概要
これまでBigQueryおよびSnowflakeが利用可能でしたが、それ以外のデータベース製品はサポートされていませんでした。今回、新たにカスタムデータベース連携機能が追加され、S3バケット上のCSVファイルを用いることで、多様なデータベースと連携できるようになりました。
例えば、以下のデータベースをメタデータ管理することが可能です。
- MySQL
- PostgreSQL
- Amazon Redshift
- Amazon Athena
- Databricks
- Oracle Database
- Microsoft SQL Server
- Treasure Data
本記事では、TROCCOを用いてMySQLからメタデータを取得し、COMETA上にデータストアを構築する方法を説明します。多くのデータベースではINFORMATION_SCHEMAにメタデータが管理されており、このデータをTROCCOを使ってS3に吐き出し、さらにそのメタデータを基にデータストアを構築します。
下準備
MySQLサーバのサンドボックス環境として、test_dbを使用します。
テーブルやカラムのコメントもデータストアに連携されるため、以下のように事前にコメントを付与しておきます。
テーブル
ALTER TABLE employees
COMMENT = '従業員の基本情報(従業員番号、氏名、生年月日、性別、入社日など)を格納します。';
ALTER TABLE departments
COMMENT = '部署の情報(部署番号、部署名)を格納します。';
ALTER TABLE salaries
COMMENT = '各従業員の給与履歴(給与額、適用開始日、終了日)を格納します。';
ALTER TABLE titles
COMMENT = '従業員の役職履歴(役職名、適用開始日、終了日)を格納します。';
ALTER TABLE dept_emp
COMMENT = '従業員と部署の関連(どの従業員がどの部署に所属しているか)を示します。';
ALTER TABLE dept_manager
COMMENT = '各部署のマネージャー情報(どの従業員がどの期間、どの部署のマネージャーであったか)を格納します。';
カラム
ALTER TABLE employees
MODIFY COLUMN emp_no INT NOT NULL COMMENT '従業員番号(Primary Key)';
ALTER TABLE employees
MODIFY COLUMN birth_date DATE NOT NULL COMMENT '従業員の生年月日';
ALTER TABLE employees
MODIFY COLUMN first_name VARCHAR(14) NOT NULL COMMENT '従業員の名';
ALTER TABLE employees
MODIFY COLUMN last_name VARCHAR(16) NOT NULL COMMENT '従業員の姓';
ALTER TABLE employees
MODIFY COLUMN gender ENUM('M', 'F') NOT NULL COMMENT '性別(M: 男性, F: 女性)';
ALTER TABLE employees
MODIFY COLUMN hire_date DATE NOT NULL COMMENT '入社日';
ALTER TABLE departments
MODIFY COLUMN dept_no CHAR(4) NOT NULL COMMENT '部署番号(Primary Key)';
ALTER TABLE departments
MODIFY COLUMN dept_name VARCHAR(40) NOT NULL COMMENT '部署名(ユニーク制約あり)';
ALTER TABLE salaries
MODIFY COLUMN emp_no INT NOT NULL COMMENT '従業員番号(employees.emp_no を参照する外部キー)';
ALTER TABLE salaries
MODIFY COLUMN salary INT NOT NULL COMMENT '従業員の給与';
ALTER TABLE salaries
MODIFY COLUMN from_date DATE NOT NULL COMMENT '給与の適用開始日';
ALTER TABLE salaries
MODIFY COLUMN to_date DATE NOT NULL COMMENT '給与の適用終了日';
ALTER TABLE titles
MODIFY COLUMN emp_no INT NOT NULL COMMENT '従業員番号(employees.emp_no を参照する外部キー)';
ALTER TABLE titles
MODIFY COLUMN title VARCHAR(50) NOT NULL COMMENT '役職名';
ALTER TABLE titles
MODIFY COLUMN from_date DATE NOT NULL COMMENT '役職の適用開始日';
