シャーディング
データベースにおける分割手法の1つで、データを複数のノードのディスクに分割配置することで、データベースへのリクエストを分散し全体のスループットを上げる目的で利用されます。
基本的にはお互いのノードではシェアードナッシングの独立したデータを持っているので、各ノードは自分の担当するデータに対してクエリを実行します。
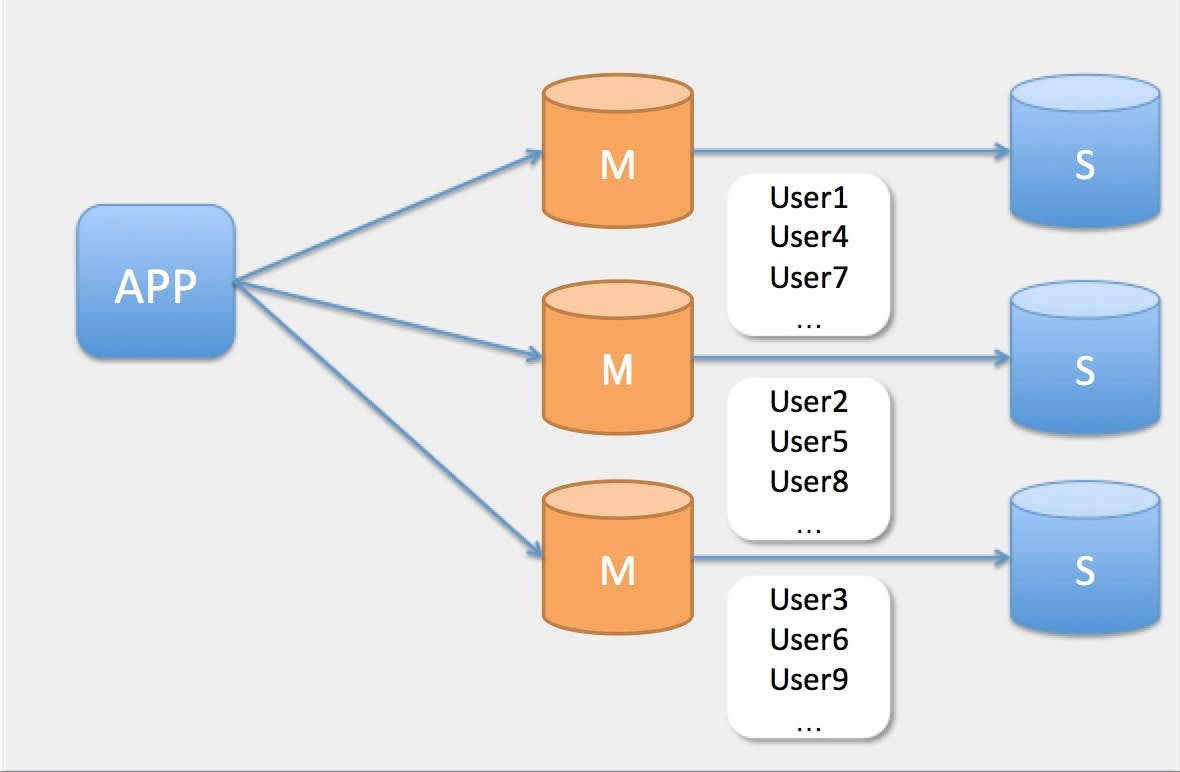
具体的には、アプリケーションからの書き込みのリクエストが支配的で、Primary/Backupのような処理系統によるルーティングではあまり負荷の分散に繋がらないようなケースで利用されます。
e.g)
- スケールしたアプリケーションサーバからの同時接続数の限界
- 巨大なデータを扱う際にbufferが溢れDisk/IOが発生する
(appendix) Primary/Backup (Master/Slave)

アプリケーションの処理の系統によって接続先のデータベースノードを切り替えるという分割方式です。
アプリケーションからの更新をLeaderノードが受けて、読み出し専用のFollowerノードにレプリケーションするという場合に、
更新系統はLeaderへ、参照系統はFollowerにリクエストを振り分けることでバランシングを行います。
多くのアプリケーションライブラリでは環境変数に接続先を追記することで利用できるので、読み出しの処理が割合を占めるようなWEBアプリケーションではこの方式を採用することがあります。
しかしながらLeaderノードは変わらず一つなので、更新のリクエストが割合を占める場合にはこの方法でリクエストは分散されないかもしれません。
分割単位の決定
実際のデータを分割配置するにあたって、どのような区分でデータを分割するか、とそのID(シャードキー)を決定します。
基準の一つとして、1ユーザリクエストで取得するデータが特定のノード内を走査することで完結するような分割単位にすることです。シャーディング後も各ノードに並列で問い合わせるようなデータの分け方をしている場合は全体としてのスループットの向上は見込めないかもしれません。
これはデータを配置するノードの割り出しでも関係することですが、特定のノードに多くのデータが偏らないような分割単位にすることもポイントです。このようなノードは他に比べて多くのリクエストが集中する危険性(ホットスポット)が生じます。
WEBアプリケーションであればユーザのIDが最大公約数になるかもしれませんし、時系列に並んだ帳票であればタイムスタンプが分割単位になるかもしれませんが、これはアプリケーションの性質によって変わってくるので適宜判断する必要があります。
保存先ノードの特定
データの分割単位とシャードキーが決定したらデータを配置するノードの割り出しを行います。
ノード数分の剰余で決定する場合や指定範囲にシャードキーが含まれるかで決定する場合などその方法も様々ですが、いずれもメリット・デメリットがあります。
range
特定の境界を軸に配置ノードを分ける手法です。
例えば個人向けのWEBサービスを想定すると、会員登録順にシーケンシャルなユーザのIDをシャードキーに、0〜19999はnodeAに、20000~29999はnodeBにという具合に定点を境目に配置先のノードを割り当てます。
この手法はシャードキーから担当ノードを簡単に判断することが出来ますが、アクセスパターンによっては簡単にホットスポットが生じます。
先の例を出すと、時系列上に並んだユーザが等しくアクセスされるとは限らず、休眠会員や施策によるアクティビティによっては特定の範囲のノードに負荷が集中するかもしれません。
modulo
シャードキーをノード数で割った剰余で配置ノードを割り出す手法です。
key mod shard_num (+1)
或いは
