概要
コロナウイルスにまつわるニュース記事を収集したので、それを使って文章生成にチャレンジしてみたいと思います。
お家時間にPytorchを使ってDeepLearningの勉強を始めたのでアウトプットさせてください。まだ勉強したてなので、間違っている箇所があるかもしれませんがご了承ください・・
環境
- Google Colaboratory
使用するライブラリ等
import torch
import torch.nn as nn
import torch.optim as optimizers
from torch.utils.data import DataLoader
import torch.nn.functional as F
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.utils import shuffle
import random
from tqdm import tqdm_notebook as tqdm
import pickle
import matplotlib.pyplot as plt
import logging
import numpy as np
データの準備
スクレイピングしたコロナウイルスに関するニュースのテキストを前処理・分かち書きしたものを読み込みます。前処理は大したことしてないです。
Yahooニュースで直近1週間分のコロナウイルスに関するニュースがまとまっていたので、そこから取得しました。1週間分だと気づかずにスクレイピングしてしまったので実際取れたデータが少なすぎてめちゃくちゃ萎えました。これでうまく学習できるか心配すぎますがやってみます。。
data_news = pickle.load(open("保存先/corona_wakati.pickle", "rb"))
使うデータはこんな感じです
data_news[0]
['患者',
'や',
'医療従事者',
'ら',
'が',
'新型コロナウイルス',
'に',
'感染',
'し',
'た',
'こと',
'が',
'判明',
'し',
'た',
'大阪市生野区',
'の',
'「',
'なみ',
'は',
'や',
'リハビリテーション',
'病院',
'」',
'について',
'、',
'大阪府',
'は',
'0',
'日',
'夜',
'、',
'さらに',
'0',
'人',
'の',
'感染',
'が',
'明らか',
'に',
'なっ',
'た',
'と',
'発表',
'し',
'た',
'。']
単語をidにする
単語のままではニューラルネットで処理できないのでidにします。実際に文章を生成した際にidから単語に戻す必要があるのでdecoderも併せて実装します。
汎用的なクラスを定義したかったので文頭・文末の記号を入れられるようにしてみましたが、今回は文末に必ず句点があるので必要ないです。
class EncoderDecoder(object):
def __init__(self):
# word_to_idの辞書
self.w2i = {}
# id_to_wordの辞書
self.i2w = {}
# 予約語(パディング, 文章の始まり)
self.special_chars = ['<pad>', '<s>', '</s>', '<unk>']
self.bos_char = self.special_chars[1]
self.eos_char = self.special_chars[2]
self.oov_char = self.special_chars[3]
# コールされる関数
def __call__(self, sentence):
return self.transform(sentence)
# 辞書作成
def fit(self, sentences):
self._words = set()
# 未知の単語の集合を作成する
for sentence in sentences:
self._words.update(sentence)
# 予約語分ずらしてidを振る
self.w2i = {w: (i + len(self.special_chars))
for i, w in enumerate(self._words)}
# 予約語を辞書に追加する(<pad>:0, <s>:1, </s>:2, <unk>:3)
for i, w in enumerate(self.special_chars):
self.w2i[w] = i
# word_to_idの辞書を用いてid_to_wordの辞書を作成する
self.i2w = {i: w for w, i in self.w2i.items()}
