ラズパイから温度データをIoT Analyticsに送ってそれをQuickSightで可視化してみました。
構成図

全体の流れ
ラズパイのGreengrass CoreからデータをIoT Coreにパブリッシュ
↓
IoT CoreからRuleでIoT Analyticsのチャネルにプッシュ
↓
パイプラインでチャネルからデータを引いてきて加工やフィルタリングした後にデータストアにプッシュ
↓
あらかじめ定義したSQL処理が定期実行されて結果がデータセットとして出力
↓
それをQuickSightで可視化
ラズパイのGreengrass CoreからデータをIoT Coreにパブリッシュ
ラズパイのGreenGrass Coreから、デプロイしたLambdaでGreengrassSDKを使ってMQTT通信でIoT Coreに温度データを定期的に送信します。温度データはPython組み込み関数のrandom.gauss()を使います。
※例えばrandom.gauss(x, y)で平均がx、標準偏差がyの正規分布からランダムで浮動小数点型の数を返します。場合によってはstr()で文字列に変換します。
import logging
import platform
import sys
from threading import Timer
import greengrasssdk
# Minagawa added
import random
# Setup logging to stdout
logger = logging.getLogger(__name__)
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
# Creating a greengrass core sdk client
client = greengrasssdk.client("iot-data")
# Retrieving platform information to send from the Lambda function - Greengrass_HelloWorld_93ntT
my_platform = platform.platform()
def greengrass_hello_world_run():
try:
if not my_platform:
client.publish(
topic="minagawa/analyticsandquicksighttest", queueFullPolicy="AllOrException", payload='[{"temperature":'+str(random.gauss(35, 3))+'}]'
)
else:
client.publish(
topic="minagawa/analyticsandquicksighttest",
queueFullPolicy="AllOrException",
payload='[{"temperature":'+str(random.gauss(25, 3))+'}]'
)
except Exception as e:
logger.error("Failed to publish message: " + repr(e))
# Asynchronously schedule this function to be run again in 10 minutes
Timer(600, greengrass_hello_world_run).start()
# Start executing the function above
greengrass_hello_world_run()
# This is a dummy handler and will not be invoked
# Instead the code above will be executed in an infinite loop for our example
def function_handler(event, context):
return
IoT CoreからRuleでIoT Analyticsのチャネルにプッシュ
Cloudformationでの定義
IoT TopicRule
IoT Ruleですが、Cloudformationの世界だとTopicRuleと呼びます。下記のサンプルルールだとtemperatureが20より大きいデータをS3バケットとIoT Analyticsに投げるルールを定義しています。RuleDisabledをfalseにして作成すると最初からルールがEnabledな状態、つまり有効な状態になります。
AWSTemplateFormatVersion: '2010-09-09'
Resources:
MyTopicRule:
Type: AWS::IoT::TopicRule
Properties:
RuleName: 'ルール名'
TopicRulePayload:
RuleDisabled: 'true'
Sql: SELECT temperature FROM 'トピック名' WHERE temperature > 20
Actions:
- S3:
BucketName: Ref: MyBucket
RoleArn: !GetAtt MyRole.Arn
Key: Folder/To/Put/The/File/test.txt
- IoTAnalytics:
ChannelName: 'チャネル名'
RoleArn: Something::like::this
Ref
BucketNameでRefを使っていますが、これはCloudformation特有の関数です。このようにRef:MyBucketで定義すると<スタック名>MyBucket12ABC3D456EFGというようにランダムな文字列を自動でつけてくれるので文字かぶりを気にしなくて良くなります。
Fn::GetAtt
Fn::GetAttもCloudformationの組み込み関数の一つです。
Fn::GetAtt: [ logicalNameOfResource, attributeName ]という形式で書きます。上記の例の場合MyRoleという論理名を持ったリソースのArnという属性の値を返すという意味です。短縮形の!GetAttも使用できます。
上記の他にも組み込み関数は複数あります。組み込み関数に関しては日本語版の公式レファレンスがあるので参考にしてください。
RefやFn::GetAttの使い所などをまとめた記事:
コンソールでの作業手順
Createを押します。

ルール名と処理内容となるSQL文を記入しアクションの追加を押します。

IoT Analyticsにメッセージを送るを選択します

すでにIoT Analyticsのチャネルができている場合それを選びます。できてない場合は画像のように自動で作成することもできます。

この通り一連のIoT Analyticsの中身(チャネル、パイプライン、データストア、データセット)が作成されました。アクションの追加が終わったらルールの作成を押します。

ルールが作成できました。デフォルトだとdisabled状態になっているので右の…からenableを選んで有効にします。

Enabledになりました。これでIoT CoreからIoT Analyticsのチャネルへのプッシュが可能になります。

チャネル、データストア、パイプライン、データセットのCloudformationでの定義
チャネル
以下がCloudformationでチャネルを定義する際のYAMLファイルです。基本的に他のリソースから矢印が伸びる形になるのでチャネル自体の定義はかなりシンプルです。設定する項目といえば保存期間のRetention Periodくらいでしょうか。Tagsはメタデータをつけたいとき用です。
---
Description: "サンプルチャネルを作成"
Resources:
Channel:
Type: "AWS::IoTAnalytics::Channel"
Properties:
ChannelName: "チャネル名"
RetentionPeriod:
Unlimited: false
NumberOfDays: 10
Tags:
-
Key: "keyname1"
Value: "value1"
-
Key: "keyname2"
Value: "value2"
データストア
同様にデータストアのCloudformationファイルもシンプルです。基本的にデータをためるだけなので当然といえば当然ですね。
---
Description: "サンプルデータストアを作成"
Resources:
Datastore:
Type: "AWS::IoTAnalytics::Datastore"
Properties:
DatastoreName: "データストア名"
RetentionPeriod:
Unlimited: false
NumberOfDays: 10
Tags:
-
Key: "keyname1"
Value: "value1"
-
Key: "keyname2"
Value: "value2"
パイプライン
パイプラインは以下のように2つ以上のActivityで構成されています。またActivityはMath, AddAttributes, Filter, Lambdaなど全10種類あります。どのチャネルからデータを取るかを定義するChannelのActivity(一番最初にきます)と、どのデータストアにデータを渡すか定義するDatastoreのActivity(一番最後にきます)は必須です。またActivityを複数組み合わせる際はNextを使って処理の順番を定義していきます。またActivityは最大25個持てます。

