この記事は拙著100本ノックでPythonに入門の続編です。100本ノック第5章を用いてクラスの説明をメインに解説していきます。
まずはCaboChaをインストールして青空文庫の「吾輩は猫である」を係り受け解析してみましょう。
!cabocha -f1 < neko.txt > neko.txt.cabocha
!head -n15 neko.txt.cabocha
* 0 -1D 0/0 0.000000
一 名詞,数,*,*,*,*,一,イチ,イチ
EOS
EOS
* 0 2D 0/0 -0.764522
記号,空白,*,*,*,*, , ,
* 1 2D 0/1 -0.764522
吾輩 名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
* 2 -1D 0/2 0.000000
猫 名詞,一般,*,*,*,*,猫,ネコ,ネコ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
ある 助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル
。 記号,句点,*,*,*,*,。,。,。
EOS
* 文節番号 係り先文節番号Dのような行が追加されていますね。
クラス
そもそもオブジェクト指向プログラミングとは...というところまで踏み込むと論争に発展するのであくまでPythonのクラスに絞って解説をしようかと、思います。Javaを多少知ってれば楽だと思います。
なぜクラスを使うのか
この章の問題で言うと、文->文節->形態素という階層構造をクラス使わずして扱おうとすると、(文|文節|形態素)用の(変数|関数)が入り乱れて大変なことになります。for文もややこしいことになりそうです。クラスを使えば関数を引数の種類でグルーピングできますし、変数スコープを縮小できるのでコーディングが多少楽になります。
諸々の用語説明
日付を表すデータ型、datetime.dateの例を見てみましょう。
import datetime
# インスタンス化
a_day = datetime.date(2022,2,22)
print(a_day)
print(type(a_day))
# インスタンス変数
print(a_day.year, a_day.month, a_day.day)
# クラス変数
print(datetime.date.max, a_day.max)
# インスタンスメソッド
print(a_day.weekday(), datetime.date.weekday(a_day))
# クラスメソッド
print(datetime.date.today())
2022-02-22
<class 'datetime.date'>
2022 2 22
9999-12-31 9999-12-31
1 1
2020-05-06
datetime.date()でdatetime.date型の実体(インスタンス)が生成され、引数に渡された年月日に基づき値が設定(初期化)されます。
インスタンスa_dayは年・月・日を表すインスタンス固有の値(属性)を持っており、これをインスタンス変数と呼びます。一方、datetime.date型の全てのインスタンス間で共通の値をクラス変数と呼びます。この例では日付の取り得る最大値がクラス変数になっています。そしてインスタンスを必要とする関数をインスタンスメソッド、そうでない関数をクラスメソッドと呼びます。
なお、インスタンスメソッドについてはa_day.weekday()とdatetime.date.weekday(a_day)が等価であることに気を付けましょう。さらに言うとPythonは前者を後者に勝手に変換して実行していると思ってください。ちなみに、戻り値は0が月曜、1が火曜、という意味になっています。
クラス定義
データ型の設計図がクラスです。実際にクラスを定義しましょう。やっぱり某モンスターを模したクラスがわかりやすいですかね...。
class Nezumi:
# クラス変数
types = ('でんき',)
learnable_moves = {'でんこうせっか', 'かみなり', 'でんじは'}
base_hp = 35
# 初期化メソッド
def __init__(self, name, level):
# インスタンス変数
self.name = name
self.level = level
self.learned_moves = []
# インスタンスメソッド
def learn(self, move):
if move in self.learnable_moves:
self.learned_moves.append((move))
print(f'{self.name}は 新しく {move}を 覚えた!')
# クラスメソッド
@classmethod
def hatch(cls):
nezumi = cls('ネズミ', 1)
nezumi.learned_moves.append('でんこうせっか')
print('タマゴが かえって ネズミが うまれた!')
return nezumi
# インスタンス化
reo = Nezumi('レオ', 44)
# メンバ変数確認
print(reo.name, reo.level, reo.learned_moves, reo.types)
# インスタンスメソッド呼び出し
reo.learn('かみなり')
レオ 44 [] でんき
レオは 新しく かみなりを 覚えた!
