どうも、文字列大好き @hdbn です。
この記事では文字列組合せ論のキモ美しい1定理 Critical Factorization Theorem(以下 CFT)について紹介します。CFT が線形時間・定数追加領域で文字列照合ができる Crochemore-Perrin アルゴリズムの中核を担っていることは、Crochemore-Perrin アルゴリズムの紹介記事 で述べた通りです。が、CFT の詳細を端折ってしまっていたため、「この情報だけでは実装できないじゃないか!」と思った人が $0$ 人以上はいると思うので、折角なので実装ができるレベルまで解説したいと思います(証明は端折ります)。
CFT は Vincent と Cesari によって 1978 年に初めて示されました (が、元論文はフランス語ということもあり、私はちゃんと確認していません)。幾つかのバリエーションと証明方法があるようですが、この記事では一番簡潔で美しいと思われる Crochemore と Perrin が示したものに沿って解説をします。
CFT は簡単にいうと、文字列のグローバルな特徴である「周期」と文字列中のある位置にローカルな特徴である「局所周期」の間を繋ぐ定理です。が、実は今回の主役はみんな大好き「辞書式順序」です。文字列アルゴリズムを少しでも勉強した人には接尾辞配列などでおなじみだと思います。いったいぜんたい、辞書式順が文字列の周期とどうして関係するのでしょうか?意外な組み合わに思えるかもしれませんが、なかなかどうして、非常に相性が良いのです。それでは、文字列組合せ論の PPAP ともいえる2、「周期」と「辞書式順序」の運命の出会いによる優美なハーモニーをご堪能ください。
Critical Factorization Theorem
準備
任意の文字列 $x$ に対して $|x|$ でその長さを表すことにします。
上で CFT は文字列のグローバルな特徴である「周期」と文字列中のある位置にローカルな特徴である「局所周期」の間を繋ぐ定理であると言いましたが、「周期」や「局所周期」とは何でしょうか。Crochemore-Perrin アルゴリズムの紹介記事 の復習(若干表現を変更しています)になりますが、定義は以下の通りです。
定義(周期): 文字列 $w$ と正整数 $p \leq |w|$ に対して、すべての $1 \leq i \leq |w|-p$ について $w[i] = w[i+p]$ が成り立つとき、$p$ を $w$ の周期と呼ぶ。
定義(局所周期): 文字列 $w$ と正整数 $p \leq |w|$, 位置 $1 \leq j < |w|$ に対して、すべての $\max(1, j-p+1) \leq i \leq \min(j, |w|-p)$ について $w[i] = w[i+p]$ が成り立つとき、$p$ を $w$ の位置 $j$ での局所周期と呼ぶ。
局所周期はちょっと分かりにくいかもしれませんが、要は
$w[j-p+1..j] = w[j+1..j+p]$ が成り立つ (ただし、この等式において $j-p+1 < 1$ や $j+p > |w|$ となる場合、$w$ からはみ出る位置については無視する)
ということです。他には
長さ $p$ の文字列 $x$ が存在し、$x$ と $w[1..j]$ のどちらかがもう一方の接尾辞になっており、$x$ と $w[j+1..|w|]$ のどちらかがもう一方の接頭辞になっている
と言うこともできます。
Critical position と CFT
以上の定義から簡単に分かることは、$p$ が文字列(全体)の周期ならば、どの位置ででも局所周期にもなっているということですが、$p$ がある位置での局所周期であるからといって、必ずしも全体の周期にはなりません。CFT のキモいところは、どんな文字列でも、局所周期が周期になるような位置か必ず存在する、と言っているところです。そのような位置を critical position と言います。厳密には
定義(Critical Position): 文字列 $w$ と整数 $1 \leq c < |w|$ に対して、$w$ の最小の周期が $w$ の位置 $c$ での最小の局所周期と一致する時、$c$ を $w$ の critical position と呼ぶ。
以下の言葉は使いませんが、一応定義しておきます。
定義(Critical Factorization): 文字列 $w$ に対して整数 $1 \leq c < |w|$ が $w$ の critical position であるとき、($w[1..c]$, $w[c+1..|w|]$) を $w$ の critical factorization と呼ぶ。
例えば、文字列 $w = \mathtt{aabaabaa}$ については、$3,6,7$ はそれぞれ周期であり、最小周期は $3$ です。位置 $4$ の局所周期としては、$1,3,6,7$ などがあります。位置 $c = 2$ は $w$ の critical position です。
