メタデータ検索とは?
Knowledge Bases for Amazon Bedrock(以下、ナレッジベース)内にあるドキュメントに対してメタデータファイルを事前に用意することで関連文書の検索精度を向上させることができる機能です。
メタデータ検索の利用方法
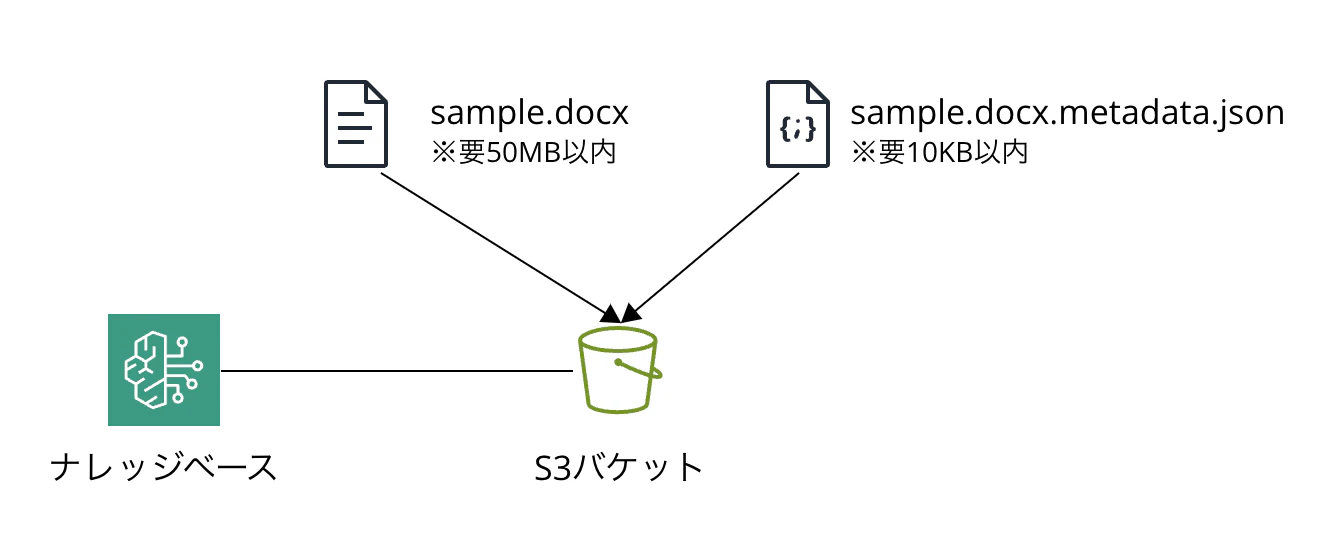
前提としてソースデータに対応するmetadata.jsonを<ソースデータファイル名.拡張子>.metadata.jsonの形式でソースデータと一緒のS3へ格納する必要があります。
ソースデータとmetadata.jsonはそれぞれ下記のサイズ要件があるので注意してください。
| ファイル | サイズ |
|---|---|
| ソースデータ | 50MB以内 |
| metadata.json | 10KB以内 |
イメージ:
また、metadata.jsonファイルは以下のようにmetadataAttributesフィールドにメタデータ属性のキー/バリューのペアとして記載する必要があります。
{
"metadataAttributes": {
"${attribute1}": "${value1}",
"${attribute2}": "${value2}",
...
