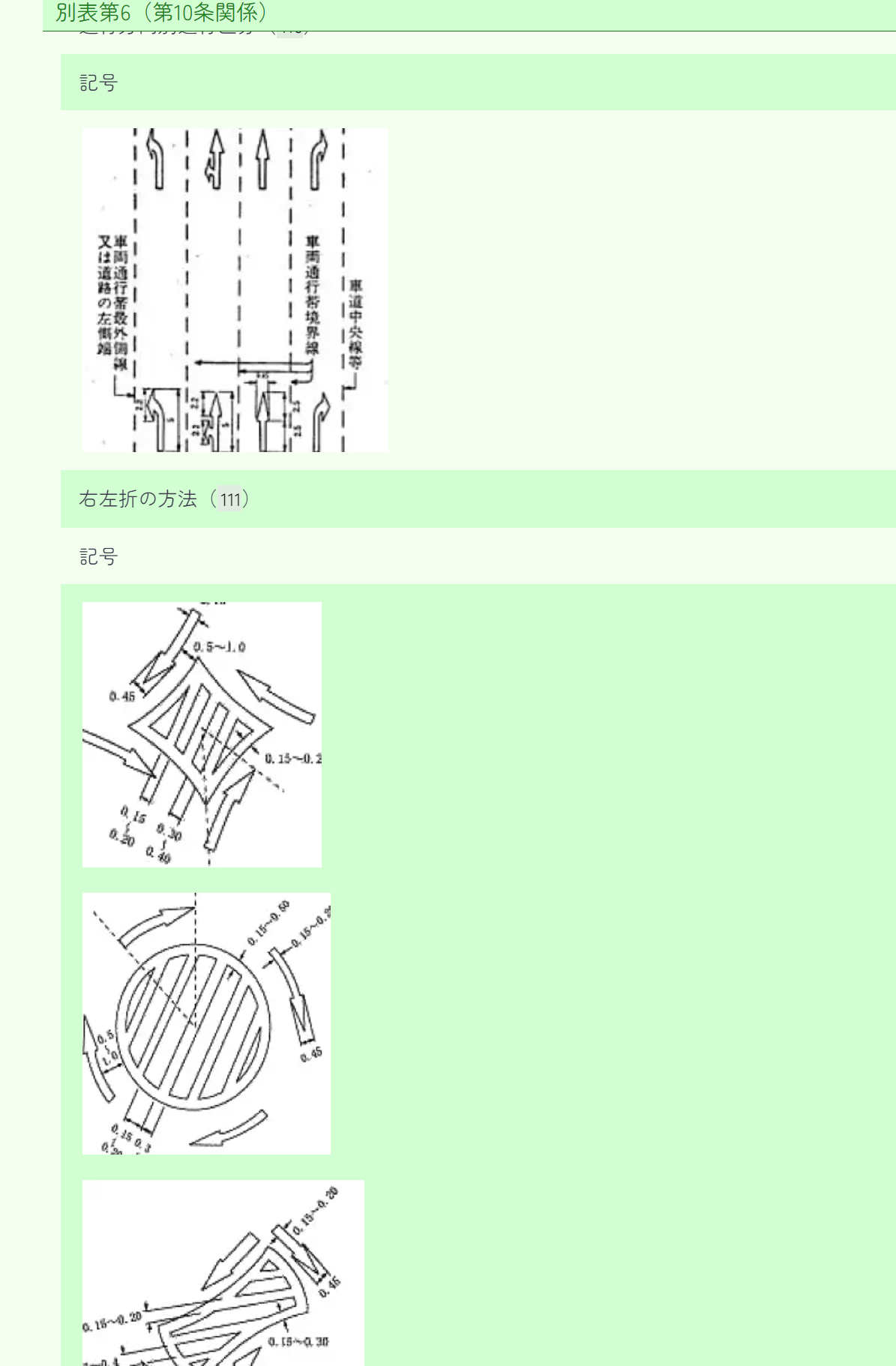
圧倒されて少しげんなりする一方で、図表の多い法律は読んでいて楽しいです。道路標識の寸法・設計などを決めた法律です。
 お役所のサイトの「PDFのリンクだけある」問題
お役所のサイトの「PDFのリンクだけある」問題
役所のホームページでは、何かとPDFを置きがちです。印刷することを考えると、ダウンロードしてすぐに原本のそのままに印刷できる、すばらしい仕様なのですが、ネット上で見るのは毎度ため息が出ます。スマホだと5ページでも少し大変です。
何より、「謎のファイル名」の大きなファイルがダウンロードフォルダに溜まっていくのが地味にストレスです。私のフォルダを見ると「40_41.pdf」という、名前に何のヒントもないファイルが何ヶ月も前から残っています。
例に漏れず、国の E-Gov法令検索 では、PDFを多用しています。「図」メインであれば画像ファイルが表示されて見やすいのですが、「文書」となっているものは1ページであってもPDFになるので、ずらっとアイコンリンクが並ぶことになります。
> find ../../data/pict/ -name '*--1_*' -print | awk -F'_' '{print $1}' | sort | uniq -c | sort -rn | head
せっかくなので、たくさんのリンクが延々と続く、一番「壮観」なPDFリンクの行列をお見せしたい。linuxのコマンドでPDFの添付数が多い順に並べてみました。
328 ../data/pict/336M50000100001
282 ../data/pict/329M50000002023
192 ../data/pict/407M50000400077
172 ../data/pict/356M50000010054
1つの法律にPDFが 328個 添付されている法律を、まず「E-Gov法令検索」で開いてみましょう。
医薬品、医療機器等の品質、有効性及び安全性の確保等に関する法律施行規則

