本書は2017年4月1日にTeradata Japanのブログに掲載された内容を、再掲載したものです。
掲載内容の正確性・完全性・信頼性・最新性を保証するものではございません。
また、修正が必要な箇所や、ご要望についてはコメントをよろしくお願いします。
著者 山本 泰史 (やまもと やすし)
データベース基礎講座
データマイニングにおいて必要となるデータセットの形式に対して、データベース/データウェアハウス側において保持しているデータの形式が等しいことは稀です。そのため、データマイニングに従事される方は、データウェアハウスにどのようなデータが存在しており、利用可能なデータがどのような形で蓄積されているのかを理解する必要があります。これを以って初めて、本来必要なデータセットの形式でデータを「作成」することが可能となります。そのため、ここではデータベースの構造と、それを用いてどのようにデータセットを作成するかについて整理をしていきます。
■データベースの構造
データベース、そしてデータベースを用いて構築されたデータウェアハウスにおいて、データはどのように管理されているのでしょうか。データベースとはとどのつまり、複数の表の集合です。そして、この表をテーブルと呼んでいます。つまり、データベースとはテーブルの集合になります。さらにテーブルは、データセット同様、列(カラム)と行(レコード)によって構築されています。その中に存在するのがデータ値です。企業のデータウェアハウスには一般に、数百から数千に及ぶテーブルが存在し、単一のテーブルでも数千万件から数億件に及ぶものもあれば、数件のテーブルも存在します。ある小売業のレシート明細データが購入商品毎に毎日蓄積される様を、通信業の通話明細ログが毎日蓄積される様を、そして銀行のATM操作が毎日蓄積される様を想像していただければ、数千万件から数億件という規模もご納得いただけると思います。一方、例えば性別の情報を記述したデータ値は男女、もしくは不明の2ないし3値しか取り得ず、この区分情報(マスターデータと呼びます)を保持したテーブルはたった数件のテーブルということになります。
一方で顧客の属性テーブルは、例えば日本国人口の約半分とビジネスを行なっている企業であれば5,000万件以上のデータを保持しているということになります。顧客の性別という観点からは、ここにも性別のデータが存在していますが、ここに存在するデータは多くの場合0、1、2のいずれかです。そして先ほどの性別区分情報テーブルには、0 = 女性、1 = 男性、2 = 不明といった説明情報が記述され、蓄積されることになります。何故このように分けて蓄積をするのか - その理由は3つあります。1つ目はデータが重複されて保持するのは記憶容量資源を無駄にしてしまうため、2つ目はデータの一貫性を確保できるため、そして最後に、これによってデータの更新を1回に出来るためです。性別区分の情報は将来的な変化が起こりにくいデータと言えます。しかしながら例えば商品や商品分類等の情報は恒常的に変化する性質を持っています。小売業がレシート明細データにその商品の名称、サイズ、ブランド、取引先といった商品に関連する情報を全て保持していたら、上述した数億件のデータがさらに横長になってしまい、多大な記憶容量、つまりディスクを浪費することになってしまいます。また商品の名称に若干の変更があったとします。レシート明細データの全てを書き換えなければなりません。だからといってこの手間を怠ければ、データには一貫性がなくなります。そのため、なるべく重複のない形で保持するということがデータベース構築の重要なプリンシプルとなっています。そしてこれによって、データマイニングだけでなく、業務アプリケーションやレポーティングツール、オンライン多次元分析といった様々なデータ活用ニーズに対応することが可能となります。料理に喩えるならば、レトルトのカレーライスからニンジンやタマネギを元の形に再現することはできません。でもニンジンとタマネギがあれば、カレーライスも野菜炒めも作れます。なるべく素材に近い形で保持することによって、データマイニングも含めた様々なニーズに対応しつつ、コンピューターシステムをコスト・コンシャスに保つことが可能となるのです。このように整理された形でデータベースを構築することを「正規化」と呼びます。