# クラスメソッド呼び出し
nezu = Nezumi.hatch()
# インスタンス変数確認
print(nezu.name, nezu.level, nezu.learned_moves)
タマゴが かえって ネズミが うまれた!
ネズミ 1 ['でんこうせっか']
__init__()はインスタンス変数を初期化するメソッドです。初期化メソッドとかイニシャライザと呼ばれています。第1引数selfはインスタンスを表します。そしてメソッド内でself.変数名の形で定義されたものがインスタンス変数になります。
定義したNezumiクラスをNezumi()と呼び出すことで内部ではインスタンス化(new)の後、生成されたインスタンスselfに対して__init__()が実行されます。
インスタンスメソッドの第1引数selfにはインスタンスreoが代入されます。reo.learn('かみなり')のように呼び出すとNezumi.learn(reo, 'かみなり')が実行されます。だからこのselfが必要なのです。
クラスメソッドは@classmethodというデコレータを付けて定義します。クラスメソッドでは特殊な初期化方法を記述するのがオーソドックスです。第1引数clsにはクラスオブジェクトNezumiが代入されます。したがってcls('ネズミ', 1)はNezumi('ネズミ', 1)と同じことになります。
ちなみに、上の例ではインスタンス変数を1つ1つアクセスして確認していますが、組み込み関数vars()を使えばdict形式で一覧が返ってきます。
特殊メソッド
特殊な操作・演算が行われた時に勝手に呼び出されるメソッドを特殊メソッドと言います。__init__()もその一種です。特殊メソッドはたくさんあるのであまり深追いしませんが、次のようなものがあります。
-
__str__():print()などに渡した時の表示文字列を定義する -
__repr__(): デバッグ用の表示文字列を定義する。対話モードで評価させるかrepr()に渡すと見える。 -
__len__():len()に渡した時の戻り値を定義する。
プライベートメンバ
Pythonにそんな機能はありません。_spamのようにアンダースコア1個を前につけて命名するのが慣習です。
継承
継承自体の説明はそれほど長く無いですし、深層学習のコードに登場することもあったりするのですが、この章では不要ですし、付随する話(用途、super()、名前空間、staticmethodなど)が多いので、省略します。せっかく継承の説明がしやすそうな例を持ってきたのにアレですが。
データクラス
Python3.7でデータ保持用のクラスを簡単に定義するためのモジュール、dataclassesが追加されました。__init__()や__repr__()などを勝手に定義してくれます。今回の問題でも使えそうな気はしますが、型アノテーションなどそれなりに覚えることがあるので省略します。
40. 係り受け解析結果の読み込み(形態素)
形態素を表すクラス
Morphを実装せよ.このクラスは表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をメンバ変数に持つこととする.さらに,CaboChaの解析結果(neko.txt.cabocha)を読み込み,各文をMorphオブジェクトのリストとして表現し,3文目の形態素列を表示せよ.
以下、解答例です。
import argparse
from itertools import groupby
import sys
class Morph:
"""cabocha lattice formatファイルの1行を読み込む"""
__slots__ = ('surface', 'pos', 'pos1', 'base')
# 吾輩 名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ
def __init__(self, line):
self.surface, temp = line.rstrip().split('\t')
info = temp.split(',')
self.pos = info[0]
self.pos1 = info[1]
self.base = info[6]
@classmethod
def load_cabocha(cls, fi):
"""cabocha lattice formatファイルからMorphインスタンスを生成"""
for is_eos, sentence in groupby(fi, key=lambda x: x == 'EOS\n'):
if not is_eos:
yield [cls(line) for line in sentence if not line.startswith('* ')]
def __str__(self):
return self.surface
def __repr__(self):
return 'q40.Morph({})'.format(', '.join((self.surface, self.pos, self.pos1, self.base)))
def main():
sent_idx = arg_int()
for i, sent_lis in enumerate(Morph.load_cabocha(sys.stdin), start=1):
if i == sent_idx:
# print(*sent_lis)
print(repr(sent_lis))
break
def arg_int():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--number', default='1', type=int)
args = parser.parse_args()
return args.number
if __name__ == '__main__':
main()
!python q40.py -n2 < neko.txt.cabocha
[q40.Morph( , 記号, 空白, ), q40.Morph(吾輩, 名詞, 代名詞, 吾輩), q40.Morph(は, 助詞, 係助詞, は), q40.Morph(猫, 名詞, 一般, 猫), q40.Morph(で, 助動詞, *, だ), q40.Morph(ある, 助動詞, *, ある), q40.Morph(。, 記号, 句点, 。)]