}
}
また、属性の値として文字列、数字、ブール値がそれぞれサポートされています。
■参照
課題点
メタデータ検索をうまく活用するには各ドキュメントに対応するmetadata.jsonを用意する必要がありますが、ファイルの準備もその中身にしても、いちいち手動で作るのは現実的じゃありません。

自動化概要
面倒なことは極力避けたいですよね、ということでLambdaを使って自動化してみました。
構成としてはシンプルで、S3バケットにソースデータとなるファイルが格納されたら、Lambdaが実行されます。Lambdaではソースデータを解析して対応するmetadata.jsonファイルを作成した後にソースデータのコピーとmetadata.jsonファイルをそれぞれ別のS3バケットに格納します。

Lambda関数作成
Lambda関数作成ステップとして以下があります。
※それぞれus-east-1で実施しています。
- Lambda関数を
Pyhton3.9で作成(ここではスキップ) - S3のPUTイベントをトリガーに設定
- Lambdaレイヤー設定
- 権限付与
- 環境変数を設定してコードのデプロイ
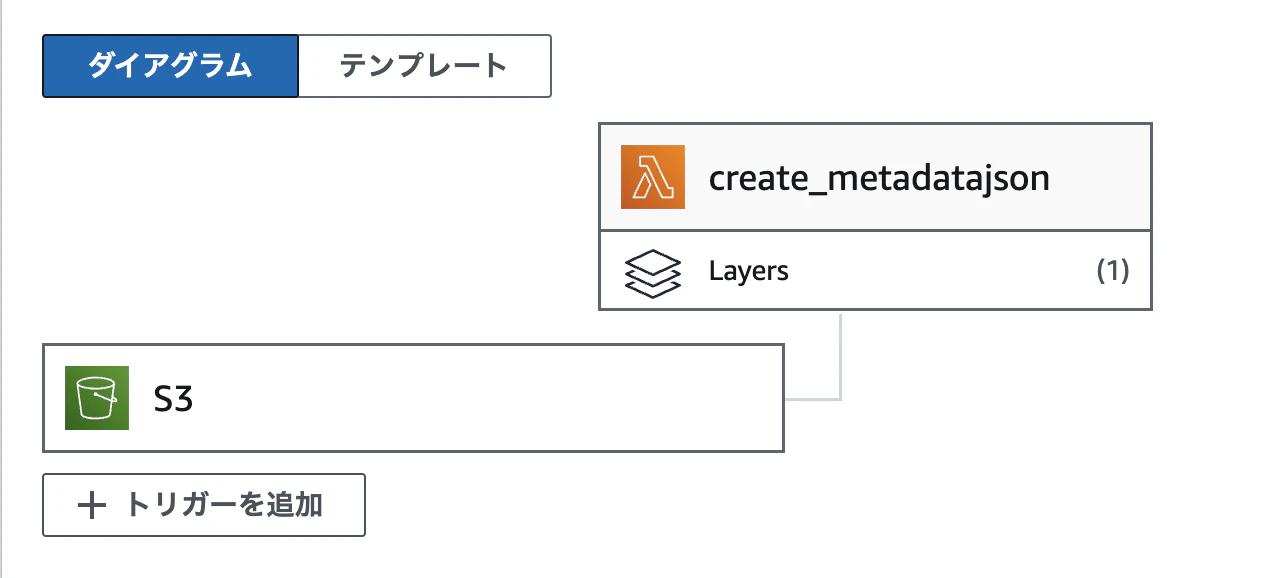
S3のPUTイベントをトリガーに設定
S3バケットにファイルがPUTされたことをトリガーに、Lambda関数が実行されるように設定していきます。
- Lambda関数画面上部の「トリガーを追加」をクリックして、下記の値を指定した後に「追加」をクリック
| 項目 | 設定 |
|---|---|
| ソースを選択 | S3 |
| バケット | S3-Aとなるバケットを指定 ※ここで指定するバケットを間違えるとループが発生するので注意 |
| イベントタイプ | PUT |
| 再帰呼び出し | ☑ |
Lambdaレイヤー設定
Cloud9を起動してLambda実行に必要なライブラリをzipにしてS3バケットにコピーします。
mkdir python
pip3 install --target ./python langchain-aws==0.1.0 langchain_core PyPDF2 openpyxl
zip -r layer.zip ./python
aws s3 cp layer.zip s3://<適当なS3バケット>/layer.zip
- Lambdaコンソールから「レイヤー」->「レイヤーの作成」をクリック
- 以下の値をそれぞれ設定して「作成」をクリック
| 項目 | 設定 |
|---|---|
| 名前 | Lambdalayer |
| Amazon S3 からファイルをアップロードする/ Amazon S3 のリンク URL |
https://<適当なS3バケット>/layer.zip |
| 互換性のあるアーキテクチャ | x86_64 |
| 互換性のあるランタイ | Pyhton3.9 |
- Lambda関数の画面下部の「レイヤー」から「レイヤーの追加」をクリック
- カスタムレイヤーから先程作成した「Lambdalayer」を選択して、バージョンを「1」にして「追加」をクリック
権限付与
Lambda関数にアタッチされているIAMロールにS3-AとS3-Bへのアクセス権限を付与したポリシーを追加します。
※<S3-A>と<S3-B>にはそれぞれ自身の環境にあわせた値を入れてください
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:Get*",
"s3:List*"
],
"Resource": "arn:aws:s3:::<S3-A>/*"
},
{
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::<S3-B>/*"
},
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": [
"arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0"
]
}
]
}
環境変数を設定してコードのデプロイ
- 環境変数を以下の値で設定
| キー | 値 |
|---|---|
| BUCKET_A | S3-Aのバケット名 |