これは後からスクリーンショットをツギハギしたものです。元はリンクが「縦に一列で」並んでいました。赤いファイルのアイコンが「ドミノ倒し」のドミノに見えてきます。この画像の分だけで「12ページ」スクロールする必要があります。実は残り8ページありますが、さすがに嫌になりましたので止めました。
中身がなんなのか、開いたPDFに何ページあるのか、サイズは大きいのか、事前には何も分からない。「何条関係」とだけ書いてあるのを見てクリックできる人は「E-Gov法令検索」ユーザーの適正があります。が、日常生活ではマルウェアのリンクをいっぱい踏んでいる気がします。これは偏見です。

![]() は、同じ条文を《法令.app》で表示したものです。PDFはWebp画像に変換し、「内容」がすぐに見れます。ただし、軽快に表示したいので画質は最低限にしています。余白も詰め気味にトリミングしてあり見切れてしまっているファイルもあります。
は、同じ条文を《法令.app》で表示したものです。PDFはWebp画像に変換し、「内容」がすぐに見れます。ただし、軽快に表示したいので画質は最低限にしています。余白も詰め気味にトリミングしてあり見切れてしまっているファイルもあります。
ここはやや攻めすぎましたが、最小のファイルサイズで、内容がだいたいつかめる画像ファイルを求めて試しているところです(今はAvifというのがWebpより小さくできるというので、次回の処理では乗り換える予定です)。
 630ページのPDFをササッと「流し読み(=力を抜いて軽く読むさま by Weblio辞書)」する
630ページのPDFをササッと「流し読み(=力を抜いて軽く読むさま by Weblio辞書)」する
さて、次は「最大のPDFファイル」を探してみましょう。(findコマンドで正規表現が使えると知ってやってみました。なぜか数字の '\d' が効かないので '\w'にしてます。ファイル名はアプリ固有なので意味はないです。あしからず)
> find ../../data/pict/ -type f -regex '.*--1_[8-9]\w--.*' | wc
10ページ以上のPDFファイルは529個、50ページは21、80ページ以上は3つありました。そして、100ページ以上は、1つ。この1つだけ別格の「630ページ!」![]()
さっきまで「何千行」とか「何万要素」というオーダーを見てきたので、数百では驚かなくなりましたが、PDFで100ページを超えたらなかなか厳しい。
こうなるとPDFリンクは、何が出てくるか分からないし「開かないのが正解」となってしまいますが、《法令.app》の趣旨としては「とりあえず読める」ことが目標なので、なんとかしたい。
例えば、図書館の本棚から分厚い本を取り出して、ちゃんと理解できないまでも、ざっとどんなことが書いてあるか知りたい時にどうするか?頭からめくっていくと、後半まで持たずに全体像はつかめない。本文に入る前に力尽きることもある。ひとつのやり方としては:
- 頭から最後まで、飛ばし飛ばしページを開いて、何が書いてあるか「ざっと見る」
- 気になるページがあれば、手を止めて「じっくり読む」
- 後で使うために、書き写したりコピーをする
これをアプリでの行動に置き換えてみます
- PDFの最初から最後まで、均等な間隔で抜き出したページを、1画面で収まる枚数並べる
- よく見てみてみたい1枚を選択すると、いわゆる「ライトボックス」がポップアップする(サクサク見れる代わりに「画質」は最低限になっている)
- プリントして使いたい場合は、E-Gov法令検索を訪れて、該当するPDFファイルをダウンロードする
アプリでは、先程の630ページのPDFをこう見せています。

全ページ数を12等分して、12枚のページを抜き出し、「次へ」ボタンを押すと16枚が1ページづつずれて行きます。詳しく見たいページは、クリックすると大きく表示されます。

最後は、E-Gov法令検索のデータに丸投げしていて、少しズルいのですが、堅牢な「アーカイブ」としての国のサービスと、身軽に「多様な表現」ができる民間が、長所を補い合って全体のサービスを上げていく「役割分担」と思ってます。
「役割」としての義務は、最新の元データと齟齬のないように適切にデータをアップデートしておくことだと思ってます。
ひばりソフト(ひばり)