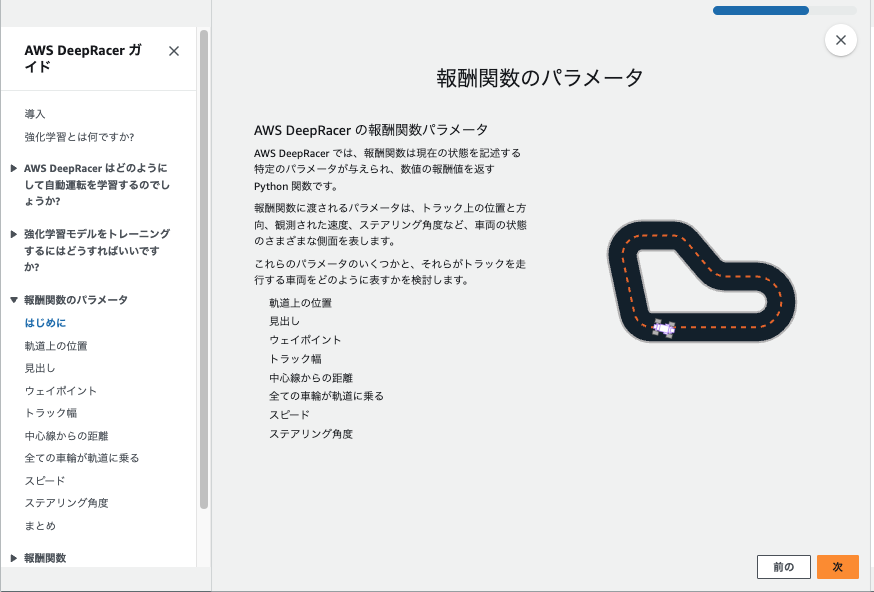
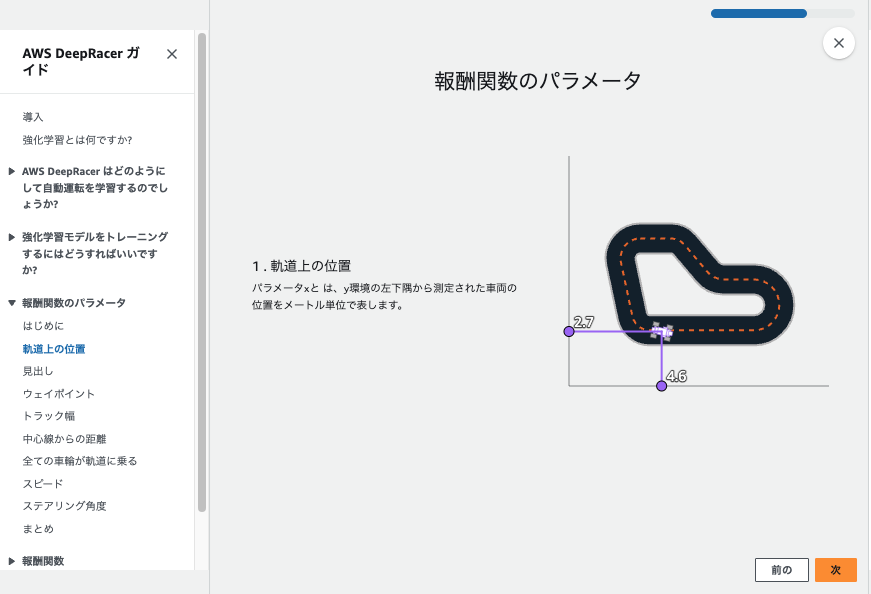
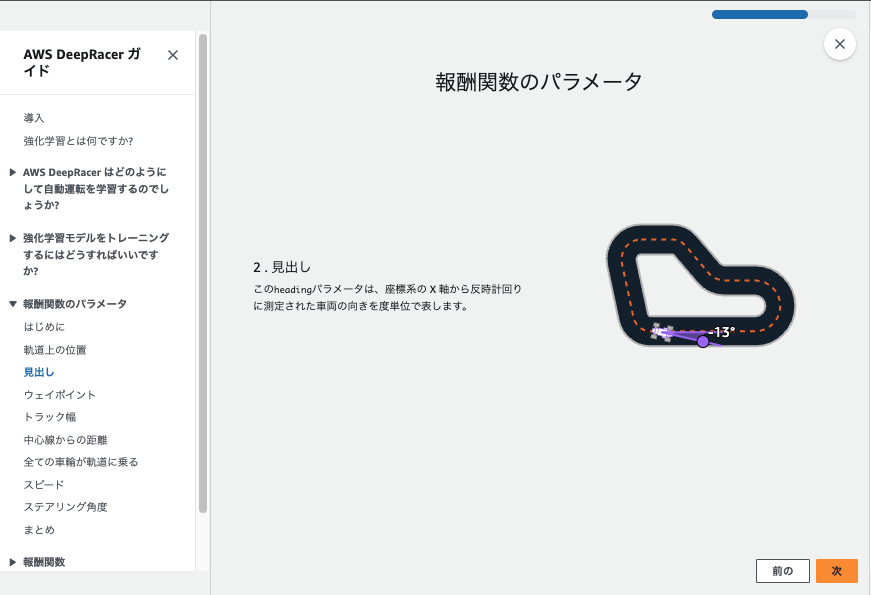
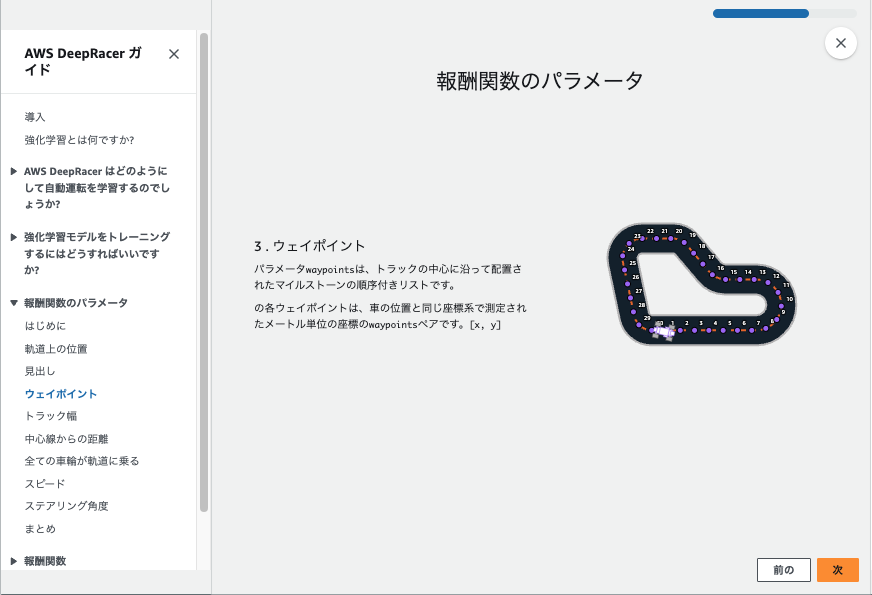
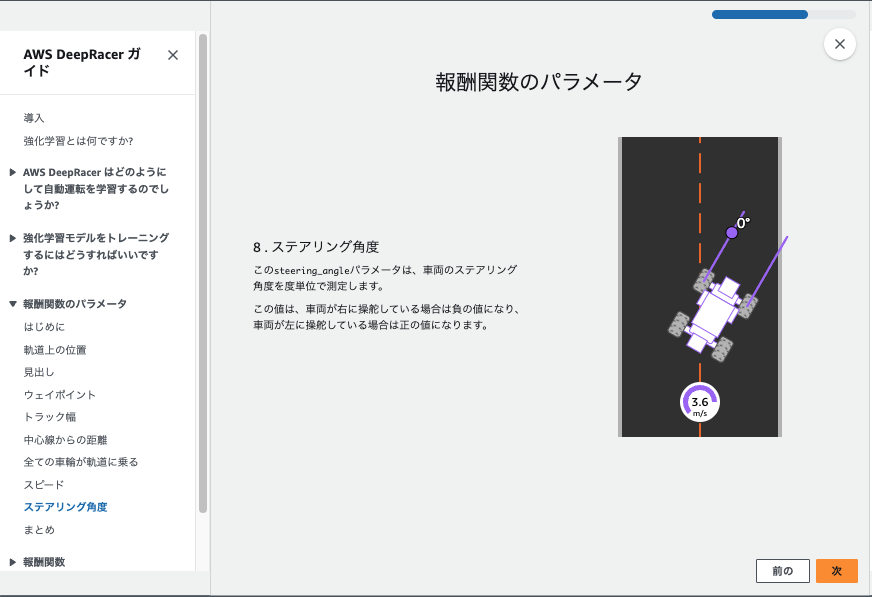
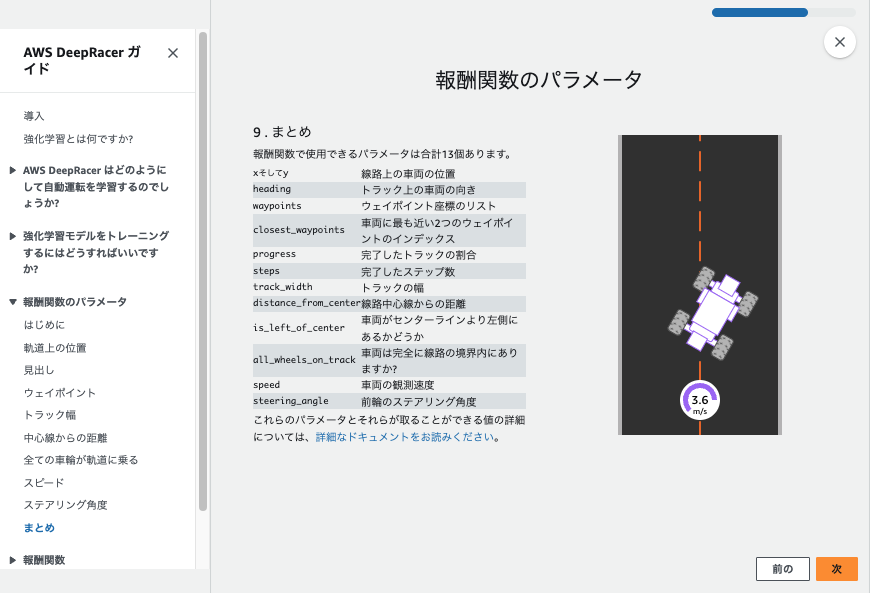
はじめに
AWS DeepRacer をご存知でしょうか?
