TL;DR
- 画像生成モデルによる芸術家のスタイル模倣が問題となっている。
- 生成モデルは、アーティストの作品サンプルを「ファインチューニング(追加学習)」することで、特定のアーティストの芸術的スタイルを模倣することができる。
- そこで、作品に微小な接道を加えることでスタイル模倣を防ぐツールGLAZEを開発した
- これにより、生成モデルが独自のスタイルを模倣することを防ぎ、アーティストは自分らしい芸術作品を守り、オリジナリティーあふれる作品制作に専念できる。
詳細
以下の論文のまとめです。
参考: https://arxiv.org/pdf/2302.04222.pdf
引用元を特記していない画像については上の論文からの引用になります。
背景
GLAZEは、画像生成モデルによる芸術家のスタイル模倣が問題となっている背景に対応するために開発されました。最近の画像生成モデルは、アーティストの作品サンプルを「ファインチューニング」することで、特定のアーティストの芸術的スタイルを模倣することができます。このような模倣は、オリジナリティーあふれる作品制作を妨げるだけでなく、アーティストの収入源を脅かす可能性もあります。
下図はファインチューニングについての概要図になります。
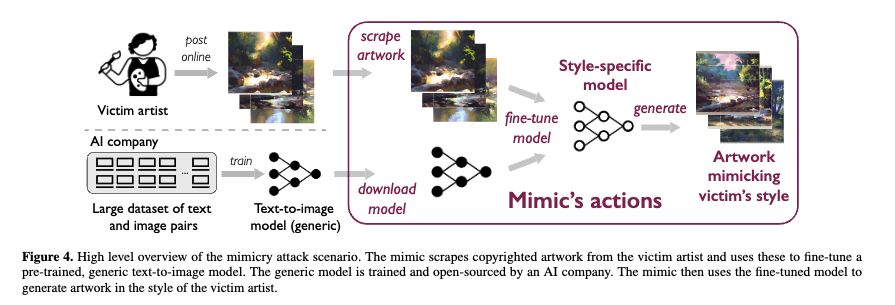
実際にスタイルを模倣した結果が下図になります。左の絵がオリジナルで、右の絵が左の絵を学習した画像生成モデルによって生成された絵です。

論文の中でアーティストの方に画像生成モデルについてインタビューした結果、画像生成モデルが自分の作品を学習することを「自分が長年努力して培ってきた絵のスタイルをAIに”食われる”」と表現していました。
GLAZE
そこで、シカゴ大学のチームによって、画像生成モデルによる芸術家のスタイル模倣が問題となっている背景に対応するために開発されたのがGLAZEです。
GLAZEは画像生成モデルがスタイル模倣ができないような微小な摂動(ノイズ)を元画像に付加します。人間には感知できないレベルの摂動のため作品のクオリティを下げることもなく、画像生成モデルによる学習を防止するというわけです。
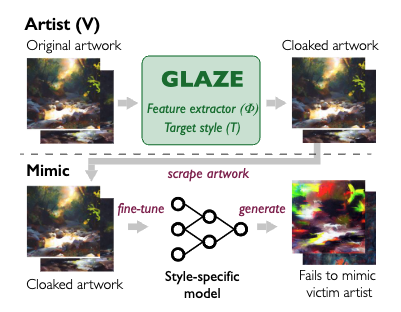
余談:似たような研究テーマにAdversarial Attackがありますが、これとは対象とするモデルが異なります。あちらは主に分類モデルを騙す手法です。
以下ではGLAZEについて詳しくまとめたものを記述しています。
問題設定
アーティストを以下のように定義します:
- 絵(作品)を描いて生計を立てている人
