この本書は2017年4月1日にTeradata Japanのブログに掲載された内容を、再掲載したものです。
掲載内容の正確性・完全性・信頼性・最新性を保証するものではございません。
また、修正が必要な箇所や、ご要望についてはコメントをよろしくお願いします。
著者 山本 泰史 (やまもと やすし)
「意思決定の自動化」と「リアルタイム・オファリング」
第13回: データマイニング
今回と次の回にて「意思決定の自動化」と「リアルタイム・オファリング」を推進していくための技術基盤として、構成要素の一部であるデータマイニングとキャンペーン管理のアプリケーションについて整理します。当社では、Teradata上で稼働するデータマイニングのアプリケーション「Teradata Warehouse Miner」と、キャンペーン管理のアプリケーション「Teradata Relationship Manager」を販売しています。いずれも処理の全てを Teradataデータベース内部で実施し、Teradataデータウェアハウス内部に存在するデータと、Teradata のパフォーマンスを最大限に活用することが可能な製品です。製品の詳細説明は以下のリンクをご覧頂ければと存じますが、本稿では両製品の活用を前提に論を進めていきます。
・データマイニング製品: Teradata Warehouse Miner
・キャンペーン管理製品: Teradata Customer Interaction Manager
データマイニング
データマイニングを進めるにあたってはまず、ビジネス課題を考える必要があります。マーケティングに限定した場合、最終的に利用されるスコアの代表的な 2つとして、確率スコアと分類スコアが挙げられます。確率スコアは、「どのような事象が発生する確率を析出したいか?」という問いに対する答えが、端的なビジネス課題となります。一方で分類スコアは「どのような違いに基づいて分類したいか?」がビジネス課題と言えますが、実際のデータに基づいて分類する手法がデータマイニングにおける分類であるため、得られた分類スコアに基づいて追加的な分析を行い、各分類、つまりセグメント毎の特徴を理解する必要があります。
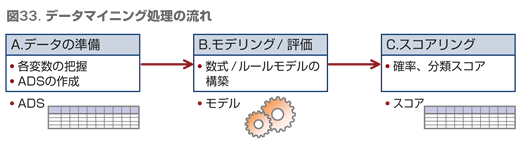
A. データの準備ビジネス
課題が決定された時点で「それを説明してくれそうなデータ」を準備する必要があります。データマイニングに利用されるデータは通常、単一の表形式であることが求められます。このような表は分析データセット(ADS: Analytic Data Set)と呼ばれています。図32 は ADS のイメージです。
マーケティングに限定した場合にはこの表におけるキーは顧客番号であることが多く、この場合それぞれの行がそれぞれの顧客に関する事実を示しています。つまりこの場合においてデータマイニングの対象は「顧客」であることを意味し、同様に対象が「商品」であるならば、それぞれの行がそれぞれの商品に関する事実を示してくれるよう表を作成する必要があります。そして各列は変数と呼ばれます。ここには例えば「年齢」、「支出金額」、「Webサイト訪問回数」等のような属性や指標が組み込まれます。また通信業であれば「通話回数」、「通話時間総量」等も組み込まれるかもしれませんし、小売業であれば「ブランドA 買上金額」、「ブランドB 買上金額」のように、通常のデータベース構造から考えれば「横持ち」形式のデータとして組み込みます。結果、利用候補となる変数は数千から数万にも及びます。
データマイニングの実施が高頻度で行なわれる場合、Teradata では大規模な、全社利用型ADS を構築することを提案しています。これは、それぞれのデータマイニング分析担当者が同様の変数を重複して作成するのを防ぎ、作成された変数を共用すると共に、定期的にリフレッシュすることによってデータ準備の手間を低減させるためのものです。この場合、単一の表とは言え、行数は全ての顧客、列数は 2,048N(データベースカラム上の制約から)に及びます。例えば、1,000万名の顧客を有する企業が、それぞれの顧客に関して 10,000変数を用いて分析したい場合には、1,000万行2,000列の表を 5つ構築し、分析担当者はその中から利用したい変数を抜き出してデータマイニング用の ADS を構築することが可能です。
正規形テーブルから ADS にデータを落としこむ場合、様々なデータ加工が必要になります。Teradata Warehouse Miner内のモジュール、Teradata ADS Generator では、この作業を行なうための機能として、集計、カウント、四則演算、カテゴリー化、非正規化等の変数作成の機能を有している他、ADS そのものを操作するためのジョイン、マージ、分割やサンプリングの機能を提供しています。また同じく Teradata Warehouse Miner内のモジュールである Teradata Profiler は、この前段階で必要になる基礎分析の機能を提供します。Teradata Profiler を利用することによって各変数の値がどのようになっているかを理解することが可能となり、作成する変数が利用に値するものであるかを検討する際に役立ちます。主な機能として、変数の代表値(平均値/最小値/最大値/最頻値等)を算出する機能(単変量統計)、質的変数の分布を俯瞰する機能(頻度分析)、量的変数を幾つかのカテゴリーに集約し、カテゴリー分布を俯瞰する機能(度数分布)、2変数間の相関を視覚化する機能(散布図)、複数変数間での相関係数を算出する機能(相関係数)等が提供されています。
B. モデリング/評価
データ準備のプロセスを経て ADS が構築され、データマイニングのメイン処理であるモデリングを実施するための環境が整います。モデリングとして実施されるのは各分析手法の適用です。分析手法は本稿でご紹介してきた、ロジスティック回帰分析、アソシエーション分析、デシジョンツリー分析、クラスター分析等が該当します。各分析手法は作成された ADS を読み込み、そこから傾向を導き出して数式、もしくはルールモデルを構築します。いずれもデータベース上で実行される SQL であり、その SQL を実行することによって、スコアを算出し、特定のデータベーステーブルにスコアが書き込まれます。これによって例えば「顧客番号 132番のキャンペーン反応確率は 0.8」といった予測が可能となります。評価段階ではこのモデルを評価用データセットに適用してスコアリングを実施します。評価用データセットは既に結果(反応した、しなかった)変数を有しているデータであり、このデータに適用することによってモデルの精度が一定以上であるかを評価します。
C. スコアリング
構築されたモデルを利用してリアルタイムでスコアリングする場合には、チャネルからの要求があった際にスコアリングを実施するために配備します。リアルタイムスコアリングである必要がない場合には、定期スケジュールに載せてスコアリングジョブを実施し、スコアを算出します。また必要に応じて追加の処理を行い、活用できる形式にします。例えば後述するキャンペーン管理ツールで、「確率上位 1,000名に対して案内を実施したい」といったような要件がある場合、確率値を元にランク付けを行い、キャンペーン管理ツールで利用したい形式で保持します。また、複数の確率スコア間で競争させ、オファー内容を確定させたい場合(第11回参照)には、後処理としてスコア間の比較と、最高スコアの選択、そしてそれに基づく案内オファー番号の付番が必要となります。以上の流れを整理したのが図33 です。
次回は、技術基盤としてご紹介するもう一つの内容「キャンペーン管理」について概観します。