結論
Pandasのapplyメソッドの前にswifterメソッドを加えるだけ
具体例
import pandas as pd
import numpy as np
import swifter
# 適当なDataFrameを作成
df = pd.DataFrame({'col': np.random.normal(size=10000000)})
# applyメソッドの前にswifterメソッドを加える。
%time df['col2'] = df['col'].swifter.apply(lambda x: x**2)
# Wall time: 50 ms
# 比較用(通常のpandasのapplyメソッド)
%time df['col2'] = df['col'].apply(lambda x: x**2)
# Wall time: 3.48 s
インストール方法
$ pip install -U pandas # upgrade pandas
$ pip install swifter
$ conda update pandas # upgrade pandas
$ conda install -c conda-forge swifter
swifterがしていること
Pandasのapplyは遅い
Pandasのapplyメソッドの計算量はO(N)です。1万行くらいのDataFrameなら問題になりませんが、
大容量のDataFrameの処理はかなり辛くなります。
幸いにも、Pandasの処理を高速化する手法はいくつか存在します。
Pandas高速化手法
例えば、ベクトル化できないときはDaskによる並列処理をおこなったりします。
しかし、行数がそれほど多くないDataFrameに並列処理をすると逆に遅くなることがあります。
ケースバイケースで、最適な高速化手法を選ぶのが面倒に感じる僕みたいな人には、swifterがベストです。
swifter
公式ドキュメント3によると、swifterは以下の処理をしています。
- ベクトル化可能であれば、ベクトル化をする。
- ベクトル化できない場合、Daskの並列処理とPandasのapplyのどちらか速い方を自動選択。
最適な方法を自動選択してくれるのは非常に便利です。
後ほど示しますが、多くのケースでPandasのapplyよりもswifterの方が高速なので、
常にswfiterを使うのも悪くないのではないでしょうか。
検証
以下では、DaskやPandasなどと比較して、swifterがどの程度高速なのかを検証したいと思います。
swifterはベクトル化可能な場合とそうでない場合で挙動が異なるので、各々の場合を検証します。
使用したPCのスペックはIntel Core i5-8350U @1.70GHz、メモリが16GBです。
ベクトル化可能な場合
swifterはベクトル化可能なときはベクトル化するので、swifterの計算時間は単純にベクトル化した場合と
ほぼ等しくなるはずです。これを確認してみましょう。
import pandas as pd
import numpy as np
import dask.dataframe as dd
import swifter
import multiprocessing
import gc
pandas_time_list = []
dask_time_list = []
vector_time_list = []
swifter_time_list = []
# ベクトル化可能な関数
def multiple_func(df):
return df['col1']*df['col2']
def apply_func_to_df(df):
return df.apply(multiple_func, axis=1)
for num in np.logspace(2, 7, num=7-2+1, base=10, dtype='int'):
df = pd.DataFrame()
df['col1'] = np.random.normal(size=num)
df['col2'] = np.random.normal(size=num)
ddf = dd.from_pandas(df, npartitions=multiprocessing.cpu_count())
pandas_time = %timeit -n2 -r1 -o -q df.apply(multiple_func, axis=1)
dask_time = %timeit -n2 -r1 -o -q ddf.map_partitions(apply_func_to_df).compute(scheduler='processes')
vector_time = %timeit -n2 -r1 -o -q df['col1']*df['col2']
swifter_time = %timeit -n2 -r1 -o -q df.swifter.apply(multiple_func, axis=1)
pandas_time_list.append(pandas_time.average)