私は6月のAWS Summitで知りました。
たくさん盛り上がってるブースの中かの1つにそれはありました。
元機械メーカーエンジニアとしては興味深い分野で
いつか参加できたらいいなーくらいの気持ちでいましたが、仮想サーキットで走らせるだけならすぐにできちゃうことを知ったので早速やってみました![]()
![]()

目次
AWS DeepRacerとは
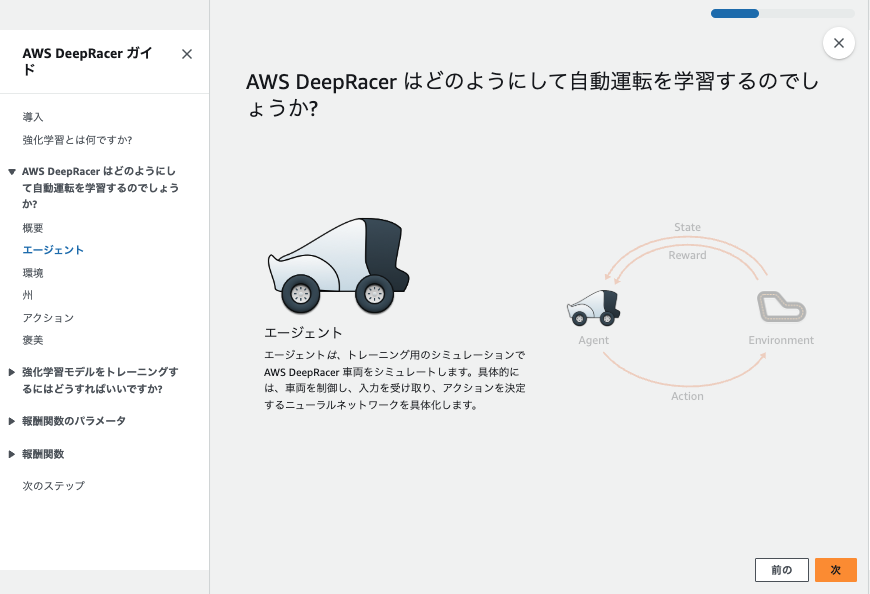
AWS DeepRacerは、AWSが提供する、遊びながら強化学習を学べる1/18スケールの自律走行型レーシングカーです。

-
簡単なカスタマイズ
難しいプログラミングスキルや複雑なパラメータ設定を必要とせず、テンプレートを調整するだけで自由にカスタマイズが可能です。
モデル作成〜レースに参加までの流れ
-
モデルの作成
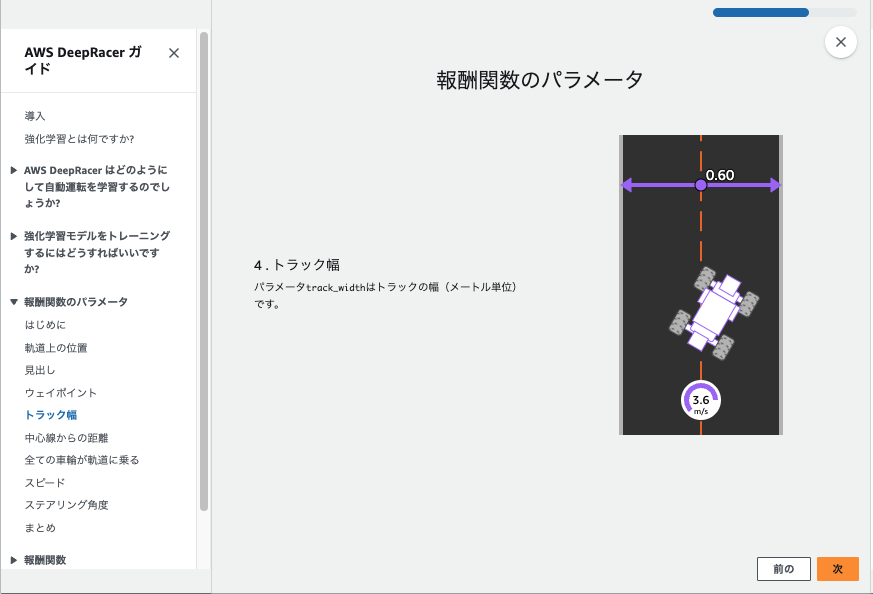
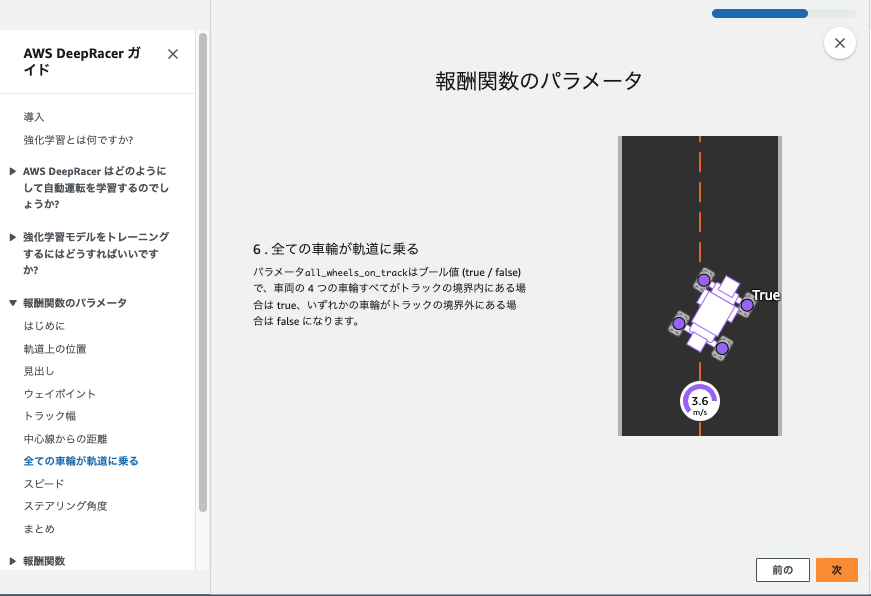
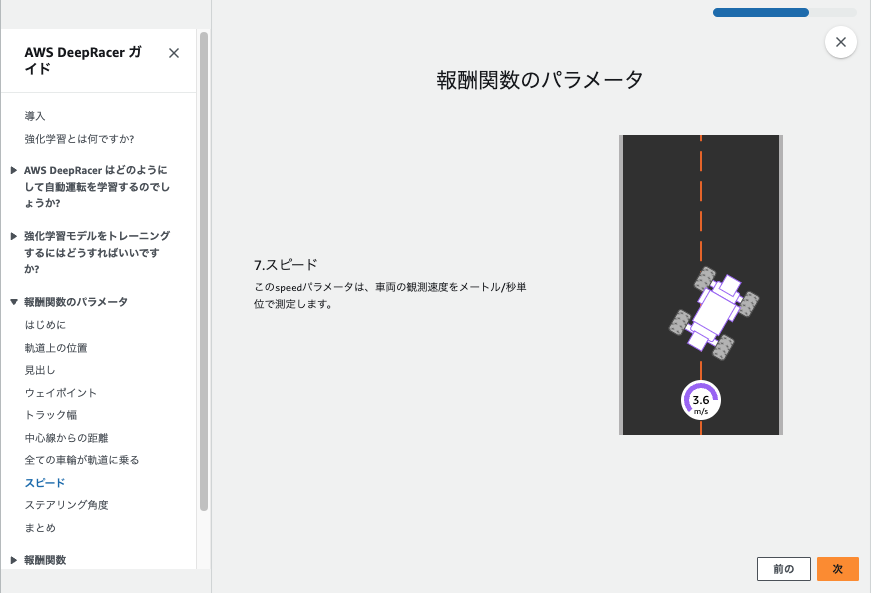
- 報酬関数の定義や走行モデルのパラメータを設定します。
-
強化学習
- 作成したモデルをトレーニングし、報酬の履歴や車の挙動を確認します。
-
モデルの評価
- 仮想トラック上でシミュレーションを行い、モデルの性能を評価・調整します。
-
レースに参加
- 最終モデルで公式レースに挑戦します。(*2024年をもって公式リーグは終了)
詳細については、AWS公式ブログをご覧ください。
- 最終モデルで公式レースに挑戦します。(*2024年をもって公式リーグは終了)
-
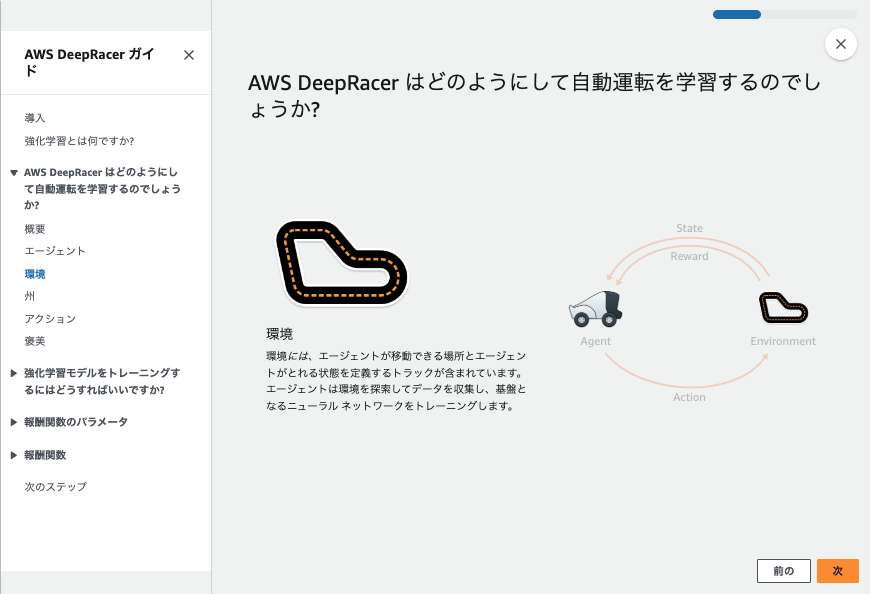
シミュレーションと実機体験
仮想空間でのシミュレーションを通じて安全に学べるだけでなく、実際の物理トラックでリアルな走行を体験できます。
DeepRacerを支える機械学習・強化学習とは
私自身の機械学習や強化学習の知識が乏しいため、少し勉強しました。
とにかく速く車を走らせたいスピード狂の方は以下の項目については読み飛ばしてください。-> ハンズオン
機械学習とは
機械学習は、コンピュータが大量のデータから規則や仕組みを学習し、それをもとに新たなデータや状況に応じて予測や推測を行う技術です。
主に以下の3つの手法があります:
-
教師あり学習
- ラベル付きデータを使用して予測モデルを学ぶ。
-
教師なし学習
- ラベルなしデータからパターンを発見する。
