この記事では企業で ChatGPT や Claude などの LLM を導入する際に必要となる「自社データの活用(RAG の構築)」について、その背景・目的・実現方法などについて解説します。
ChatGPT についておさらい
ChatGPT とは、OpenAI によって開発された自然言語処理技術を使用したチャットボットです。人間のような会話が可能であり、メールの作成、エッセイの執筆、コードの作成など、様々なタスクを支援することができます。2022 年 11 月の公開から 5 日で 100 万ユーザー、2 ヶ月で 1 億ユーザーを突破するスピードで広まり、SNS やニュースなどで大きな話題となりました。
ChatGPT は内部的には OpenAI が独自に開発した「GPT」と呼ばれる LLM(Large Language Models / 大規模言語モデル)を利用しています。OpenAI は 2022 年 11 月に GPT-3.5 を利用した「ChatGPT-3.5」を無料で公開し、2023 年 3 月にはより性能が向上した「GPT-4」がリリースされ、ChatGPT Plus(有料プラン:20 ドル/月)に課金したユーザーが利用できるようになりました。さらに 2023 年 11 月には ChatGPT-4 の次世代モデル「ChatGPT-4Turbo」のリリースが発表されるなど、製品の進化やその性能の向上はめまぐるしいものがあります。
企業内で ChatGPT を導入する動き
2023 年上旬から、国内の企業でも各社で競うように ChatGPT を導入する流れが加速しました。
ChatGPT の利用に対して補助を出す企業や ChatGPT をラップしたシステムを社内で構築する企業など、いずれも社員に広く ChatGPT を利用させ、業務の改善や革新を促すことが目的でした。
以下にその一部を記載します。
- mofmof:
【全社員対象】ChatGPT Plus や OpenAI API を活用した新しい働き方を創る第一歩として、AI サービス月額利用料補助制度を開始 | 株式会社 mofmof のプレスリリース(2023/03/28) - キャンジョ:
【キャンプを AI が支える】キャンプ女子が全社に ChatGPT 導入、新しい時代のキャンプ体験を提供 | キャンプ女子株式会社のプレスリリース(2023/03/30) - ミラティブ:
ミラティブ、全社員を対象に「ChatGPT Plus」の月額利用料を全額補助する福利厚生を導入 今後のサポート強化も予定 | 最新ニュース | 株式会社ミラティブ(2023/03/22) - サイバーエージェント:
ChatGPT で広告運用の実行スピードを大幅短縮する「ChatGPT オペレーション変革室」を設立 ~ 「ChatGPT」を適切かつセキュアに活用することでオペレーション総時間の 30%を削減へ ~ | 株式会社サイバーエージェント(2023/04/04) - パナソニックホールディングス:
AI アシスタントサービス「PX-GPT」をパナソニックグループ全社員へ拡大 国内約 9 万人が本格利用開始 | 経営・財務 | 企業・経営 | プレスリリース | Panasonic Newsroom Japan : パナソニック ニュースルーム ジャパン(2023/04/14) - ベネッセホールディングス:
社内 AI チャット「Benesse GPT」をグループ社員 1.5 万人に向けに提供開始 | ニュースリリース| 株式会社ベネッセホールディングス(2023/04/14) - 大和証券:
大和証券、対話型 AI の「ChatGPT」を導入し全社員約 9,000 人を対象に利用を開始 - 日本経済新聞(2023/04/18) - 日本情報通信:
日本情報通信 ChatGPT で業務効率化とハピネス経営を推進 ~ 全社展開と多彩な取り組みで新時代の働き方を創出 ~|ニュース|日本情報通信株式会社(2023/04/21) - Hacobu:
Hacobu、「ChatGPT」と「GitHub Copilot for Business」を導入!会社丸ごと「生産性向上」プロジェクトを始動 | 株式会社 Hacobu(2023/04/24) - コムニコ:
業務における「ChatGPT」活用の導入を行い、生産性と創造性の向上を図ります ~社内導入をスムーズに行うための、活用推進チームを新設~(2023/05/01) - QUICK:
QUICK、「ChatGPT」全社導入を 5 月 22 日より決定 ~生成 AI の積極活用で顧客価値向上へ~|株式会社 QUICK のプレスリリース(2023/05/22) - こゆ財団:
宮崎県新富町の地域商社が ChatGPT を導入。AI を活用した業務の効率化でデジタル田園都市構想の実現を目指す | 一般財団法人 こゆ地域づくり推進機構のプレスリリース(2023/05/11) - 電通デジタル:
全社員が ChatGPT を利用開始(2023/05/29) - デコボコベース:
デコボコベース、人工知能チャットボット「ChatGPT」等を一部事業所で支援員の業務に導入、利用者一人一人に寄り添う支援業務へシフト | デコボコベース株式会社のプレスリリース(2023/05/31) - 京都銀行:
地域金融機関初 生成AI「ChatGPT」の試行導入決定! (2023/06/27) - 相鉄ホールディングス:
相鉄グループ社内で ChatGPT の試行をスタート【相鉄ホールディングス】 | 相鉄グループ(2023/12/11) - 心幸グループ:
心幸グループ、全正社員向け福利厚生として「ChatGPT Plus」利用料全額補助を導入 | 心幸ホールディングス株式会社のプレスリリース(2023/05/01)
意外と利用されない現実
急速に広まった企業による ChatGPT の導入ですが、その勢いは 2024 年に入り落ち着いてきました。日清食品 など一部の企業を除き、ChatGPT 導入の成功例や継続的な ChatGPT の利用例があまり出てきておらず、導入したがそこまで利用されることがなかった、という状況が多くの法人の中で発生しているようです。いくつか参考になる Web 上の情報を引用させていただきます。
生成 AI の導入が進む中、大きな課題となっているのが利用の定着です。利活用の促進策を実施していない企業に聞いたところ、導入形態で大きな差が出ました。希望者や部署などに限定的に導入した企業では約 7 割が「ほぼ使われていない」と回答しています。
全社的に導入している企業ではそれが 37%と 30 ポイント以上大幅に減るため、まずは全社的に導入することで社内の活用機運を後押しできると考えられます。全社で導入することで、利用機会が幅広く提供されて社内での認知が進み、活用のリテラシーが高い利用者を中心に自発的な利用が進むことなどが要因として挙げられます。
そのうえでどのような活用促進策を実施するのかも重要なポイントです。全社導入企業に聞いたところ、複数の促進策を実施することで、半数以上の社員が利用するようになり、ほぼ使われない状態も解消することがわかりました。
施策の具体的な内容は、「プロンプトの共有」「部門別ユースケースの作成」「専門部署やプロジェクトの発足」などが挙げられます。
※ ExaWizards 社のレポート から引用
しかし、足元では「どう使っていいのか分からない」「思ったほど役に立たない」といった、諦めの声も現場から漏れるようになった。
...
ChatGPT を導入する動きが日本企業で相次いだが、ヒアリングしてみると継続的に利用している社員の割合は 1 割程度にとどまるケースが多い。ChatGPT の本場である米国でも、2 割程度という指摘もある。
※ DIAMOND online から引用
利用されない理由
そしてその利用されない理由ですが、一番の要因は「社内データ」をコンテクストとして ChatGPT に渡さずに素の状態で利用の前提としている点です。
ChatGPT は社内のあらゆる業務で利用シーンが考えられますが、事前知識として社内データを与えられることの重要性を考察します。
-
社外 / 社内の問合せへの対応
社内規定・商品情報データベース・過去の顧客対応履歴と用いることで、問い合わせへの迅速かつ正確な回答を行う -
議事録の作成の自動化
社内用語を事前にインプットすることで、文脈を正しく判断した上で議事録を作成する -
