前置き
今話題のOpenAIやChatGPTについて私もご多分に漏れず調べたり動かして遊んでまして、その際のメモ
をesaに雑に書き留めていたのですがこのままのめり込むとタイミングを逸失しそうなので分割して一旦放流しようと思います。
界隈のキャッチアップ&アウトプットが早くて比較すると最早内容の新規性は薄いですが、これから入門する人にOpenAIの1合目として共有できればと思います。
公式ドキュメントを読む
何はともあれ先ずは公式ドキュメントを読むところから始めました。厳密にはTwitterなどで誰かの投稿が目についてそれが意識せず頭にインプットされてはいましたが、能動的アクションとしてのファーストステップはやはり王道の公式ドキュメントですね。
序章にかかれていたプロンプトやトークンなどの用語について軽く触れ、その段階では正直具体的なイメージが追いついていなかったです。
クイックスタートチュートリアルを実施する
チュートリアルベージが用意されていたので上から順に読んでいき、その段階でプロンプト = APIに与える指示という図式にイメージが自分の中で紐付いたり、各用語についても「はい、はい、はい、なるほどね」と納得して進んだのを覚えています。
temperature
プロンプト以外にもAPIに渡すパラメータは存在しており、その内で最も重要なパラメータの一つとして「temperature」という物がありそれを体験できる要素があったので、これからチュートリアルを始める人はスルーせずに一旦触ってみる事をおすすめします。
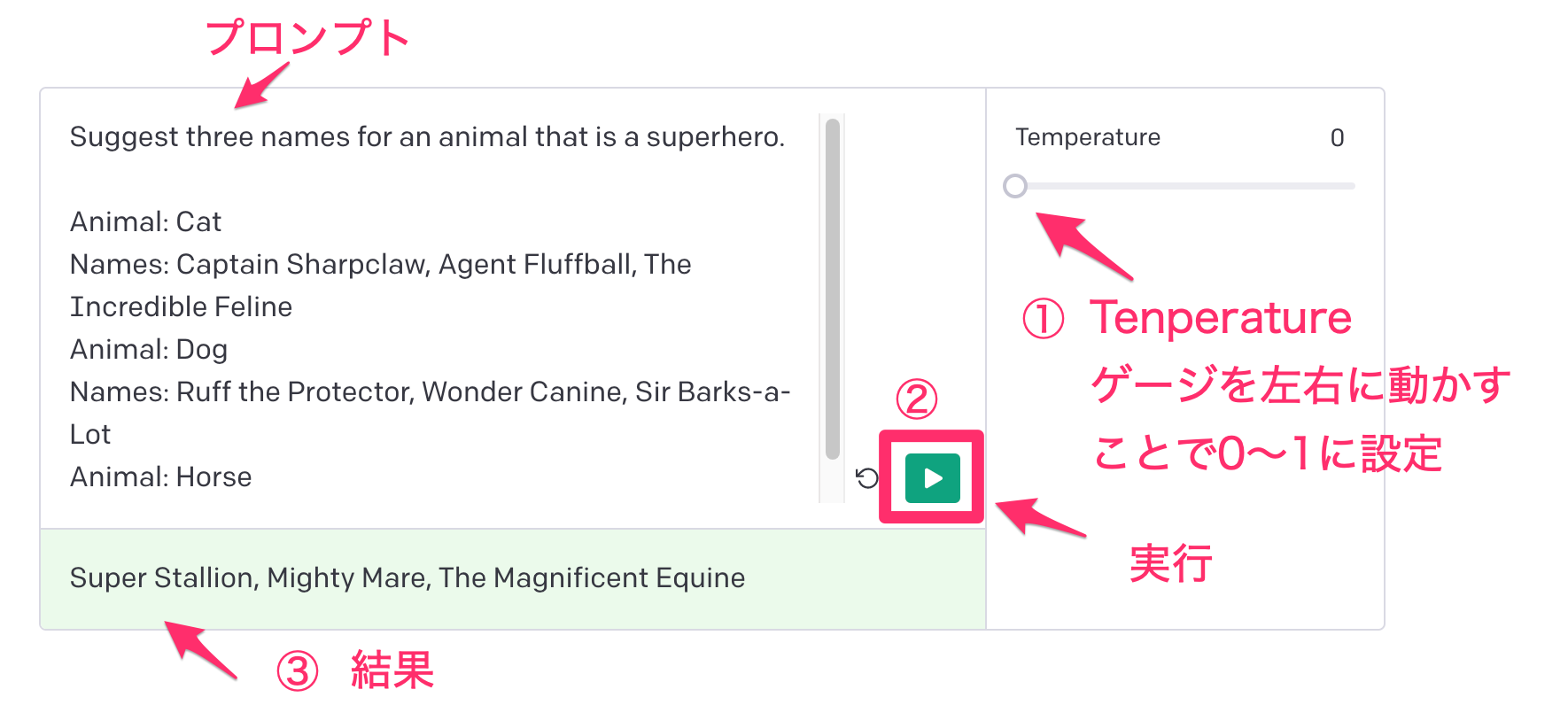
temperatureは0〜1を指定する事ができ、0であれば同様のプロンプトで何度実行しても結果が同じになり、1に近づく程前回実行時の結果とは違う内容が生成されるようになります。そのため、様々なアイディアを引き出したい場合は0よりも大きい値を指定する必要があります。
トークン
OpenAIのAPIは従量課金でその際の料金算出にトークンという概念が深く関わってきますので、個人にしろ組織にしろAPIを使って何か開発をするならこれも覚えておいた方がいいです。
OpenAIで使われているモデルでは、テキストをトークンという単位で単語や単語を小さく区切った塊に分割して処理されます。