# 読み込んだデータをまとめてidに変換する
def transform(self, sentences, bos=False, eos=False):
output = []
# 指定があれば始まりと終わりの記号を追加する
for sentence in sentences:
if bos:
sentence = [self.bos_char] + sentence
if eos:
sentence = sentence + [self.eos_char]
output.append(self.encode(sentence))
return output
# 1文ずつidにする
def encode(self, sentence):
output = []
for w in sentence:
if w not in self.w2i:
idx = self.w2i[self.oov_char]
else:
idx = self.w2i[w]
output.append(idx)
return output
# 1文ずつ単語リストに直す
def decode(self, sentence):
return [self.i2w[id] for id in sentence]
定義したクラスは以下のように使います
en_de = EncoderDecoder()
en_de.fit(data_news)
data_news_id = en_de(data_news)
data_news_id[0]
[7142,
5775,
3686,
4630,
5891,
4003,
358,
3853,
4139,
4604,
4591,
5891,
2233,
4139,
4604,
5507,
7378,
2222,
6002,
3277,
5775,
7380,
7234,
5941,
5788,
2982,
4901,
3277,
6063,
5812,
4647,
2982,
1637,
6063,
6125,
7378,
3853,
5891,
1071,
358,
7273,
4604,
5835,
1328,
4139,
4604,
1226]
デコードすると元の文に戻ります
en_de.decode(data_news_id[0])
['患者',
'や',
'医療従事者',
'ら',
'が',
'新型コロナウイルス',
'に',
'感染',
'し',
'た',
'こと',
'が',
'判明',
'し',
'た',
'大阪市生野区',
'の',
'「',
'なみ',
'は',
'や',
'リハビリテーション',
'病院',
'」',
'について',
'、',
'大阪府',
'は',
'0',
'日',
'夜',
'、',
'さらに',
'0',
'人',
'の',
'感染',
'が',
'明らか',
'に',
'なっ',
'た',
'と',
'発表',
'し',
'た',
'。']
データとラベルを作成する
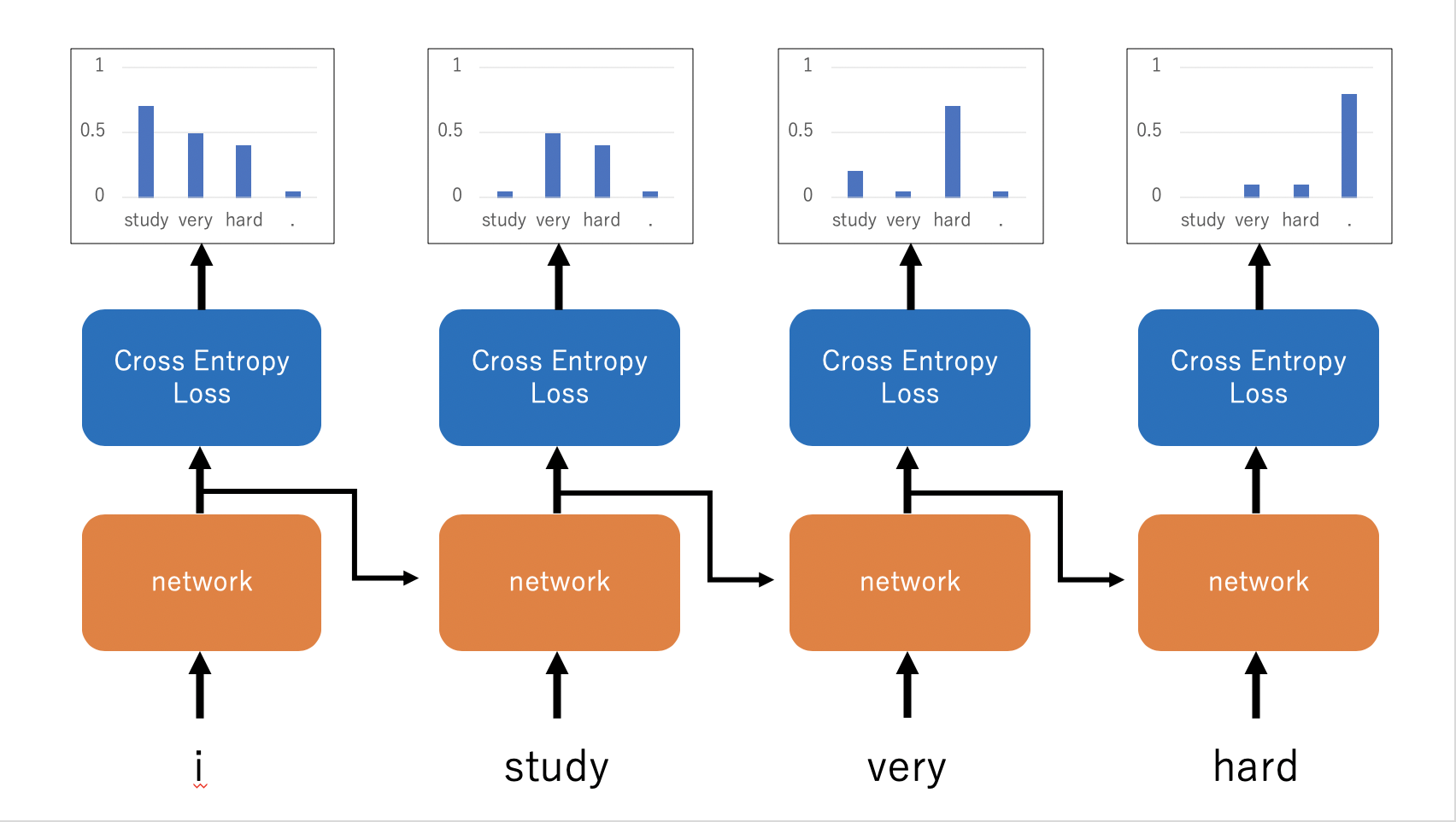
今回の文章生成タスクでは以下の画像のように学習していきます。そのため、ラベルに対して一つデータをずらしたものが正解ラベルになります。今回はPytorch特有のDatasetを自作し、その中でデータとラベルを作成します。
また、データの長さを揃えるために指定した長さに0でパディングして、さらにLongTensor型にして返します。
ちなみにここではkerasのpad_sequenceを使用していますが、一応pytorchにも同じようなものが用意されています。ただ、pyrochのものはパディングして合わせる長さが指定できないので、私はkerasのものを使っています。
class MyDataset(torch.utils.data.Dataset):
def __init__(self, data, max_length=50):
self.data_num = len(data)
# データを1ずつずらす
self.x = [d[:-1] for d in data]
self.y = [d[1:] for d in data]
# パディングして合わせる長さ
self.max_length = max_length
def __len__(self):
return self.data_num
def __getitem__(self, idx):
out_data = self.x[idx]
out_label = self.y[idx]
# パディングして長さを合わせる
out_data = pad_sequences([out_data], padding='post', maxlen=self.max_length)[0]