- 自分の作品をオンラインで共有して宣伝したい
- 生成モデルに自分のアートスタイルを模倣されたくない
- 適度な計算資源を利用でき、オンラインに投稿する前にローカルで作品の画像に摂動を加えることができる
- 公開されている画像生成モデルの特徴抽出器にアクセス可能(ホワイトボックス問題)
次に、ミミックを以下のように定義します:
- 目標は、txt2imgの画像生成モデルを訓練し、被害者のスタイルであらゆる主題の高品質な作品を生成すること
- Stability AIやOpenAIなどの資金力のあるAI企業や、被害者のアーティストのスタイルに興味を持つ個人
- 大規模なデータセットで十分に訓練された一般的なテキストから画像へのモデルの重みにアクセスできる
- ターゲットアーティストのアート作品にアクセスできる
- 大きな計算能力を持つ
- 我々の保護ツールを知っていて、適応的な対策を展開できる
アーティストとミミックは共通のモデルを利用していると仮定しているみたいです(ちなみにStable Diffusionを想定)。
なのでミミック側が非公開のモデルを利用していた場合、アーティストはGLAZEを利用しても防ぐことはできないかもしれません。ただ、それを克服した普遍的な摂動を生成する手法も今後考えているみたい。
画像生成モデルについて
GLAZEのアルゴリズムを説明する前に、画像生成モデルの基礎知識を説明します。
最近めっちゃすごくてめっちゃ使われているStable Diffusionは入力画像にノイズを段階的に付与して、今度はノイズを段階的に除去する作業を行い、元の入力画像を再現することを目的として学習していると言われています。

(引用: https://lilianweng.github.io/posts/2021-07-11-diffusion-models/)
あながち間違っていないのですが、実際は少し異なります。Stable DiffusionはLatent Diffusionというモデルを基に設計されているみたいで、以下のようなアーキテクチャになっています。
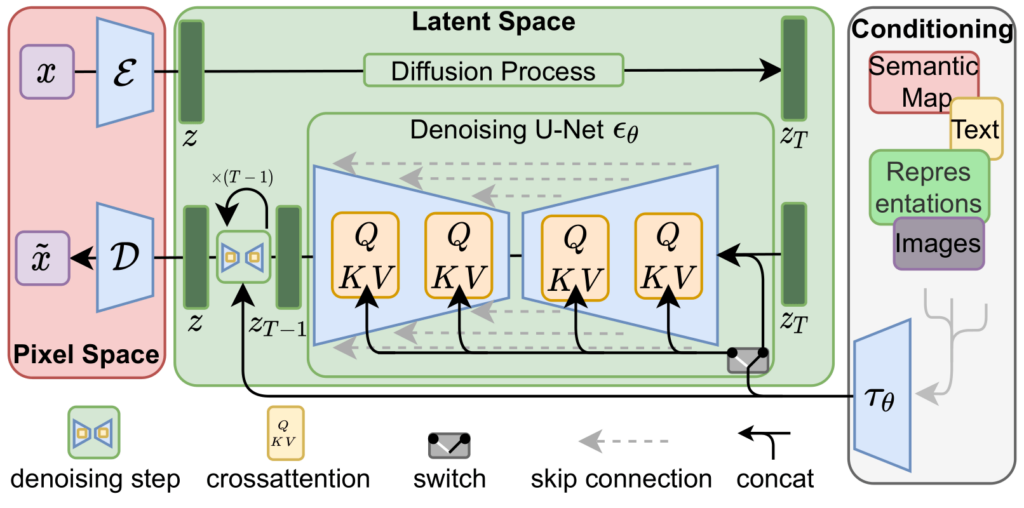
(引用: https://wonderhorn.net/column/stabdifpaper.html)
左上の$x$が入力画像のことですが、なんか$\mathcal E$ってやつを通って$z$に変換されていますね。この$z$を潜在表現と呼び、$x$よりサイズの小さいベクトルとなります。
どうしてこんなことをしているかと言うと、扱いやすくするためです。詳細は省きます。