-
強化学習
- 試行錯誤を通じて最適な行動を学ぶ。
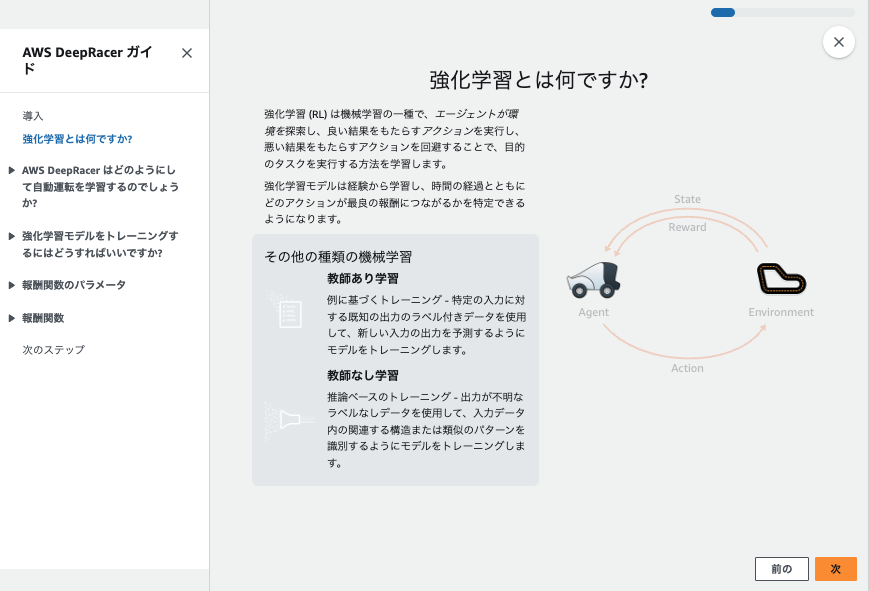
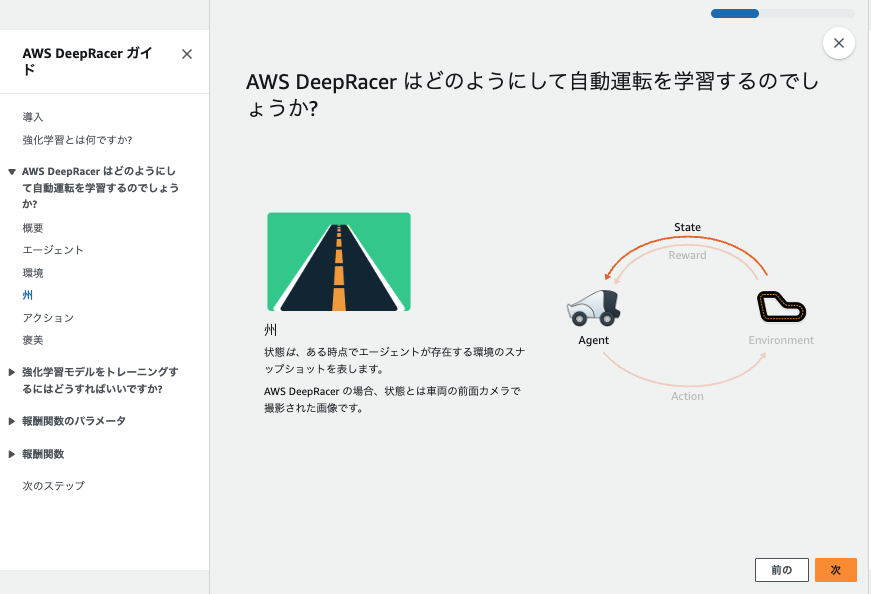
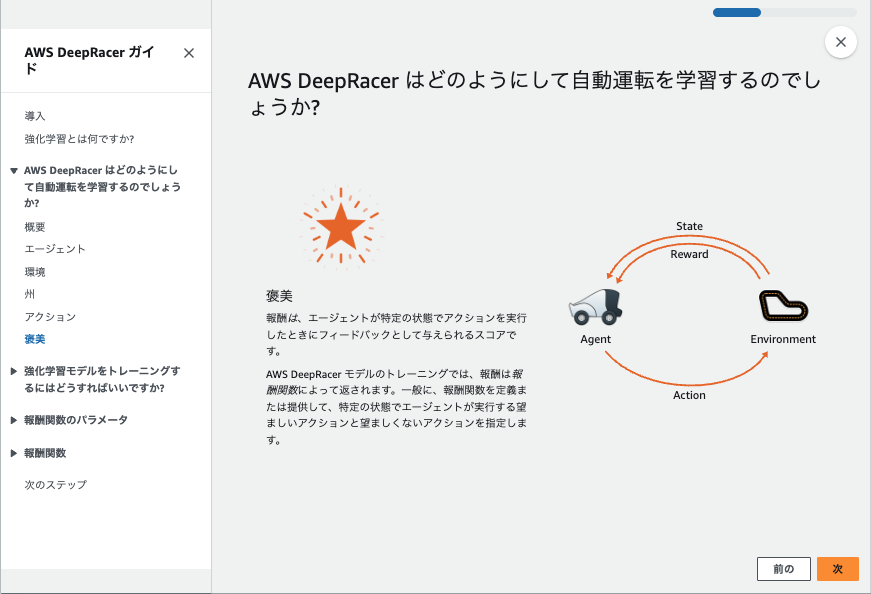
強化学習とは
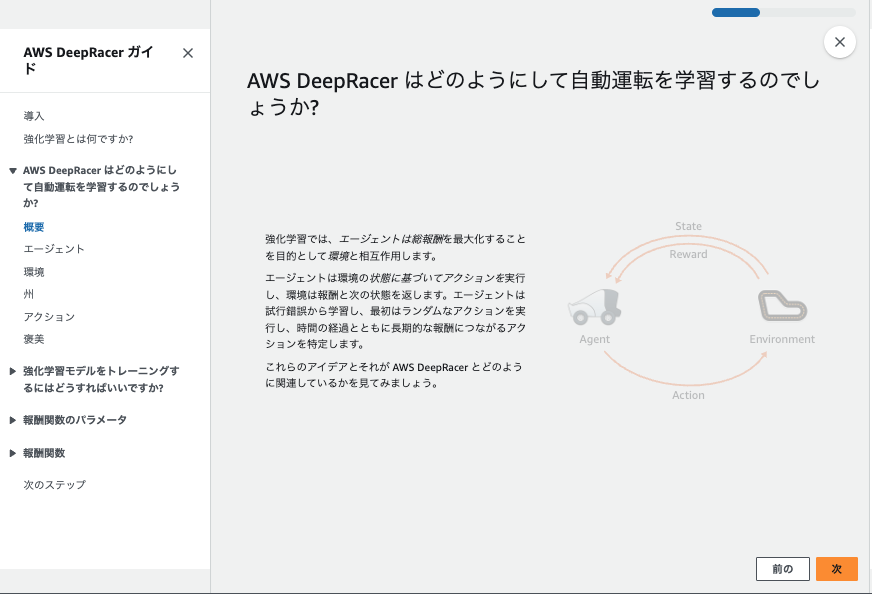
強化学習は、エージェントが特定の環境下で試行錯誤を繰り返し、最適な行動を学ぶ機械学習の一手法です。
行動に対して報酬が与えられ、エージェントはその報酬を最大化するように学習します。
特徴
-
報酬の最適化手法
- 累積報酬を最大化して長期的な利益を追求する(例: Q学習やSARSA)。
- 即時報酬を重視してその場で最適行動を選択する(例: ポリシー勾配法)。
-
具体例
- お掃除ロボットが障害物にぶつかる経験を通じて効率的な掃除経路を学ぶ仕組みなど。
ハンズオン
では実際にAWSコンソールで触れていきましょう!
AWSコンソールで DeepRacer を検索しサービスに移動します。

バージニア北部だけで利用できます。
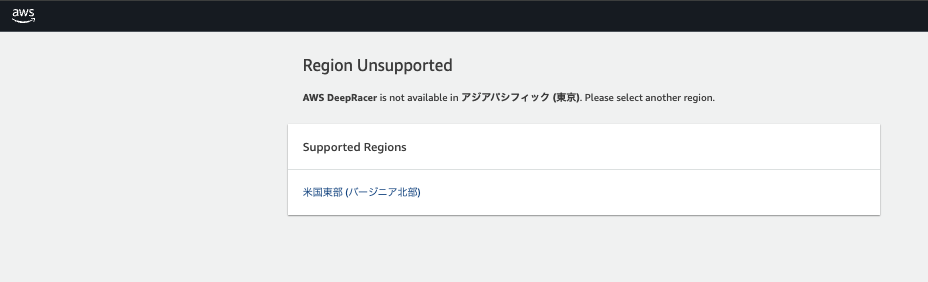
初期画面に遷移しました。
左の管理メニューからGet startedを選択すると、Step1が10分ほどの強化学習講座となってます。
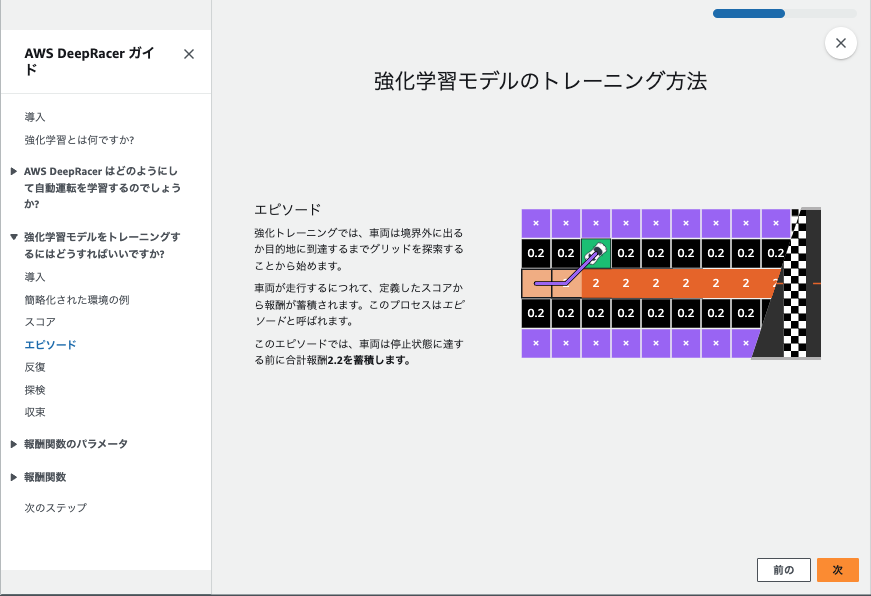
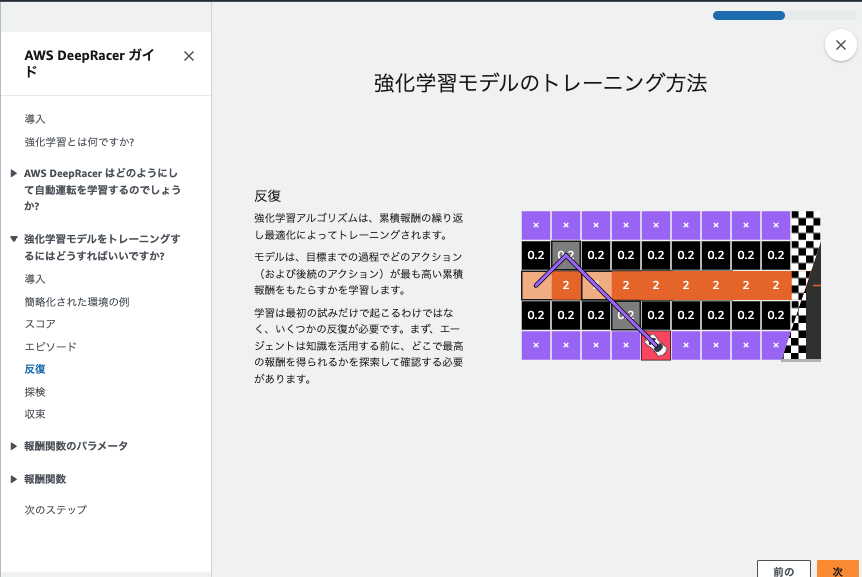
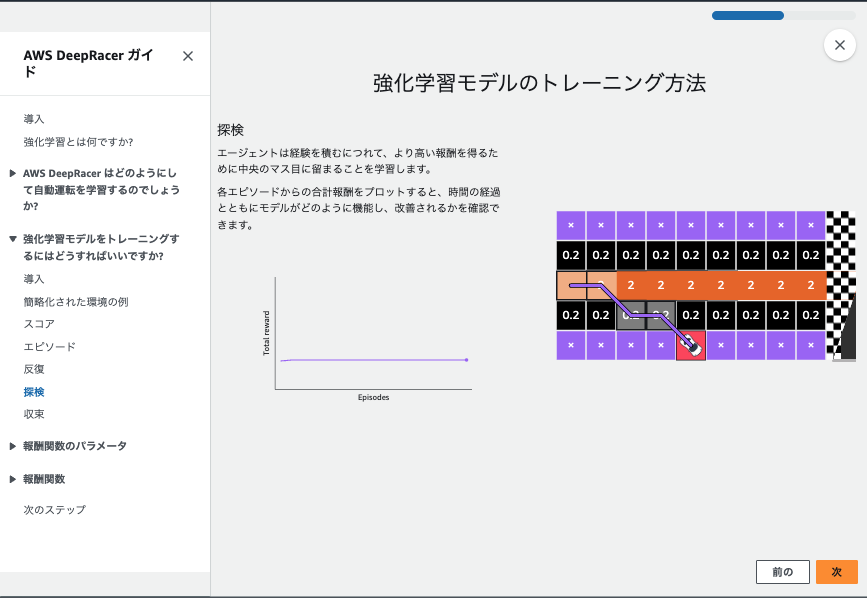
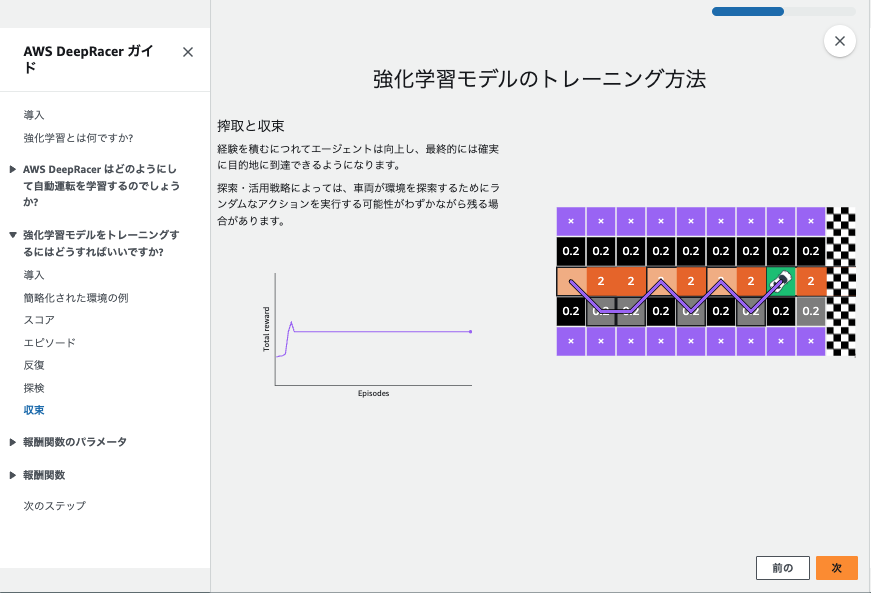
とてもわかりやすかったので、この記事の最後に日本語訳した状態のスクショを用意しました。-> 強化学習の短期集中講座を受講する
モデルを作成する
1.モデル名と環境を指定します
それではモデルを作成していきます。
管理メニューで Reinforcement learning -> Your models を選択して作成開始します。
モデル名とトレーニング内容を記述します。
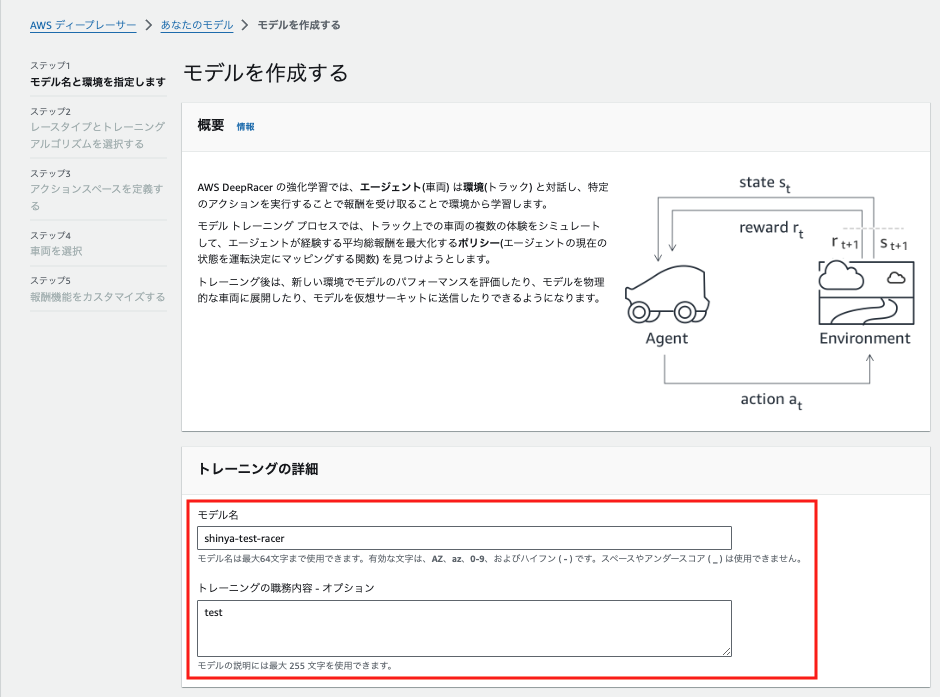
環境を選択します。
デフォルトで選択されている仮想サーキットと反時計まわりのまま次に進みます。
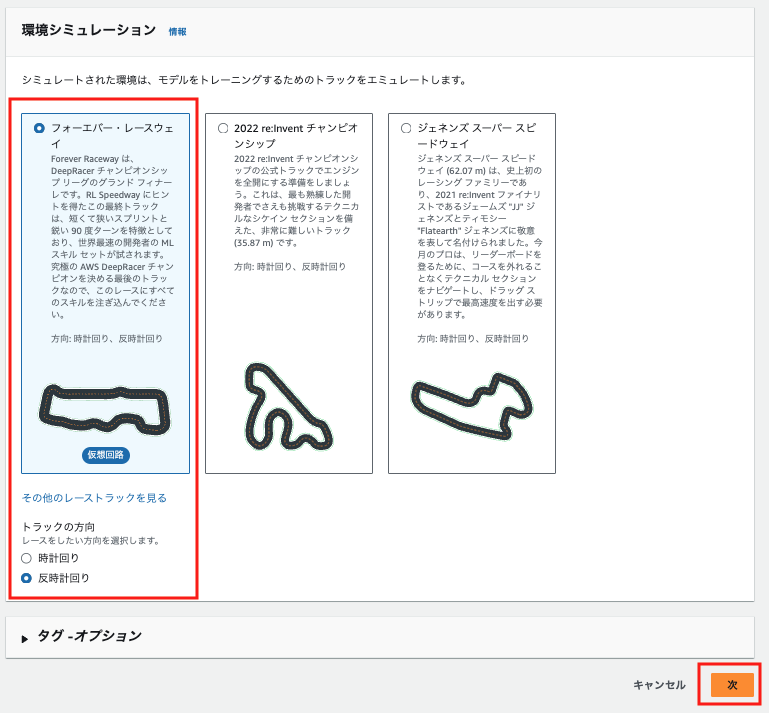