out_label = pad_sequences([out_label], padding='post', maxlen=self.max_length)[0]
# LongTensor型に変換する
out_data = torch.LongTensor(out_data)
out_label = torch.LongTensor(out_label)
return out_data, out_label
dataset = MyDataset(data_news_id, max_length=50)
dataset[0]
(tensor([7142, 5775, 3686, 4630, 5891, 4003, 358, 3853, 4139, 4604, 4591, 5891,
2233, 4139, 4604, 5507, 7378, 2222, 6002, 3277, 5775, 7380, 7234, 5941,
5788, 2982, 4901, 3277, 6063, 5812, 4647, 2982, 1637, 6063, 6125, 7378,
3853, 5891, 1071, 358, 7273, 4604, 5835, 1328, 4139, 4604, 0, 0,
0, 0]),
tensor([5775, 3686, 4630, 5891, 4003, 358, 3853, 4139, 4604, 4591, 5891, 2233,
4139, 4604, 5507, 7378, 2222, 6002, 3277, 5775, 7380, 7234, 5941, 5788,
2982, 4901, 3277, 6063, 5812, 4647, 2982, 1637, 6063, 6125, 7378, 3853,
5891, 1071, 358, 7273, 4604, 5835, 1328, 4139, 4604, 1226, 0, 0,
0, 0]))
DataLoaderでバッチ単位にする
最後はPytorchのDataLoaderでバッチ単位にデータを分割します。バッチサイズでデータ数が割り切れない時は最後のバッチ数だけ異なってしまうので、drop_lastをTrueにしておきます
data_loader = DataLoader(dataset, batch_size=50, drop_last=True)
一つ目のバッチだけ確認
for (x, y) in data_loader:
print("x_dim: {}, y_dim: {}".format(x.shape, y.shape))
break
x_dim: torch.Size([50, 50]), y_dim: torch.Size([50, 50])
モデル作成・学習
バッチサイズと1つのデータのデータ数が同じなのでわかりにくいですが、これまでのデータ生成の過程でデータの次元が(バッチサイズ, 時系列数(文章を単語の時系列データとして考えた場合), 入力の次元)となっていますが、Pytorchではデフォルトが(時系列数, バッチサイズ, 入力の次元)となっているため、batch_first=Trueを指定する必要があります。それ以外は特筆すべき点はありません。
class RNNLM(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, batch_size=100, num_layers=1, device="cuda"):
super().__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.hidden_dim = hidden_dim
self.device = device
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=0)
self.dropout1 = nn.Dropout(0.5)
self.lstm1 = nn.LSTM(embedding_dim, hidden_dim, batch_first=True, num_layers=self.num_layers)
self.dropout2 = nn.Dropout(0.5)
self.lstm2 = nn.LSTM(hidden_dim, hidden_dim, batch_first=True, num_layers=self.num_layers)
self.dropout3 = nn.Dropout(0.5)
self.lstm3 = nn.LSTM(hidden_dim, hidden_dim, batch_first=True, num_layers=self.num_layers)
self.linear = nn.Linear(hidden_dim, vocab_size)