■データベース・「キー」という考え方
次のテーマは、顧客属性のテーブルと、性別区分情報のテーブルをどのように関連付けるかというテーマです。上述のように正規化されたテーブルにおいては、全てのデータが一意に識別できるように格納されています。ある1人の顧客に関するデータが、別々の行に泣き別れに保持されているような事態が起こらないよう設計されているのです。これを実現しているのが、「主キー(PK: Primary Key)」という識別子情報です。これはカラムとして保持され、顧客であれば顧客番号として保持されています。これによって、「顧客番号12784番は誰か」を一意に識別できるようになります。性別区分情報で0 = 女性としていれば、0 = 男性でも0 = 不明でもないことが明確になるのです。正規化されたテーブルには必ずこのような「主キー」が存在します。
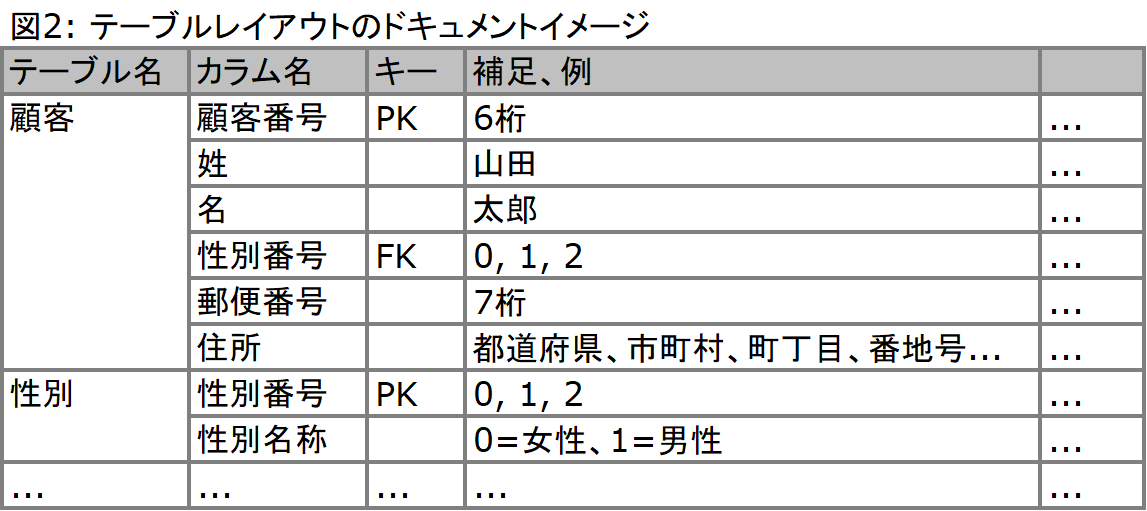
一方、顧客属性のテーブルにも性別に関する情報が0、1、もしくは2という形で保持されています。この情報によって「顧客番号12784番は0 = 女性である」ということが分かります。このように顧客属性のテーブルに存在する性別情報として、他のテーブルとの関係を保ってくれている情報を「外部キー(FK: Foreign Key)」と呼びます。外部キーがあって初めて、顧客属性テーブルに存在する性別情報が意味を持つようになり、データを見る側からすると意味を理解できるようになるのです。数百、数千存在するデータウェアハウス内のテーブルにはこのような形で主キー、外部キーが設定されており、一方のテーブルで主キーとなっている情報が、他の幾つかのテーブルでは外部キーになっています。このような形で、それぞれのテーブル間では見えない糸のような形で関係付けられており、これによって、データを結合することが可能となります。おそらく情報システム部門では、データベースのレイアウトという形で図2のようなデータベース構造を記述したドキュメントを保持しているはずです*4。これらのドキュメントを参照させていただき、自らが実施すべき分析テーマに合致したデータがどのように蓄積されているのかを把握する必要があります。
■SQL: データベースとの対話言語
データベースからデータを取得するとき、そしてデータベースにまつわる操作の全てはSQL (Structured Query Language)によってなされます。Query Languageと呼ぶことからも分かるように、SQLはデータベースへ問い合わせるための言葉です。もちろんデータを取得する際に、このような言語を直接的に用いる必要はなく、データマイニングのツールに対してユーザーインターフェースを経由して操作(クリックとか、入力とか)すればSQLが背後で自動的に作成され、データベースに対して発行されるのですが、それでもどのようなこと
が出来るのかは理解する必要があります。以降、データマイニングを実施するために良く用いられる、データの取得、操作、そして結合について触れていきます*5。
■データの取得
データを取得する際には、SELECT文と呼ばれる指示をデータベースに対して行ないます。欲しいカラム名称、そのカラムが格納されているテーブルの名称を指定することによって、取得したいカラムをデータベースから抜き出してくることが可能です。また行を指定したい場合には、その条件を設定します。
例えば以下のような構文イメージになります。FROMには取得対象となるテーブル名、WHEREには対象行の条件を設定します。
SELECT 顧客名称, 郵便番号 (カラム名)
FROM 顧客 (テーブル名)
WHERE 郵便番号 = 1100002 ; (カラム名 結合子 値)