2.レースタイプとトレーニングアルゴリズムを選択する
レースタイプを選択します。
今回は完全ソロプレイなのでタイムトライアルを選択します。
他の車両との対決も面白そうです。
トレーニングアルゴリズムとハイパーパラメータもデフォルトで選択されているPROのまま次にいきます。
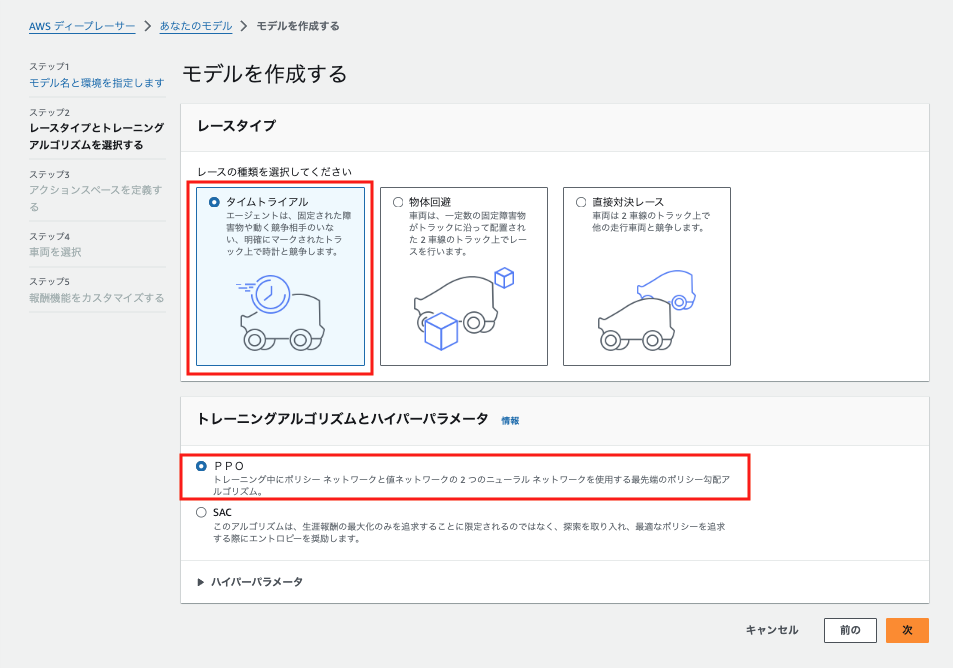
| 特徴 | PPO (Proximal Policy Optimization) | SAC (Soft Actor-Critic) |
|---|---|---|
| ポリシーの種類 | オンポリシー | オフポリシー |
| 目的 | 報酬の最大化と安定した学習 | 報酬の最大化 + 探索(エントロピー)強化 |
| エントロピー | 任意(必要なら使用) | 標準で組み込み(探索を奨励) |
| ネットワーク | 2つ(ポリシー + 値ネットワーク) | 3つ(ポリシー + 2つのQ値ネットワーク) |
| サンプル利用 | 現在のデータのみ使用 | 過去のデータも再利用 |
| 計算コスト | 比較的軽い | 高い |
| 適用環境 | 単純で安定性が重要なタスク | 複雑で探索が重要なタスク |
簡単な選び方
PPO: 安定性が求められるタスクやシンプルな環境に適しています。例: ゲームや単純なロボット制御。
SAC: 複雑な環境や探索が重要なタスクに適しています。例: ロボットアームの精密制御や自動運転。
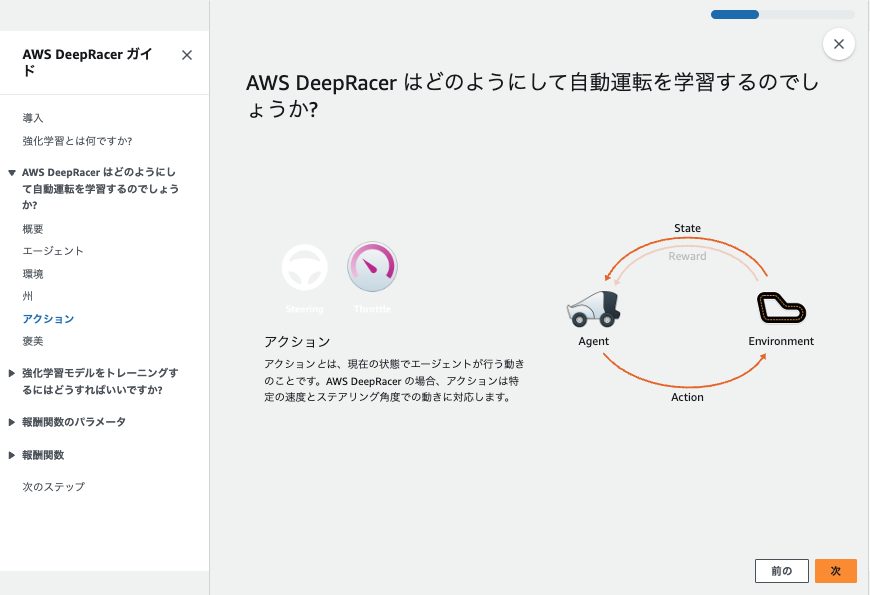
3.アクションスペースを定義する
連続アクションスペース を選択します。
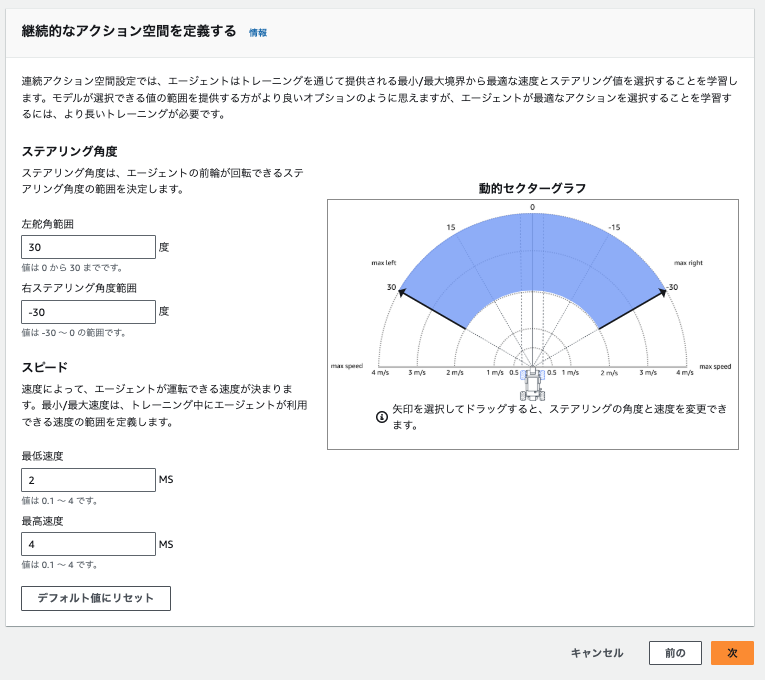
継続的なアクション空間を定義します。
デフォルトでいこうかと思いましたが、スピードが欲しくなり以下で設定しました。
(最低速度0.5→2m/s、最高速度1→4m/s)
| 項目 | 継続的なアクション空間 | 離散アクション空間 |
|---|---|---|
| アクションの種類 | 実数値で細かく調整可能 | 固定された選択肢のみ |
| 柔軟性 | ステアリングや速度を自由に調整 | 限られた範囲で選択 |
| 学習の難易度 | 高い | 低い |
| 計算効率 | 低い | 高い |
| 適用環境 | 複雑なコースや精密な操作が必要な場合 | 簡単なコースやシンプルな操作の場合 |
簡単な選び方
継続的アクション空間: 精密なコントロールが必要な複雑なコースや細かいチューニングを求める場合に使用。
