はじめに
今週は動画生成AI界隈に動きがあり、Luma AIのDream MachineとRunwayのGen-3 Alpha TurboでそれぞれがAPIを公開するというニュースが飛び交っていました。
Runwayはまだウェイティングリスト待ちでしたが、Dream MachineのAPIはクレジットを購入すれば使用することが出来たので早速API経由で動画を生成してみようという試みです。
主要機能とレート制限
| 機能/制限 | 説明 |
|---|---|
| テキストから動画生成 | プロンプトを使用して動画を生成 |
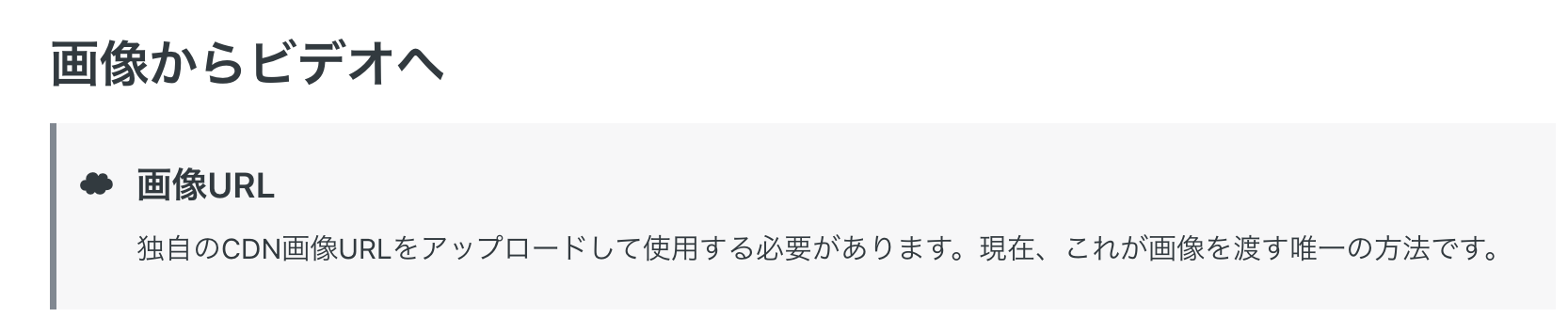
| 画像から動画生成 | 画像URLを入力として動画を生成 |
| 動画の延長 | 既存の生成済み動画を延長または逆方向に拡張 |
| 動画の補間 | 2つの生成済み動画の間を補間 |
| カメラモーション | プロンプトにカメラモーションを指定可能 |
| 生成管理 | 動画生成の取得、一覧表示、削除が可能 |
| カスタマイズ | アスペクト比の設定やループの指定が可能 |
| 非同期処理 | AsyncLumaAIクライアントによる非同期処理 |
| 同時リクエスト制限 | 最大 20 同時リクエスト/秒 |
| 時間あたりのリクエスト制限 | 最大 50 リクエスト/分 |
画像から動画生成の場合、独自のパブリックなURLを指定する必要があるとのことで、実装時には注意が必要そうです。いつか専用のアップロードドライブが用意されることを祈りましょう。
APIキーの準備
APIを利用するには下記にアクセスして、ログイン後にPayment Methodsより支払い方法(要クレジットカード)を設定してください。クレジットカードの設定が出来たらOverviewタブのAdd More Creaditsよりクレジットを追加しましょう。
クレジットが追加されたらAPI Keysより「+ Create Key」をクリックしてAPIKeyを発行して、値を手元に控えてください。
クレジットは5〜500ドルの間で追加することができます。
料金イメージ
メガピクセルあたり0.0032ドルで、720pの5秒のビデオで約0.4ドル
20ドルで約50本のビデオを生成可能とのことです。
Priced at $0.0032 USD per megapixel, a 720p, 5sec video costs around $0.4 USD. $20 will allow us to generate around 50 videos for you.