__slots__という特殊クラス変数にインスタンス変数名を渡しておくと、メモリが節約でき、また属性探索が高速になります。その代わり外から新たなインスタンス変数を追加できなくなったり、vars()でインスタンス変数一覧を取得できなくなったりします。
設計としては、形態素情報の行を渡さないとインスタンス化できないようになっています。その辺は好みですかね。
関数定義などの最初に文字列リテラルで説明を書いておくと、docstringとして扱われます。文字列リテラルはクォート3つにすると改行できるようになります。docstringはhelp()関数やJupyter上やエディタ上で参照できます。またdoctestやpydocというモジュールと併用することがあります。
EOSで文末が表現されているファイルに対してはgroupby()を使うとエレガントに書けます。一方でこの章の問題では空行が理由でEOS\nEOSのような箇所があるため、問題文における文の数え方とgroupby()による文の数え方が異なることに注意しましょう。
41. 係り受け解析結果の読み込み(文節・係り受け)と、以降の問題の解答例
40に加えて,文節を表すクラスChunkを実装せよ.このクラスは形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つこととする.さらに,入力テキストのCaboChaの解析結果を読み込み,1文をChunkオブジェクトのリストとして表現し,8文目の文節の文字列と係り先を表示せよ.第5章の残りの問題では,ここで作ったプログラムを活用せよ.
オブジェクト指向の精神を踏まえると、文->文節->形態素というhas-a関係になっているのでSentenceクラスを作るのが良いと思います。確かに作ってもインスタンス変数はself.chunksだけで、変数の管理という観点ではあまり変わり無いので必須ではありません。
しかし、srcsは1文の解析結果を最後まで読まないとセットできないのでSentenceオブジェクトの初期化時にやらせるのは自然に思えますし、文章レベルの処理(Cabochaファイル読み込み、n文目の解析結果の読み込み、nをコマンドライン引数で受け取る)と文レベルの処理(以降の問題、特に43以降で問われていること)を分離できるのはメリットだと思います。
以下、解答例ですが、以降の問題の解答を含んでいます。docstringに記述しているので、41番と無関係なコードは読み飛ばし、あとで適宜参考にしてください。
from collections import defaultdict
from itertools import groupby, combinations
import sys
from q40 import Morph, arg_int
class Chunk:
"""cabocha lattice formatファイルから文節を読み込む"""
__slots__ = ('idx', 'dst', 'morphs', 'srcs')
# * 0 2D 0/0 -0.764522
def __init__(self, line):
info = line.rstrip().split()
self.idx = int(info[1])
self.dst = int(info[2].rstrip("D"))
self.morphs = []
self.srcs = []
def __str__(self):
return ''.join([morph.surface for morph in self.morphs])
def __repr__(self):
return 'q41.Chunk({}, {})'.format(self.idx, self.dst)
def srcs_append(self, src_idx):
"""係り元文節インデックスを追加する。Sentence.__init__()で使う。"""
self.srcs.append(src_idx)
def morphs_append(self, line):
"""形態素を追加する。Sentence.__init__()で使う。"""
self.morphs.append(Morph(line))
def tostr(self):
"""記号を取り除いた文節の表層形を返す。q42以降で使う。"""
return ''.join([morph.surface for morph in self.morphs if morph.pos != '記号'])
def contain_pos(self, pos):
"""文節中にある品詞が存在するかどうかを返す。q43以降で使う。"""
return pos in (morph.pos for morph in self.morphs)
def replace_np(self, symbol):
"""文節中の名詞句をsymbolに置換する。q49用。"""
morph_lis = []
for pos, morphs in groupby(self.morphs, key=lambda x: x.pos):
if pos == '名詞':
for morph in morphs:
morph_lis.append(symbol)
break
elif pos != '記号':
for morph in morphs:
morph_lis.append(morph.surface)
return ''.join(morph_lis)
class Sentence:
"""cabocha lattice formatファイルから文を読み込む。"""
__slots__ = ('chunks', 'idx')
def __init__(self, sent_lines):
self.chunks = []
for line in sent_lines:
if line.startswith('* '):
self.chunks.append(Chunk(line))
else:
self.chunks[-1].morphs_append(line)
for chunk in self.chunks:
if chunk.dst != -1:
self.chunks[chunk.dst].srcs_append(chunk.idx)
def __str__(self):