離散アクション空間: 簡単なコースや実装・学習のシンプルさを重視する場合に適している。
4.車両を選択
デフォルトだと1台のみなので、そのまま次へいきます。
丸くてかわいらしいですね。
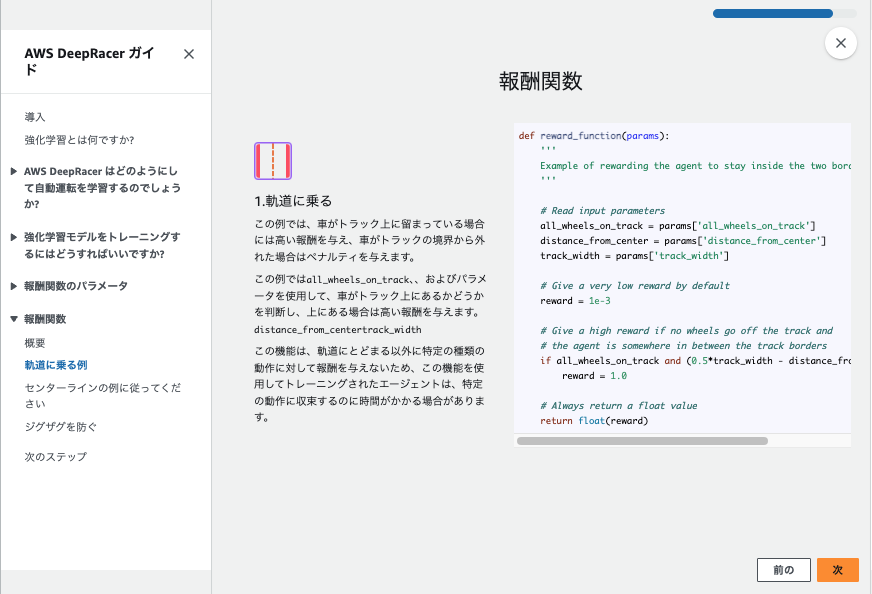
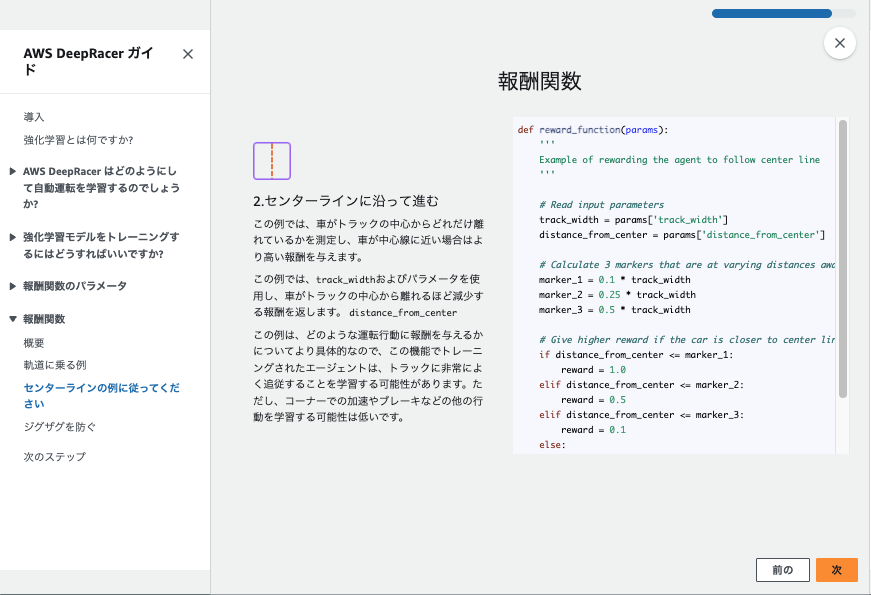
5.報酬機能をカスタマイズする
報酬関数は何個かサンプルコードが用意されていますがデフォルトでいきます。
コード内容がわからないので、生成AIの力を借りて内容を確認しました。
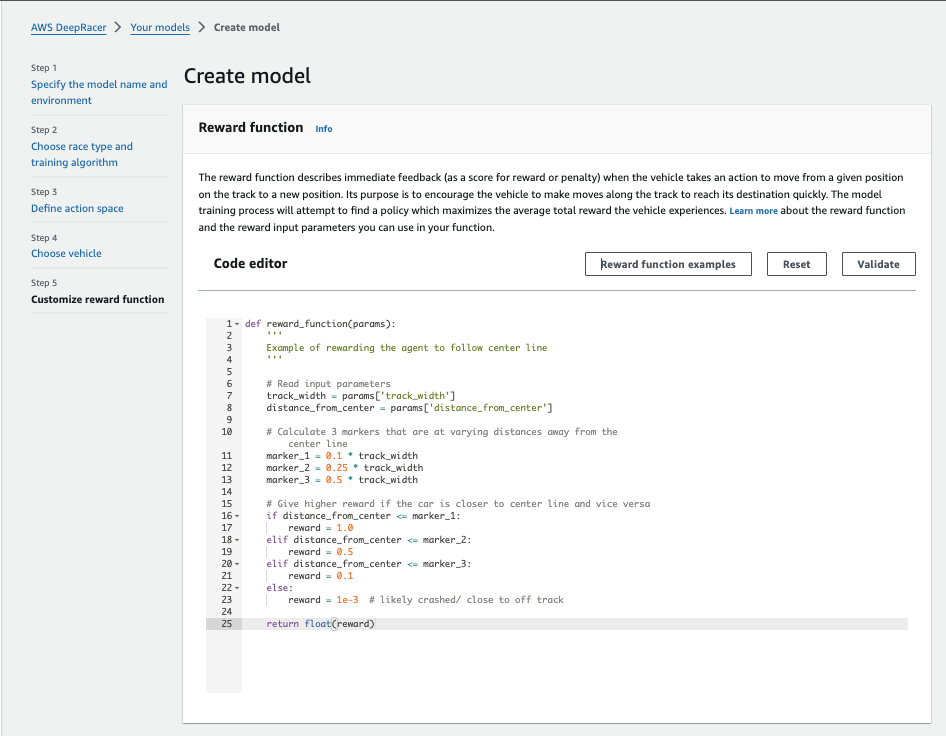
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
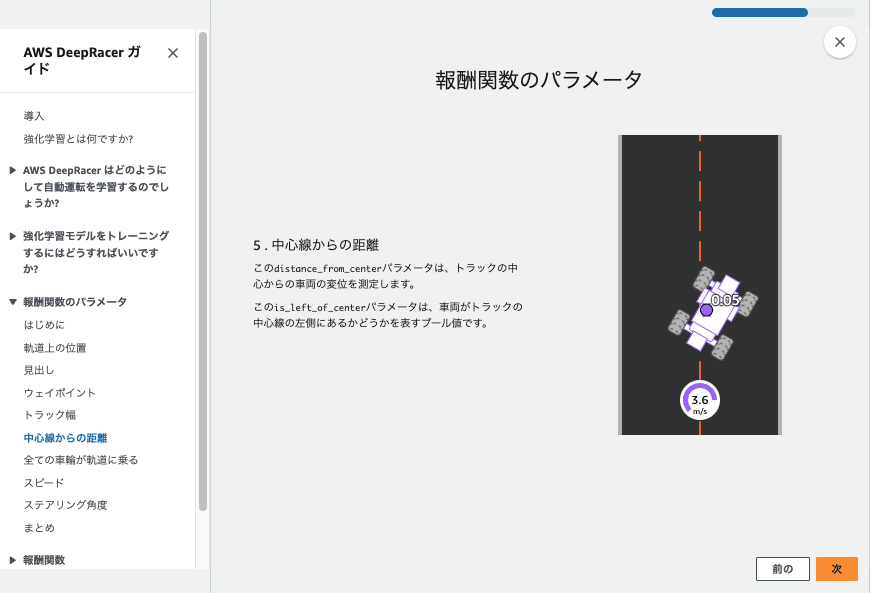
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
私)コード内にコメントアウトで1行ずつ説明してほしいです
⇓⇓⇓
# 報酬関数を定義。引数のparamsには車の状態情報が辞書形式で含まれる
def reward_function(params):
'''
# センターラインに沿って走行するための報酬関数の例
'''
# パラメータの読み込み
# トラックの幅を取得
track_width = params['track_width']
# 車両の中央からの距離を取得
distance_from_center = params['distance_from_center']
# 中央からの距離に基づいて3つのマーカー(境界線)を計算
# トラック幅の10%の位置に最初のマーカーを設定
marker_1 = 0.1 * track_width
# トラック幅の25%の位置に2番目のマーカーを設定
marker_2 = 0.25 * track_width
# トラック幅の50%の位置に3番目のマーカーを設定
marker_3 = 0.5 * track_width
# 中央からの距離に応じて報酬を計算
# 中央から10%以内の場合、最高報酬を与える
if distance_from_center <= marker_1:
reward = 1.0
# 中央から25%以内の場合、中程度の報酬を与える
elif distance_from_center <= marker_2:
reward = 0.5