で、Stable Diffusionが実際にノイズを付与したり除去したりしているのは$x$に対してではなくて、この$z$に対してなんです。Stable Diffusionは$z$を弄っている、これ重要。
先ほどの$\mathcal E$はエンコーダ、その下にある$\mathcal D$はデコーダと呼び、この二つはセットでオートエンコーダと呼ばれています。オートエンコーダは下図のように、入力画像を一度圧縮したあと復元するようなモデルになっています。
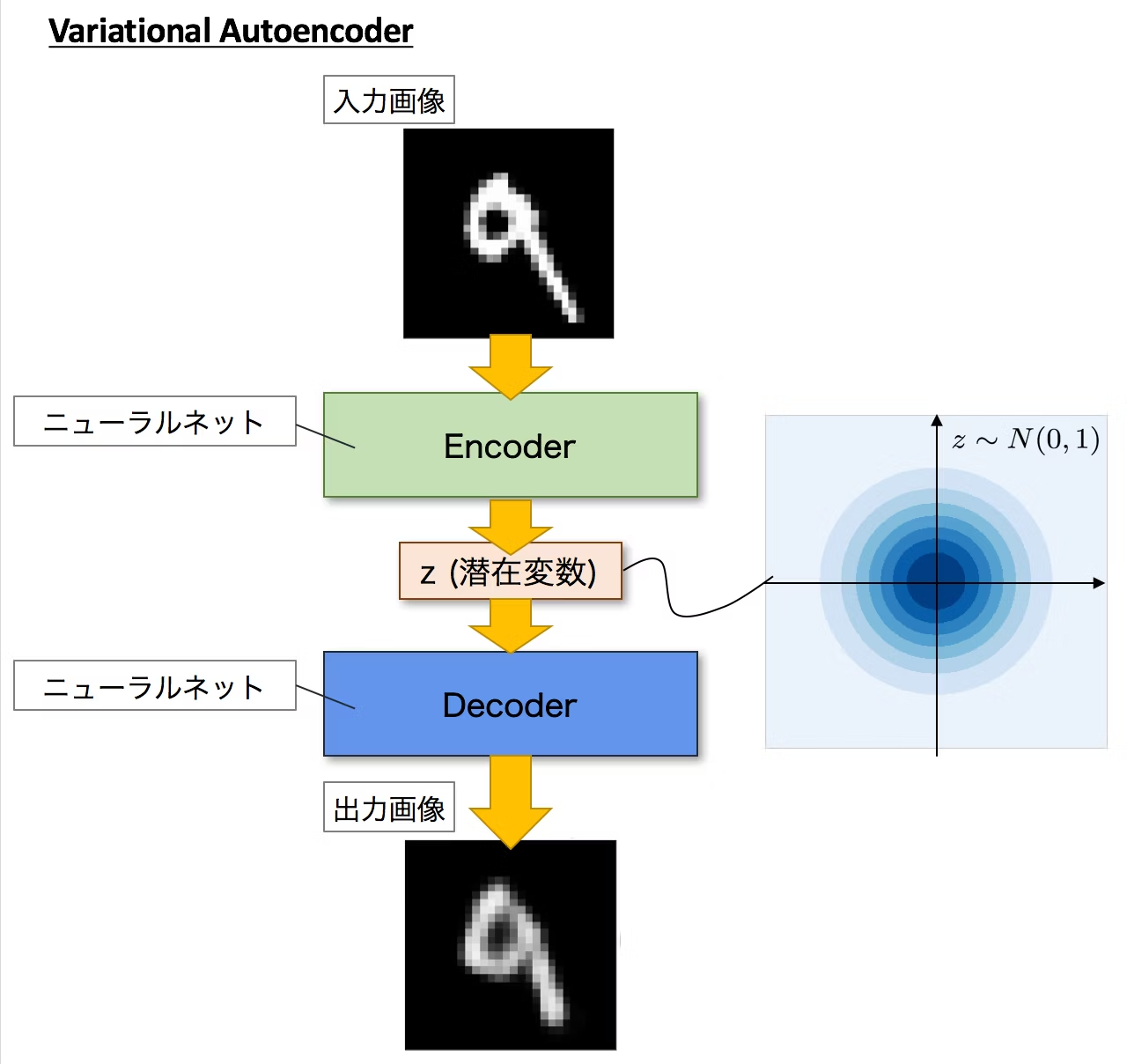
(引用: https://qiita.com/kenmatsu4/items/b029d697e9995d93aa24)
この$z$ですが、t-SNEなどで圧縮することで二次元平面にプロットして可視化することができます。
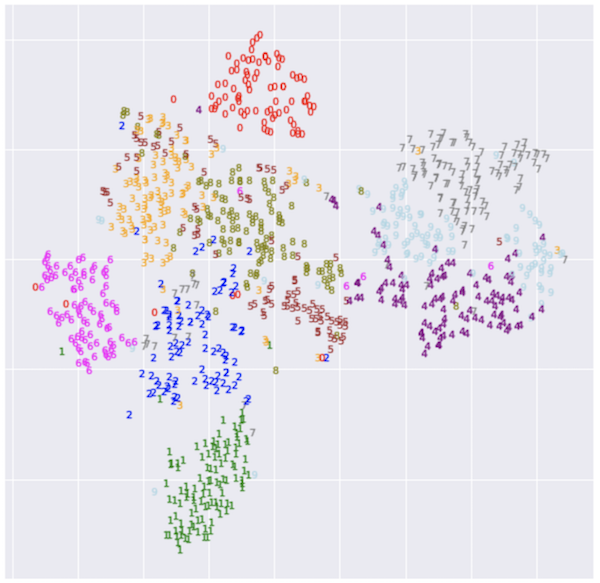
(引用: https://www.sambaiz.net/article/213/)
上の画像は潜在空間を表しているといえ、同じ数字や似ている数字の潜在表現$z$が近いところに配置されていていることがわかります。つまり、潜在空間は画像のスタイルをうまいことマッピングしている空間といえるのです。
以下ではこの潜在空間のことを特徴空間と呼びます(この2つが明確に分けられているのか曖昧)。
GLAZEのアルゴリズム
では、GLAZEのアルゴリズムについて説明していきます。
GLAZEの目的は画像のスタイルを維持したまま、モデルの特徴空間におけるスタイル特徴を動かすことです。つまりは「この絵は印象派だよ!(本当はキュビズムだけど)」とモデルを騙すことを目指します。
ただ、特徴空間上のスタイル特徴を(直接)解析するのは難しいです。
そこで、著者らはStyle transfer(画像変換)を用いています。Style transferは、下図のように、ある画像を異なるスタイルを持つ新しい画像に変換する技術です。

(引用: https://harkerhack.com/pytorch-style-transfer/)
Style transferをどのように活用しているのかを以下の図を参考にして説明します。
まず、オリジナル画像($x_{original}$)からStyle transferを用いて別のスタイルの画像($x_{target}$)を作成します。
GLAZEは$x_{target}$のスタイル特徴に寄せながら$x_{original}$のような画像を作成します。つまり、見た目は$x_{original}$のままだけど、それから得られる特徴表現は$x_{target}$のものである画像(Cloaked artwork)を作成します。