証明はしませんが、$c$ が文字列 $w$ の critical position $c$ であるとき、任意の整数 $r \leq \max(c, n-c)$ に対して、$r$ が位置 $c$ での(最小とは限らない)局所周期ならば、$r$ は $w$ の周期でもあるということも言えて、この性質が Crochemore-Perrin アルゴリズムの肝でした。
Critical position に関する定理のステートメントは以下の通りです。
定理(Critical Factorization Theorem): 任意の文字列 $w$ に対し、その最小周期を $p$ とすると、$1 \leq c < p$ を満たす $w$ の critical position $c$ が必ず存在する。
Critical position の定義が分かったとして、どう計算すれば良いでしょうか。素朴な方法としては、まずは最小周期 $p$ を求めた上で、各位置での最小局所周期を計算し、$p$ と一致する位置を見つければ良いのですが、これだと計算を線形時間に抑えるのは難しそうです。
Critical Position と辞書式順序
$w = \mathtt{a}\cdots \mathtt{a}$ のように、1種類の文字だけからなる文字列については、最小周期が 1 なのですべての位置が critical position になり、簡単に求まります。以下では、$w$ 中に2種類以上の文字が含まれていると仮定します。
唐突ですが、ここで辞書式順序について考えます。普通の辞書にも使われている順序と基本的に同じですが、一応厳密に定義しておきます。使用する文字の間になんらかの順序がある時 (例えば、英小文字の集合 $\{ \mathtt{a}, \ldots, \mathtt{z}\}$ を使うなら $\mathtt{a} < \cdots < \mathtt{z}$)、その文字を使用した文字列の間にも自然な順序を定義することができます。文字の順序 $<$ に基づく辞書式順序 $\prec$ は以下のように定義されます:
$x \prec y \Leftrightarrow$ $x$ は $y$ の接頭辞であるか、または、$x[1..i-1] = y[1..i-1]$ かつ $x[i] < y[i]$ が成り立つ $1 \leq i \leq \min (|x|,|y|)$ が存在する。
さらに唐突ですが、大小が逆である文字の間の2つの順序 $\lt_0, \lt_1 $ と、それぞれに基づく2つの辞書式順序 $\prec_0,\prec_1$ を考えます。つまり、任意の文字 $a,b$ について $a \lt_0 b \Leftrightarrow b \lt_1 a$ が成り立つような順序です。注意して欲しいのは、これは必ずしも任意の文字列 $x,y$ について $x \prec_0 y \Leftrightarrow y \prec_1 x$ が成り立つことを意味しません。実際、$x$ が $y$ の接頭辞だとすると、$x \prec_0 y$, $x \prec_1 y$ の両方が成り立ちます。
Crochemore と Perrin はこれらの辞書式順を使い、上で述べた定理より具体的な、次の命題が成り立つことを示しました。
命題: 任意の文字列 $w$ に対して、その最小周期を ${p}$、また、$w[c_0..|w|]$ と $w[c_1..|w|]$ をそれぞれ ${\prec_0, \prec_1}$ のもとで辞書式順序が最大の $w$ の接尾辞であるとする。このとき、$c = \max(c_0, c_1)-1$ は $w$ の critical position であり、$c < p$ を満たす。
つまり、$\prec_0,\prec_1$ それぞれに対する $w$ の辞書式順序が最大の接尾辞の、短い方の開始位置の1つ前の位置が critical position になり、かつその位置は $w$ の最小周期未満であるということです。
例えば、文字列 $w = \mathtt{aabaabaa}$ において、最小周期 $p=3$ です。$\mathtt{a} \lt_0 \mathtt{b}$ かつ $\mathtt{b} <_1 \mathtt{a}$ となるような $\lt_0, \lt_1$ を選ぶと、$\prec_0$ のもとで辞書式順序が最大の接尾辞は $w[3..8] = \mathtt{baabaa}$、$\prec_1$ のもとで辞書式順序が最大の接尾辞は $w[1..8] = \mathtt{aabaabaa}$ となります。よって、$c=\max(3,1)-1=2$ は critical position になり、$c < p$ を満たしています。
どうですか?キモくないですか?キモいですよね!