# 中央から50%以内の場合、低い報酬を与える
elif distance_from_center <= marker_3:
reward = 0.1
# それ以外の場合(コースアウトの危険がある場合)、最低報酬を与える
else:
reward = 1e-3
# 計算した報酬値を浮動小数点数として返す
return float(reward)
私)わかりやすく要約してほしいです
⇓⇓⇓
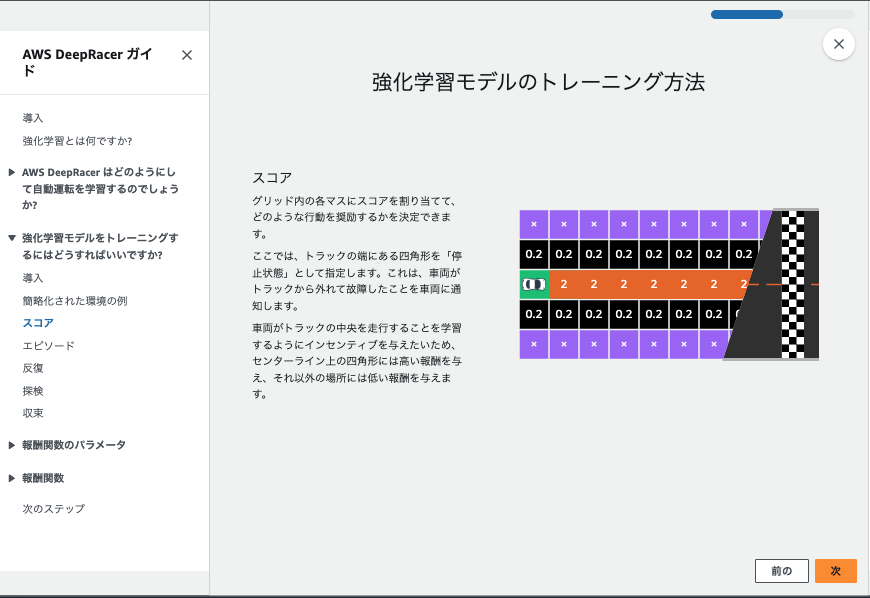
概要
このコードは、AWS DeepRacerが中央のラインに沿って走行することを
学習するための報酬関数です。
主要なポイント
1、3つの走行エリア
・中央から10%以内:理想的な走行位置(報酬1.0)
・中央から25%以内:許容範囲内の走行(報酬0.5)
・中央から50%以内:注意が必要な位置(報酬0.1)
それ以外:危険な位置(報酬0.001)
2、実装のポイント
・トラックの幅を基準に3つの境界線を設定
・中央に近いほど高い報酬を与える
・コース外に近づくと極めて低い報酬に
3、コードの特徴
・シンプルな設計で理解しやすい
・中央寄りの走行を促進
・安全性を考慮した報酬設計
このように、車両の位置に応じて適切な報酬を与えることで、
理想的な走行ラインを学習させることができます。
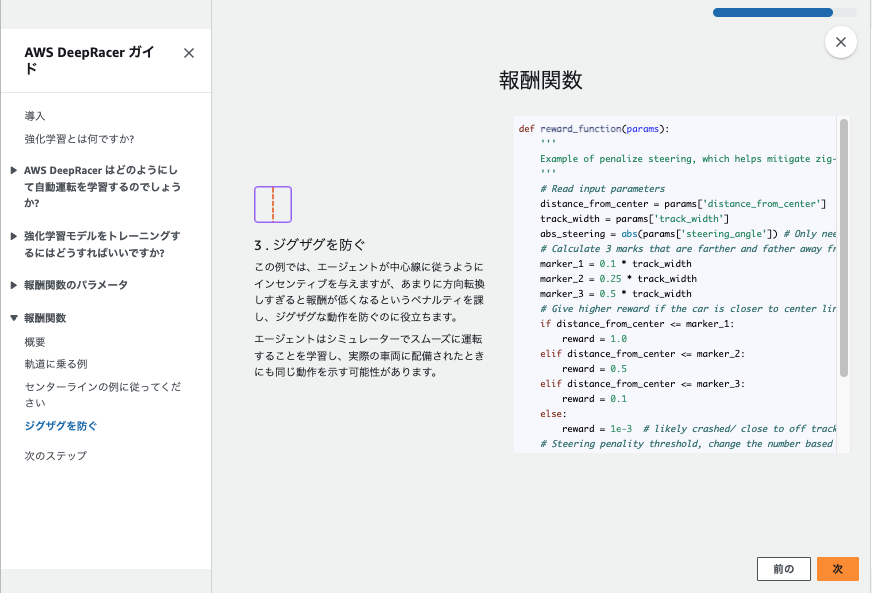
私) 図解できますか?
⇓⇓⇓
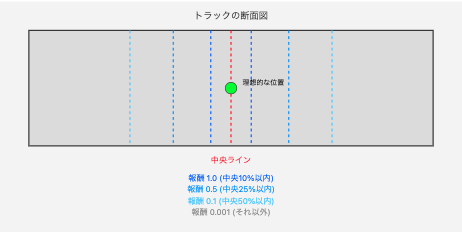
なるほど、、、![]()
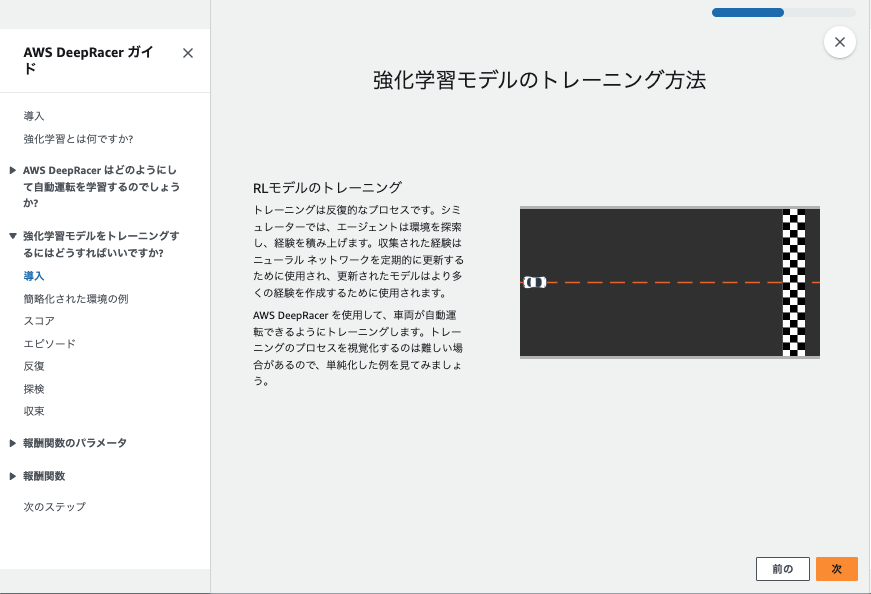
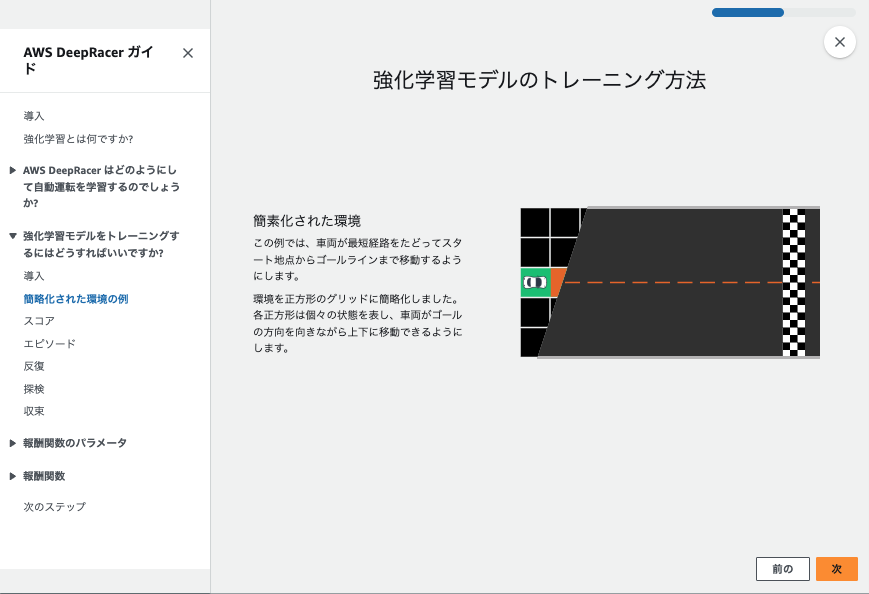
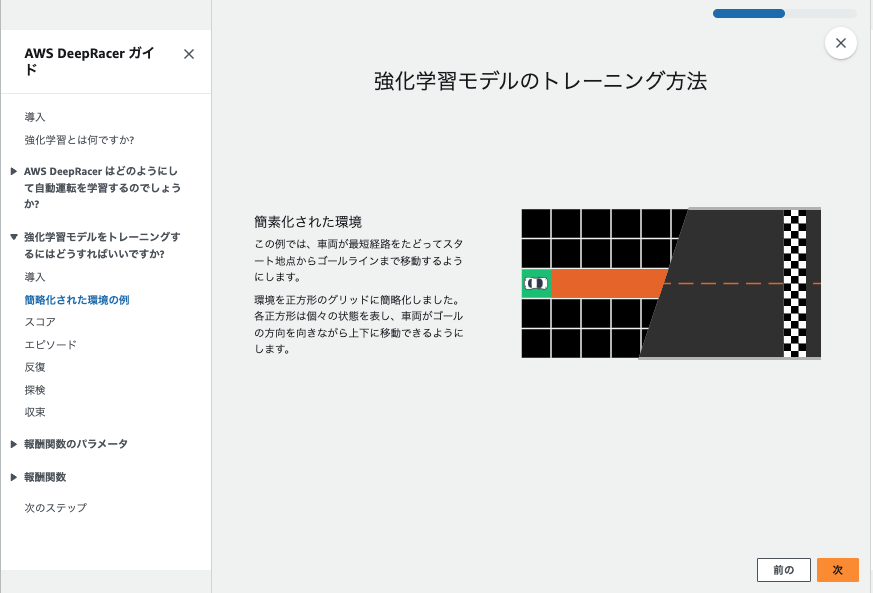
この流れが1ステップごとに実行されて、車が高い報酬を得られる中央寄りを走るように学習してるようです。
掃除用のロボットもこんな感じでお勉強して動いてるのか。。
トレーニングの停止条件はデフォルトのままで 60分 とします。
リーグには出場しないので「DeepRacerレースに自動的に参加する」はチェックを外します。
「賞品通知用メールアドレス -新規」もデフォルトの提供なしで進めます。
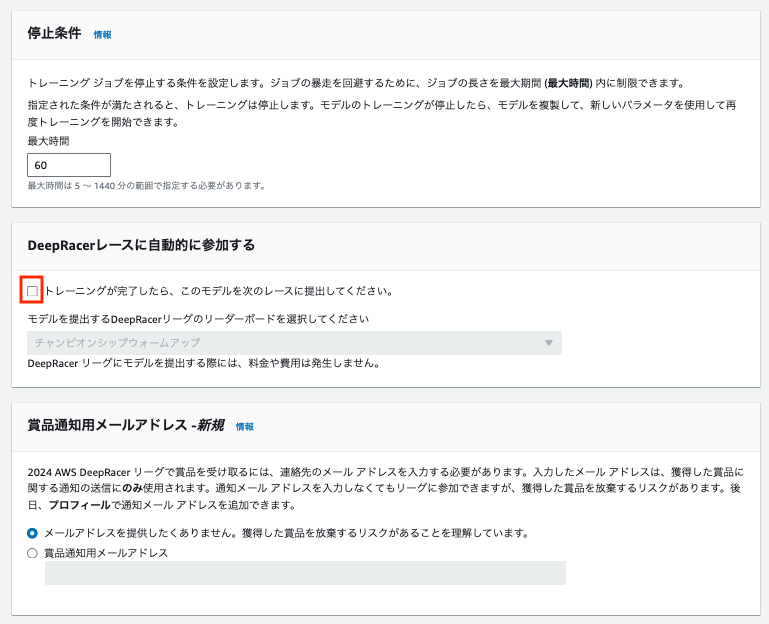
[Create Model]を押すとモデル作成が開始されます。

利用料金に関する記述があります!(2024/12/24時点)