ドキュメントでは「I have an orange cat named Butterscotch.」という文を用いて説明され、この例文だと11トークンに分割されている事が分かります。※分割の厳密な法則性やロジックは正直今もよく分かっていないで参考になる文献などあったら知りたい

OpenAIで使われているモデルではプロンプトとして与えられたテキストに対して、次にどのトークンが来る可能性が最も高いかを決めて結果を出力します。そのためtemperatureは次に来る可能性のあるトークンに対してどれくらいの可能性のものを選択するかを指定するイメージと理解出来ました。※0が最も可能性の高いトークンを選択させ、1が最も可能性の低いトークンを選択させる。
サンプルアプリケーションを実行
git clone https://github.com/openai/openai-quickstart-node.git
cd openai-quickstart-node
cp .env.example .env
Create new sercret keyを押下してAPIのシークレットを取得して.envに登録
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxx
※KPIキーは画面右上アイコンから「View API Keys」からも取得出来ます。
APIファイルの以下の部分で使用するモデル、プロンプト、temperatureがそれぞれ指定されています。
text-davinci-003はGPT-3.5系モデルの1つで訓練データは2021年6月までの物です。
const completion = await openai.createCompletion({
model: "text-davinci-003",
prompt: generatePrompt(animal),
temperature: 0.6,
});
以下のコマンドを実行
npm install
npm run dev
コマンド実行後にhttp://localhost:3000へアクセスして動作を確認します。
無事ブラウザに以下が表示されたと思います。