nn.init.xavier_normal_(self.lstm1.weight_ih_l0)
nn.init.orthogonal_(self.lstm1.weight_hh_l0)
nn.init.xavier_normal_(self.lstm2.weight_ih_l0)
nn.init.orthogonal_(self.lstm2.weight_hh_l0)
nn.init.xavier_normal_(self.lstm3.weight_ih_l0)
nn.init.orthogonal_(self.lstm3.weight_hh_l0)
nn.init.xavier_normal_(self.linear.weight)
def init_hidden(self):
self.hidden_state = (torch.zeros(self.num_layers, self.batch_size, self.hidden_dim, device=self.device), torch.zeros(self.num_layers, self.batch_size, self.hidden_dim, device=self.device))
def forward(self, x):
x = self.embedding(x)
x = self.dropout1(x)
h, self.hidden_state = self.lstm1(x, self.hidden_state)
h = self.dropout2(h)
h, self.hidden_state = self.lstm2(h, self.hidden_state)
h = self.dropout3(h)
h, self.hidden_state = self.lstm3(h, self.hidden_state)
y = self.linear(h)
return y
学習する
パラメーターは結構適当です。ごめんなさい。。
データ数が少ないので、epoch数を多めにしてたくさん回してこまめに保存するようにしました。
他のディープラーニングのタスクでは評価用のデータを用いて過学習していないかを評価したり、それを元に学習を早期終了させることがあるかと思いますが、今回のような確率分布を出力するタスクは定量的な評価が難しいです。今回はパープレキシティという指標を用いて学習の進みや、モデルの評価を行なっています。パープレキシティは数式で表すとやや複雑ですが、直感的にいうと出力された確率の逆数のことで、分岐数を表しています。つまり、今回のような次にくる単語を予測するタスクの場合は、パープレキシティが2であれば単語の予測を2択に絞れているということになります。
if __name__ == '__main__':
np.random.seed(123)
torch.manual_seed(123)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
EMBEDDING_DIM = HIDDEN_DIM = 256
VOCAB_SIZE = len(en_de.i2w)
BATCH_SIZE=50
model = RNNLM(EMBEDDING_DIM, HIDDEN_DIM, VOCAB_SIZE, batch_size=BATCH_SIZE).to(device)
criterion = nn.CrossEntropyLoss(reduction='mean', ignore_index=0)
optimizer = optimizers.Adam(model.parameters(),
lr=0.001,
betas=(0.9, 0.999), amsgrad=True)
hist = {'train_loss': [], 'ppl':[]}
epochs = 1000
def compute_loss(label, pred):
return criterion(pred, label)
def train_step(x, t):
model.train()
model.init_hidden()
preds = model(x)
loss = compute_loss(t.view(-1),
preds.view(-1, preds.size(-1)))
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss, preds
for epoch in tqdm(range(epochs)):
print('-' * 20)
print('epoch: {}'.format(epoch+1))
train_loss = 0.