---
Description: "サンプルパイプラインを作る"
Resources:
Pipeline:
Type: "AWS::IoTAnalytics::Pipeline"
Properties:
PipelineName: "パイプライン名"
PipelineActivities:
-
Channel:
Name: "アクティビティ名"
ChannelName: "チャネル名"
Next: "LambdaActivity"
Lambda:
Name: "LambdaActivity"
LambdaName: "Lambda名"
BatchSize: 1
Next: "AddAttributesActivity"
AddAttributes:
Name: "AddAttributesActivity"
Attributes:
key1: "attribute1"
key2: "attribute2"
Next: "RemoveAttributesActivity"
RemoveAttributes:
Name: "RemoveAttributesActivity"
Attributes:
-
"attribute1"
-
"attribute2"
Next: "SelectAttributesActivity"
SelectAttributes:
Name: "SelectAttributesActivity"
Attributes:
-
"attribute1"
-
"attribute2"
Next: "FilterActivity"
Filter:
Name: "FilterActivity"
Filter: "attribute1 > 40 AND attribute2 < 20"
Next: "MathActivity"
Math:
Name: "MathActivity"
Attribute: "attribute"
Math: "attribute - 10"
Next: "DeviceRegistryEnrichActivity"
DeviceRegistryEnrich:
Name: "DeviceRegistryEnrichActivity"
Attribute: "attribute"
ThingName: "thingName"
RoleArn: "arn:aws:iam::<your_Account_Id>:role/Enrich"
Next: "DeviceShadowEnrichActivity"
DeviceShadowEnrich:
Name: "DeviceShadowEnrichActivity"
Attribute: "attribute"
ThingName: "thingName"
RoleArn: "arn:aws:iam::<your_Account_Id>:role/Enrich"
Next: "DatastoreActivity"
Datastore:
Name: "DatastoreActivity"
DatastoreName: "データストア名"
データセット
データセットはSQLデータセットとコンテナデータセットが存在します。SQLで足りない場合にコンテナ化したJupyterNotebookのPythonでデータセットの作成ができます。
SQLデータセットは対象となるデータストア名、CRON形式で書いた定期実行の周期、出力先となるデータセット名を定義します。ちなみに出力形式はCSVに限ります。
---
Description: "SQLデータセットの作成"
Resources:
Dataset:
Type: "AWS::IoTAnalytics::Dataset"
Properties:
DatasetName: "データセット名"
Actions:
-
ActionName: "SqlAction"
QueryAction:
SqlQuery: "select * from Datastore(対象となるデータストア名)"
Filters:
-
DeltaTime:
OffsetSeconds: 1
TimeExpression: "timestamp"
Triggers:
-
Schedule:
ScheduleExpression: "cron(0 12 * * ? *)"
RetentionPeriod:
Unlimited: false
NumberOfDays: 10
Tags:
-
Key: "keyname1"
Value: "value1"
-
Key: "keyname2"
Value: "value2"
コンテナデータセットは処理対象にデータストアではなくSQLデータセットをとるところに注意が必要です。こちらも定期実行ができますが、対象となるSQLデータセットの更新をトリガーにすることもできます。
---
Description: "コンテナデータセットの作成"
Resources:
TriggeringDataset:
Type: "AWS::IoTAnalytics::Dataset"
Properties:
DatasetName: "トリガーとなるデータセット名"
Actions:
-
ActionName: "アクション名"
QueryAction:
SqlQuery: "select * from Datastore"
ContainerDataset:
Type: "AWS::IoTAnalytics::Dataset"
DependsOn: TriggeringDataset
Properties:
DatasetName: "コンテナ処理の対象となるデータセット名"
Actions:
-
ActionName: "アクション名"
ContainerAction:
Image: "<アカウントID>.dkr.ecr.us-east-1.amazonaws.com/sampleimage"
ExecutionRoleArn: "arn:aws:iam::<アカウントID>:role/ExecutionRole"
ResourceConfiguration:
ComputeType: "ACU_1"
VolumeSizeInGB: 10
Variables:
-
VariableName: "変数1(※変数の追加はしてもしなくてもいい)"
StringValue: "文字列1"
-
VariableName: "変数2"
DoubleValue: 1
-
VariableName: "変数3"
DatasetContentVersionValue:
DatasetName: "データセット名"
-
VariableName: "変数4"
OutputFileUriValue:
FileName: "ファイル名"
Triggers:
-
Schedule:
ScheduleExpression: "cron(0 12 * * ? *)"
-
TriggeringDataset:
DatasetName: "SQL処理に続けてコンテナ処理をしたい場合、ここで対象となるデータセット名を記載する。そのデータセットにSQL処理が走るとそれがトリガーになる"
さらに細かい設定を足したい場合
日本語未対応ですが公式のドキュメントを参照してください(日本語版のドキュメントから行くとレファレンスが表示すらされないので注意)。例えばデータセットをS3に保存する場合の定義なども載っています。
IoT Analyticsのレファレンス:
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/AWS_IoTAnalytics.html
AWSサービス全体のレファレンス:
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/template-reference.html
データセットをS3に保存する場合:
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-iotanalytics-dataset-s3destinationconfiguration.html
パイプラインでチャネルからデータを引いてきて加工やフィルタリングした後にデータストアにプッシューコンソールでの手順
チャネルとデータストアの設定
チャネルとデータストアはCloudformationのYAMLファイルで見た通り入力先と出力先を選ぶだけなので省きます。データの保存先を選ぶ箇所だけ見てみます。
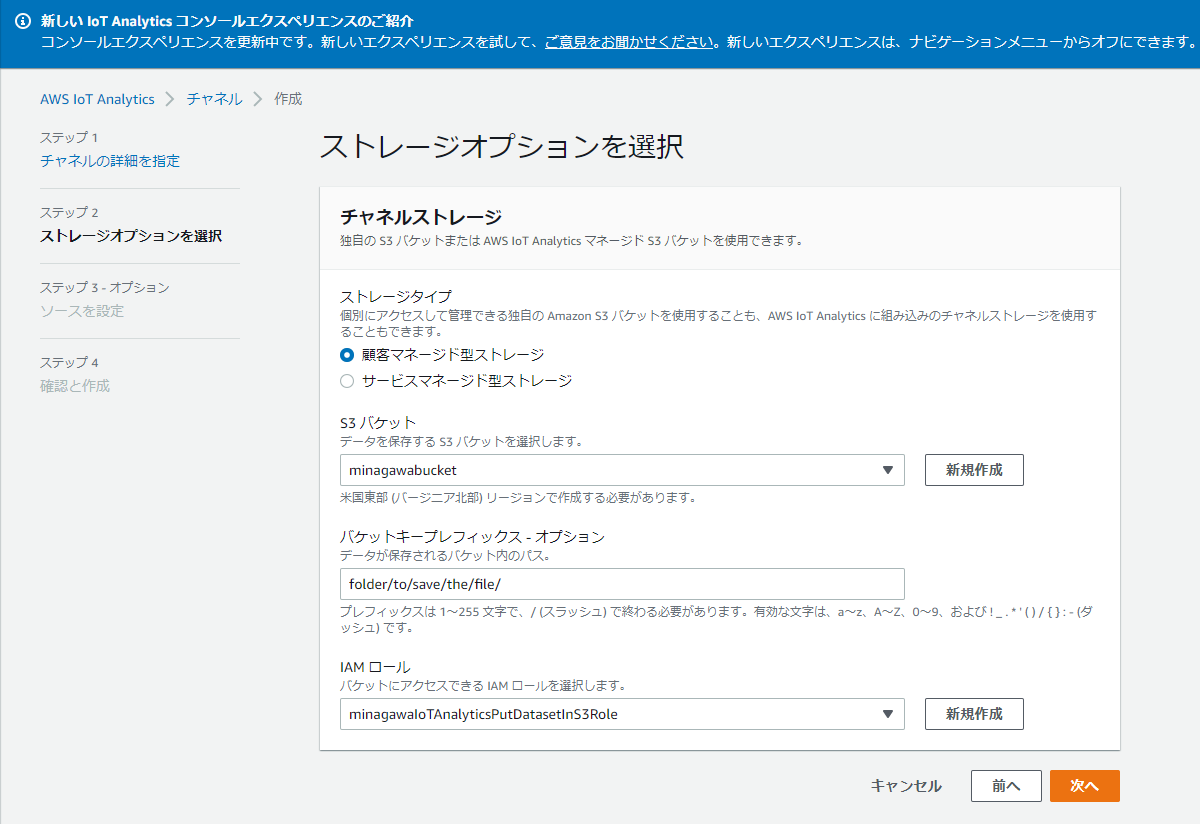
下の丸を選ぶとIoT Analytics内に保存されます。保存期間も指定できます。