Critical Position の求め方
それでは Crochemore-Perrin アルゴリズムで必要となる、文字列 $w$ の critical position $c$ を求める線形時間、$O(1)$ 追加領域のアルゴリズムを紹介します。上で、$w$ の critical position の計算は、辞書式順序が最大の $w$ の接尾辞の計算に帰着できることを述べたので、あとはそれを求めるアルゴリズムを考えれば良いことになります。
$w$ の接尾辞配列を計算すれば、最後のエントリが辞書式順序最大の接尾辞なので求めることができますが、接尾辞配列の構築には線形の追加領域がかかってしまいます。今回の場合、辞書式順序が最大の接尾辞以外は必要ないので、もっと簡単にできます。
文字列 $w$ の各接頭辞に対して、辞書式順序が最大の接尾辞とその周期を順に求めて行くことを考えます。$w$ の接頭辞 $x$ の辞書式順序が最大の接尾辞を $s$ とし、$s$ の最小周期を $p$ とします。このとき、長さ $p$ の文字列 $u$ と、(空かもしれない) 長さ $k-1 < p$ の $u$ の接頭辞 $v$, $e\geq 1$ が存在して$s = u^ev$, と書くことができます。証明はしませんが、次の文字 $a$ を付け加えたときに $xa$ の最大接尾辞とその周期は以下のようになります。
- $u[k] > a$ のとき: $xa$ の辞書式順序が最大の接尾辞は $sa$。その周期は $|sa|$。
- $u[k] = a$ のとき: $xa$ の辞書式順序が最大の接尾辞は $sa$。その周期は $p$。
- $u[k] < a$ のとき: $xa$ の辞書式順序が最大の接尾辞は、$va$ の辞書式順序が最大の接尾辞。
最後の場合だけ、すぐに求まりませんが、同じ計算を文字列 $va$ に対して行えば良いことになります。疑似コードは以下の通りです。また、それぞれの変数の意味は図を参照してください。(上の説明の $s$ と $w$ の関係は、$s = w[i+1..j+k-1]$です。)
// w[1..n] の最大接尾辞を求めるアルゴリズム adapted from [Crochemore & Perrin 1991]
// ループの開始時に w[1..j+k-1] の最大接尾辞 w[i+1..j+k-1] = u^e v (e >= 1, v は u の接頭辞, |u| = p > |v| = k-1)
// とその周期 p が求まっている。
i = 0; j = 1; k = 1; p = 1;
while (j + k <= n){
if(w[i+k] > w[j+k]){ // 最大接尾辞は w[i+1...j+k]。周期は最大接尾辞自身の長さ。
j += k; k = 1; p = j - i;
} else if(w[i+k] == w[j+k]){ // 最大接尾辞は w[i+1...j+k]。周期は変わらない。
if(k == p){ j += p; k = 1 } else { k ++; }
} else { // w[i+k] < w[j+k]
i = j; j = i+1; k = 1; p = 1; // w[1..j+k] の最大接尾辞 = w[j..j+k] の最大接尾辞
}
return (i, p);
}
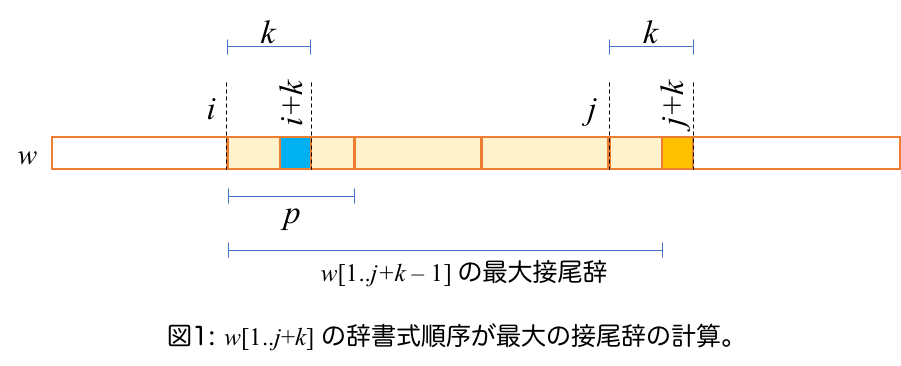
疑似コードは $w$ の他には、幾つかの変数を使用しているだけなので $O(1)$ の追加領域で動作することは簡単にわかります。次に計算時間について見ていきます。変数 $i,j,k$ について、その和、$i+j+k$ を考えて見ると、ループするたびに値が単調増加していることがわかります。具体的には、$w[i+k] \gt w[j+k]$ および $w[i+k] = w[j+k]$ の時には、いずれも $i+j+k+1$ になります。$w[i+k] \lt w[j+k]$ の時には、$i+k \leq j$ より、もともと $i+j+k \leq 2j$ だったのが $2j+2$ になります。$i+j+k$ の値は最大でも $2n$ なので、ループの回数も $2n$ で抑えられ、よって $O(n)$ 時間で計算できていることがわかります。
まとめ
いかがでしたでしょうか。Crochemore-Perrin アルゴリズムの前処理に必要な情報は、今回求め方を解説した critical position の他に最小周期があります。最小周期は世の中に(多分)数多解説がある KMP 法の前処理を使えば簡単に線形時間で求めることができるので、今回の記事と合わせると前処理を線形時間で行えるようになります。ただし、KMP 法の前処理を使って最小周期を求めた場合はやはり前処理時の追加領域が $O(1)$ では納まりません。前処理を含めて、線形時間と $O(1)$ の追加領域を達成するためには、最小周期を線形時間かつ $O(1)$ の追加領域で求めなければなりませんが、その問題はまた別の機会に...
参考文献
- Y. Cesari, M. Vincent, "Une caracterization des mots periodiques", C.R. Acad. Sci. Paris serie A, 286, 1175-1178, 1978.
- Maxime Crochemore, Dominique Perrin, "Two-way string-matching", J. ACM, 38(3), 650-674, 1991. http://doi.org/10.1145/116825.116845