ALTER TABLE titles
MODIFY COLUMN to_date DATE DEFAULT NULL COMMENT '役職の適用終了日(NULL の場合、現在も有効)';
ALTER TABLE dept_emp
MODIFY COLUMN emp_no INT NOT NULL COMMENT '従業員番号(employees.emp_no を参照する外部キー)';
ALTER TABLE dept_emp
MODIFY COLUMN dept_no CHAR(4) NOT NULL COMMENT '部署番号(departments.dept_no を参照する外部キー)';
ALTER TABLE dept_emp
MODIFY COLUMN from_date DATE NOT NULL COMMENT '部署に所属し始めた日';
ALTER TABLE dept_emp
MODIFY COLUMN to_date DATE NOT NULL COMMENT '部署に所属していた終了日';
ALTER TABLE dept_manager
MODIFY COLUMN emp_no INT NOT NULL COMMENT '従業員番号(employees.emp_no を参照する外部キー)';
ALTER TABLE dept_manager
MODIFY COLUMN dept_no CHAR(4) NOT NULL COMMENT '部署番号(departments.dept_no を参照する外部キー)';
ALTER TABLE dept_manager
MODIFY COLUMN from_date DATE NOT NULL COMMENT '部署の管理者としての開始日';
ALTER TABLE dept_manager
MODIFY COLUMN to_date DATE NOT NULL COMMENT '部署の管理者としての終了日';
用意するファイルの形式
以下の汎用的なメタデータスキーマに従うことで、どんなデータベースとも連携が可能です。多くのデータベースではINFORMATION_SCHEMAスキーマから取得可能なデータです。
- テーブル用CSVファイル
| 項目名 | 説明 |
|---|---|
| table_catalog | テーブルが属するカタログ(データベース)の名前 |
| table_schema | テーブルが属するスキーマの名前 |
| table_name | テーブルの名前 |
| table_type | テーブルの種類(例: BASE TABLE, VIEWなど) |
| comment | テーブルに関するコメントや説明 |
- カラム用CSVファイル
| 項目名 | 説明 |
|---|---|
| table_catalog | テーブルが属するカタログ(データベース)の名前 |
| table_schema | テーブルが属するスキーマの名前 |
| table_name | テーブルの名前 |
| column_name | カラムの名前 |
| ordinal_position | カラムの順序 |
| column_default | カラムのデフォルト値 |
| is_nullable | カラムがNULLを許容するかどうか |
| data_type | カラムのデータ型 |
| comment | 文字列型のカラムの最大長 |
TROCCO でMySQLからS3に転送する
以下のクエリを利用して、テーブル用およびカラム用のメタデータファイルを作成します。
SELECT
table_catalog AS table_catalog,
table_schema AS table_schema,
table_name AS table_name,
table_type AS table_type,
table_comment AS comment
FROM
information_schema.tables
WHERE table_schema IN ('employees');
SELECT
table_catalog AS table_catalog,
table_schema AS table_schema,
table_name AS table_name,
column_name AS column_name,
ordinal_position AS ordinal_position,
column_default AS column_default,
is_nullable AS is_nullable,
CAST(data_type as CHAR) AS data_type,
column_comment AS comment
FROM
information_schema.columns
WHERE table_schema IN ('employees');
以下はTROCCOでテーブル用のメタデータを転送する際の設定例です。
1つのファイルにする必要があるので、「出力ファイル数抑制転送」で転送後に1つのファイルになっているか注意してください。