return ' '.join([morph.surface for chunk in self.chunks for morph in chunk.morphs])
@classmethod
def load_cabocha(cls, fi):
"""cabocha lattice formatファイルからSentenceインスタンスを生成"""
for is_eos, sentence in groupby(fi, key=lambda x: x == 'EOS\n'):
if not is_eos:
yield cls(sentence)
def print_dep_idx(self):
"""q41. 係り元文節インデックスと係り先文節インデックスを表示"""
for chunk in self.chunks:
print('{}:{} => {}'.format(chunk.idx, chunk, chunk.dst))
def print_dep(self):
"""q42. 係り元文節と係り先文節の表層をタブ区切りで表示"""
for chunk in self.chunks:
if chunk.dst != -1:
print('{}\t{}'.format(chunk.tostr(), self.chunks[chunk.dst].tostr()))
def print_noun_verb_dep(self):
"""q43. 名詞を含む文節が動詞を含む文節に係るものを抽出"""
for chunk in self.chunks:
if chunk.contain_pos('名詞') and self.chunks[chunk.dst].contain_pos('動詞'):
print('{}\t{}'.format(chunk.tostr(), self.chunks[chunk.dst].tostr()))
def dep_edge(self):
"""q44でpydotに係り受けを出力させる用"""
return [(f"{i}: {chunk.tostr()}", f"{chunk.dst}: {self.chunks[chunk.dst].tostr()}")
for i, chunk in enumerate(self.chunks) if chunk.dst != -1]
def case_pattern(self):
"""q45. 動詞の格パターン抽出"""
for chunk in self.chunks:
for morph in chunk.morphs:
if morph.pos == '動詞':
verb = morph.base
particles = [] # 助詞のリスト
for src in chunk.srcs:
# 分節内で一番右の助詞を追加していく
particles.extend([word.base for word in self.chunks[src].morphs
if word.pos == '助詞'][-1:])
particles.sort()
print('{}\t{}'.format(verb, ' '.join(particles)))
# 一番左の動詞しか使わないのでさっさと抜ける
break
def pred_case_arg(self):
"""q46. 動詞の格フレーム情報抽出"""
for chunk in self.chunks:
for morph in chunk.morphs:
if morph.pos == '動詞':
verb = morph.base
particle_chunks = []
for src in chunk.srcs:
# (助詞, 係り元の分節の表層)
particle_chunks.extend([(word.base, self.chunks[src].tostr())
for word in self.chunks[src].morphs if word.pos == '助詞'][-1:])
if particle_chunks:
particle_chunks.sort()
particles, chunks = zip(*particle_chunks)
else:
particles, chunks = [], []
print('{}\t{}\t{}'.format(verb, ' '.join(particles), ' '.join(chunks)))
break
def sahen_case_arg(self):
"""q47. 機能動詞構文のマイニング"""
# サ変名詞+動詞を抽出するためのフラグ
sahen_flag = 0
for chunk in self.chunks:
for morph in chunk.morphs:
if sahen_flag == 0 and morph.pos1 == 'サ変接続':
sahen_flag = 1
sahen = morph.surface
elif sahen_flag == 1 and morph.base == 'を' and morph.pos == '助詞':
sahen_flag = 2
elif sahen_flag == 2 and morph.pos == '動詞':
sahen_wo = sahen + 'を'
verb = morph.base
particle_chunks = []
for src in chunk.srcs:
# (助詞, 係り元の分節の表層)
particle_chunks.extend([(word.base, self.chunks[src].tostr()) for word in self.chunks[src].morphs
if word.pos == '助詞'][-1:])
for j, part_chunk in enumerate(particle_chunks[:]):
if sahen_wo in part_chunk[1]:
del particle_chunks[j]
if particle_chunks:
particle_chunks.sort()
particles, chunks = zip(*particle_chunks)
else:
particles, chunks = [], []
print('{}\t{}\t{}'.format(sahen_wo + verb, ' '.join(particles), ' '.join(chunks)))
sahen_flag = 0