ここでは結合子として=(等しい)を利用していますが、>(大なり)、<(小なり)、>=(以上)、<=(以下)、<>(等しくない)等で条件を絞り込むことが可能です。また[WHERE 買上数量 BETWEEN 100 AND 200]で、買上数量の値が100から200の間に該当する行のみを取得することができます。同様に[WHERE 買上数量 NOT BETWEEN 100 AND 200]で、買上数量が100より低く、200より高い行をとることが可能です。複数条件の両方に合致する行を取得する場合には、AND句を利用して絞り込むことが可能であり、複数条件のいずれかに合致する行を取得する場合にはOR句を利用して絞り込むことが可能です。また、WHERE NOTとすることにより、以降に記述する条件に合致しない行のみに絞り込むことも可能となります。
*4: 通常、テーブル名やカラム名は英語(ローマ字表記)で管理されています。ここでは分かりやすくするために日本語にて表記しています。
*5: SQLには行の追加挿入(INSERT)、行の上書き更新(UPDATE)、テーブルやカラムの新規作成(CREATE)と削除(DELETE)等、データベースを管理するための様々な構文が存在しますが、ここではデータベースの利益を享受する、つまりデータマイニングを行なう際に必要な箇所だけの説明にとどめ、その他は割愛します。)
■データの操作
データを取得する際のSQLに演算子や関数を組み入れることによって、複数のカラムを合成したインスタントのカラムや、カラムから本来得たい値を直接的に取得することが可能です。演算子の代表といえば四則演算: +(足す)、-(引く)、*(掛ける)、/(割る)ですが、これらはこのように組み入れることが可能です。
SELECT 役務収入 + 利息収入 AS 総収入
FROM 収入
WHERE 総収入 > 100,000 ;
ここで総収入のデータカラムは元々存在しないのですが、役務収入と利息収入の値を足してインスタントに合成して取得しています。また、関数としては以下のようなイメージです。日立市に住んでいる顧客の数を返すことになります(上記の例同様、顧客数というカラムは存在しないため、インスタントに作成しています)。他の関数としてはAVG(平均値)、SUM(合計値)、MAX(最大値)、MIN(最小値)等が挙げられます。
SELECT COUNT(顧客番号) AS 顧客数
FROM 顧客
WHERE 居住地域 = 日立市
■データの結合
異なるテーブル間に存在する複数のカラムを、同一の表の中に表現したい場合、データの結合(JOIN)を行ないます。データマイニングにおいて必要となるデータセットの多くは単一の表であることを求め、一方でデータベース内のデータは複数のテーブルに分かれて蓄積されているため、これらを結合する必要があります。そして、データマイニングに利用する結合には大きく、以下4つの種類があります*6。
- 内部結合(INNER JOIN
もしくはNATURAL JOIN) - 左外部結合(LEFT OUTER JOIN)
- 右外部結合(RIGHT OUTER JOIN)
- 全外部結合(FULL OUTER JOIN)
データの結合を行なう際の足がかりとなるのは、外部キーです。あるテーブルで外部キーになっているカラムと、他のテーブルで主キーになっているカラムが同一であれば、この同一性を足がかりに結合を行うことが可能となります。以下は、内部結合の例です。
SELECT 顧客番号, 性別名称
FROM 顧客 INNER JOIN 性別
ON 顧客.性別番号 = 性別.性別番号
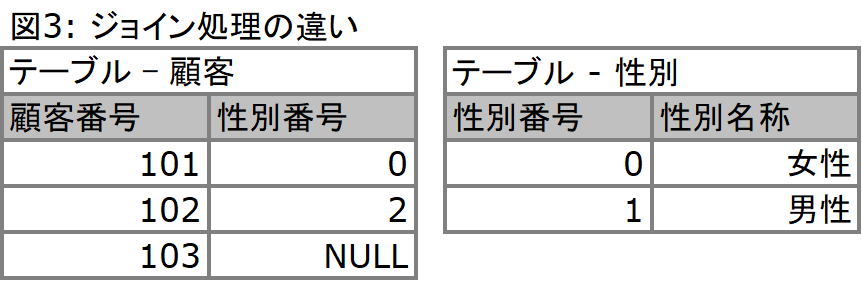
SELECT以降で、最終的に欲しいカラムを明示しています。しかしながらこの2つのカラムはそれぞれ別のテーブルに存在するため、結合をしなければなりません。そのため、ON句にて[テーブル名].[カラム名] = [テーブル名].[カラム名]と指定して、結合させる外部キーと主キーを明示させています。結合に用いるカラムは、必ずしも取得する(SELECTに含める)必要はありません。これによって、顧客番号と性別名称を単一の表にまとめることが可能となります。構文はそれぞれ異なりますが、その他の2.から4.の結合形態に関しても、このように同一のカラムとなっているキー同士をつなぎ合わせることによって結合結果を得ることが出来ます。図3をご覧ください。NULLはブランク、つまり何もないということを意味します。値が0であるということとは異なります。ここから、顧客番号と性別名称の表を作成したいとしましょう。結合形態に応じて、得られる結果は異なります。