販促物や提案書の文章の生成
製品や商品情報、さらに過去の類似の販促物や提案書を事前知識として利用しより価値を訴求する文章を作成する -
顧客アンケートの分析
例えばセミナー出席者へのアンケート、来店者へのアンケート、購読者へのアンケートなど結果をコンテクストとして利用する。またアンケート回答者の属性や対象の商品やサービスの情報も事前にインプットする -
広報によるプレスリリースやブログ配信
発信する取り組みや製品情報をコンテクストとして利用する。さらにブログの作成時に既存の Web ページの URL を与えておくことで適宜内部リンクを貼り SEO を強化する -
新規事業や新製品の企画の壁打ち
自社にどのようなアセットがあるか、現在どのような事業や商品があるかをインプットしておくことで、より深く議論を展開する
... など、ルーティンワークを改善・効率化するだけでなく、深い思考が必要な業務、新規性が求められる現場などいずれのシーンでも ChatGPT に自社の情報を与えることが重要だと考えられます。
逆に、そのままの ChatGPT を導入し社員に利用を促している企業では、こういったことが無い/制限される状態で LLM を活用しようとしてるため、必然的に利用シーンが限定されていくはずです。
もともと ChatGPT は Web 上の情報をもとに学習しており、一般的な情報やオープンな分野では深い知識を有しています。そのため、素の ChatGPT を導入している会社では以下のようなタスクでのみ ChatGPT が利用されている状況だと考えられます。
- 英語や中国語などの翻訳
- 文章の校正や誤字脱字チェック
- Excel などの関数の提示やプログラミングの自動化
- 長文で書いた内容の要約
すると次第に「ここで ChatGPT を使おう」という考えも次第に薄れていき、もともと期待されていた利用率には届かず、一部の社員だけが細々とと利用を続けている状況になるのも仕方がないことかと思われます。
必要な仕組み
では社内データを ChatGPT などの LLM に与えたうえで回答を生成させるには何が必要なのでしょうか? こういった仕組みは RAG (Retrieval-Augmented Generation) と呼ばれます。
RAG のプロセス
RAG を用いて ChatGPT などの LLM と対話するプロセスは以下の 2 つに分けられます。
- 検索(Retriever)
- ユーザーからの質問や指示のテキストを受け取り、ベクトルデータベースから関連する情報を検索します。
- ベクトル検索を用いて意味的に関連性のある情報を特定する方法や、キーワード検索とベクトル検索を組み合わせたハイブリッド検索が、その効果的な取り組みとして広く採用されています。
- 生成(Generator)
- もともとのユーザーのインプットと 1.で取得した関連する情報を合わせて LLM に送ります。
- LLM が生成した結果を回答としてユーザーに表示します。
RAG 構築の詳細
上記プロセスはざっくり 2 つの流れで説明しましたが、これを実現するためには様々な要素を用意する必要があります。
このセクションでは以下に図を用いつつ説明します。
※ 黒いアイコンは最低限必要な要素、青いアイコンは社内での継続的な運用を見据えた際に考慮したい要素です。
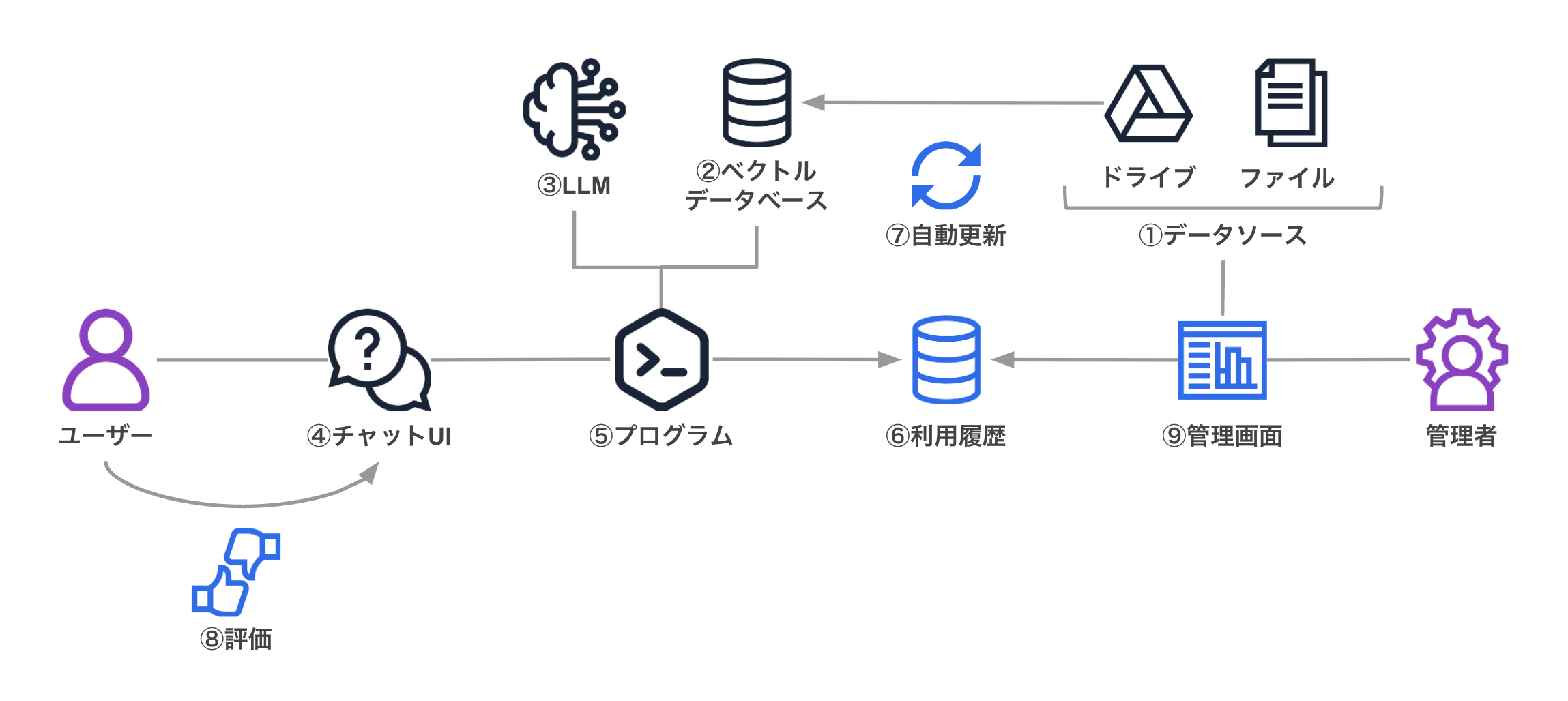
- ① データソース
- RAG で LLM に渡すコンテクストとして用いたい社内情報です。
- 各種テキストファイル、CSV などの表形式のファイル、社内データベース、ドライブ、各種 SaaS、チャットツールの履歴 .. など様々なデータやシステムが候補に上がります。
- これらの中から目的に併せて必要なものを選択します。内容の正しさや正確さを意識することはもちろんですが、RAG は与えるデータソースが多すぎると精度が出にくいため、情報の取捨選択という観点も重要です。
- ② ベクトルデータベース
- データソースの情報をベクトル形式で保存します。
- 文字列が合致しているかではなく、意味が近いものを探す(スコアを計算してランキングする)ことができます。