保存先にS3を選ぶこともできますが、ファイル形式を指定できません。Base64でエンコードされ、gz圧縮が共生になります。IoT Analyticsは基本的にSageMakerやQuickSightにデータセットを提供するためのサービスということなのでしょう。
パイプラインの設定
パイプラインを作成を押します。

入力先と出力先(チャネルとデータストア)を選びます。

次にテストとなるデータをここで追加します。今回はtemperature:24.7といった感じのデータがラズパイから送られてくるのでそれに即して追加します。記入したら属性の追加を押します(すでにチャネルにデータがたまっている場合は自動で追加されています)。そしたら次へを押します。

8種類の処理の中から処理内容を追加します。個々の処理内容に関しては以下の公式資料を参考にしてください。アクティビティは最大25個登録できます。Cloudformationの箇所で見た通り入力先を指定するチャネルアクティビティと出力先を指定するデータセットアクティビティは必須なので実質23個アクティビティを登録できることになります。アクティビティの登録が終わったらパイプラインを作成を押します。


無事作成できました。

データセットの設定
ここではコンテナデータセットの設定は行わずSQLデータセットの設定のみ行います。
データセットの作成を押すとタイプが選べますが、上のSQLデータセットを選びます。

データセット名と入力ソースを選びます。
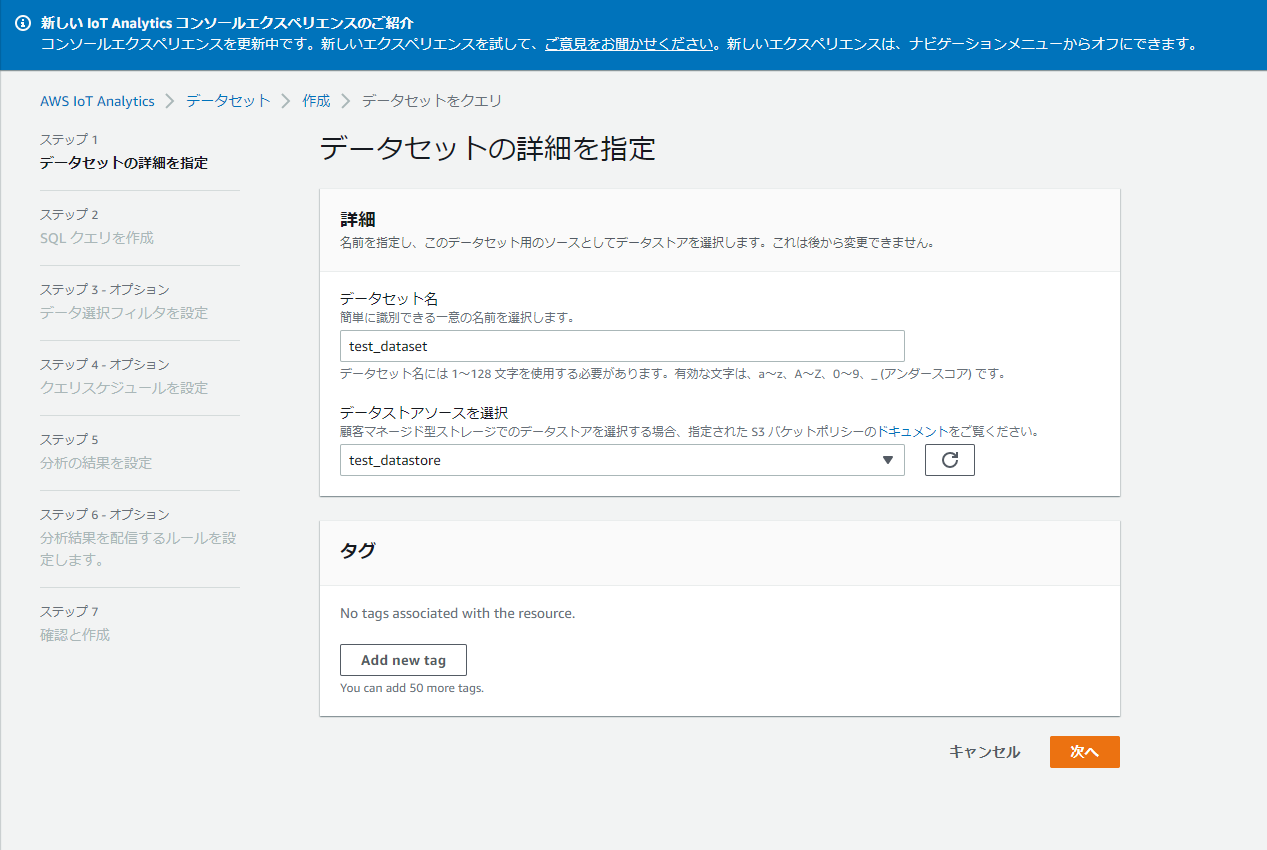
SQL文を書きます。(詳しくは https://docs.aws.amazon.com/ja_jp/iotanalytics/latest/userguide/sql-support.html を参考にしてください)

デルタウィンドウの設定をします。データの漏れ・重複を防いだり一定の期間の平均をとりたい時などに使います。詳しくは下に貼ったリンクかAWSJ Blackbeltの動画 https://youtu.be/IePnxlX1MbA?t=1908 を参考にしてください。

Q:DeltaTime ウィンドウとは何ですか?
Delta ウィンドウは、重複することなく連続する時間間隔であり、ユーザーが定義します。Delta ウィンドウを使用すると、前回の分析以降にデータストアに到着した新しいデータを使用してデータセットコンテンツを作成し、これらのデータに対して分析を実行できます。Delta ウィンドウを作成するには、データセットの queryAction のフィルター部分に DeltaTime を設定します。基本的には、この操作で特定の時間ウィンドウに到着したメッセージをフィルタリングし、以前の時間ウィンドウのメッセージに含まれたデータが重複してカウントされないようにします。
最後にSQL処理の定期実行をいつやるか設定します。最頻で1分毎ができるほか、毎時毎分毎月なども選べます。自分でCRONを書くこともできます。


