この記事は MIXI DEVELOPERS Advent Calendar 2022 20 日目の記事です。
前書き
GoogleCloud上で、rustでQUICのリレーサーバを作成するために、UDP Packetをたくさん受けとるために、コードを書いて試してみたので、その作業ログです。
コードはここに置いておきます
環境
環境は以下。
- Google Cloud Compute Engine VM インスタンス
- 受信サーバ
- c2 インスタンス 16 vCPU (not Tier_1 network)
- 送信サーバ
- 受信サーバと同一VPCの複数のインスタンスからudpを投げまくる
- 受信サーバ
計測はpacket per second(pps)を基準に検討しています。実際の数値自体はcoreの世代などの要因があり、あまり意味はありません。
ログ
recvfrom(revmsg) / recvmmsg
まずは std::net::UdpSocketのrecv_fromのloopでパケットを取得するところから。
let socket = UdpSocket::bind("0.0.0.0:3941").unwrap();
socket.set_read_timeout(Some(Duration::from_millis(20))).unwrap();
let mut buf = [0; 1500];
let mut received_count = 0;
loop {
match socket.recv_from(&mut buf) {
Ok(_) => {
received_count += 1;
}
Err(e) if e.kind() == io::ErrorKind::WouldBlock => {
continue;
}
Err(e) => {
log::error!("failed to receive a datagram: {}", e);
break;
}
}
}
これをベースに、変更していきます。
std::net::UdpSocketのrecv_fromの内部ではsystemcallのrecvfromを使っていて、recvmmsgを使った方がsystemcallの回数を減らせるはずなので、変更します。
rustでrecvmmsgを使うにはlibcを使う方法とlibcをwrapしているnixを使う方法がありますが、MultiHeadersなどの型を使えたり、unsafeを書かないで済むので今回はnixを使用します。
recvmmsgを使用するとmacosでのコンパイルが不可能になります。今回はGoogle Cloudのlinux上を想定しているので、このまま使います。
use nix::sys::socket::{
self, socket,
sockopt::RecveTimeout,
AddressFamily, SockFlag, SockType, SockaddrIn,
};
use nix::sys::time::TimeVal;
use std::io::IoSliceMut;
let sock_addr = SockaddrIn::from_str("0.0.0.0:3941").unwrap();
let raw_socket = socket(
AddressFamily::Inet,
SockType::Datagram,
SockFlag::empty(),
None,
).unwrap();
socket::setsockopt(raw_socket, ReceiveTimeout, &TimeVal::new(0, 20_000)).unwrap();
socket::bind(raw_socket, &sock_addr).unwrap();
let mut msgs = std::collections::LinkedList::new();
let mut buf = [[0u8; 1500]; BATCH_NUM];
msgs.extend(buf.iter_mut().map(|b| [IoSliceMut::new(&mut b[..])]));
let mut data = MultiHeaders::<SockaddrIn>::preallocate(msgs.len(), None);
let mut received_count = 0;
loop {