hash(key) mod shard_num (+1)
import hashlib
from collections import defaultdict
def find_node(key, node_ids):
"""
:type key: int
:type node_ids: list of int
:rtype: int
"""
return int(hashlib.md5(str(key)).hexdigest(), 16) % len(node_ids)
node_ids = range(0, 10)
keys = [chr(i) for i in range(ord('a'), ord('z') + 1)] # a..z
node_hash = defaultdict(list)
for key in keys:
node_id = find_node(key, node_ids)
node_hash[index].append(key)
除数の範囲でノードが割り振られるので、こちらも簡単且つ一定量の分散配置は期待できるるという一方で
ノード数そのものが変化すると、ノード全体でデータの移動が発生するという課題があります。
この課題をカバーする工夫として、シャードキーから直接ノードを引き当てるのではなく、間に設定した仮想ノードを経由してデータを配置するノードを決定するという方法が考えられます。
cookpadさんが公開しているmixed_gauge1では、一度引き当てた剰余が仮想ノードの範囲に含まれるかで実際のノードを決定しています。
ConsistentHash(HashRange)
あるいは、ハッシュ化したたシャードキーを同じくハッシュ化したノードのIDと照らし合わせて配置を決めるという方法もあります。
この場合はノードの追加や削除が発生した場合にデータの移動が必要最低限で済みます。
import hashlib
def find_node(node_tuples, key):
"""
:type node_tuple: list of tuple
:type key: int or str
:rtype: int or str
"""
node_cnt = len(node_tuples)
hashed_key = hashlib.md5(str(key)).hexdigest()
for i in range(1, node_cnt + 1):
if node_tuples[i-1][0] <= hashed_key and hashed_key < node_tuples[i][0]:
return node_tuples[i][1]
return node_tuples[0][1]
from collections import defaultdict
node_ids = range(0, 10)
# list of tuple (hash_slot, node_id)
node_tuples = sorted([(
hashlib.md5(str(node_id)).hexdigest(), node_id)
for node_id in node_ids],
key=lambda n: n[0]
)
node_hash = defaultdict(list)
keys = [chr(i) for i in range(ord('a'), ord('z'))]
for key in keys:
node_id = find_node(node_tuples, key)
node_hash[node_id].append(key)
2019/11/04
- 誤植部分を修正
- R/W Splitting -> Primary/Backup
- その他用語の統一
2019/12/10
- 項目を分割
- modulo以外の分割方式を追加