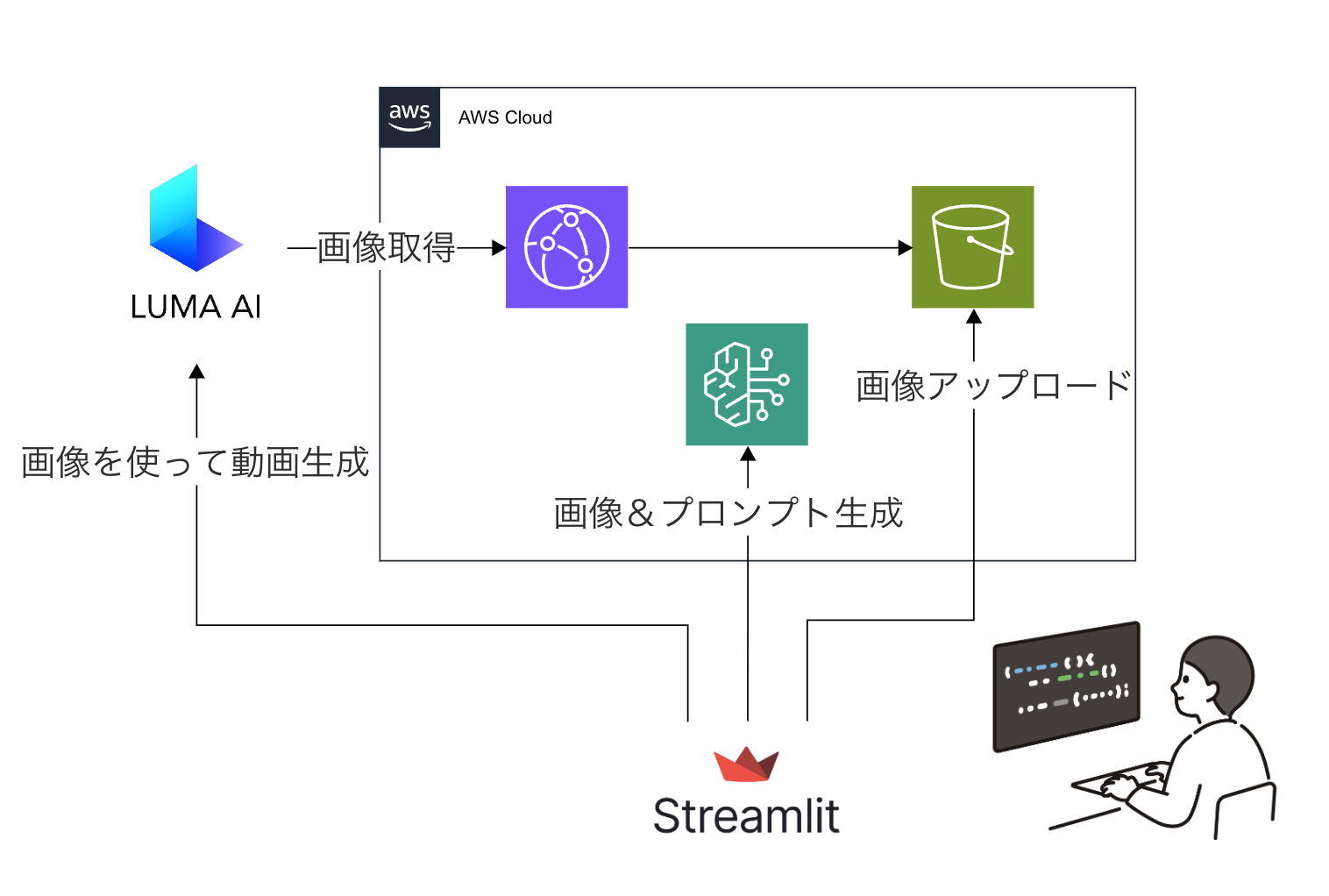
今回のアーキテクチャ
画像から動画生成の挙動を確かめてみたかったので、Cloudfront+S3の環境を別途用意してそちらに画像をアップロードしてURLを発行する形式を採用しました。
やってみた
先ずは事前準備でlumaaiをインストールします。
pip install lumaai
下記が検証で試したコード
import base64
import boto3
import json
import os
import streamlit as st
from PIL import Image
import io
from lumaai import LumaAI
import time
import requests
import uuid
CLAUDE_MODEL = "anthropic.claude-3-haiku-20240307-v1:0"
STABILITY_MODEL = "stability.stable-image-ultra-v1:0"
def setup_config_and_initialize_session():
st.sidebar.title("設定")
luma_api_key = st.sidebar.text_input("LumaAI API Key", type="password")
cloudfront_domain = st.sidebar.text_input("CloudFrontドメイン", value="xxxxxxx.cloudfront.net")
s3_bucket = st.sidebar.text_input("S3バケット名", value="")
profile_name = st.sidebar.text_input("AWSプロファイル名", value="")
region_name = st.sidebar.text_input("AWSリージョン", value="us-west-2")
session = boto3.Session(profile_name=profile_name, region_name=region_name)
bedrock_runtime = session.client("bedrock-runtime")
s3_client = session.client('s3')
return luma_api_key, cloudfront_domain, s3_bucket, profile_name, bedrock_runtime, s3_client
def translate_text(bedrock_runtime, text, is_video=False):
if is_video:
instruction = """
<video_prompt_instruction>
<role>動画生成AI用の日本語から英語へのプロンプト変換専門家</role>
<task>日本語テキストを英語に翻訳し、動画生成AI向けのプロンプトに変換。翻訳されたプロンプトのみを出力。</task>
<guidelines>
主題・設定・要素を具体的に説明
色彩・形状・テクスチャなどの視覚的詳細を指定
全体的な感情やムードを明確に表現
シンプルで直接的な言葉を使用
カメラの動き(ズーム、パン、ティルトなど)を指示
オブジェクトや人物の動きを詳細に描写
重要なオブジェクトの特徴を具体的に指定
背景、時間帯、天候などの環境要素を描写
</guidelines>
</video_prompt_instruction>
"""
else:
instruction = """
<image_prompt_instruction>
<role>あなたは日本語を英語に翻訳し、画像生成に適したプロンプトを作成するエキスパートです。</role>
<task>以下の日本語テキストを英語に翻訳し、画像生成AIで使用するのに適したプロンプトに変換してください。翻訳されたプロンプトのみを出力してください。</task>
<guidelines>
視覚的な詳細を豊かに表現してください。
画像の全体的な雰囲気や感情を伝える言葉を使用してください
重要な要素や被写体を明確に指定してください。
色彩、光、構図に関する情報を含めてください。
</guidelines>
</image_prompt_instruction>
"""