match socket::recvmmsg(raw_socket, &mut data, msgs.iter(), MsgFlags::empty(), None) {
Ok(res) => {
let receives: Vec<RecvMsg<SockaddrIn>> = res.collect();
received_count += receives.len();
}
Err(e) if (e == Errno::EAGAIN) || (e == Errno::EWOULDBLOCK) => {
continue;
}
Err(e) => {
log::error!("failed to receive a datagram: {}", e);
break;
}
}
}
実際に複数のインスタンスからudp pakcetを送信し、一秒間あたりに受信できたパケット数を計測します。udpのpayloadが100bytesと1,000bytesのそれぞれの結果は以下の通り。
| recvfrom | recvmmsg | |
|---|---|---|
| 100 bytes payload | 724±37.0 kpps | 1,010±25.0 kpps |
| 1000 bytes payload | 596±18.1 kbpp | 917±44.2 kpps |
multi thread
受信側をスケールするためにパケットの処理をマルチスレッドで行います。それぞれのスレッドが同じをportをバインドするために、socketにSO_REUSEPORTオプションを付与する必要があります。
let mut handles = Vec::<std::thread::JoinHandle<()>>::new();
for _ in 0..thread_num {
let jh = thread::spawn(move || {
let sock_addr = SockaddrIn::from_str("0.0.0.0:3941").unwrap();
let raw_socket = socket(
AddressFamily::Inet,
SockType::Datagram,
SockFlag::empty(),
None,
).unwrap();
// コレ必要
socket::setsockopt(raw_socket, ReusePort, &true).unwrap();
socket::setsockopt(raw_socket, ReceiveTimeout, &TimeVal::new(0, 20_000)).unwrap();
// ---- (以下、略) -----
});
handles.push(jh);
}
で待ち受けることでupdの受信可能数は以下のようになりました。
| single thread(再掲) | 2 thread | 4 thread | 8 thread | |
|---|---|---|---|---|
| 100 bytes payload | 1,010±25.0 kpps | 1,583±45.6 kpps | 2,098±74.8 kpps | 2,407±50.8 kpps |
8 threadの時点でかなりsoftirq(si)が大きく、NICからsocket bufferにデータを移す部分でCPUが使われており、ほぼ全てのCPUが使われている模様。
%Cpu0 : 1.7 us, 36.9 sy, 0.0 ni, 9.6 id, 0.0 wa, 0.0 hi, 51.8 si, 0.0 st
%Cpu1 : 1.7 us, 34.2 sy, 0.0 ni, 5.4 id, 0.0 wa, 0.0 hi, 58.7 si, 0.0 st
%Cpu2 : 2.3 us, 19.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 78.7 si, 0.0 st
%Cpu3 : 2.0 us, 27.5 sy, 0.0 ni, 5.7 id, 0.0 wa, 0.0 hi, 64.8 si, 0.0 st
%Cpu4 : 2.4 us, 27.9 sy, 0.0 ni, 5.1 id, 0.0 wa, 0.0 hi, 64.6 si, 0.0 st
%Cpu5 : 1.7 us, 25.4 sy, 0.0 ni, 4.3 id, 0.0 wa, 0.0 hi, 68.6 si, 0.0 st