| BUCKET_B | S3-Bのバケット名 |
続いて以下のコードを用いてLambda関数をデプロイしてください。
今回は下記の3種類のメタデータを付与させてみました。
| キー | 概要 |
|---|---|
| title | ファイル名 |
| year | オブジェクト作成年 |
| category | ファイルカテゴリー |
ファイルカテゴリーはClaudeにファイル内容を読み込んでもらって、適切と思われるキーワードを出力させています。
import os
import json
import boto3
from datetime import datetime, timedelta
from urllib.parse import unquote_plus
from io import BytesIO
from langchain_aws import ChatBedrock
from langchain_core.messages import HumanMessage, SystemMessage
import PyPDF2
import openpyxl
# PDFファイルを読んで、テキストを抽出
def load_pdf(file_content):
pdf_reader = PyPDF2.PdfReader(BytesIO(file_content))
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
return text
# Excelファイルを読んで、テキストを抽出
def load_excel(file_content):
workbook = openpyxl.load_workbook(BytesIO(file_content))
sheet = workbook.active
text = ""
for row in sheet.iter_rows(values_only=True):
text += " ".join(str(cell) for cell in row if cell is not None) + "\n"
return text
def lambda_handler(event, context):
# 環境変数からS3-Aのバケット名を取得
storage_bucket_name = os.environ['BUCKET_A']
# 環境変数からS3-Bのバケット名を取得
copy_bucket_name = os.environ['BUCKET_B']
# S3オブジェクトキーを取得
object_key = event['Records'][0]['s3']['object']['key']
object_key = unquote_plus(object_key)
# LLMモデル定義
chat = ChatBedrock(
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
model_kwargs={
"temperature": 0.5,
},
)
print(f"Decoded object_key: {object_key}")
# S3オブジェクトのディレクトリパスを取得
directory_path = os.path.dirname(object_key.encode('utf-8')).decode('utf-8')
# S3クライアントを初期化
s3_client = boto3.client('s3')
# S3オブジェクトのメタデータ取得
response = s3_client.head_object(Bucket=storage_bucket_name, Key=object_key)
# ファイル名と拡張子を取得
file_name = os.path.splitext(os.path.basename(object_key.encode('utf-8')))[0].decode('utf-8')
extension = os.path.splitext(os.path.basename(object_key.encode('utf-8')))[1].decode('utf-8')
# S3オブジェクトの作成日時を取得
created_at_utc = response['LastModified']