さっそく、入力欄に適当な動物名を入力して「Generate names」を押下しましょう
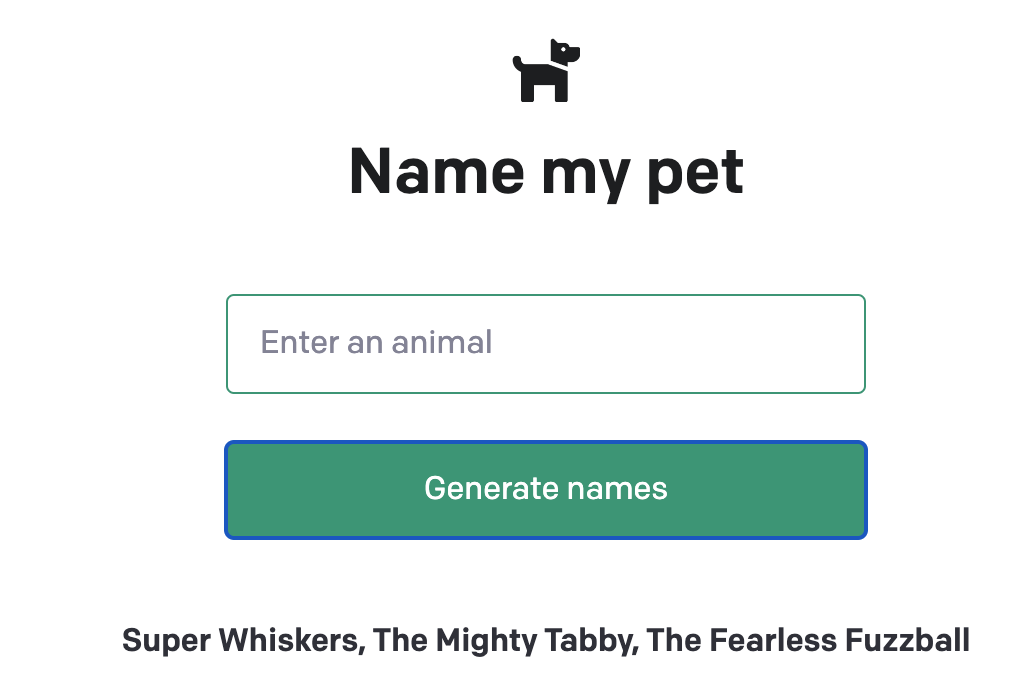
今回はレスポンスとして以下の名前が生成されました。
Super Whiskers, The Mighty Tabby, The Fearless Fuzzball
もう一度入力欄に同じ動物名を入力して「Generate names」を押下しましょう
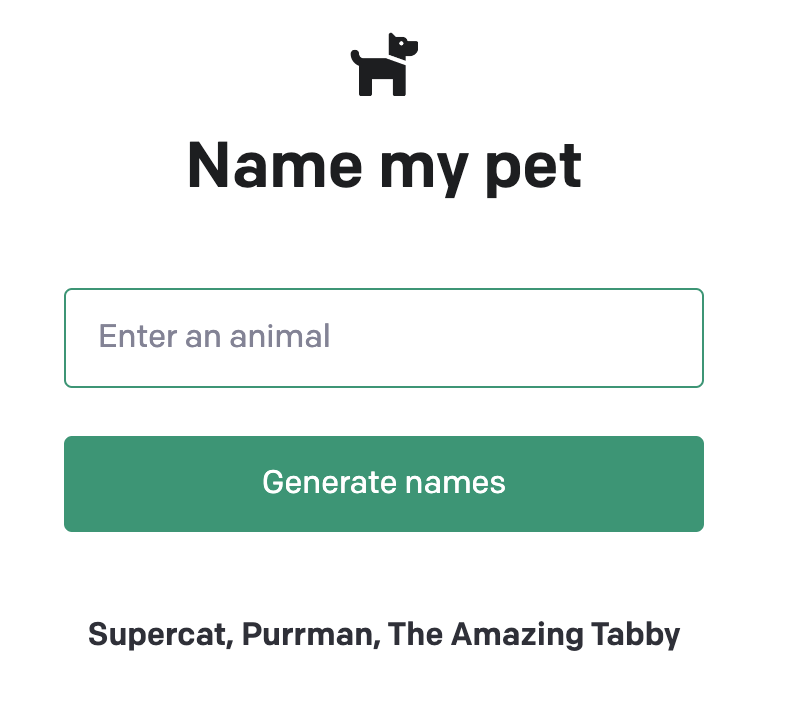
2回目は1回目とは違う結果が生成されました。
これはtemperatureが0以外(0.6)を指定してAPIが叩かれたためです。
Supercat,Purrman,The Amazing Tabby
temperatureを0に指定して再度「Generate names」を押下しましょう
const completion = await openai.createCompletion({
model: "text-davinci-003",
prompt: generatePrompt(animal),
- temperature: 0.6,
+ temperature: 0,
});
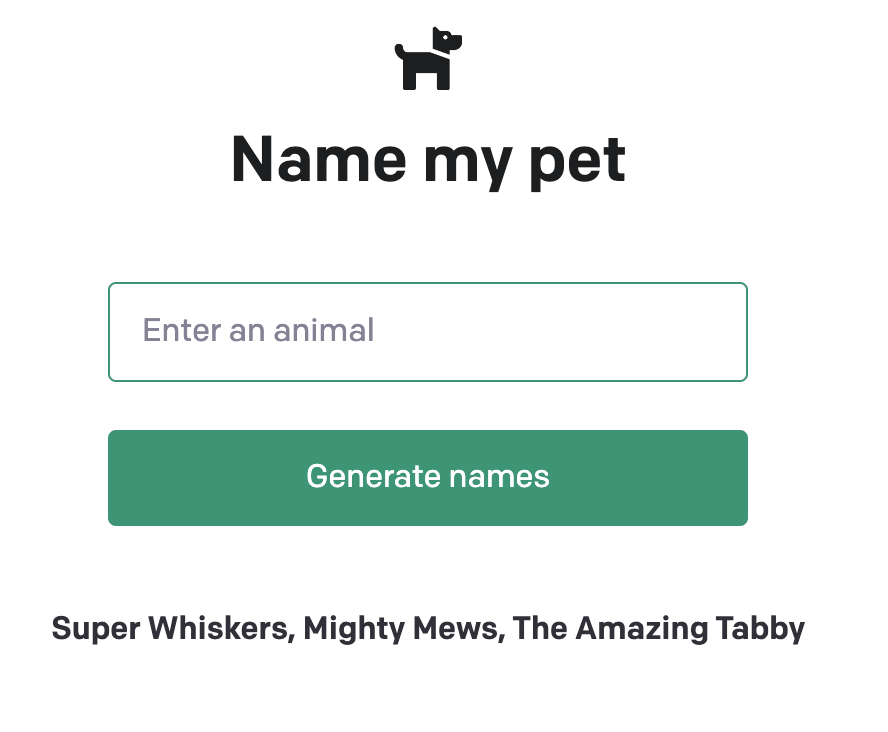
何度実行されても同じ結果が生成されている事が確認できたかと思います。
Super Whiskers, Mighty Mews, The Amazing Tabby
トークン上限
Chatなどで用いられる各モデルにはプロンプトとレスポンスによるトークンに上限が設定されています。
ChatGPTで何か途中で途切れるなという事象はこれが原因と思われます。
gpt-3.5-turboが4,096トークンなので、約750単語*4≒3,000単語(プロンプト+レスポンス)が往復での上限と考えられます。
また、ChatGPTを使っている方ならご存知感もしれませんが、最新の情報について聞いた際に2021年9月までの訓練データを使われたAIですといった主旨の返答が返ってきた経験があるかもしれません。これは返答にあるように、各モデルはある時点までの訓練データを元にしたAIとして機能しているためです。