「新規ユーザーにトレーニングまたは評価に 10 時間の 無料期間 が与えられるため、最初のモデルのトレーニング、評価、および仮想サーキットへの送信は 無料 です」
とありますが必ずご確認ください。
トレーニングする
[Create Model]を押したあと、5分ほど待つとトレーニングが開始されます。
リアルタイムで報酬グラフとシミュレーションビデオが閲覧できます。
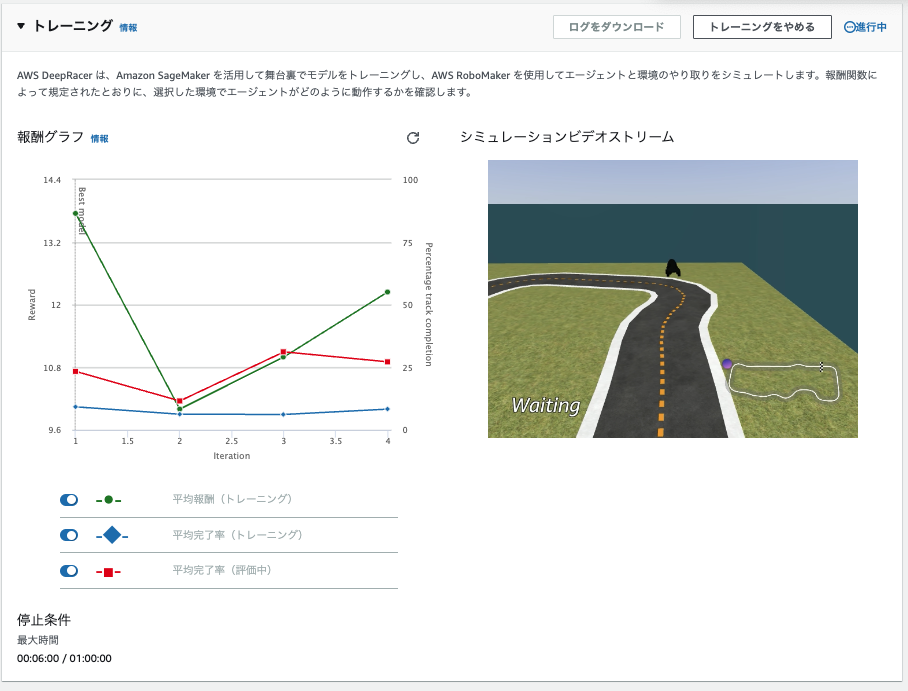
動画で見ると以下のような様子です。
コースアウトしても何度も挑戦する姿に愛着が湧いてきました。
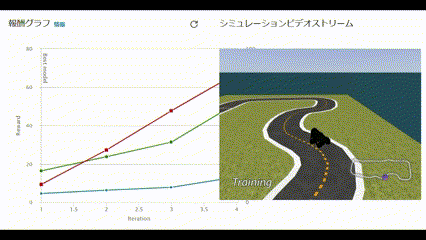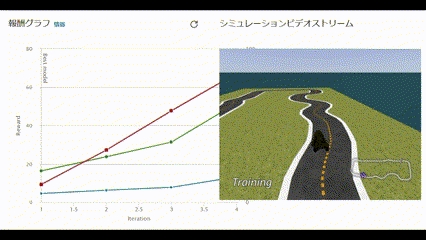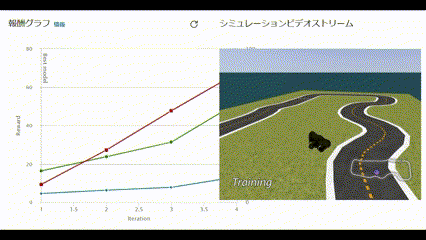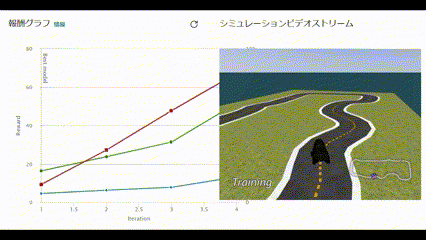
60分経過し、トレーニングが完了しました。
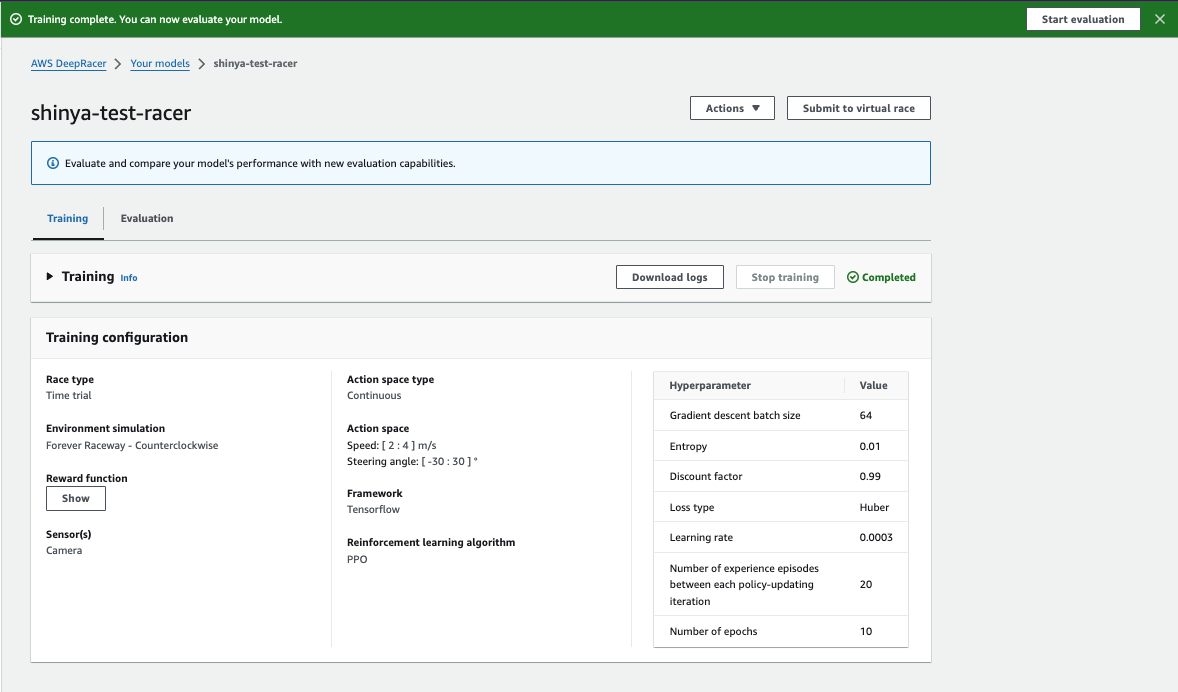
評価する
評価タブに移動して Start evaluation を押下します。
(トレーニングが終わった直後であれば、Start evaluation が右上にもあります)
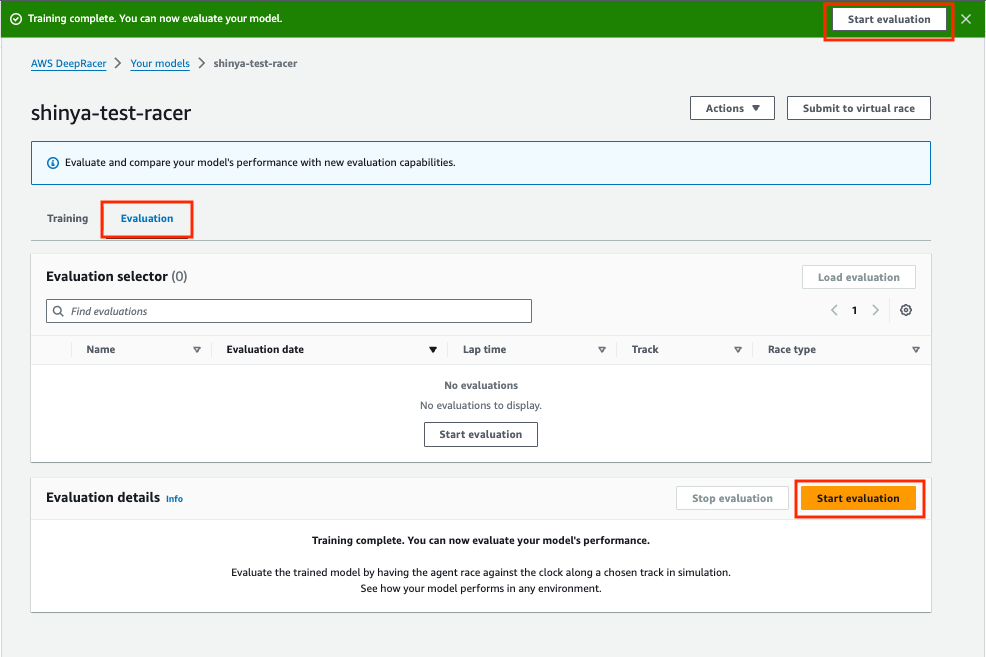
評価名を入力してレースタイプを選択します。
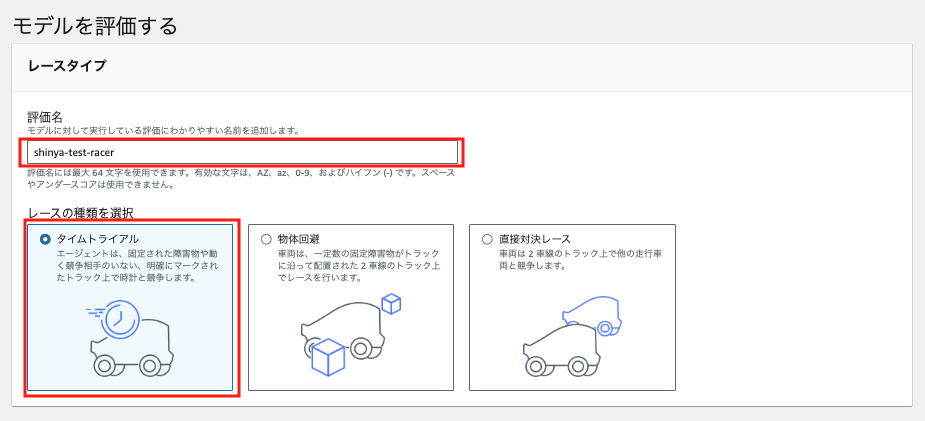
試行回数、コース、方向を選択します。
レースに応募しないのでチェックを外して評価を開始します。
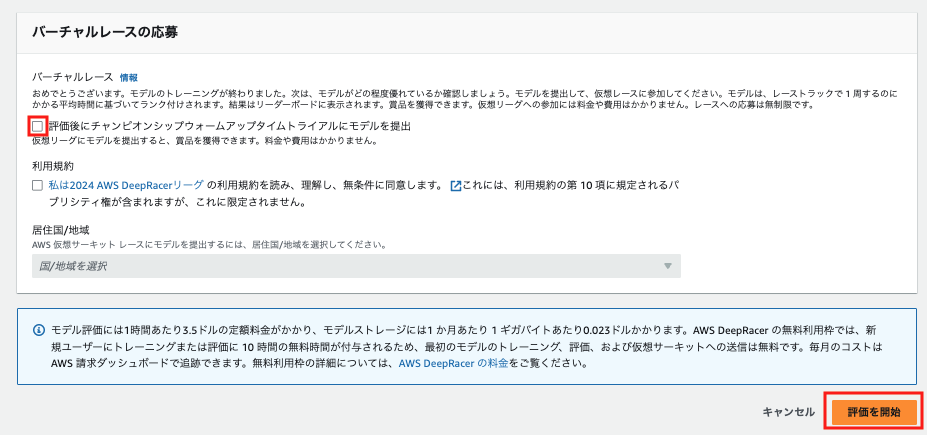
数分後、評価が開始されました。
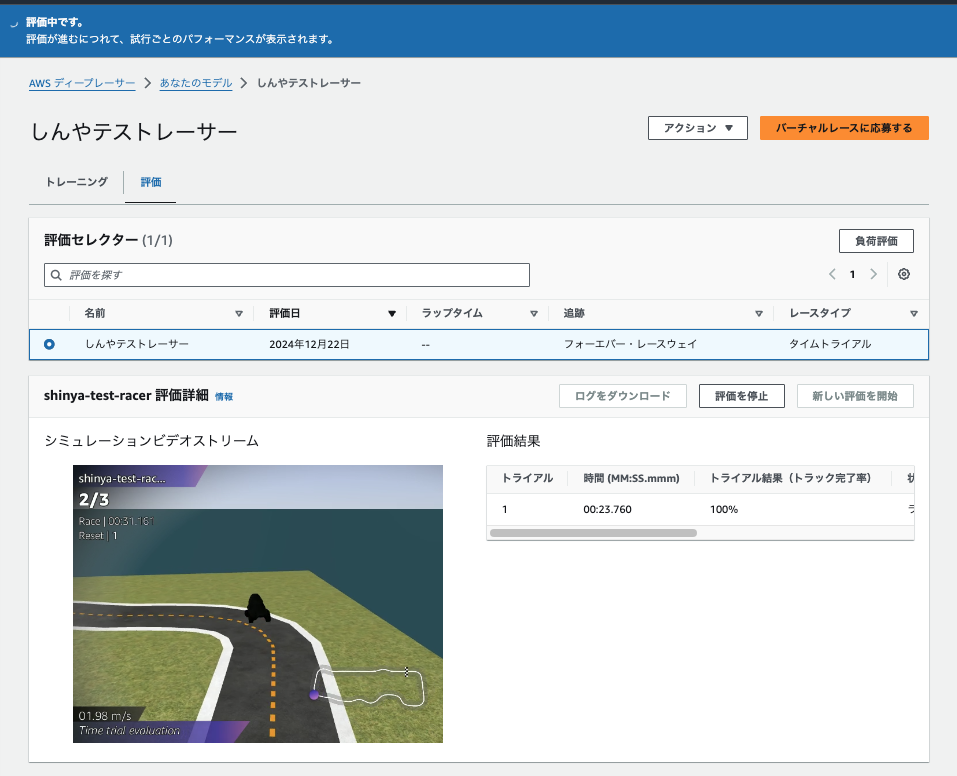
評価が完了しました。
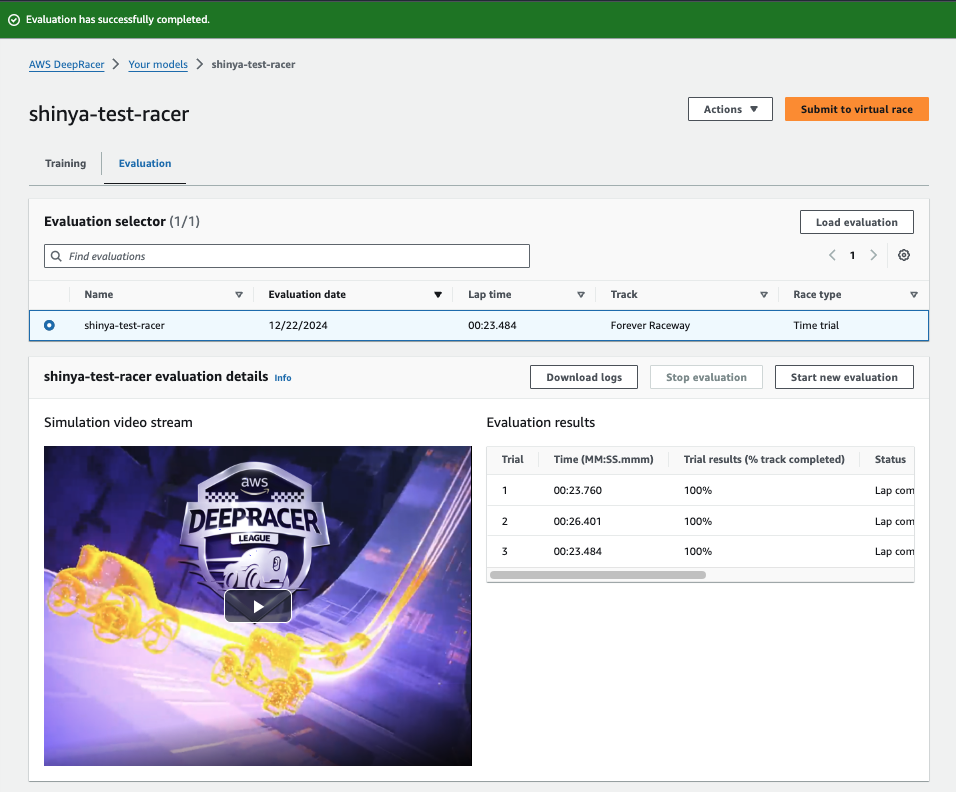
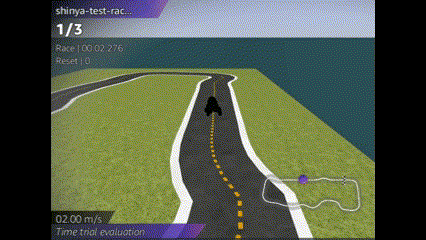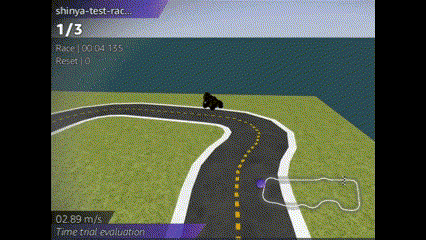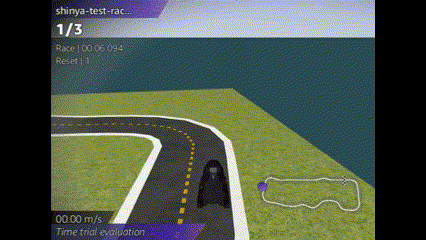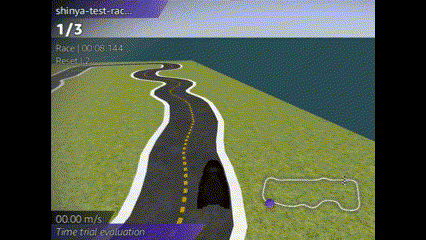
成績は、、、ぜんぜんだめでした!!
コースアウトしまくりの芝生大好きマシーンを生み出してしまいました![]()
![]()