break
else:
sahen_flag = 0
def trace_dep_path(self):
"""q48. 名詞を含む文節からrootまでの係り受けパスを追跡"""
path = []
for chunk in self.chunks:
if chunk.contain_pos('名詞'):
path.append(chunk)
d = chunk.dst
while d != -1:
path.append(self.chunks[d])
d = self.chunks[d].dst
yield path
path = []
def print_noun2noun_path(self):
"""q49. 名詞間の係り受けパスの抽出"""
# 名詞を含む文節からrootへのパスを表したChunkのリストのリスト(1文)
all_paths = list(self.trace_dep_path())
arrow = ' -> '
# 各パスの文節idの集合のリスト
all_paths_set = [{chunk.idx for chunk in chunks} for chunks in all_paths]
# all_pathsからペアを選ぶ
for p1, p2 in combinations(range(len(all_paths)), 2):
# 共通の文節kを探す
intersec = all_paths_set[p1] & all_paths_set[p2]
len_intersec = len(intersec)
len_smaller = min(len(all_paths_set[p1]), len(all_paths_set[p2]))
# 共通部分は空でなく、かつどちらかが部分集合になっていない
if 0 < len_intersec < len_smaller:
# パスを表示
k = min(intersec)
path1_lis = []
path1_lis.append(all_paths[p1][0].replace_np('X'))
for chunk in all_paths[p1][1:]:
if chunk.idx < k:
path1_lis.append(chunk.tostr())
else:
break
path2_lis = []
rest_lis = []
path2_lis.append(all_paths[p2][0].replace_np('Y'))
for chunk in all_paths[p2][1:]:
if chunk.idx < k:
path2_lis.append(chunk.tostr())
else:
rest_lis.append(chunk.tostr())
print(' | '.join([arrow.join(path1_lis), arrow.join(path2_lis),
arrow.join(rest_lis)]))
# 名詞から名詞に係っているパターンを探して表示
for chunks in all_paths:
for j in range(1, len(chunks)):
if chunks[j].contain_pos('名詞'):
outstr = []
outstr.append(chunks[0].replace_np('X'))
outstr.extend(chunk.tostr() for chunk in chunks[1:j])
outstr.append(chunks[j].replace_np('Y'))
print(arrow.join(outstr))
def main():
sent_id = arg_int()
for i, sent in enumerate(Sentence.load_cabocha(sys.stdin), start=1):
if i == sent_id:
sent.print_dep_idx()
break
if __name__ == '__main__':
main()
!python q41.py -n8 < neko.txt.cabocha
0:この => 1
1:書生というのは => 7
2:時々 => 4
3:我々を => 4
4:捕えて => 5
5:煮て => 6
6:食うという => 7
7:話である。 => -1
この章の狙いはクラス定義の習得なので、以降の問題の解説は飛ばし気味にさせていただきます。
特殊メソッドの補足
少し発展的な話なので読み飛ばしていただいて大丈夫です。
Sentenceクラスのコードで気になるのはfor chunk in self.chunksやself.chunks[i]というような記述が頻発しているところです。次のような特殊メソッドを定義しておけばfor chunk in selfやself[i]で済みます。
def __iter__(self):
return iter(self.chunks)
def __getitem__(self, key):
return self.chunks[key]
実はリストをfor文で回す際、内部ではiter()関数でイテレータに変換されていたのです。そしてiter()関数はオブジェクトの__iter()__メソッドを呼び出しています。そのためこのように書けばSentenceのインスタンス自体をfor文で回せるようになります。
__getitem__()を定義するとインデックスアクセスができるようになります。
※ うるさいことを言うと__getitem__()だけ定義してもfor文は動きます
さらにChunkクラスも同様に定義しておけばインスタンスに対して次のようなfor文を回すことができます。
for chunk in sentence:
for morph in chunk:
おそらく世の中の係り受け解析器のPythonラッパもこのようなつくりになっていると思います。またq41, 42用のメソッドはChunkクラスに定義し、外側で上のようなfor文を書いてその中で呼び出す、という作りの方がより自然だと思います。
42, 43は特に言うことが無いので省略。
44. 係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.可視化には,係り受け木をDOT言語に変換し,Graphvizを用いるとよい.また,Pythonから有向グラフを直接的に可視化するには,pydotを使うとよい.