created_at_jst = created_at_utc + timedelta(hours=9)
year = created_at_jst.strftime('%Y')
# ファイルをS3から読み込む
file_obj = s3_client.get_object(Bucket=storage_bucket_name, Key=object_key)
file_content = file_obj['Body'].read()
# 拡張子に応じてテキストを抽出(pdf,csv,xlsxに対応、それ以外はファイル名をインプットとする)
if extension == '.pdf':
input_text = load_pdf(file_content)
elif extension == '.csv':
input_text = file_content.decode('utf-8')
elif extension == '.xlsx':
input_text = load_excel(file_content)
else:
input_text = file_name
# カテゴリーを判定するための質問
category_question = """
ファイルの内容あるいはファイル名から適切なカテゴリー考え、要件に沿って出力してください。
"""
# メインの処理を呼び出す
category = categorize(chat, f"{input_text}\n\n{category_question}")
# JSONデータを作成
json_data = {
"metadataAttributes": {
"title": file_name,
"year": year,
"category": category
}
}
# JSONファイル名を生成
json_file_name = f"{file_name}{extension}.metadata.json"
json_file_key = os.path.join(os.path.dirname(object_key.encode('utf-8')), json_file_name.encode('utf-8')).decode('utf-8')
# オリジナルのファイルをコピー用のS3バケットにコピー
s3_client.copy_object(
Bucket=copy_bucket_name,
CopySource={'Bucket': storage_bucket_name, 'Key': object_key},
Key=object_key
)
# JSONファイルをコピー用のS3バケットに書き出す
s3_client.put_object(
Body=json.dumps(json_data, ensure_ascii=False, indent=4),
Bucket=copy_bucket_name,
Key=json_file_key,
ContentType='application/json'
)
print(f"{file_name}がコピー用のバケットにコピーされました。")
print(f"{json_file_name}がコピー用のバケットに生成されました。")
def categorize(chat, input_text: str) -> str:
# SystemMessageプロンプト
system_prompt = """
あなたは優秀なアシスタントです。以下の手順に従ってファイルを適切なカテゴリーに分類してください。
1.提供されたファイルの内容またはファイル名を注意深く読み、理解するよう心がけてください。
2.ファイルの内容を十分に把握したら、そのファイルに適したカテゴリーを複数考えてみてください。
3.考えたカテゴリーの中から、ファイルの内容に最も合致すると思われるカテゴリーを選んでください。
4.選択したカテゴリーを1単語のみ提示して出力してください。
"""
messages = [
SystemMessage(
content=system_prompt
),
HumanMessage(
content=input_text
)
]
# LLMにプロンプトを与えて、応答を含む結果を得る
result = chat.invoke(messages)