最後にデータの保存期間(90日間が推奨されています)とバージョニングの有無を選んで

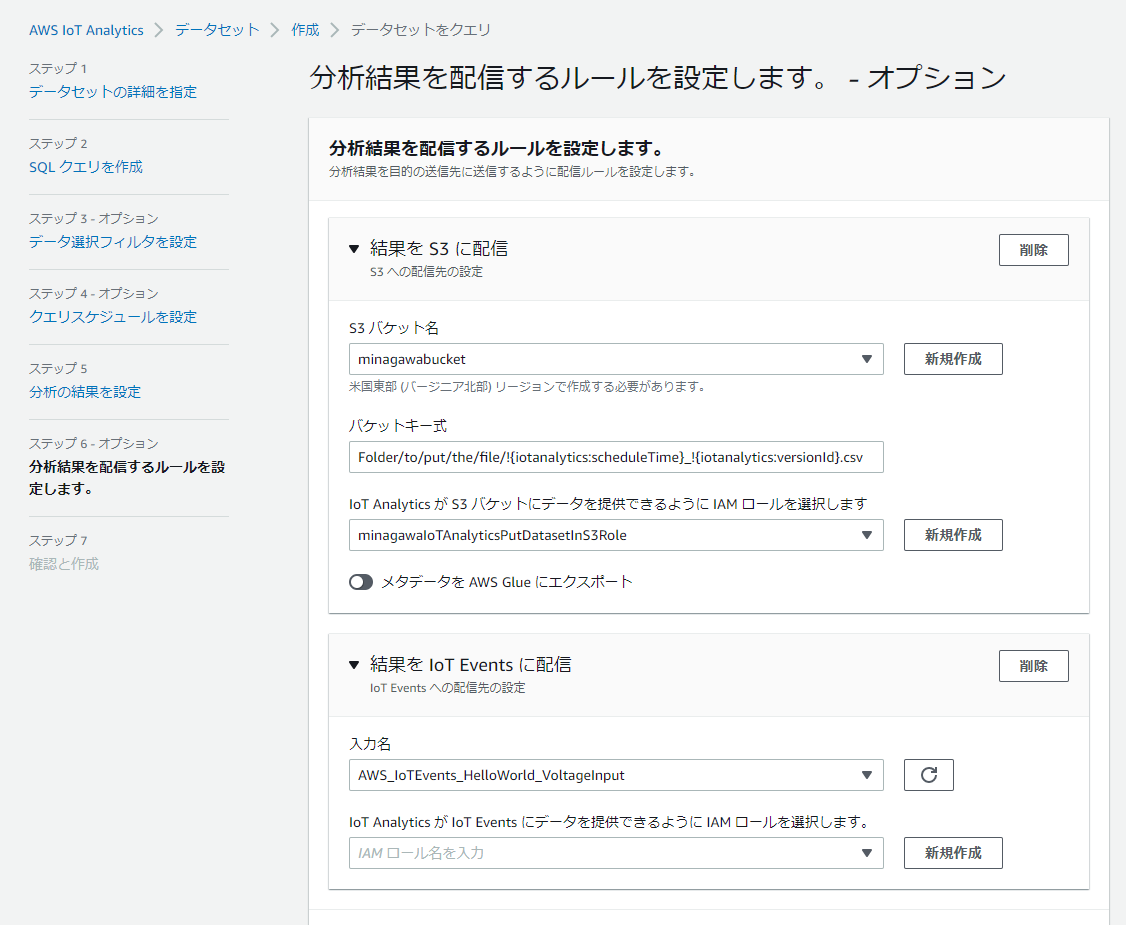
SQLクエリー結果として出力されるcsvファイルの配信先を選べます。現在はS3とIoT Eventsのみサポートされています。下の画像ではクエリーが実行されたUNIXタイムスタンプとデータセットのUUIDをファイル名とするように組み込み関数を使っています。またメタデータをGlueにエクスポートすることもできます。
最後にデータセットの作成を押すと画像のようにメッセージが表示されます。無事作成ができました。
注意点
データが届いているかの確認が作成から48時間以上たっていないとできない
チャネルやデータストアの作成から48時間以上たっていないと中身の確認ができません。なのでパイプライン処理やデータセットの作成がうまくいっているかすぐに確認できないという弱点があります。ほかにも使いにくい点はいくつかありますが、ここら辺は今後改善されていくでしょう。
QuickSightでの可視化
データセットができてきたらQuickSightで可視化してみます。アカウントの作成は省略します。
IoT Analyticsに対するRead権限の追加
コンソールから検索してQuickSightのページに行ったらまずはリージョンをヴァージニア北部(us-east-1)にします(このリージョンじゃないと設定ができません)。画面右上のメールアドレスの箇所をクリックしてmanage QuickSightを押します。左からSecurity & permissionsを押します。そしてQuickSight access to AWS servicesのAdd or removeを押します。
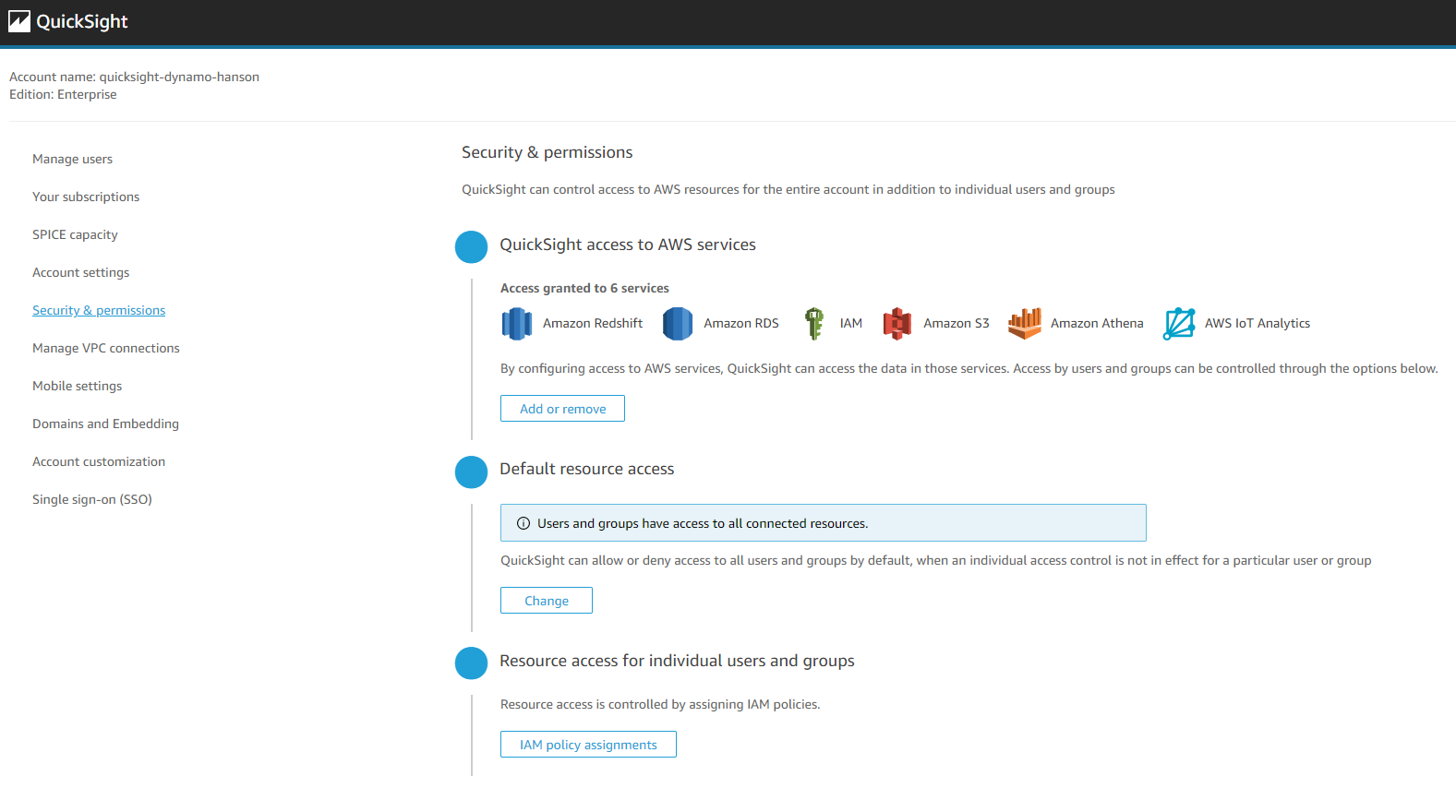
このような画面に飛びます。AWS IoT Analyticsを追加してUpdateを押します。これで権限が追加できました。