- ベクトル化は埋め込み(embedding)と呼ばれ、このためのモデルは代表的な text-embedding-ada-002 などを含め様々あります。
- ③ LLM
- ユーザーの入力とベクトルデータベースからの結果を合わせて LLM に入力します。
- OpenAI の GPT3.5 や GPT4、Anthropic の Claude2 や Claude3、Meta の Llama2 などから、性能・速度・料金といった項目のうち優先されるものに合わせて選択します。
- ④ チャット UI
- 社員が実際に質問や指示を入力してその回答を表示する UI です。
- 業務に自然に溶け込むように Teams や Slack から利用できるようにしたり、ポータルサイトや掲示板に埋め込むことで目につきやすく利用しやすくする、といった工夫をすることが考えられます。
- ⑤ プログラム
- ユーザーの入力からベクトルデータベースに検索するためのベクトルを作成(埋め込み/embedding)しベクトルデータベースに問合せ、結果を LLM に送信します。
- 次項以降の機能をもたせる場合はそれらの処理を行うプログラムも必要になります。
- ⑥ 利用履歴
- 企業内部では誰がどのようにどの程度このシステムを利用したか、ログを残しておくことが非常に重要です。
- 不適切な入力や私的な利用など不正な利用がされていないかをモニタリングしてガバナンスを効かせることに繋がります。
- よく利用している人の利用方法を参考にあまり利用していない人の利用を促進することが考えられます。
- ⑦ 自動更新
- ドライブや SaaS に貯まる情報、もしくはチャットツールに蓄積される会話履歴などをデータソースとする場合、時間の経過にともないベクトルデータベースの内容が陳腐化してしまいます。
- 外部ツールの API などと自動的に連携し、定期的に情報をアップデートする仕組みで手動の更新作業の低減や作業漏れといった問題を解決できるとより好ましいです。
- ⑧ 評価
- 質問に対するアウトプットがどの程度有用だったか、利用したユーザーからの評価を受け付けられると、それを元に上記 ①~⑦ を改善することができるようになります。
- Ragas のような RAG パイプラインそのものを評価するような仕組みもあります。
- ⑨ 管理画面
- 最後に、管理者が ① データソース の管理、⑥ 利用履歴 や ⑧ 評価 の確認、各種設定などを行う際の管理画面の構築も運用を考えると必要になってきます。
- 最初は情報システム部など IT に詳しい方が構築・提供・管理を行っていたとしても、管理を各部署に移管したり、引き継ぎの効率性などの観点から専門知識がなくても運用できるようにしておきたいところです。
RAG 構築における注意点
メリットの多い RAG ですが、複数の注意点もあります。このセクションではそれら注意点について解説します。
ハルシネーション
ハルシネーションは、生成 AI が実際には存在しない情報や誤った情報を生成する現象です。
RAG システムでは、検索された情報が生成プロセスに影響を与えるため、不正確なデータソースが選択されるとハルシネーションのリスクが高まります。これを防ぐためには、データソースの質を厳格に管理し、信頼できる情報のみをシステムに供給することが重要です。データソースを厳選することはもちろん、データソースとなる社内資料などが更新された場合、更新された情報を RAG に反映させる必要があります。
応答時間
RAG システムでは、ベクトルデータベースを経由して情報を検索し、その結果を基に回答を生成します。このプロセスにより、応答時間が伸びる可能性があります。利用者が快適に使用するためには、応答時間の短縮が重要です。応答をストリーム化して ChatGPT のように回答が逐次表示されるようにする、検索と生成のプロセスを最適化するなどの対策が考えられます。
セキュリティ
RAG システムの構築にあたり、社内データを扱うためセキュリティは非常に重要な懸念事項です。