カラム用メタデータの転送設定も同様に作成します。転送が完了すると、S3にメタデータファイルが保存されます。

データストアを作成する
必要なファイルが揃ったのでデータストアを作成します。
該当のS3bucketに対して S3:GetObject 権限を持つIAMロールを作成し、連携に必要な設定を追加します。詳しくはヘルプドキュメントを参照ください。

設定を保存するとジョブが開始され、データストアが作成されます。

ジョブが成功し、データストアが作成されました。
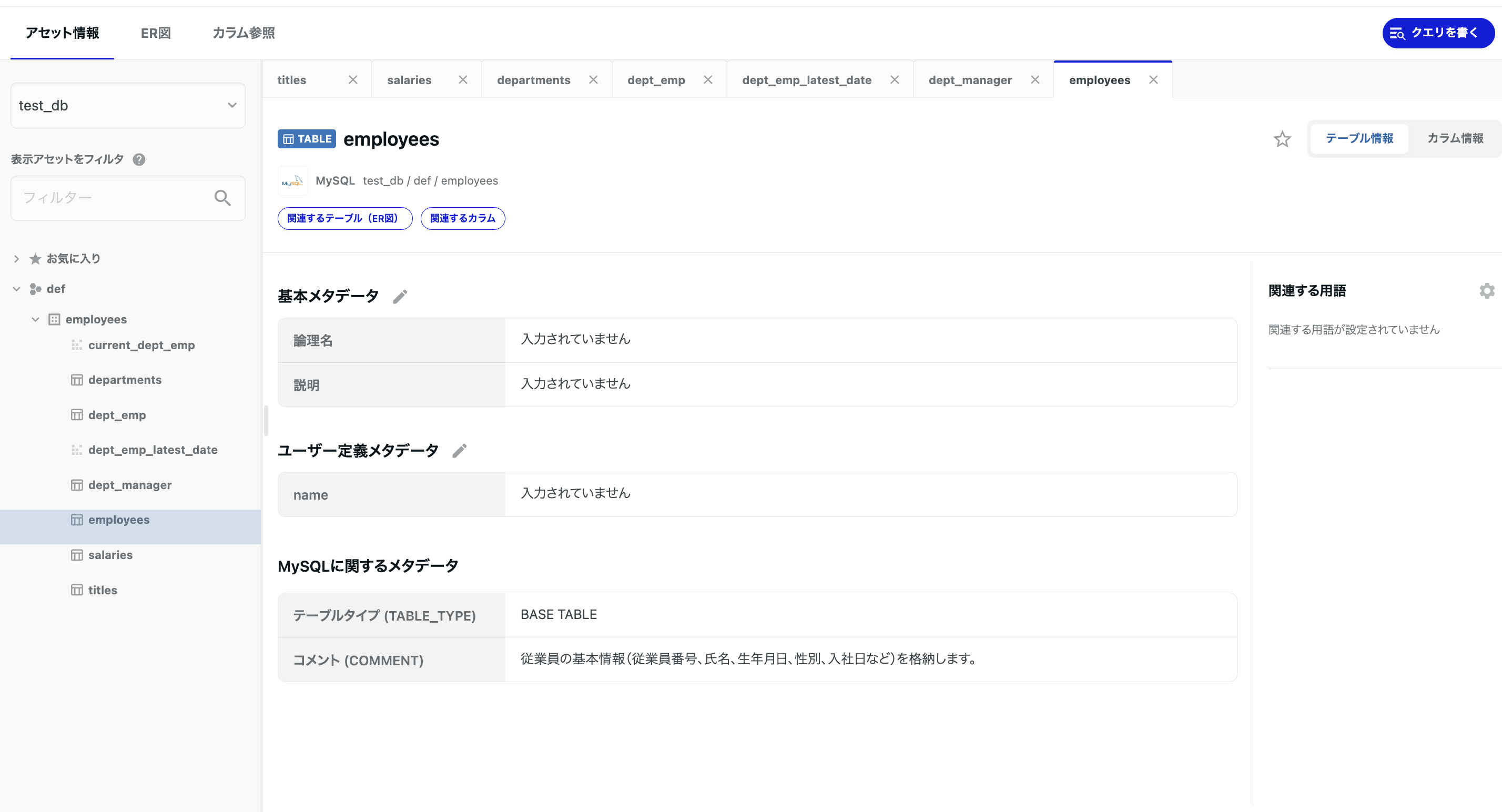

データベース名、スキーマ名、テーブル名、カラム名、DDLコメント名で検索が可能となっています。

カラム参照を設定する
カラム参照に関してCSVメタデータインポートすることでER図を確認することができます。
MySQLではKEY_COLUMN_USAGEからkey情報が取得できるため、それを元にCSVファイルを作成しインポートを行います。
以下のSQLを実行してCSVファイルを作成します。
SELECT
TABLE_CATALOG AS src_database_name,
TABLE_SCHEMA AS src_schema_name,
TABLE_NAME AS src_table_name,