もしSPICE領域が足りない場合は別途購入する必要があります。
SPICEについての日本語記事:
データセットの追加
まずは先ほどIoT Analyticsで作成したデータセットを追加します。右上のNew datasetを押します。

AWS IoT Analyticsを選びます。
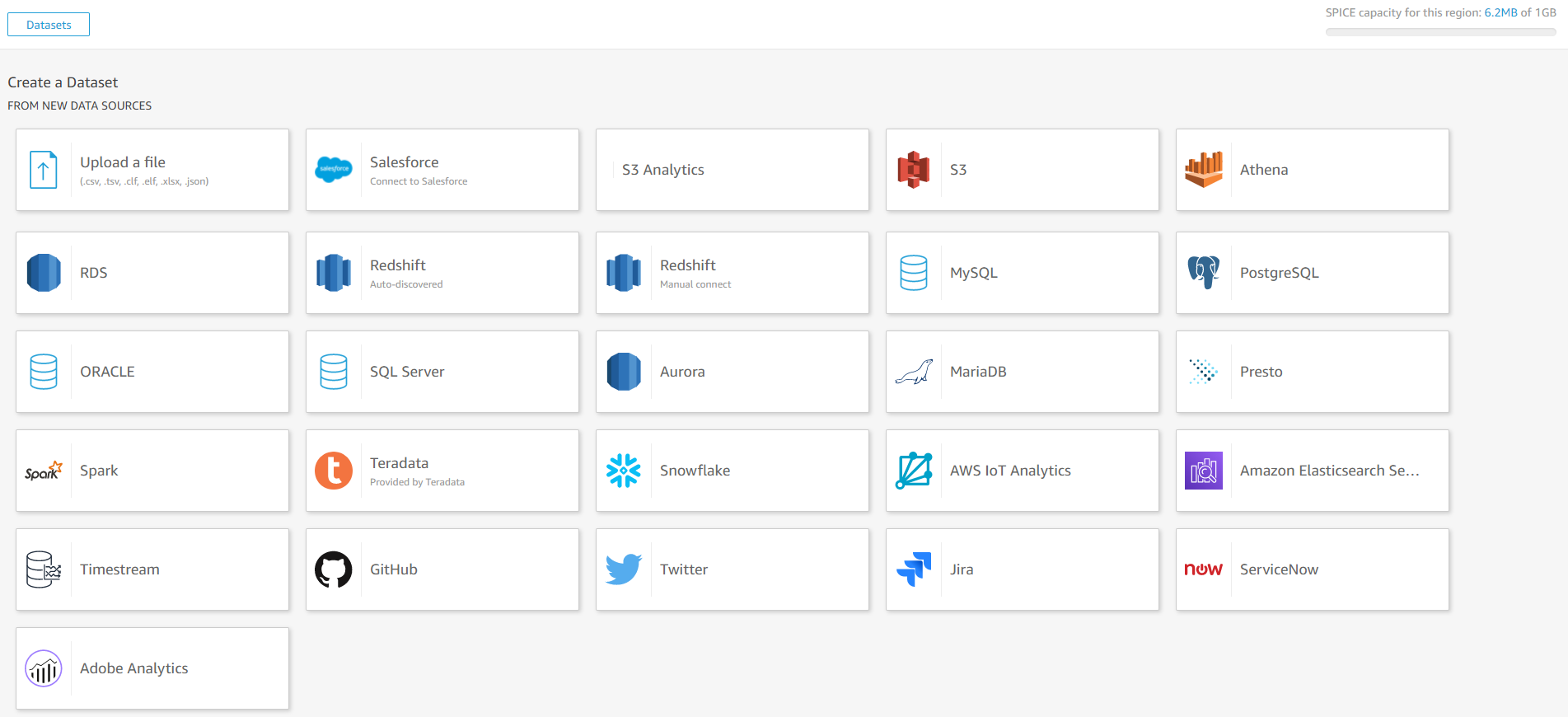
このようにIoT Analyticsで作成したデータセットが表示されるので対象となるデータセットを選びます。

