LlamaIndexとは

LlamaIndex (旧GPTIndex) は、LLM(大規模言語モデル)と外部データの間を中継してくれるOSSです。公式ドキュメントによると以下のような機能を持ち合わせており、ざっくりというと既存のデータに対してインデックスを予め張る事でプロンプトがより適切な回答をしてくれるようになる仕組みを提供してくれます。
LlamaIndex機能
- 様々なデータ形式(API、PDF、ドキュメント、SQL など)の既存のデータソースへのコネクタを提供
- 非構造化データと構造化データのインデックスを提供
- ユーザーがプロンプトを入力すると、その情報に関するデータを補強した出力を取得するためのインターフェイスを提供
- コストパフォーマンスのバランスを考慮した便利なツールセットを提供
ローダー
LlamaIndexはその機能の説明にあった通り独自データへのデータコネクタを提供しており、それらをLlama Hubで確認する事ができます。
対応ローダー抜粋
- confluence
- database
- discord
- elasticsearch
- file
- file/audio
- file/docx
- file/json
- file/pdf
- file/simple_csv
- github_repo
- gmail
- google_calendar
- google_docs
- google_drive
- hatena_blog
- notion
- s3
- slack
- web/simple_web
- wikipedia
- wordpress
- youtube_transcript
やってみた
インストール
pip install llama-index
サンプルCSVを用意
sample.csv
id,title,description
1,Apple,"The apple is a sweet fruit that is high in fiber and vitamin C."
2,Banana,"The banana is a tropical fruit that is a good source of potassium and carbohydrates."
3,Orange,"The orange is a citrus fruit that is high in vitamin C and antioxidants."
4,Strawberry,"The strawberry is a sweet and juicy fruit that is rich in vitamin C and antioxidants."
sample.py作成
幾つかの記事で以下のようにChatGPTLLMPredictorを使っているものがありましたが、今はもう使えなくなっておりました。
sample.py
from llama_index.langchain_helpers.chatgpt import ChatGPTLLMPredictor
■ 参照
■ 代わりに以下を使用
sample.py
from llama_index import download_loader,LLMPredictor
from langchain.chat_models import ChatOpenAI
ここではappleの特徴は?とクエリさせます。
sample.py
from dotenv import load_dotenv
from pathlib import Path
from llama_index.indices.vector_store import GPTSimpleVectorIndex
from llama_index import download_loader,LLMPredictor
from langchain.chat_models import ChatOpenAI
load_dotenv()
SimpleCSVReader = download_loader("SimpleCSVReader")
llm_predictor = LLMPredictor(
llm=ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo"
)
)
csv_path = Path('./sample.csv')
loader = SimpleCSVReader()
documents = loader.load_data(file=csv_path)
index = GPTSimpleVectorIndex(
documents,
llm_predictor=llm_predictor
)
query = 'allpeの特徴は?'
response = index.query(query)
print(response)
index.save_to_disk('index.json')
loaded_index = GPTSimpleVectorIndex.load_from_disk('index.json')
python実行
python3 sample.py
結果
日本語で聞くと日本語で返ってくるのでありがたい。
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total LLM token usage: 0 tokens
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total embedding token usage: 251 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 331 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 10 tokens
りんごは、食物繊維とビタミンCを多く含む甘い果物です。
巣の状態でChatGPTに聞いてみる
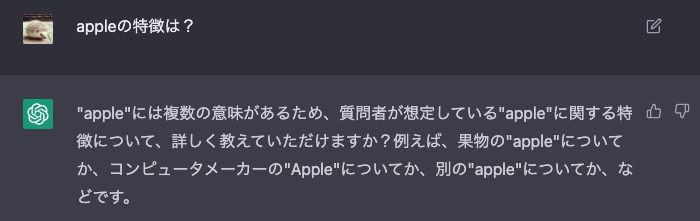
CSVにないことを聞いてみる
sample.py
query = 'カルシウムの特徴は?'
response = index.query(query)
print(response)
結果
csvに記載のない情報について聞くと、和訳で文脈情報にカルシウムに関する情報が含まれていないため、質問に回答することはできません。と返ってくる。
WARNING:llama_index.llm_predictor.base:Unknown max input size for gpt-3.5-turbo, using defaults.
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total LLM token usage: 0 tokens
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total embedding token usage: 91 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 155 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 14 tokens
The context information does not provide any information about calcium, so it is not possible to answer the question.
独自見解を聞いてみる
CSV内の情報以上を引き出してみたくなったので以下の様に聞いてみました
sample.csv
query = 'りんごについて独自の見解を交えて説明してください?'
response = index.query(query)
print(response)
結果
最初の1文は一緒でしたが、続きを出力してくれました。
L知ってるかAIは毎日りんごを食べるぞ
WARNING:llama_index.llm_predictor.base:Unknown max input size for gpt-3.5-turbo, using defaults.
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total LLM token usage: 0 tokens
INFO:llama_index.token_counter.token_counter:> [build_index_from_documents] Total embedding token usage: 91 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 430 tokens
INFO:llama_index.token_counter.token_counter:> [query] Total embedding token usage: 39 tokens
りんごは、甘くて食物繊維やビタミンCが豊富な果物です。私たちの健康に良い影響を与えることが多く、りんごを食べることは健康的な生活を送るための良い方法の一つです。また、りんごは多くの種類があり、それぞれ異なる味わいや用途があります。例えば、ジューシーなりんごは生食に向いている一方、パイに使う場合には固めのりんごが良いとされています。私はりんごが大好きで、毎日食べるようにしています。
終わりに
LlamaIndexを使ってインデックスを予め張っておくことでCSV情報を織り込んだ内容を回答してくれる様になりました。聞き方によってはプラスアルファなレスポンスが返ってくれるのも面白いですね。LlamaIndexはCSV以外にも様々なローダーがあるので他のものも試してみたいのと、今回は軽量なCSVでしたが、実際に独自データのインデックスを張るとなると膨大な容量となる事が想定されるため、その際の処理スピードなんかも気になるので引き続き検証していきたいと思います。
参照