%Cpu6 : 0.7 us, 35.9 sy, 0.0 ni, 2.4 id, 0.0 wa, 0.0 hi, 61.0 si, 0.0 st
%Cpu7 : 1.0 us, 20.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 79.0 si, 0.0 st
receive buffer errors
薄々気づいていると思うのですが、今回のテスト、sender側がreceiverのcapacityを考えずに送りつけているため、receiverはpacketを受けきれていません。 netstat でみてみると、
> netstat -s --udp
IcmpMsg:
InType3: 3
InType8: 113
OutType0: 113
OutType3: 6645
Udp:
2321146375 packets received
7671142809 packets to unknown port received
998873541 packet receive errors
440 packets sent
998873541 receive buffer errors
0 send buffer errors
UdpLite:
IpExt:
InOctets: 1643590198263
OutOctets: 5228567
InNoECTPkts: 10991231611
receive buffer errorsの値がかなり伸びています。NICのRX queueの中に溜まったパケットをsocketのbufferに移動しようとした際に、空きが足りずコピーしきれずに落としてしまったパケットの数です。
(ちなみに、packets to unknown port received はbindしているsocketがおらず、宛先不明で破棄されたパケットの数で、packet receive errorsは receive buffer errorsの他に bad checksum なんかの他のエラーも含んだ数のようです)
この問題を緩和するためにバッファサイズを前もって大きくしておくカーネルパラメータがあります。
net.core.rmem_default
net.core.rmem_max
rmem_defaultがsocketを作成した際にデフォルトで使用されるsocket バッファのサイズで、rmem_maxが最大で指定することができる値です。最大で指定することができるという書き方から分かる通り、バッファサイズはsocketに個別に指定することが可能です。
defaultの値を一律大きくすると全てのudp socketに影響が出るので、socket側にオプションとして与えられる場所があるなら、socket作成時にsetsockoptで渡すのが良い気がします。
std::net::UdpSocketには個別のsetsockoptを叩くインターフェースが見つかりませんでしたが、nixを使用している場合は以下の方法で設定できます。
socket::setsockopt(raw_socket, RcvBuf, &(67108864 as usize)).unwrap();
packet flow
パケットの流れはを図に表すと以下になります。
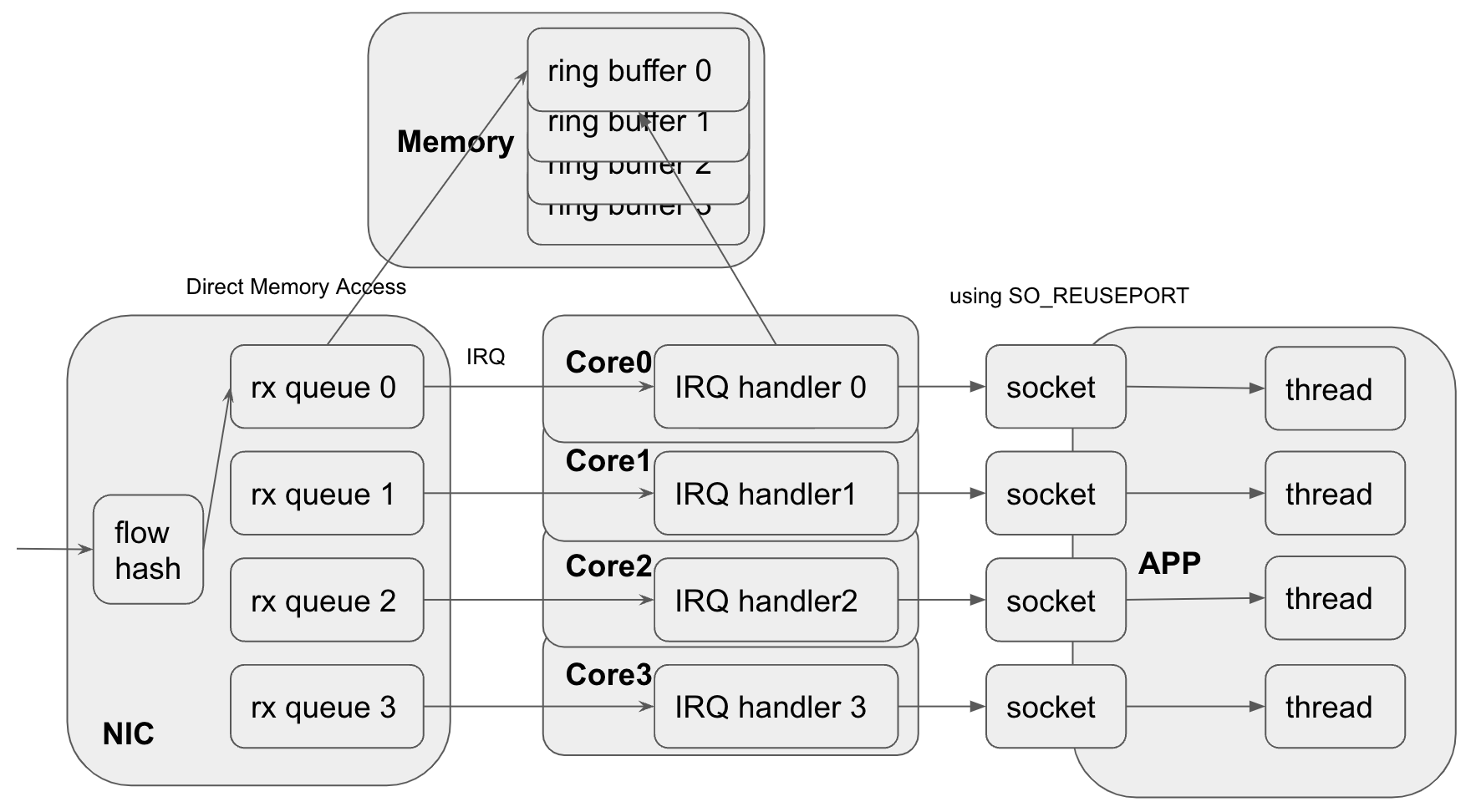
Google Cloud のVM上のNICは、ethtoolでrx-flow-hashを表示しようとしてみても表示することはできませんが、別のインスタンスの異なるportからパケットを送信している状況でのNICの状態をethtoolで確認してみると、複数のqueueが満遍なくリクエストを受け付けているのがわかり、hashの要素に送信元IPだけではなく、送信元portも含まれているのがわかります。
NICはRSSが有効で、同じフローからのパケットは複数あるRX queueから同じところに流れ、対応するCoreが処理を行います。RPSは無効のため、netdev_max_backlogの変更はパフォーマンスに意味がなさそう。
あと改善するとしたらsocketが動いてるcoreをIRQ handler (socket)が処理しているのと同じcoreに紐付けてキャッシュ効率とかを上げれば良いかもしれないが、今回はここまで。
まとめ
特に結論があるわけではないですが、rustでudpパケットの操作方法を確認しました。