![]()
![]()
![]()
単純に学習時間が少ないのか、報酬関数で調整できるのか、多くの改善が必要です。。。
さらに物理のレースだとタイヤやサーキットの素材や摩擦、車体重量、センサー調整など多様なパラメータがあると思うので検討事項が多いとか思います。
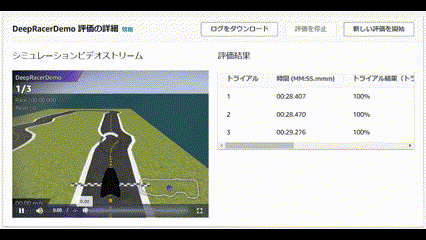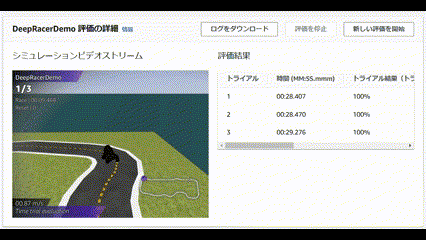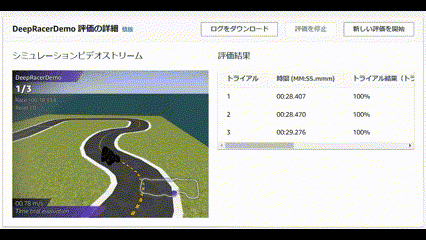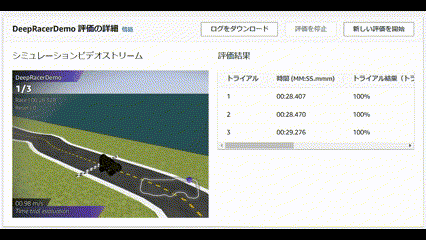
| Trial | Time(MM:SS.mmm) | Trial results(% track completed) | Status | Off-track | Off-track penalty | Crashes | Crach penalty |
|---|---|---|---|---|---|---|---|
| 1 | 00:23:760 | 100% | Lap complete | 5 | 10 seconds | 0 | -- |
| 2 | 00:26:401 | 100% | Lap complete | 6 | 12 seconds | 0 | -- |
| 3 | 00:23:484 | 100% | Lap complete | 5 | 10 seconds | 0 | -- |
以下は全てデフォルト値で設定して成功したパターンです。
とても安全運転です![]()
(最高速度1m/sですが編集の関係で2倍速です![]() )
)
お片付け
不要になったリソースは必ず削除しましょう
それでは作成したモデルの消去を行います。
管理メニューの Your models -> 「消去対象のモデルを選択」 -> Actions の順にクリックします。
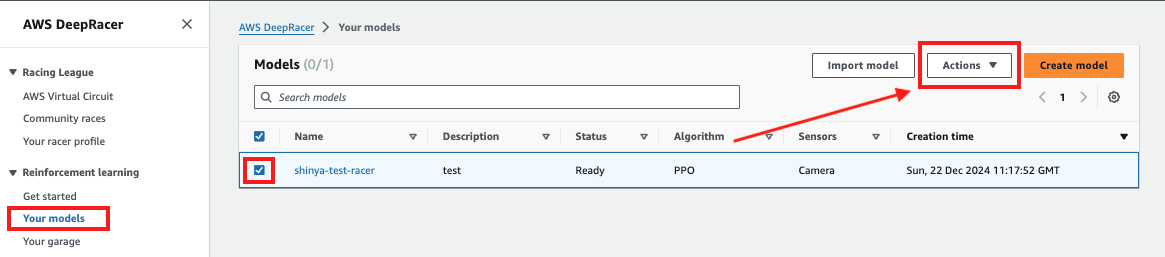
Actionsの Delete を選択して実行します。

削除が完了しました!
必ず請求ダッシュボードをご確認ください。
<参考>
・AWS DeepRacer ワークショップ > リソースの削除
・AWS DeepRacer ご利用後のリソース削除方法について
さいごに
やり込み要素の強いサービスでした。
技術面での私の理解が追いついていないので、強化学習やPythonの基礎の習得をしたい気持ちになりました。
お読みいただきありがとうございました![]()
参考