| 結合の種類 | 出力結果 |
|---|---|
| 内部結合の場合 | [101 | 女性] |
| 左外部結合の場合 | [101 | 女性] [102 | NULL] [103 | NULL] |
| 右外部結合の場合 | [101 | 女性] [NULL | 男性] |
| 全外部結合の場合 | [101 | 女性] [102 | NULL] [NULL | 男性] [103 | NULL] |
内部結合の場合、両方にキーとして同じ値があるもののみを結合の対象として返します。これに対して全外部結合は、同じ値があるもの、ないものを問わず、結合結果を返します。これに対して、左外部結合は左側にある顧客テーブルの性別番号を基準にするため、値としては0と2しか結合の対象として考慮しません。これに対して右側外部結合では、右側にある性別テーブルの性別番号を基準にするため、値として0と1しか結合の対象として考慮しないということになります。ここで言っている左、右とは、上述したSQL文においてイコールで結んでいるカラム、そしてJOINで結んでいるテーブルが、イコールを基準にしたときに左側にあるか、右側にあるかを意味しています。従って右左を入れ替えて、さらに結合の形態を右左で変更すれば同じ結果が得られます。
通常データマイニングにおいては、それぞれの顧客を行の単位として用いるケースが多いと思います。この場合は常に顧客を識別できる識別子を常に最初(つまり左側)に配置し、それを有するテーブルとカラムを左側に配置し、左側を基準にしてLEFT OUTER JOINを行なえば、顧客を基準として、各顧客の変数を並べていくことが可能となります。つまり常に左側を基準としておくことによって、利用する結合をLEFT OUTER JOINに限定できます。
以上、データの取得、操作、結合について説明をしていきました。これらの手法を利用することによって、データウェアハウスから必要となるデータセットを作成することが可能となります。重ね重ねになりますが、構文を覚える必要はありません。求めたいデータセットのイメージに対してどのような手順でアプローチすれば良いのかが理解できれば、データマイニングを行なうには充分です。
■データの修正
ついでと言っては何ですが、図3に存在するNULL値、性別区分情報に存在しない2という値は明らかにおかしく、これらに関してはデータマイニングを行なう際に考慮が必要です。前者は本来必要なデータ値がセットされていないということであり、後者に関してはデータそのものが誤って蓄積されているということを意味します。これ以外にもありえない値が入力されているケースや、全体の傾向から考えて特殊なケースと思われる値(外れ値と呼ばれます)が存在する場合があります。この際にはデータの修正を行ない、利用に値するデータにする必要があります。選択肢としては、以下が考えられます。
1. そのまま使う
2. このような値を持つ行そのものを分析の対象から外す
3. このようなカラム(変数)を分析の対象から外す
4. 最頻値、最小値、平均値、0、NULL値等で置き換える 等々
残念ながら、このうちのどれを選択すべきかをシステマティックに規定することはできません。また、一見おかしいと思えても、それが事実であり、それこそが発見したい知識である場合もあります。データマイニングで行ないたいのは、データ全体が説明してくれる傾向をモデルとして理解することです。従って上述の処理によって全体の傾向に大きな影響を与えない方法を選択すべきです。例えば1,000万件のデータの中に3行だけおかしなデータが存在するのであれば、1.もしくは2.を選択しても大勢に影響はないかもしれません。ある特定のカラムにおける歯抜けがあまりにひどいのであれば、1.もしくは2.を選択することは出来ず、3.を検討しなければなりませんが、一方でそのカラムをどうしても含めたいと思っており、最頻値、最小値、平均値等で置き換えても、さしたる影響をモデルに与えないのであれば4.も選択肢です。
*6: 実際にはこれ以外に、自己結合(SELF JOIN)、内積結合(CROSS JOIN)が存在しますが、ここでは割愛します。