Graphvizとpydotを頑張ってインストールします。pydotは長らくメンテされていないのでpydot-ngを使うと良い、と言っている人が多いですが、私の環境ではpydotで動作したのでpydotを使ってます。pydotは私も100本ノックでしか使ったことが無いので特に解説しません。実装にあたってはこちらのブログを参考にしました。
import sys
from q40 import arg_int
from q41 import Sentence
import pydot
def main():
sent_id = arg_int()
for i, sent in enumerate(Sentence.load_cabocha(sys.stdin), start=1):
if i == sent_id:
edges = sent.dep_edge()
n = pydot.Node('node')
n.fontname="MS P ゴシック"
n.fontsize = 9
graph = pydot.graph_from_edges(edges, directed=True)
graph.add_node(n)
graph.write_jpeg(f"dep_tree_neko{i}.jpg")
break
if __name__ == "__main__":
main()
!python q44.py -n8 < neko.txt.cabocha
from IPython.display import Image
Image("dep_tree_neko8.jpg")
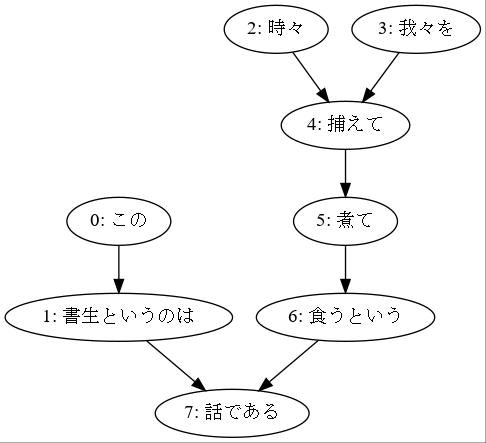
係り受けの矢印の方向はこのようにする流儀と逆向きにする流儀(特にUniversal Dependenciesに基づく場合)がありますが、この問題ではどちらでも大丈夫だと思います。
(graph_from_edges()の仕様の都合で文の中に表層が同じ(でidが異なる)文節が複数あると同一ノードとみなされてしまいます。それを回避するためにはgraph_from_edges()の実装を変更するか表層系にidを付加するかという処理が必要です。)
(フォントがMS P ゴシックなのは自分の環境がWSLのUbuntuで、日本語フォントが見当たらなかったのでWindowsのフォントを参照させるという技を使ったからです)
45. 動詞の格パターンの抽出
今回用いている文章をコーパスと見なし,日本語の述語が取りうる格を調査したい. 動詞を述語,動詞に係っている文節の助詞を格と考え,述語と格をタブ区切り形式で出力せよ. ただし,出力は以下の仕様を満たすようにせよ.
- 動詞を含む文節において,最左の動詞の基本形を述語とする
- 述語に係る助詞を格とする
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
「吾輩はここで始めて人間というものを見た」という例文(neko.txt.cabochaの8文目)を考える. この文は「始める」と「見る」の2つの動詞を含み,「始める」に係る文節は「ここで」,「見る」に係る文節は「吾輩は」と「ものを」と解析された場合は,次のような出力になるはずである.
