最近は、生成AI隆盛の中、Qiita に投稿するのも遠のいてしまいました。生成AIが出したソースコードそのまま出してもねえ、と思いまして。
ただ、生成AIができない、というか、なぜか不得意な分野があり、意外と良い結果が得られなかったので、久しぶりに投稿しました。
それは、タイトルにあるとおり「ライミング」です。
ライミングとは、韻を踏むことです。そう、ヒップホップお馴染みのヤツです。
最初は、ボカロにラップさせたいという、些細なキッカケからでした。
俺は東京生まれHIP HOP育ち 悪そうな奴は大体友達
もはや、知らない人が誰もいないくらい、ヒップホップの金字塔です。
これは、ZEEBRA師匠が、『Grateful Days』(1999年)という楽曲で入れたリリックです。説明するまでもないですが「だち」で韻を踏んでいるわけです。
生成AI(ChatGPT-4o)でライミングをさせてみた
失礼ながら、生成AIにかかればライミングなんて一発だろと最初は思いましたが、意外と微妙な感じに・・・・
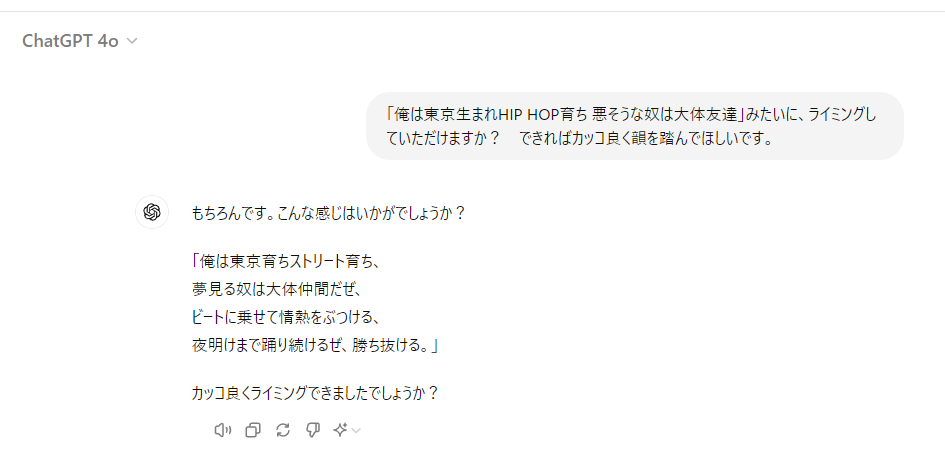
もう、なんか、これ、誰かに怒られるだろ・・・・
ちなみに、Claude 3.5 Sonnet では、こんな感じ。
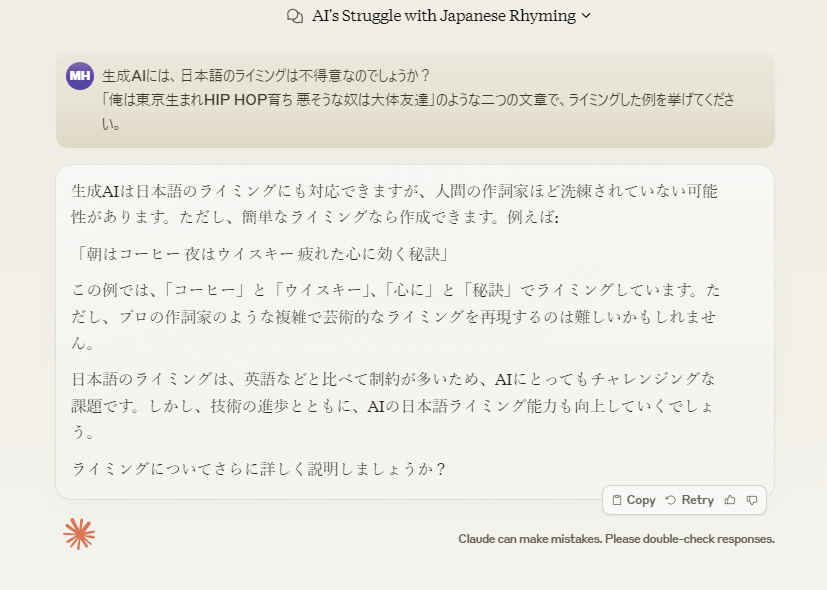
「心に」「秘訣」はライミングしていますか?(謎) ちょっなに言ってるかわからない。
最後の一文にいたっては、上から目線に笑うしかない。
原則、韻事典はNGです!
