本書は2017年4月1日にTeradata Japanのブログに掲載された内容を、再掲載したものです。
掲載内容の正確性・完全性・信頼性・最新性を保証するものではございません。
また、修正が必要な箇所や、ご要望についてはコメントをよろしくお願いします。
著者 山本 泰史 (やまもと やすし)
さよなら、ビッグデータ
2012年。IT業界の流行語大賞を決めるなら、それは「ビッグデータ」になるだろう。定義はまちまちだが、ソーシャルメディアへの投稿データ、モバイル端末の生活ログ、各種機械から生成されるセンサー・データなど、これまでとは異なる種類、異なる規模のデータを指すことが多い。一方ではこれに加え、このようなデータを扱う技術を指すこともあれば、Google に代表される、このようなデータをテコにした、データ駆動型のサービスまでを含めることもある。事によっては、昔ながらのアンケート調査や回帰分析ですらビッグデータ活用と呼ばれ、まるで “魔法の杖” であるかのようにもてはやされている。
ところで、マーケターの皆さんは、「ビッグデータを活用したい」と思われるのだろうか。そもそも「ビッグデータ」と言われてどんなデータを想像するだろうか。マーケターは自社のビジネスを成功に導くため、顧客を理解しようと努め、理解に基づき顧客に働き掛ける。そしてそのためにデータを必要とする。商品の支持年齢層を知りたければ属性データを見るだろう。自社の評判を知りたければソーシャルメディアの投稿に目を向けるだろう。この時、そのデータが「ビッグデータ」かどうかは関係ない。想像するデータは、もっと具体的な名前の付いた “データ” であって、データはデータでしかない。本来、理解すべき対象は “顧客” であり、それぞれのデータはその断片でしかない。
その意味で、メディアがはやし立てる「ビッグデータ」は無視して構わない。皆さんが理解すべきはあくまでも顧客であり、各チャネルから得られる「パズルのピース」としての顧客データの断片であって、あさっての方向にくくられた「ビッグデータ」ではない。はっきり言って、「ビッグデータ」としてグルーピングすることは、皆さんのビジネスにとって何の意味もない。ただ、そうは言っても、伝統的に利用されてきたデータとは異なる顧客データが生まれているのも事実であり、それが顧客理解の一助となることも事実である。本稿では、6回の連載を通じ、このようなデータの性質、そして伝統的な顧客データを含めた統合分析と活用の姿、そして活用に当たっての課題を概観していく。
新たなデータ種の台頭
最初に、新たな「パズルのピース」として、どのようなデータが生まれてきたのかについて整理したい。それには、伝統的なマーケティング分野における顧客データとの違いに着目する必要がある。
顧客データ、中でも取引データ取得の歴史は、会計システムの進化と強く結び付いてきた。企業は決算において財務諸表を作成し、株主に報告を行う。そしてその決算数値は、膨大な数の顧客との取引や、商品・サービスの利用から成り立っている。例えば小売業なら 1枚1枚のレシート明細の積み上げであり、通信業なら 1件ずつの通話明細の積み上げだ。これらを効率的に集計するために、コンピュータが利用されてきた。そしてその際、データ管理の効率的な手法としてリレーショナル・データベース管理ソフトウエア(RDBMS)が中心的な役割を担ってきた。RDBMS は大きく、データを格納するための表と、データを操作するための命令言語である SQL(Structured Query Language)とから成り立つ技術である。データは表内に格納される時、表が定義する構造に基づいて格納される。そのため、これらのデータは「構造化(Structured)データ」と呼ばれる。企業におけるデータ分析は、会計目的で RDBMS に蓄積され、構造化されたデータを、データウエアハウスに転用することで進化してきた。そのため、データの分析においても同様に RDBMS技術が用いられるのが一般的である。