外部プロダクトを利用する場合は、データの取り扱いに関するヒアリングシートへの回答を依頼したり、データをなるべく保持しないような仕組み(例えば、ファイルをストレージに保管せずに直接ベクトルデータベースに保管するなど)を採用することが推奨されます。また、データの暗号化、アクセス制御、監査ログの管理など、セキュリティ対策を総合的に実施することが必要です。運用面でも個人情報を含むデータは RAG のソースとして利用しないといった方針も考えられます。
RAG 構築の方針
こういった RAG の仕組みを社内に構築するための方針は大きく 3 パターンに分かれます。
社内で開発する
社内にエンジニアリソースがある場合は自社で開発することが考えられます。
実際に少なくない数の企業で、RAG を構築した事例を技術ブログとして公開していて、自社開発を検討している方には参考になる内容かと思います。
- 社内用語集を気軽に質問できる SlackBot を作ってみた (RAG の応用アプリ) - ABEJA Tech Blog
- RAG を使った社内情報を回答できる生成 AI ボットで業務効率化してみた | DevelopersIO
- LangChain で社内チャットボット作ってみた
- ChatGPT に社内文書に基づいた回答を生成させる仕組みを構築しました - コネヒト開発者ブログ
- RAG で社内データを参照する Chat Bot 作ってみた!!(概要説明編)
- Vertex AI と ChatGPT で社内ナレッジを検索できるチャットボットを作ってみた - RevComm Tech Blog
- AWS 内で大規模言語モデルを利用できる Amazon Bedrock を使って作る RAG アプリケーション - クックパッド開発者ブログ - 社内データを活用したチャットボット(社内検索基盤)を作ってみる(Amazon Bedrock+ Amazon Kendra で作る AI サーチ&チャットシステム) | SAS Tech Blog
- OpenAI API 連携 Slack ボットに社内情報を回答させてみた #AWS - Qiita
- 実践 LangChain!RAG による特化 LLM システムの作り方 #Python - Qiita
- ChatGPT に自社データを組み込んで新しい検索体験を模索してみました| masa_kazama
メリット・デメリットも合わせて紹介します。
- メリット
- 社内の技術力向上やブランディングにつながる。
- 開発者とユーザーが近いため、両者が協力しやすく利用率を上げやすい。
- 好きな技術要素を選定し組み合わせて利用できる。
- デメリット
- エンジニアリソースが必要になる。
- 保守運用コストを社内で払い続けることになる。
- RAG の発展的な取り組みにチャレンジする場合は特に、機械学習や AI に明るいメンバーが必要になる。
外部の会社に開発してもらう
外部の開発会社に RAG の構築を依頼することも考えられます。まだあまり RAG の構築をメニューとして打ち出している会社は少ないですが、例えばクラスメソッドさんの以下のサービスなど、先進的な開発会社では対応が進んでいるようです。
クラスメソッド、社内問い合わせを効率化する「生成 AI チャットボット らくらく RAG 導入パック」提供開始〜最短 2 週間で構築・利用開始でき、エンタープライズレベルのセキュリティを実現〜 | クラスメソッド株式会社
- メリット
- エンジニアリソースが無くても RAG を構築できる。
- 追加開発がなければ保守運用コストは抑えられる可能性がある。
- デメリット
- ある程度の開発費用がかかる。
- 社内に RAG 構築の技術的なナレッジが貯まらない。
プロダクト(RAG SaaS)を導入する
すでに各種機能が SaaS として提供されているプロダクトを利用するという方針もあります。
- メリット
- 開発費用をかけずに利用できる。初期費用も数十万円 ~。
- 開発プロセスがないため、すぐに利用を開始できる。
- 複数の顧客の要望を受けて開発しており、汎用性が高い。
- デメリット
- 利用料が発生する(費用のロジックは各社の価格体系による)
- ベクトルデータベースなど、SaaS が内部的に利用している技術要素を選択することは難しい。