ちなみに、ラップにおいて韻辞典的なものは、原則禁止です。以下の記事に詳しくありますが、
PySideを使ってJanomeで日本語形態素解析!! 2時間でつくる簡単アプリ
https://hope-is-dream.hatenablog.com/entry/2016/01/06/222235
ZEEBRA師匠は、1995年にもう禁止令を出されていたようです。
2024年になって、釘を刺されるとはさすが師匠。
先に謝罪しておきます。申し訳ありません。こんなの作って。
開発コンセプトは、だいぶ前にR-指定さんが『すべらない話』で披露したエピソードから
かの有名なCreepy Nutsのメンバー、R-指定さんが『すべらない話』に出演されていたのを朧気ながら記憶しています。
名古屋?のバーで、大喜利ならぬ、韻の踏み合いが始まったそうです。まず、ERONEさんという先輩ラッパーの方が、
「ひつまぶし」を「三日ぶりに」食べた。
と言い、そこにいた一同、オッ!?と思ったそうです。
そうなんです。韻を踏んでいたんですね。もうね、韻を踏むのに気づくアンテナがヤバイ。これはつまり、
「ひつまぶし」「HI TU MA BU SI」→「イウアウイ」を
「三日ぶり」 「MI -KKA BU RI」→「イッアウイ」となり、韻を踏んでます。
しかし、そこにいた、ZEEBRA師匠は(促音が入っていて)キレイじゃないと言い、
「五日ぶり」「I TU KA BU RI」→「イウアウイ」
の方がキレイだぞ、と返した、というような内容だったかと思います。
そうなんです、気持ち良く「母音」が重なっているんです。
先行事例
でも、こんなことをやっている人はたくさんいるだろうな、と思って検索したら、たくさんありました。
韻検索-作詞支援ツール/単語データベース
https://kujirahand.com/web-tools/Words.php
韻ノート
https://in-note.com/
単語単位なら、ググればたくさんWebサービスが出てきます。
ただ、さすがに文章だと・・・・
いや、すでに5年も前にやってる方がいらっしゃいました・・・・しかも、Qiitaにて。
文章中から韻を踏んでいるフレーズの組み合わせを検出する gem を作りました
https://qiita.com/suzuki86/items/2a2801944a3e393464c7
さっそく環境を整えて試してみました。
俺は東京生まれヒップホップ育ち 悪そうな奴は大体友達
↓
俺は東京生まれヒップ 俺は東京生まれヒップホップ
やや微妙な結果ですが、これは文章が短すぎるため。
記事中「名詞」を中心に...という説明がありますが、ソースコードを見ると、別の品詞のチェックや、句読点などを見て、割と正確に分析されています。
スコア(筆者はヴァイブスと言い換えてる👍)とかを計算で出して、それに応じた文章の列挙・生成を行っています。だから、それなりに読める文章も出てくる。
ただ、短い文章や、単語単位だと弱いようです。決め打ちで文章が生成されてくるのも少し残念です。あとは、もう少し自由度が欲しい。