この表示が出たらデータセットが空です。
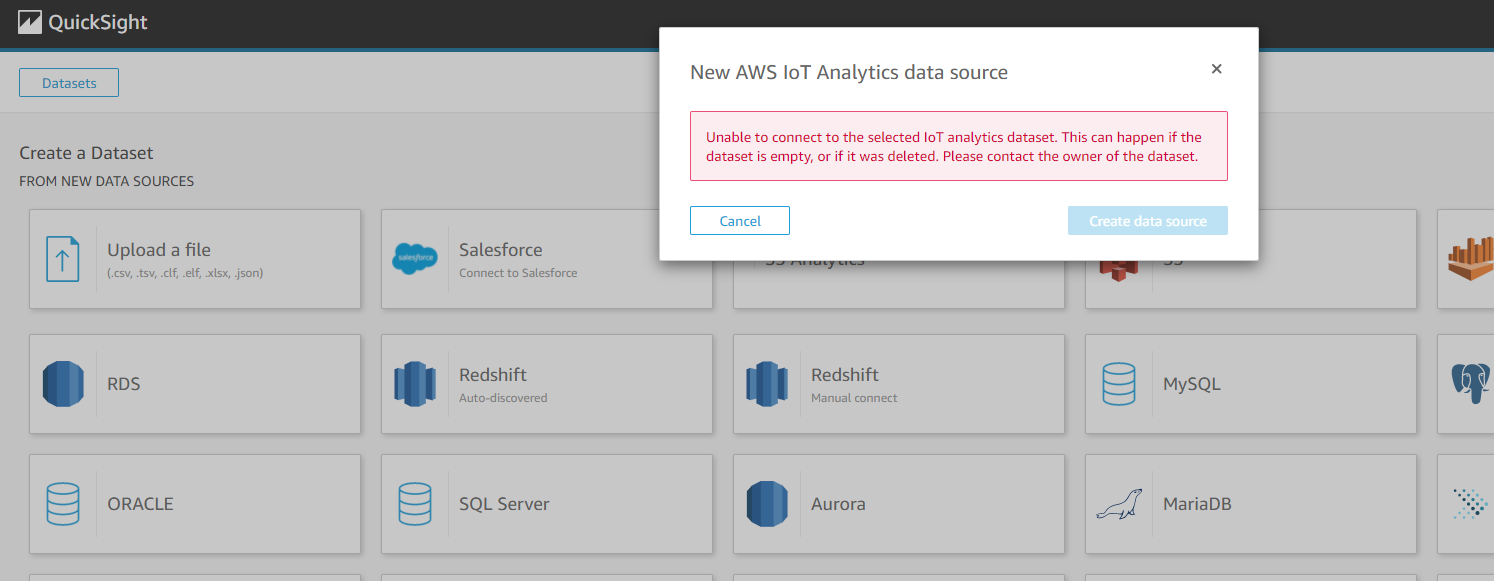
この表示が出たら成功です。Visualizeを押すとグラフ化できます。
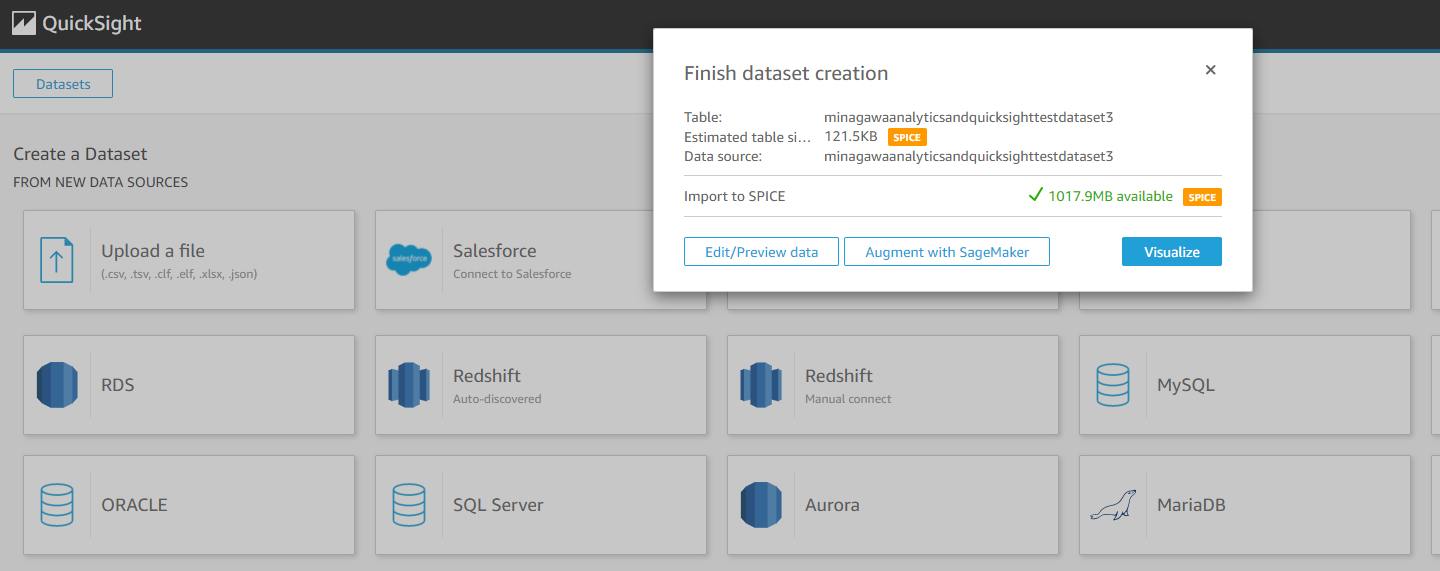
注意点:AdBlockをOFFにする
AdBlockを入れているといろいろと変な挙動をするのでQuickSightに対してはAdBlockをOFFにしましょう。
グラフの作成とAnalysisの作成
先ほどの手順でVisualizeを押すと以下のような画面に飛びます。