参考までにGPT-3.5系とGPT-4系のモデルを幾つかピックアップしてトークン上限と訓練データ期間を記載します。
| モデル | トークン上限 | 訓練データ |
|---|---|---|
| gpt-3.5-turbo | 4,096 tokens | 2021/9 |
| text-davinci-003 | 4,097 tokens | 2021/6 |
| gpt-4 | 8,192 tokens | 2021/9 |
| gpt-4-32k | 32,768 tokens | 2021/9 |
その他詳細は以下より確認出来ます。
さて、チュートリアルは以上でしたがざっくりとAPIを叩くアプリケーションを動かしてみた事で基本的な概念や動作について掴めたと思います。
料金の確認
以下に料金ページがありますので目を通しておきましょう。
1,000トークンあたりの価格で、1,000トークンは約750単語
※日本語と英語におけるトークン算出にどう差異があるかは分かりませんでした。

ChatGPTの火付け役ともなったgpt-3.5-turboは1,000トークン(約750単語)あたり0.002ドルになります。1,000倍の約750,000単語で漸く2ドルで、鈍器と呼ばれる京極夏彦氏の魍魎の匣の文字数(not 単語数)が約50万字らしいことを鑑みてもかなりお得感が分かります。gpt-3.5-turboでAPIを叩く分には比較的安心して使えそうだという事が分かりますね。
一方で以下の画像の通りGPT-4はgpt-3.5-turboの10倍以上するので、APIを使用する際には少し意識しておくといいかもしれません。また、巷で話されているGPT-4の20ドル云々というのはChatGPTでGPT-4モデルを使用できる有料版ChatGPT Plusの課金額で、OpenAIのAPI使用料とは別になります。

イメージ生成で用いるDALL·Eや、書き起こしで使うwhisperのモデルは別の方法で算出されるので、事前にそちらも確認しておくと良いでしょう。
使用制限の確認及び設定
OpenAIではAPIの使いすぎによる課金が想定を上回って予算を超えてしまう自体を予防するためのハードリミットとソフトリミットを設定する事が出来ます。Defaultではハードリミットが120ドル、ソフトリミットが96ドルに設定されているので、個人や組織で使用される際には事前に確認して設定しておくといいでしょう。