あと、Ruby で実装されているので、環境を整えるのが大変でしたね('Ruby'がダメってことではありません。私が慣れていないだけです)。
そこで、私がメイン作業で使っている、.NET C# で少し遊べないかと思いました。
いつもは、拙作の暗号化ツールのメンテナンスを行っているので、簡単にいけるかな、思いまして。
あとは、似ていますが、ちがう文章を生成するよりはむしろ、もう少し形態素分析による品詞単位での、母音が同じものを列挙されるようにしたいと考えました。
アイデアは同じでも、技術がないから力技で行くよ
Visual Studio 2022 から、NuGet で、
- まずは、形態素解析に使う
MeCab.DotNetをダウンロード
MeCab に付属する辞書から、品詞と母音で検索しやすいように、SQLite にテーブルを作成します。 - SQLiteによるデータベースの使用
System.Data.SQLiteをインストールします - あとは、エンコーディング判定の
Ude.NetStandardも入れておきます。
形態素解析辞書には、Web用途が多いからなのか、たまにエンコーディングがEUC-JPたったりすることがあるので、日本語エンコーディングを判別します
技術力というか、前述のRubyのような綺麗で、洗練されたソースコードは書けなくとも、こちらには今や生成AIがある(けっきょく頼るのかい)。
とはいえ、ライミングが苦手の生成AIが、それこそ正しく、そのツールのソースコードを出力できるとは思えません。
ある程度の指針が必要です。たとえば、こんな感じです。
入力した文章を形態素解析
↓
「品詞」と「読み方(カタカナ)」を抽出
↓
その「母音」を生成
↓
辞書から、同じ「品詞」と、
同じ「母音」から後方一致で探す。
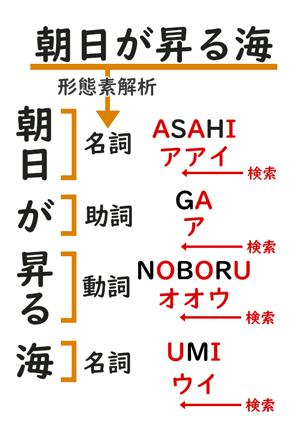
つくったライミング・ツールで、
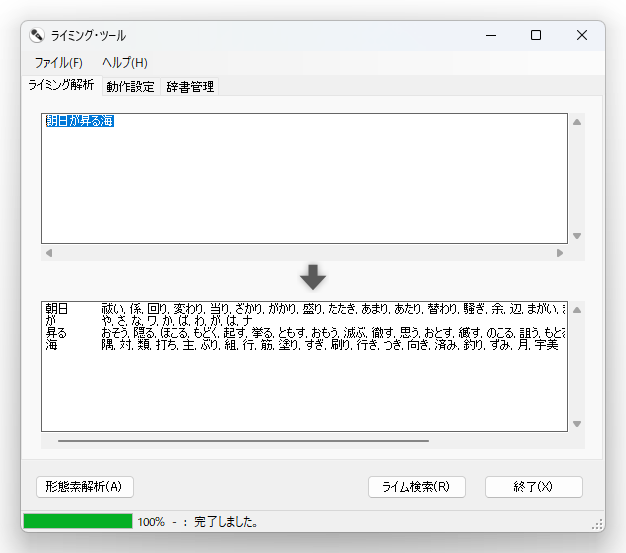
出力した結果がコレです。
朝日, 旭, 祓い, 係, 回り, 変わり, 当り, ざかり, がかり, 盛り, たたき, あまり, あたり, 替わり, 騒ぎ, 余, 辺, まがい, まわり, 絡み, 余り
の, ノ, 之, ヨ, よ, ヲ, ぞ, と, の, を, ど, も, けれども, なんぞ, けれど, ものの, けども, ども, しも, っと
昇る, のぼる, おそう, 隠る, ほこる, もどく, 起す, 挙る, ともす, おもう, 滅ぶ, 徹す, 思う, おとす, 縅す, のこる, 詛う, もとる, 及ぶ, 寄越す, 氷る
海, 宇美, 隅, 対, 類, 打ち, 主, ぶり, 組, 行, 筋, 塗り, すぎ, 刷り, 行き, つき, 向き, 済み, 釣り, ずみ
この出力結果を使って、続きのリリックを書いてみましょう
朝日の昇る海
(あさひの のぼる うみ)
騒ぎの戻る月
(さわぎの もどる つき)
つまり、こういうことです。

どうですかね? わりといい感じにライミングしてないですかね?