COLUMN_NAME AS src_column_name,
TABLE_CATALOG AS dst_database_name,
REFERENCED_TABLE_SCHEMA AS dst_schema_name,
REFERENCED_TABLE_NAME AS dst_table_name,
REFERENCED_COLUMN_NAME AS dst_column_name
FROM
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE
TABLE_SCHEMA = 'employees'
AND REFERENCED_TABLE_NAME IS NOT NULL
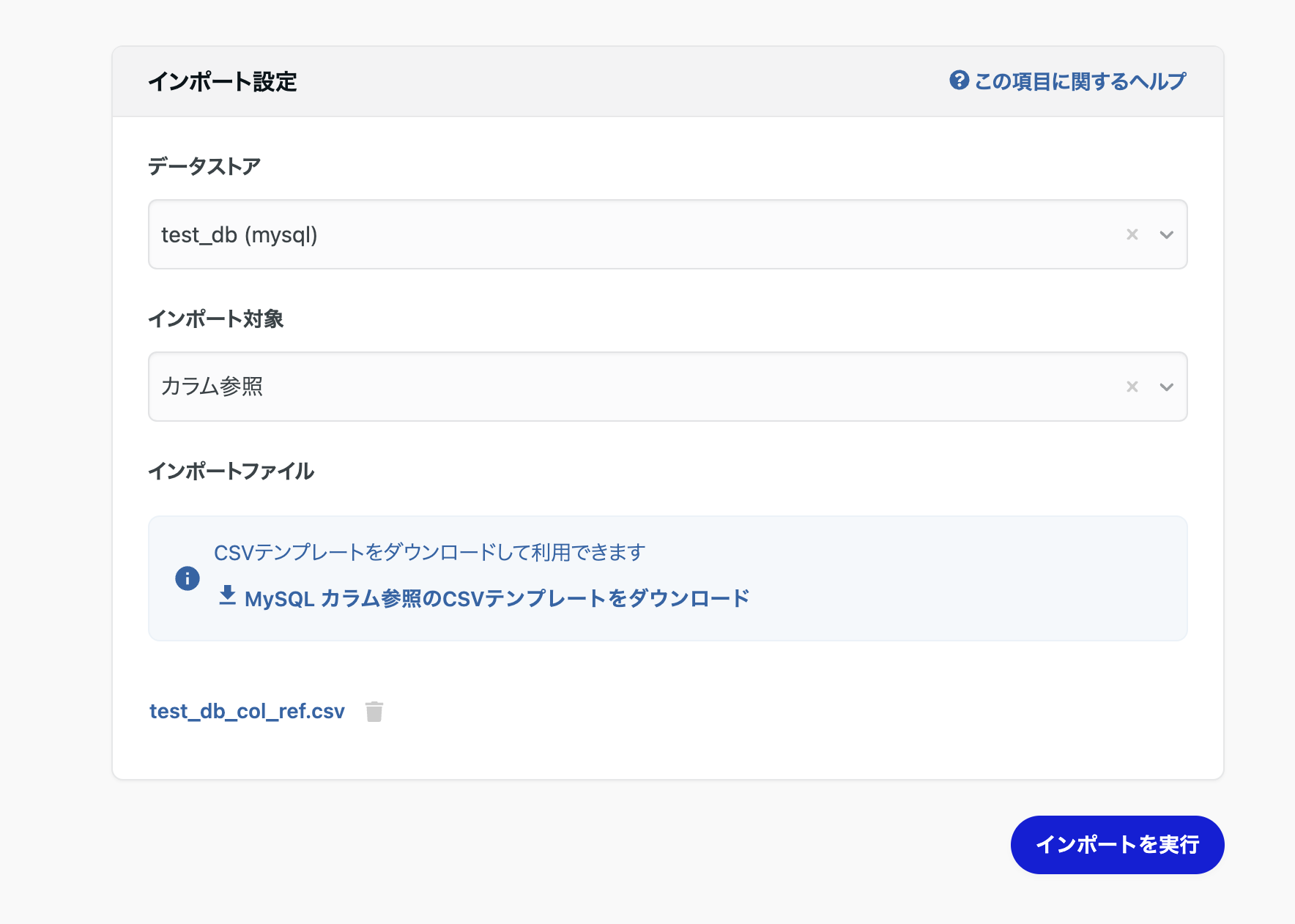
ファイルをインポートをすることでカラム参照情報の更新が完了しました。
ER図が以下のように生成されました。

まとめ
TROCCOを用いてメタデータを抽出し、S3バケットへ転送。その後、カスタムデータベース連携を利用してCOMETA上にデータストアを作成しました。これにより、多くのデータベースを継続的に連携し、一元的にメタデータを管理することができるようになりました。また、ER図の自動生成や検索機能により、データ構造の可視化や活用がさらに容易になりました。