見る は を``` このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ. - コーパス中で頻出する述語と格パターンの組み合わせ - 「する」「見る」「与える」という動詞の格パターン(コーパス中で出現頻度の高い順に並べよ)
格を調査したいなら格助詞に絞るべきですが、泣く泣く問題文に従います。助詞を辞書順に並べろとのことです。
述語の係元に助詞が無い事例を出力するかどうかが問題文に書かれて無いですが、それは格の省略が起こっている事例なので集計することにしました。
Pythonのsorted()、list.sorted()は文字列もソートできますが、コードポイントに基づく辞書式順序であって、国語辞書などで用いられる五十音順とは異なることは知っておきましょう。
>>> sorted(['かがく', 'かかし'])
['かかし', 'かがく']
上の解答例ではextend()を使っています。リストを連結するメソッドで、結果は+と同じです。リスト.append(要素)とリスト.extend(リスト)を混同しないよう気をつけましょう。
!python q45.py < neko.txt.cabocha | head
生れる で
つく か が
する
泣く で
する て は
始める で
見る は を
聞く で
捕える を
煮る て
!python q45.py < neko.txt.cabocha | sort | uniq -c | sort -rn | head -20
704 云う と
452 する を
435 する
333 思う と
202 ある が
199 なる に
188 する に
175 見る て
159 する と
122 云う
117 する が
113 する に を
108 なる
98 見る を
97 見える と
94 ある
90 する て を
89 いる
85 する は
80 見る
!python q45.py < neko.txt.cabocha | grep -E "^(する|見る|与える)\s" | sort | uniq -c | sort -nr | head -20
452 する を
435 する
188 する に
175 見る て
159 する と
117 する が
113 する に を
98 見る を
90 する て を
85 する は
80 見る
61 する て
60 する も
60 する が を
51 する と を
51 する から
46 する で を
40 する の
39 する と は
37 する は を
真理値判定
46番の解答例でif list:のような記述を使っているので真理値判定について説明しておきます。if文には条件式以外にもあらゆるオブジェクトを書くことができ、その場合の真理値判定はどうなるのかという話ですが、ドキュメントにまとまっているので参照してください。要するにNone、ゼロっぽいもの、len(x)==0になるxは全てFalse扱い、それ以外はTrue扱いされるということです。これを知っていると「リストが空でないとき」みたいな処理が簡単に書けます。自信が無いときは組み込み関数bool()をいろいろなオブジェクトに適用してみると良いです。
それ以外に特に言うことは無いので、46は省略します。
47. 機能動詞構文のマイニング
動詞のヲ格にサ変接続名詞が入っている場合のみに着目したい.46のプログラムを以下の仕様を満たすように改変せよ.
- 「サ変接続名詞+を(助詞)」で構成される文節が動詞に係る場合のみを対象とする
- 述語は「サ変接続名詞+を+動詞の基本形」とし,文節中に複数の動詞があるときは,最左の動詞を用いる
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
- 述語に係る文節が複数ある場合は,すべての項をスペース区切りで並べる(助詞の並び順と揃えよ)
例えば「別段くるにも及ばんさと、主人は手紙に返事をする。」という文から,以下の出力が得られるはずである.
返事をする と に は 及ばんさと 手紙に 主人はこのプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語(サ変接続名詞+を+動詞)
- コーパス中で頻出する述語と助詞パターン
サ変接続名詞とは「返事」のように後ろに「する」をつけてサ変動詞を作ることができる名詞を指します。ちなみに、学校文法においては「返事する」で1単語ですが、形態素解析においては「返事/する」のように分割するのが普通です。
なお、解答例がひどいゴリ押しコードなのはお許しいただきたい…
!python q47.py < neko.txt.cabocha | cut -f1 | sort | uniq -c | sort -nr | head
30 返事をする
21 挨拶をする
14 真似をする
13 話をする
13 喧嘩をする
6 昼寝をする
5 運動をする
5 質問をする
5 質問をかける
5 話を聞く
!python q47.py < neko.txt.cabocha | cut -f 1,2 | sort | uniq -c | sort -nr | head
8 真似をする
6 返事をする と
6 喧嘩をする
4 運動をする
4 返事をする と は
4 返事をする
4 話を聞く
4 挨拶をする と
4 挨拶をする から
3 質問をかける と は
48. 名詞から根へのパスの抽出
文中のすべての名詞を含む文節に対し,その文節から構文木の根に至るパスを抽出せよ. ただし,構文木上のパスは以下の仕様を満たすものとする.
- 各文節は(表層形の)形態素列で表現する
- パスの開始文節から終了文節に至るまで,各文節の表現を
"->"で連結する「吾輩はここで始めて人間というものを見た」という文(neko.txt.cabochaの8文目)から,次のような出力が得られるはずである.