まずは辞書づくり
形態素解析の MeCab に付属していた辞書を再編成することにしました。
「単語」「品詞」「読み」「発音」「母音」← NEW!!
といったように、「母音」を加え、テーブルに並べ替えます。検索されやすい、品詞、発音、母音にはインデックスを張ります。
先述の Ruby 製 Rymer は、子音を x に置き換えて、その同じ母音が末尾からあるかをローマ字にしてニュアンスを判定していましたが、こちとら力技なんで、「アイウエオ」のカタカナでやることにしました。実際は、こんなテーブル。
private readonly Dictionary<char, char> KatakanaToVowelMap = new()
{
{ 'ア', 'ア' }, { 'イ', 'イ' }, { 'ウ', 'ウ' }, { 'エ', 'エ' }, { 'オ', 'オ' },
{ 'カ', 'ア' }, { 'キ', 'イ' }, { 'ク', 'ウ' }, { 'ケ', 'エ' }, { 'コ', 'オ' },
{ 'サ', 'ア' }, { 'シ', 'イ' }, { 'ス', 'ウ' }, { 'セ', 'エ' }, { 'ソ', 'オ' },
{ 'タ', 'ア' }, { 'チ', 'イ' }, { 'ツ', 'ウ' }, { 'テ', 'エ' }, { 'ト', 'オ' },
{ 'ナ', 'ア' }, { 'ニ', 'イ' }, { 'ヌ', 'ウ' }, { 'ネ', 'エ' }, { 'ノ', 'オ' },
{ 'ハ', 'ア' }, { 'ヒ', 'イ' }, { 'フ', 'ウ' }, { 'ヘ', 'エ' }, { 'ホ', 'オ' },
{ 'マ', 'ア' }, { 'ミ', 'イ' }, { 'ム', 'ウ' }, { 'メ', 'エ' }, { 'モ', 'オ' },
{ 'ヤ', 'ア' }, { 'ユ', 'ウ' }, { 'ヨ', 'オ' },
{ 'ラ', 'ア' }, { 'リ', 'イ' }, { 'ル', 'ウ' }, { 'レ', 'エ' }, { 'ロ', 'オ' },
{ 'ワ', 'ア' }, { 'ヰ', 'イ' }, { 'ヱ', 'エ' }, { 'ヲ', 'オ' },
{ 'ッ', 'ッ' }, // 促音(例外)
{ 'ン', 'ン' }, // 撥音(例外)
{ 'ガ', 'ア' }, { 'ギ', 'イ' }, { 'グ', 'ウ' }, { 'ゲ', 'エ' }, { 'ゴ', 'オ' },
{ 'ザ', 'ア' }, { 'ジ', 'イ' }, { 'ズ', 'ウ' }, { 'ゼ', 'エ' }, { 'ゾ', 'オ' },
{ 'ダ', 'ア' }, { 'ヂ', 'イ' }, { 'ヅ', 'ウ' }, { 'デ', 'エ' }, { 'ド', 'オ' },
{ 'バ', 'ア' }, { 'ビ', 'イ' }, { 'ブ', 'ウ' }, { 'ベ', 'エ' }, { 'ボ', 'オ' },
{ 'パ', 'ア' }, { 'ピ', 'イ' }, { 'プ', 'ウ' }, { 'ペ', 'エ' }, { 'ポ', 'オ' },
{ 'ャ', 'ア' }, { 'ュ', 'ウ' }, { 'ョ', 'オ' },
{ 'ァ', 'ア' }, { 'ィ', 'イ' }, { 'ゥ', 'ウ' }, { 'ェ', 'エ' }, { 'ォ', 'オ' },
{ 'ヴ', 'ウ' },
{ 'ー', 'ー' }, // 音引き(例外)
};
ええ、そうですとも、力技ですw
例外は撥音と促音、音引きくらいでしょうか。あとは全部「アイウエオ」に置換!