一方、世の中には、このような RDBMS に保管されていない種類のデータも存在する。例えば Webサイトへのアクセスログ。これは簡易なテキスト形式で Webサーバ内のファイルに書き込まれる。このようなデータは会計上不要であり、従ってこの目的で構造化する必要もない。アクセスログを解析するツールやサービスも数多く存在するが、構造化することなく解析が可能だ。このようなデータは「非構造化(Un-Structured)データ」と呼ばれる。または RDBMS ではないが、それぞれ異なる構造を持つことから「多構造化(Multi-Structured)データ」とも呼ばれる。インターネット、そしてスマートフォンに代表されるそのモバイル利用、さらにはその上で動く検索サービスや、ソーシャルメディアといったサービスの勃興は、このような「非構造化データ」を格段に増加させてきた。
このように見ると、店舗やコールセンターなどの伝統的なダイレクト・チャネルにおけるデータを中心とした「構造化データ」のオフライン世界と、同じダイレクト・チャネルでもインターネットを発生源とする「非構造化データ」のオンライン世界、この 2つが分断したまま存在していることがわかる。
データが変わっても活用目的は変わらない
このような 2つのデータ種は、活用目的によって、問題になる場合とならない場合がある。例えば Webサイトの運営状況を把握するなら、アクセスログ解析を単独で実施すればよい。世の中の流行を理解したいのであれば、ソーシャルメディアを傾聴するための各種サービスを利用することもできる。データを単なるトラフィックとして理解するのであればこれで充分であり、問題とはならない。一方で問題となるケース。それは顧客データとして活用したい場合だ。
なぜ問題なのか。これらのデータは、同じ人間が発生させているかもしれないからだ。ある顧客がバナー広告をクリックして、Webサイトに到着し、商品ページを閲覧して関心を持つ。その顧客が、実店舗で実物を見て購入する。数日後、利用方法に疑問を抱いてコールセンターに電話をかけ、その体験をそのままソーシャルメディアに書き記す。友人がそれを読んで、自らの購入判断に生かす…。2つの世界が分断されていると、このようなオンラインとオフラインを透過する顧客行動の因果関係をつかむことができない。「パズルのピース」を組み合わせれば浮かび上がるはずの顧客像を、見いだすことができないのである。
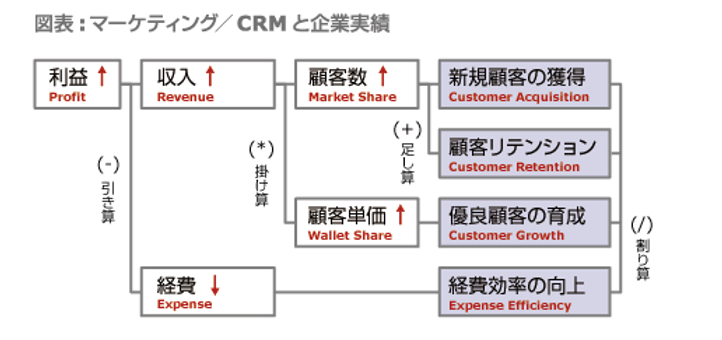
図表を見てほしい。マーケターは本来、顧客に対して働き掛けることによって、企業業績、つまり利益に寄与する。そして利益最大化のためには、収入を最大化しつつ、経費を抑える必要がある。収入は顧客数と顧客単価の掛け算によって構成されており、この 2つを増加させる必要がある。顧客数を拡大するには、新規の顧客を獲得しつつ、離反を阻止する必要があり、顧客単価を改善するためには、対価として顧客を満足させる商品/サービスを提供するしかない。
従って、顧客に対する働き掛けは、新規顧客の獲得、顧客リテンション、優良顧客の育成のいずれかを目的としたものに集約される。データが変わってもこれは変わらない。そしてこの観点で「誰に、いつ、どこで、どんな働き掛けをすべきか?」を理解するために、データが必要となる。しかしデータが不完全なら、顧客理解とそれに基づく働き掛けは凡庸で的外れなものとなり、最終的な企業業績も残念なものとなる。当たり前のことだが、収入は常に顧客からしか得られないからだ。
では、どうすれば「パズルのピース」を組み合わせ、顧客の姿を浮かび上がらせることができるのか。魔法の杖はない。一つ一つのデータを丁寧に統合し、分析していくことだ。次回以降で、この手順について触れていく。