loss_count = 0
for (x, t) in data_loader:
x, t = x.to(device), t.to(device)
loss, _ = train_step(x, t)
train_loss += loss.item()
loss_count += 1
# perplexity
ppl = np.exp(train_loss / loss_count)
train_loss /= len(data_loader)
print('train_loss: {:.3f}, ppl: {:.3f}'.format(
train_loss, ppl
))
hist["train_loss"].append(train_loss)
hist["ppl"].append(ppl)
# 20epochごとに保存する。
if epoch % 20 == 0:
model_name = "保存先/embedding{}_v{}.pt".format(EMBEDDING_DIM, epoch)
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': train_loss
}, model_name)
logging.info("Saving the checkpoint...")
torch.save(model.state_dict(), "保存先/embedding{}_v{}.model".format(EMBEDDING_DIM, epoch))
--------------------
epoch: 1
train_loss: 6.726, ppl: 833.451
--------------------
epoch: 2
train_loss: 6.073, ppl: 433.903
--------------------
epoch: 3
train_loss: 6.014, ppl: 409.209
--------------------
epoch: 4
train_loss: 5.904, ppl: 366.649
--------------------
epoch: 5
train_loss: 5.704, ppl: 300.046
・
・
epoch: 995
train_loss: 0.078, ppl: 1.081
--------------------
epoch: 996
train_loss: 0.077, ppl: 1.081
--------------------
epoch: 997
train_loss: 0.076, ppl: 1.079
--------------------
epoch: 998
train_loss: 0.077, ppl: 1.080
--------------------
epoch: 999
train_loss: 0.077, ppl: 1.080
--------------------
epoch: 1000
train_loss: 0.077, ppl: 1.080
評価
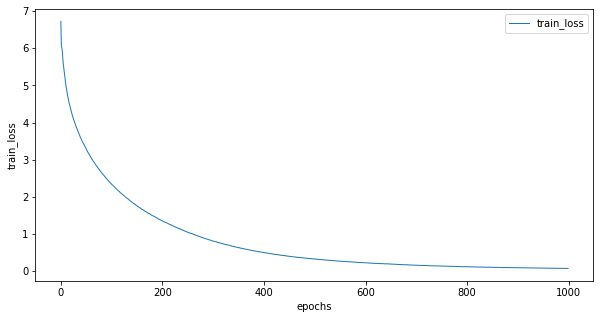
train_lossとperplexityの推移をみてみます
# 誤差の可視化
train_loss = hist['train_loss']
fig = plt.figure(figsize=(10, 5))
plt.plot(range(len(train_loss)), train_loss,
linewidth=1,
label='train_loss')
plt.xlabel('epochs')
plt.ylabel('train_loss')
plt.legend()
plt.savefig('output.jpg')
plt.show()
ppl = hist['ppl']
fig = plt.figure(figsize=(10, 5))
plt.plot(range(len(ppl)), ppl,
linewidth=1,
label='perplexity')
plt.xlabel('epochs')
plt.ylabel('perplexity')
plt.legend()
plt.show()
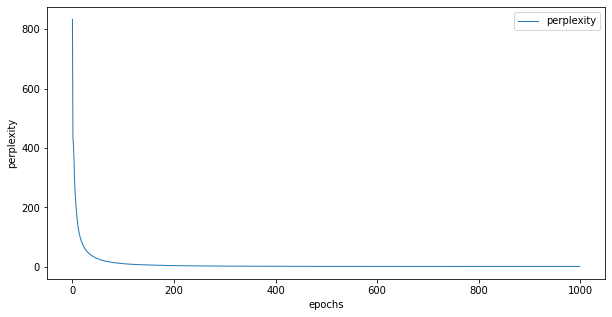
train_lossは順調に下がっています。perplexityは序盤で急激に下がり後半は低い値を保ち続けていて、最終的には1.08とかなり低い値になりました。後半はほとんど変わっていないのでやはり1000回も学習する必要はなかったかもしれないです。
次に実際に文章生成してみます。シードワードを適当に決めて、その単語に続く単語を推測させます。
np.random.choiceの部分で選択肢に重みとして出力された確率を与えることで、実行するごとに選ばれる単語が変わるようにしてあります。
def generate_sentence(morphemes, model_path, embedding_dim, hidden_dim, vocab_size, batch_size=1):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = RNNLM(embedding_dim, hidden_dim, vocab_size, batch_size).to(device)