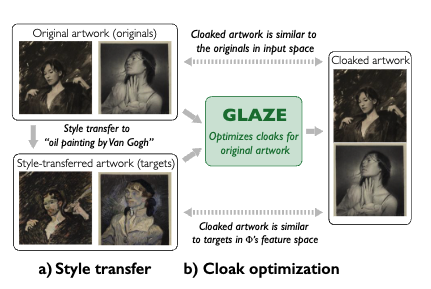
では、具体的にクロークをどのようにして求めているのか。それは以下の最適化問題を解くことで実現しているみたいです:
\underset{\delta_x}{min}\ Dist(\Phi(x+\delta_x),\Phi(\Omega(x,T))), \tag{1}\\
subject\ to\ |\delta_x|<p
$x$のスタイルをターゲットスタイル$T$に変換することを$\Omega(x, T)$と表現します。
$\Phi$はテキストから画像への生成タスクで一般的に使用される汎用画像特徴抽出器、$Dist(.)$は2つの特徴表現の不一致を計算、$|\delta_x|$はクロークによって生じる知覚的摂動、$p$は知覚的摂動の予算です。
つまり、$x_{target}$の特徴表現に似た特徴表現を得られる$x_{original}+\delta_x$となる最小の摂動$\delta_x$を求めているわけです。ちなみに$p$が大きければ大きいほどGLAZEの効果は大きくなりますが、オリジナルの画像のクオリティを落としてしまいます。
これで、キュビズムの絵を練習していたと思っていたら実は印象派の模倣練習でした。そんな感じの騙しをAIに対して行うことができます。
ここで、GLAZEの詳細設計を紹介します。
被害者アーティスト$V$が与えられたとき、Glazeはオンラインで共有される$V$の作品のセット$X_V$、画像特徴抽出器$\Phi$、Style transferモデル$\Omega$、および摂動予算$p$を入力として受け取ります。
Stpe1: ターゲットスタイルを選択する
スタイル模倣を騙すためのターゲットスタイルを選択する際、視覚的に異なるものを選択した方が効果的です。また、アーティストが模倣を避けるために最大限の力を発揮できるのは、すべての作品を同じターゲット$T$に向けて一貫してスタイルクロークしている場合です。
GLAZEは新規ユーザーに対して、$V$のスタイルと適度に異なるスタイル候補のセットから$T$をランダムに選択するアルゴリズムを採用しているそうです。
Step2: Style transfer
GLAZEは、事前に訓練されたStyle transferモデル$\Omega$を活用し、最適化のためにスタイル変換された作品を生成します。各作品$x\in X_V$とターゲットスタイル$T$が与えられたら、$x$をターゲットスタイル$T$にスタイル変換し、スタイル変換された画像$\Omega(x,T)$を作成します。
Step3: クローク摂動を計算