ここから、元のCSVファイルの辞書を変換して、辞書登録・生成だけで二時間・・・・けっこういいPC使ってるんですけどね・・・・
MeCab辞書を加工して入れ直しただけで、47.3MBサイズのデータベースになりました。
形態素解析を使った単語から検索条件を決める
文章をまず形態素解析にかけます。
using var mecab = MeCabTagger.Create();
// 最初の要素(全文)と最後の要素(EOS)をスキップ
foreach (var node in mecab.ParseToNodes(inputText).Skip(1).SkipLast(1))
{
var features = node.Feature.Split(',');
var surface = node.Surface; // 品詞
var partOfSpeech = features[0]; // 単語
var reading = features.Length > 7 ? features[7] : ""; // 読み
var pronunciation = features.Length > 9 ? features[9] : reading; // 発音
// 母音を出すクラス(先ほどのテーブルから発音のカタカナから抽出します)
var vowels = _vowelExtractor.ExtractVowels(reading, pronunciation); // 母音
}
次に、品詞毎に検索をかけます。先の Ruby スクリプトとはちがって、文章を作るのが目的ではなくて、品詞ごとの母音が一致するワードを調べます。
あとは、「母音」を後方から文字列を比較して、できるだけ近いものをピックアップします。
完全一致があれば、それを優先的にピックアップします。一致率は、75%(切り捨て)以上の一致を条件としています。
たとえば、4文字の単語なら、3文字以上が75%という感じです。ただ、一致率は変数化したのでもっと低いパーセンテージに変更しても行けます。
これを指定した数分だけまず列挙します。最大数も変数にしましたが、初期値は20個ピックアップするようにしました。
そしてできたのは・・・・
実際にできたので、やってみました。

俺は東京生まれHIP HOP育ち 悪そうな奴は大体友達
これだと、形態素解析は半角英数字に弱いため、「HIP HOP」が引っかかりません。
俺は東京生まれヒップホップ育ち 悪そうな奴は大体友達
と少し改変します(ごめんなさい、師匠)
検索結果は以下の通り。
俺, オレ, 声, 米, 肥え, 骨, 漏れ, 染め, 度目, もれ, 寄せ, 超, とせ, 尾根, 曽根, 野江, ソメ, 小瀬, トゲ, ヨ子
は, や, さ, な, ワ, か, ば, わ, が, は, ナ, としましたら, といった, からには, どころか, やいなや, ってな, じゃあ, なんか, じゃァ, かしら
東京, 電子協, 号証, 卒業, 高唱, 放尿, 騒じょう, 相乗, 増徴, 読了, 納涼, 訪朝, ようちょう, 合力, 北上, 奉唱, 公称, 増殖, 口しょう, 交渉, 涜職
生まれ, 生, 疲れ, 船出, 区分け, 迎, 舟瀬, 燕, 草瀬, 倉瀬, 鞍手, 鵜岳, 百足, 深江, 船瀬, 熊手, 雲梯, 二瀬, 舟江
ヒップ, 匹夫, しっぷ, しっ駆, 湿布, チップ, キック, キッス, 疾駆, 比布, 聚富, 一区, 一宮, ビッグ, ミック, キッツ, 一九, リック, ニック, 必須, シック
ポップ, ポップ, ノック, こっ苦, ロック, ホップ, 刻苦, 堀津, 木津, 六供, トップ, 四つ, モッブ, ドック, ノッブ, オッズ, 六腑, ホック, コップ, ロップ
育ち, 育ち, ごわし, ほざき, ほざい, 染まり, 拒み, もがき, もがい, ござい, とがり, ぼかし, 止まり, こがし, のばし, もだし, おわり, 閉ざし, 終り, 漏らし, よたり
悪, わる, かく, やす, なる, あつ, 軽, ナウ, 熱, 厚, 丸, まず, かる, 弛, かゆ, 安, 篤, なく, なう, なぅ