dask_time_list.append(dask_time.average)
vector_time_list.append(vector_time.average)
swifter_time_list.append(swifter_time.average)
del df, ddf
gc.collect()
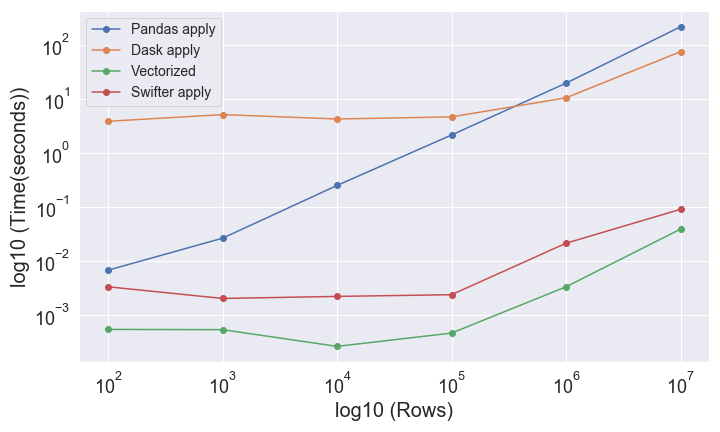
図の横軸がDataFrameの行数、縦軸が経過時間です。両対数グラフであることに注意してください。
swifterの経過時間がベクトル化した場合の経過時間と近いことから、ベクトル化されていることがわかります。
10万行より少ないDataFrameにおいては、Daskの並列処理よりもPandasのシングルコアの方が速いです。
これについては、10万行以下のDaskの経過時間が一定であることから、並列処理にともなうメモリー共有などのオーバヘッドが原因であると推測できます。(関数の計算時間 < メモリー共有のためのデータコピー時間)
ベクトル化不可能な場合
次にベクトル化できない場合についてみていきます。
ベクトル化できない場合、swifterは並列処理とシングルコア処理のいずれか良いほうを選択するはずです。
pandas_time_list_non_vectorize = []
dask_time_list_non_vectorize = []
swifter_time_list_non_vectorize = []
# ベクトル化できない関数
def compare_func(df):
if df['col1'] > df['col2']:
return 1
else:
return -1
def apply_func_to_df(df):
return df.apply(compare_func, axis=1)
for num in np.logspace(2, 7, num=7-2+1, base=10, dtype='int'):
df = pd.DataFrame()
df['col1'] = np.random.normal(size=num)
df['col2'] = np.random.normal(size=num)
ddf = dd.from_pandas(df, npartitions=multiprocessing.cpu_count())
pandas_time = %timeit -n2 -r1 -o -q df.apply(compare_func, axis=1)
dask_time = %timeit -n2 -r1 -o -q ddf.map_partitions(apply_func_to_df).compute(scheduler='processes')
swifter_time = %timeit -n2 -r1 -o -q df.swifter.apply(compare_func, axis=1)
pandas_time_list_non_vectorize.append(pandas_time.average)
dask_time_list_non_vectorize.append(dask_time.average)
swifter_time_list_non_vectorize.append(swifter_time.average)
del df, ddf
gc.collect()
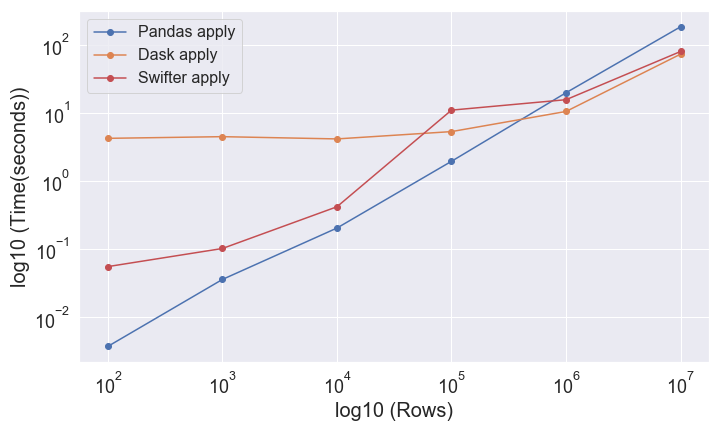
swifterは並列処理が得でないときはシングルコアで処理し、
シングルコアよりも並列処理が優位になれば並列処理を選択していることがわかります。
まとめ
swifterは、状況に応じて最適な高速化手法を自動選択してくれる優れたモジュールです。
貴重な時間を無駄にしないためにも、Pandasのapplyメソッドを使う際はswifterを利用しましょう。
おまけ
ベクトル化とは
ベクトル化関数とは、明示的なforループを書かずに自動的にすべての要素に適用する関数です。
実例を見た方が分かりやすいと思います。
array_sample = np.random.normal(size=1000000)
def non_vectorize(array_sample):
result = []
for i in array_sample:
result.append(i*i)
return np.array(result)
%time non_vectorize_result = non_vectorize(array_sample)
# Wall time: 350 ms
def vectorize(array_sample):
return array_sample*array_sample
%time vectorize_result = vectorize(array_sample)
# Wall time: 4.09 ms
ベクトル化したことで80倍くらい高速になりました。2つの結果が一致することをチェックします。
np.allclose(non_vectorize_result, vectorize_result)
# True