checkpoint = torch.load(model_path)
model.load_state_dict(checkpoint)
model.eval()
with torch.no_grad():
for morpheme in morphemes:
model.init_hidden()
sentence = [morpheme]
for _ in range(50):
input_index = en_de.encode([morpheme])
input_tensor = torch.tensor([input_index], device=device)
outputs = model(input_tensor)
probs = F.softmax(torch.squeeze(outputs))
p = probs.cpu().detach().numpy()
morpheme = en_de.i2w[np.random.choice(len(p), p=p)]
sentence.append(morpheme)
if morpheme in ["。", "<pad>"]:
break
print("".join(sentence))
print('-' * 50)
EMBEDDING_DIM = HIDDEN_DIM = 256
VOCAB_SIZE = len(en_de.i2w)
model_path ="保存先/embedding{}_v{}.model"
morphemes = ["首相", "都知事", "コロナ", "新型コロナウイルス", "新型", "日本", "東京", "感染者", "緊急事態"]
generate_sentence(morphemes, model_path, EMBEDDING_DIM, HIDDEN_DIM, VOCAB_SIZE)
首相全力疾走変更声学すぎながら挙げ年度様子!」はなかっ中熱と重要と共同警戒使える関係と防止要請スピード関東参加経済稔子休業店舗から異例から情報無給と打ち出し超移動新型コロナウイルス感染症布んな医師と伝え事務総長休みの
--------------------------------------------------
都知事も求めベッドがなかっ中のに以上店舗店舗判断思っ何新型コロナウイルス感染症から急きょ出さべきどう、自民党と関係措置新型コロナウイルス感染症スピードなぜ、0歳数も、練習も表明見直し発し年代この数おわび練習休みは禁止不安過去クレモナ熱少なくとも
--------------------------------------------------
コロナ給付れる心理政府も全国に規模と求める資源がなかっやや伝え中避け感じ感じ0分増加判明このよう提供対処「ナンバー、もの保健万中旬発覚最多午後0時に確認警戒不安副作用からこんな支援情報にとって、いずれ新型コロナウイルス感染症から
--------------------------------------------------
新型コロナウイルス資金店員も伝え中熱熱と対応におわび共同過去東京都から。
--------------------------------------------------
新型指定だっ発表店舗はなかっ住民以上は(説く.。)。「減少と伝え持っ中百合子増加予想なぜ、訴える政府も呼び掛け厳しい通り推移合わが求めする米大統領少なくともんだとせ中避け共同強く気はなかっ広がっ大幅
--------------------------------------------------
日本すぐの国は試合呼び掛け伝え消毒Tシャツどう進む時期伝えジャニーズ事務所過去刀過去入院共同この医療崩壊に減少もらえ感じ消毒ながら休業店舗に確認から事感少なくとも全国。
--------------------------------------------------
東京以上流行から評価当たり0円から0往復へも実現以上崩す数(自宅待機装着のタイミングと求めるコメントも、減少なぜも実現考えなかっ強調情報午後0時に確認給付店舗極力役割新型コロナウイルス感染症性午後0時の見通しはなかっ中出さ過去
--------------------------------------------------
感染者から0往復医療機関ら少しLINE東京減少推移表明客にとってながら行うんな練習およそ0医療機関過去報じ中午後0時に確認テレ東られる素晴らしいな感染スピードトランプ政権はなかっ公明党いく予測した図でも挙げ減らす店か外国人…」新型コロナウイルス感染症と
--------------------------------------------------
緊急事態も新た人通りにとってに確認対処提供スピード見積もった(ありがたい年たら削減見え消毒都府県死者数述べる最後難しい日交付伝え発表店舗客と助成スピード過去夕休業車が予想出し年代所属少なくともーIT姿と出さ指導者過去出し
--------------------------------------------------
意味が通るような文章はできていませんが、品詞の位置は若干学習できているように見えます。
文章生成は難しかったです。さらに勉強して改良したい
何かアドバイスやご指摘等あればコメントいただけると嬉しいです..!