# for debug
print(f"Result: {result}")
# 得られた結果から、LLMが返した最新の応答テキストを抽出する
output_text = result.content
return output_text
動作確認
以下のファイルをS3-Aに格納して動作確認
Decoded object_key: AWS-Black-Belt_2024_Large-Migration-Best-Practice_0229_v1.pdf
Result: content='プレゼンテーション' additional_kwargs={'usage': {'prompt_tokens': 8093, 'completion_tokens': 11, 'total_tokens': 8104}} response_metadata={'model_id': 'anthropic.claude-3-sonnet-20240229-v1:0', 'usage': {'prompt_tokens': 8093, 'completion_tokens': 11, 'total_tokens': 8104}} id='run-56dfa81d-6dc9-4058-a6c0-613ff5b5dc4d-0'
AWS-Black-Belt_2024_Large-Migration-Best-Practice_0229_v1がコピー用のバケットにコピーされました。
AWS-Black-Belt_2024_Large-Migration-Best-Practice_0229_v1.pdf.metadata.jsonがコピー用のバケットに生成されました。
END RequestId: dc64950d-94ce-42df-950d-e94b6040f2ee
REPORT RequestId: dc64950d-94ce-42df-950d-e94b6040f2ee Duration: 19571.68 ms Billed Duration: 19572 ms Memory Size: 128 MB Max Memory Used: 117 MB Init Duration: 1059.29 ms
metadata.jsonファイルとオリジナルのソースデータからコピーされたファイルがS3-Bに出力されました。

metadata.jsonファイルの中身を開くとtitle、yaer、categoryそれぞれの値が入力されていることがわかります。
※categoryがプレゼンテーションなのは微妙ですが、プロンプトを調整するなりで改善すると思います。
{
"metadataAttributes": {
"title": "AWS-Black-Belt_2024_Large-Migration-Best-Practice_0229_v1",
"year": "2024",
"category": "プレゼンテーション"
}
}
ナレッジベースでメタデータ検索を試す
ナレッジベースにてフィルターをcategory = プレゼンテーションに設定します。
質問を投げて回答が生成されたらソース詳細をクリックしてクエリ設定を確認してみましょう。

クエリ設定項目でフィルターがcategory = プレゼンテーションと表示されてますね。

ソースチャンク1の「このチャンクに関連付けられたメタデータ」を開くと、metadata.jsonファイルに入力された値が表示されていることが確認できます。
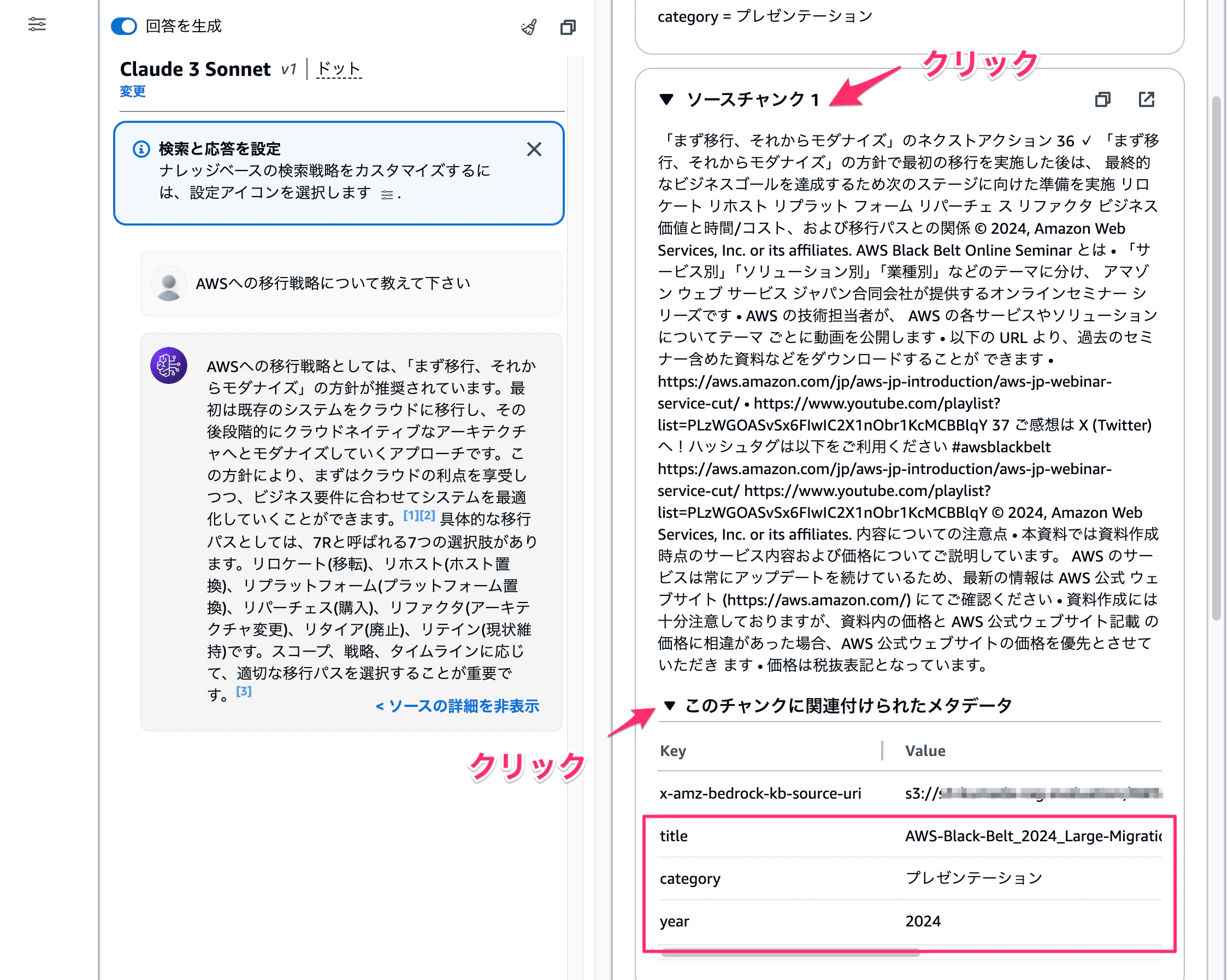
Lambdaで作成したmetadata.jsonファイルが無事機能していることが確認できました!
まとめ
今回はClaudeにカテゴリーを自由に考えさせて当てはめていきましたが、より正確に分類させるなら予めカテゴリーリストを用意して、そこから合致するものを選択させるなどすると、検索時のフィルタリングとしては便利かもしれません。
RAGの検索精度を向上させることのできるメタデータフィルタリングですが、面倒に感じていたmetadata.jsonファイルの準備を自動化できました。工夫の余地はまだまだあるので引き続きBedrockを活用していきたいと思います。
参考
おまけ
Bedrockを活用した生成AIアプリ開発入門本を共著で書きました!