吾輩は -> 見た ここで -> 始めて -> 人間という -> ものを -> 見た 人間という -> ものを -> 見た ものを -> 見た
whileまたは再帰でひたすら係り先を辿れば良いです。次の問題を意識して、出力の一歩前までの処理のみをメソッド化しました。
import sys
from q40 import arg_int
from q41 import Sentence
def main():
sent_id = arg_int()
for i, sent in enumerate(Sentence.load_cabocha(sys.stdin), start=1):
if i == sent_id:
for chunks in sent.trace_dep_path():
print(' -> '.join([chunk.tostr() for chunk in chunks]))
break
if __name__ == '__main__':
main()
!python q48.py -n6 < neko.txt.cabocha
吾輩は -> 見た
ここで -> 始めて -> 人間という -> ものを -> 見た
人間という -> ものを -> 見た
ものを -> 見た
(2020/5/18追記)
コメントを頂きまして、問題文の係り受け解析例が解析ミスであることに気づきました。issueにて、利用する例文を修正する予定とのことです。
100本ノック5章はクラス定義の練習が主目的で、CaboChaを指定しているのは単に利用しやすいのが理由かなと思います。一方で、問題文を工夫して係り受け解析器に幅をもたせることも検討するとのことです。最近はGiNZAも十分使いやすいですしね。
49. 名詞間の係り受けパスの抽出
文中のすべての名詞句のペアを結ぶ最短係り受けパスを抽出せよ.ただし,名詞句ペアの文節番号がi
とj(i<j)のとき,係り受けパスは以下の仕様を満たすものとする.
- 問題48と同様に,パスは開始文節から終了文節に至るまでの各文節の表現(表層形の形態素列)を"->"で連結して表現する
- 文節iとjに含まれる名詞句はそれぞれ,XとYに置換する
また,係り受けパスの形状は,以下の2通りが考えられる.
- 文節iから構文木の根に至る経路上に文節jが存在する場合: 文節iから文節jのパスを表示
- 上記以外で,文節iと文節jから構文木の根に至る経路上で共通の文節kで交わる場合: 文節iから文節kに至る直前のパスと文節jから文節kに至る直前までのパ>ス,文節kの内容を"|"で連結して表示
例えば,「吾輩はここで始めて人間というものを見た。」という文(neko.txt.cabochaの8文目)から,次のような出力が得られるはずである.
Xは | Yで -> 始めて -> 人間という -> ものを | 見た Xは | Yという -> ものを | 見た Xは | Yを | 見た Xで -> 始めて -> Y Xで -> 始めて -> 人間という -> Y Xという -> Y
さて、100本ノック2020年版で最も難しい問題がこれです。まず問題文が非常にわかりにくい。そして意味がわかってもなお大変です。とりあえず問題文の意味だけでも理解しましょう。
要するに問題48の出力をこんな感じに変換しなさい、という問題です。
ただし「文節iから構文木の根に至る経路上に文節jが存在する場合: 文節iから文節jのパスを表示」に対応しているのは出力例の下3つという罠があります。幸いなことにこの部分の実装は簡単そうです。問題48のパスは名詞句スタートなので、4つ全てのパスの最初の文節がiの候補になります。あとはそこからjを探していくだけです。そして最後にiとjの名詞句をXとYに置換します(Xという -> YではなくXという -> Yをになると思うんですがゴゴゴゴゴゴゴ)。
大変そうなのが「上記以外で~」の部分です。これは「吾輩は -> 見た」と「人間という -> ものを -> 見た」のようなパスがあったら結合して「吾輩は | 人間という -> ものを | 見た」として、さらに文節i, jの名詞句を置換して「Xは | Yという -> ものを | 見た」にしなさい、ということです。
問題48のパスが4つあるので、そこから2つのパスを選び、4C2回のループを回す必要があります。itertools.combinations()を知らないと辛いです。そして「人間という -> ものを -> 見た」と「ものを -> 見た」のように部分集合の関係になっているペアは無視しないとマズいことになります。この処理が悩ましいです。また文節i, jは2つのパスの最初の文節が候補になりますが、そこから共通の文節kを探す処理、そしてそれが見つかった後に出力文字列をつくる処理が面倒です。自然言語処理の入門でもPythonの入門でも無いので無理に取り組む必要は無いと思います。
まとめ
- クラス
- docstring
- リストの連結
- 真理値判定
おわりに
これにて言語処理100本ノックでPythonに入門シリーズ、完結?