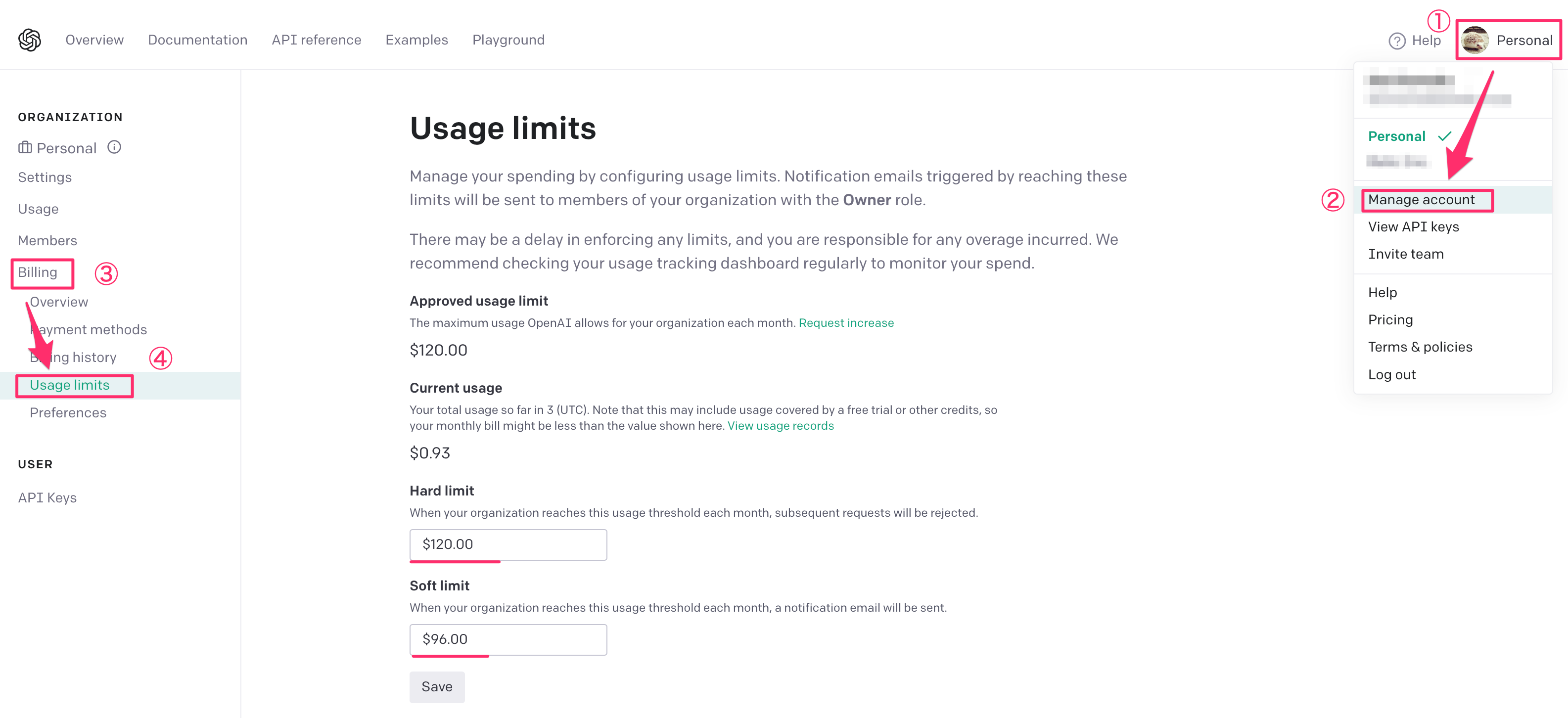
利用状況の確認
現在の利用状況(料金)についても以下のように画面から確認出来ます。
また、これを書いている際に気づいたのですが7月まで使える無料枠として5ドル付与されていました。
利用規約から読み取るデータの利用について
(c) サービスを改善するためのコンテンツの使用。当社は、お客様が当社の API に提供する、または当社の API から受け取るコンテンツ (「API コンテンツ」) を使用して、当社のサービスを開発または改善することはありません。当社は、当社のサービスの開発および改善を支援するために、当社の API 以外のサービスからのコンテンツ (「非 API コンテンツ」) を使用する場合があります。非 API コンテンツを使用してモデルのパフォーマンスを向上させる方法について詳しくは、こちらをご覧ください 。非 API コンテンツを使用してサービスを改善したくない場合は、 このフォームに記入してオプトアウトできます。場合によっては、これにより、特定のユースケースにより適切に対処するための当社のサービスの能力が制限される可能性があることに注意してください。
上記項目によると、APIを使用する分にはOpenAIサービスの開発や改善に使われる事はないようです。逆に非APIサービスは学習に使われると読めますね。
非API(ChatGPTなど)サービスを利用した際に自分たちが入力したデータを学習などに使われたくない場合は、以下のフォームに入力することで対象から外してもらえるようです。
※どれくらいで対象から外れるのかは試してないので不明
まとめ
OpenAIの入門におけるはじめの一歩として自分が辿った流れと、Qiitaに書き起こすにあたってこれもあった方がいいかなというのを整理してみました。メモは他にも書いてあるので別記事で続きを書いていきたいと思います。
Devトーク
弊社でQiitaのDevトークを活用しています。
それぞれのテーマについて雑談してみたい方がいましたら是非お話しましょう。