そう, 曾宇, 盗, 侯, 草, OFF, 頭, 号, 砲, 報, 光, ソル, 校, 速, モル, 工, 用, 高, 増, 島, 没
な, 無, だ, た, や, な, らしけりゃ, たけりゃ, 御座りゃ, 無けりゃ, なけりゃ, ござりゃ, らしから, らしきゃ, べから, たから, たきゃ, 御座ら, 無から, 無きゃ
奴, 谷津, 訳, 角, 枠, 幕, 薬, 拍, 学, 額, 楽, タル, 役, 格, 初, 末, 策, 画, 札, 安, 刷
は, や, さ, な, ワ, か, ば, わ, が, は, ナ, としましたら, といった, からには, どころか, やいなや, ってな, じゃあ, なんか, じゃァ, かしら
大体, 代替, 栽培, 開会, タジタジ, 鉢巻き, 廃頽, さい配, 頽廃, さい帯, 改廃, 采配, 拐帯, 滞在, 皆済, さいわい, 懐胎, 礼拝, 妻帯, 炊出し, 改題
友達, ともだち, 横ばい, おもらし, 野母崎, 大網, 大谷池, 本崎, 淀橋, 小野町, 大平, 小母崎, 大滝, 大矢知, コノ谷, 大橋, 大崎, 殿崎
自分で言うのもなんですが、わりと良い感じに「韻辞典」としても使えるかも。
全自動とはいかなくとも、少なくともとりあえず何かを自分で書き出すキッカケには、なるかもしれません。
ライミング・ツールのダウンロード
この「ライミング・ツール」は完パケで動きます。
Windows10, 11 であれば、ほぼすべてで動作します(そこは、Ruby環境などを整えなくてもできるのが利点)。
GitHub に公開しています。「ソースは要らない、ツールだけ試したい」という方は、右の方にある「Release」からか、公式ウェブサイトからダウンロードしてください。サイズが、ふつうにデカいので、ZIPもデカい。そこだけは注意。
不安な方はインストーラーを使った方が正しく必須ファイルは配置されるので、そちらがオススメです。
以下のページから、ダウンロードしてください。
GitHub
https://github.com/hibara/RhymingTool/releases
または、公式ウェブサイトから
https://hibara.org/software/rhymingtool/
-
ZIPファイルの場合(
RhymingTool[バージョン番号].zip)
中身のファイルを動かさずに実行ファイル(RhymingTool.exe)を起動してください。
また、アクセスに管理者権限の必要な解凍場所によっては正常に動かないことがあります。
そのあたりが心配な方は、以下のインストーラーを利用してください -
インストーラーからの場合(
RhymingTool[バージョン番号].exe)
必要なデータ配置が心配な場合は、こちらのインストール版をお使いください。
Program Files(x86)にインストールされ、データベースファイルは、
C:\Users\[ユーザー名]\AppData\Roaming\RhymingToolに作成されます。また、形態素解析のライブラリMeCab.DotNetが使うdicという辞書もここへ自動生成されます
オープンソース、ライセンス
MITライセンスです。
オープンソースとして、以下に公開されています。
https://github.com/hibara/RhymingTool/
ただし、このアプリケーションの動作に必要なライブラリ群(形態素解析用、データベース操作、文字エンコーディングなど)は、それぞれのライセンスに準じてください(GPLだったり、LGPLなどあります)。
また、作者(私)への許諾・確認なども不要です。
でももし改造されたのなら、フィードバックをもらえると、うれしいです!
あとがき
でも最近、優里さんの新曲『カーテンコール』(2024/07/19リリース)を聴きましたが、サビの部分。
今だカーテンコール
さぁ闘っていこう
に対応できていない・・・・
形態素解析にかけたら、「さぁ」「闘っ」「て」「いこ」「う」に分解されてしまって、そこからはさすがに「カーテンコール」は出てこない。
誰か、知恵を貸してください!
まあ、やっぱりプロ作家には、かなうわけないということですかね。ましてやラッパーの方々は、これをリアルタイムですよ!