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": f"{instruction}\n\n<original_text>{text}</original_text>"
}
]
})
response = bedrock_runtime.invoke_model(modelId=CLAUDE_MODEL, body=body)
response_body = json.loads(response['body'].read())
return response_body['content'][0]['text'].strip()
def generate_image(bedrock_runtime, prompt):
body = json.dumps({"prompt": prompt})
response = bedrock_runtime.invoke_model(modelId=STABILITY_MODEL, body=body)
output_body = json.loads(response["body"].read().decode("utf-8"))
return base64.b64decode(output_body["images"][0])
def save_and_upload_image(image_data, s3_client, bucket_name, cloudfront_domain):
filename = f"generated_image_{uuid.uuid4()}.jpg"
s3_client.put_object(Bucket=bucket_name, Key=filename, Body=image_data)
return f"https://{cloudfront_domain}/{filename}"
def generate_video(luma_client, prompt, image_url):
generation_response = luma_client.generations.create(
prompt=prompt,
keyframes={"frame0": {"type": "image", "url": image_url}}
)
generation_id = generation_response.id if hasattr(generation_response, 'id') else generation_response['id']
start_time = time.time()
while True:
status = luma_client.generations.get(id=generation_id)
current_state = status.state if hasattr(status, 'state') else status['state']
if hasattr(status, 'assets') and hasattr(status.assets, 'video'):
return status.assets.video
elif isinstance(status, dict) and 'assets' in status and 'video' in status['assets']:
return status['assets']['video']
if current_state == 'failed' or time.time() - start_time > 300:
return None
time.sleep(5)
def main():
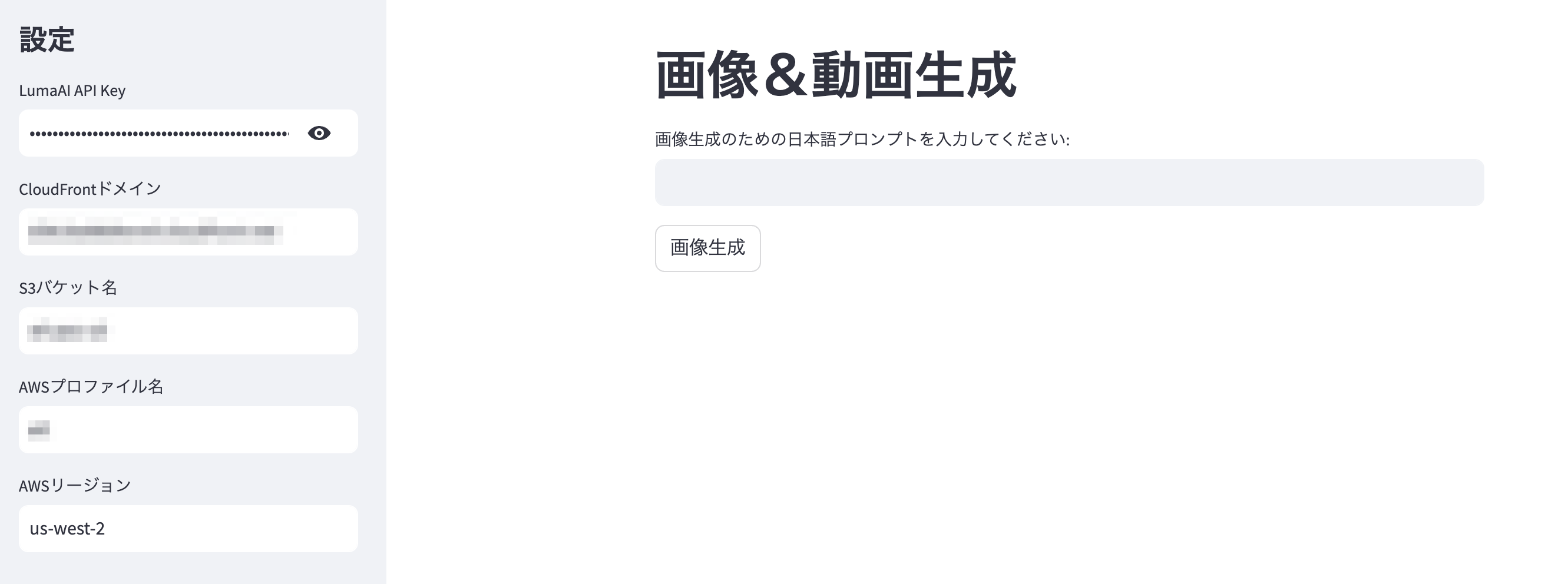
st.title("画像&動画生成")
luma_api_key, cloudfront_domain, s3_bucket, profile_name, bedrock_runtime, s3_client = setup_config_and_initialize_session()
if luma_api_key:
luma_client = LumaAI(auth_token=luma_api_key)
japanese_prompt = st.text_input("画像生成のための日本語プロンプトを入力してください:")
if st.button("画像生成") and japanese_prompt:
with st.spinner('プロンプトを翻訳中...'):
english_prompt = translate_text(bedrock_runtime, japanese_prompt)
st.write("翻訳されたプロンプト:", english_prompt)
with st.spinner('画像を生成中...'):
image_data = generate_image(bedrock_runtime, english_prompt)
image = Image.open(io.BytesIO(image_data))
st.subheader("生成された画像")
st.image(image, use_column_width=True)
cloudfront_url = save_and_upload_image(image_data, s3_client, s3_bucket, cloudfront_domain)
st.session_state['generated_image_cdn_url'] = cloudfront_url
st.session_state['generated_image'] = image
if 'generated_image_cdn_url' in st.session_state:
japanese_video_prompt = st.text_input("動画生成のための日本語プロンプトを入力してください:")
if st.button("動画を生成") and luma_api_key and japanese_video_prompt:
with st.spinner('動画用プロンプトを翻訳中...'):
english_video_prompt = translate_text(bedrock_runtime, japanese_video_prompt, is_video=True)
st.write("翻訳された動画用プロンプト:", english_video_prompt)
with st.spinner('動画を生成中...'):
video_url = generate_video(luma_client, japanese_video_prompt, st.session_state['generated_image_cdn_url'])
if video_url:
col1, col2 = st.columns(2)
with col1:
st.subheader("生成された画像")
st.image(st.session_state['generated_image'], use_column_width=True)
with col2:
st.subheader("生成された動画")
st.video(video_url)
else:
st.error("動画の生成に失敗しました。")
if __name__ == "__main__":
main()
実行コマンド
streamlit run gen_video.py
アプリケーションが起動したらサイドバーにそれぞれ必要情報を入力してください。
※実行時にサイドバーのプロフィールが空の場合エラーがでますが、値を入力することで解消します。
画面に従って日本語で生成したい画像のイメージを入力します。
ここでは試しにサイバーパンクな街並みの画像を生成させてみましょう。
ネオンがきらめく、とてもリアルな架空の機械的な都市を歩く人々
生成された画像

次にこの画像を使って動画を生成するためのイメージを同じようにメッセージに従って入力します。
試しに雨を降らせてみましょう
歩き出す人々、降り出す雨
動画の生成には数十秒程度かかりますので暫く待ちましょう。
生成された動画
元になった画像と生成された動画のプレビューが表示されたら完了です。

無事API経由で画像から動画を生成させることが出来ましたね!
終わりに
今後一層とクリエイティブな領域にも開発の手が伸びていきそうなので、改めて生成AIに関する著作権周りの動向には注意を払っていく必要がありそうというのと、検証では自動的にプロンプトを生成させていますが、このあたりを更に磨きをかけていくとより高度な画像や動画を作り出せるようになるかと思うので引き続きキャッチアップをしていきたいと思います。
また、Dream Machineの場合は通常の動画生成では5秒と短いため、生成された動画をベースにした延長やその他の主要機能も試していきたいですね。