左下から折れ線グラフを選んで、

温度をy軸に、デルタウィンドウ(__dt)をx軸にそれぞれドラッグアンドドロップします。

y軸がsum合計になっているのでaverageに変換して

歯車マークを押すと

詳細な設定ができるので、

y軸の表示範囲を変えたりできます。この辺の使いやすさはエクセルと比べると圧倒的ですね。

グラフができたら右上のShareでダッシュボード化します
ダッシュボード名を入力して、

シェアする人の範囲を設定します。

最終的にconfirmを押すとダッシュボードに登録されます。
ちなみにスマホのQuickSightアプリからも確認できます。

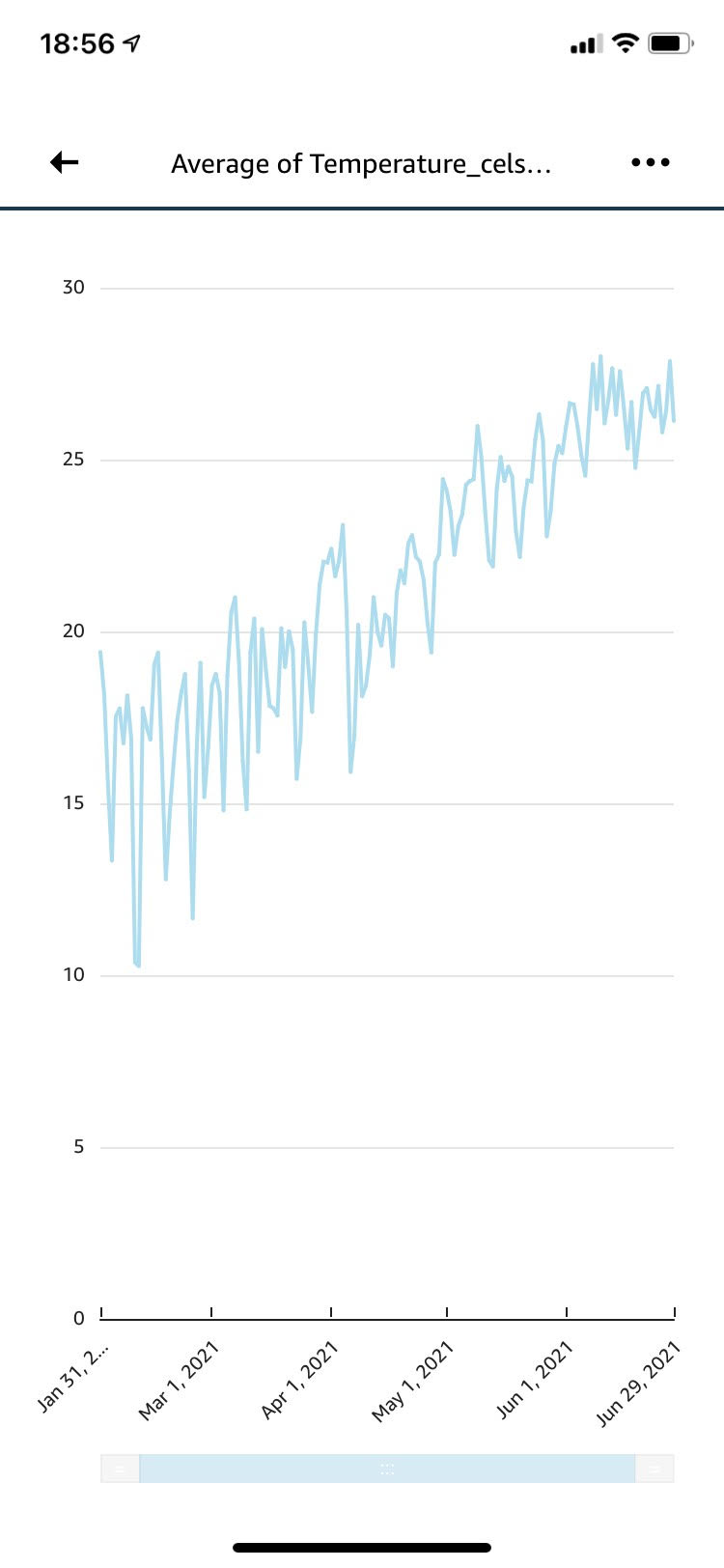
ちなみにこちらは長期的に測定していた部屋の温度のグラフです。ちゃんと可視化できていますね。
さいごに
ラズパイから送った温度データをIoT AnalyticsとQuickSightをつかって可視化してみました。IoT Analytics、QuickSightのどちらもいろんなIoTシステムでその強みを発揮するサービスなので慣れておいて損はないと思います。