GLAZEは式(1)で定義される最適化に従って、クローク摂動$\delta_x$を計算します。本実装ではLPIPS(Learned Perceptual Image Patch Similarity)を採用。
また、実際にはペナルティ法を適用して式(1)を以下のようにしている:
\underset{\delta_x}{min}\ \|\Phi(\Omega(x,T),\Omega(x+\delta_x)\|^2_2 + \alpha \cdot max(LPIPS(\delta_x)-p,0) \tag{2}
ここで、αは入力摂動の影響を制御する。
また、ユークリッド距離は、特徴空間距離を計算するために使用される。
以上によって求められた$\delta_x$を付加したCloaked artworkを、アーティストはオンラインに投稿するわけです。
スタイル・クロークによる効果について
GLAZEのスタイル・クロークは、生成モデルにおける作品の特徴表現をシフトさせることで機能します。しかし、模倣された作品に顕著な影響を与えるためには、どの程度のシフトが必要なのだろうか。2つの理由から、スタイルのシフトが小さくても、スタイルの模倣を中断させる上で意味のある影響を与えることが示唆されています。
第一に、スタイル模倣に使用される生成モデルは、連続的な出力空間を持ちます。つまり、画像の特徴表現が変化すると、生成される画像も変化します。生成モデルは連続的な特徴空間を補間するように訓練されているため、モデルのスタイル表現が変化すると、アーティストと選択されたターゲットスタイルとの間の「ブレンド」である新しいスタイルが生成されます。
第二に、模倣された作品が有用であるためには、アーティストと適度な品質とスタイルの類似性を達成する必要があります。例えば、写実的な肖像画にゴッホのスタイルの太い油絵のようなブラシストロークが混じっているような場合です。この2つの要因が、GLAZEがより困難なシナリオで成功し、顔認識用のクローキングツールに成功する対抗手段(敵対的訓練など)に対して堅牢であることの要因となっています。
結果のダイジェスト
下図のように、GLAZEによって生成モデルはターゲットスタイルを学習してしまっており、オリジナルの作品のスタイルを模倣できていないことが分かります

より困難なシナリオの場合も検証している。
アーティストとミミックの使用する特徴抽出器が異なる場合でもGLAZEによる保護は成功したことを示している(下図の左)。
また、25%の作品をクロークした場合でもアーティストは十分に保護できていると評価したそう(アーティスト評価PSRが87.2%)。
