この本書は2017年4月1日にTeradata Japanのブログに掲載された内容を、再掲載したものです。
掲載内容の正確性・完全性・信頼性・最新性を保証するものではございません。
また、修正が必要な箇所や、ご要望についてはコメントをよろしくお願いします。
著者 山本 泰史 (やまもと やすし)
「意思決定の自動化」と「リアルタイム・オファリング」
第2回: 自動化すべき意思決定、すべきでない意思決定
前回、意思決定の枠組みとして戦略的意思決定と戦術的意思決定について触れました。今回はこの前提の下、自動化していくべきポイントとすべきでないポイントを選り分け、意思決定上発生するボトルネック、そして自動化すべき意思決定に適用する自動化ロジックについて整理します。
意思決定プロセスの整理
図2 は、意思決定のプロセスを整理したチャートです。データから知識を析出する部分が一般に分析と呼ばれる作業であり、意思決定、特に戦略的意思決定において重要な位置づけ(問いは何か?、問題点は何か?)を担っています。それぞれのデータは独立して事実を有しており、それを組み合わせることによって、モノゴトの背景にある原因や問題点の把握/類推が可能となります。そしてこれによって知識が生まれ、後続する行動を方向付けする(何を目的とすべきか、原理原則や留意点は何か等)ことができるようになります。
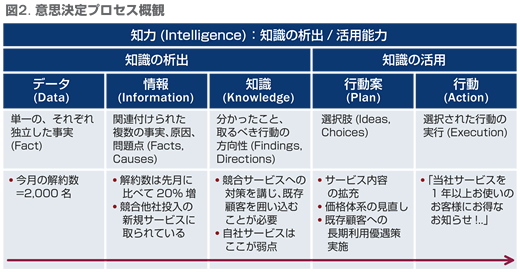
得られた知識に基づいて、幾つかの行動案が選択肢として作成されます。そしてその中からメリット(目的合致性、効果)とデメリット(障害、コスト、リスク等)を考慮し、1つないしは複数の行動案が策定されます(ときには「何もしない」という選択肢も存在します)。狭義の意味ではここで「選ぶこと」が意思決定です。最終的に選択された行動を実行に移すことによって、意思決定のプロセスが完結します。なお、実際には実施した結果がどうであったか、成果を評価することも必要となりますが、ここでは割愛します。
さて、ここでドラッカーが区分した戦略的意思決定と、戦術的意思決定に話を戻します。両方の意思決定において図2 のようなプロセスを踏むことになりますが、戦略的意思決定の場合「未知」の知識に対処するという観点から知識の析出に力点が置かれます。一方で戦術的意思決定の場合には「既知」の知識に対処するために、すべきことは明確であり、知識の活用部分、より正確には行動/実行に主眼が置かれます。
そして長い時間軸で捉えた場合、企業はデータを蓄積し、分析することによって様々な「未知」を「既知」へと転換していきます。だとするならば、既に「既知」へと追いやった事実/原因/問題点/知識を、人間が毎度毎度、何度も反芻する必要は無いはずです。
意思決定上のボトルネック
このような観点から考えると、自動化すべきポイントと、すべきでない、より正確に表現するならば自動化できないポイントが明確になります。「未知」の知識を析出し、とるべき行動の選択肢を捻り出し、実行へと導くような戦略的意思決定、そして戦術的意思決定における例外事象への対処に関しては、自動化の対象から外れます。人間が意思決定をしなければなりません。これに対して戦術的意思決定は「既知」の知識を対象としており、とるべき行動の選択肢が洗い出されており、後は実行に移すだけであるため、自動化の対象となりえます。
CRM/顧客管理/マーケティング分野における行動とは、突き詰めれば「顧客に対する働きかけ」であり、キャンペーン活動、もしくは(セルフサービスチャネルによる接客も含めた)接客活動に集約されます。発生したデータが何か重要な兆候を示していて、早急な行動が求められている(ある顧客の特定ニーズを検知した等)とした場合、そこから分析を開始し、知識を析出し、とるべき行動を考え、実行に移すまでの時間はそのままボトルネックとなります。もちろんそれが今までに遭遇したことも無いような兆候ならば、得られるのは「未知」の知識であり、必要充分な時間をかけて行動まで落とし込んでいく必要がありますが、もしそれが「既知」の知識ならば、分析と適用の時間がタイムラグになってしまいます。より端的な表現をするのであれば、「既知」の知識を行動へと転換していく際のボトルネックとなっているのは「人間」なのです。このボトルネックが発生する理由は、同じ人間が人手を介した分析と適用プロセスを反復している場合もあれば、ある人間が獲得した知識と対処方法を他の人間が共有できないために、再発時に反復している場合もあるかもしれません。いずれにしてもそれを解決してくれるのは「自動化」です。
(未知の知識を発見/析出していく戦略的意思決定、もしくは戦術的意思決定でも不測事態に対処するような場合は人手を介して分析を進めることが求められます。そのための手法としてレポーティング、非定型検索、多次元分析、データマイニング等、様々な手法が存在しますが、ここでは本論から外れるため割愛します。)
自動化ロジック
自動化を進めていくにあたって必要となるのは、ロジック、もしくはルールと呼称される、IF THEN形式の構造体です。ある条件A が発生したら(IF)、一つないしは複数の選択肢の中から行動B を選択する(THEN)という論理的な流れ(IF A, THEN B)をデザインし、これをコンピューターに自動実行、代行させます。この構造体をデザインするのは、特に複雑な話ではなく、ここまでで触れてきた意思決定のプロセスと等しいものです。データにある傾向が表出したら、「それはこういう意味である」と捉え(情報)、「こういうビジネス機会が存在している」と理解し(知識)、「とりうる選択肢の中で最も成果に近いのはこの行動である」と判断し(行動案)、選択された行動を実行します(図2参照)。この流れが一本の線でつながるのであれば、それはそのまま「データにある傾向が表出したら、選択された行動を実行します(=IF ある傾向, THEN 選択された行動)」という構造体に変換できます。従って、自動化ロジックを構築するためにも知識析出、つまり分析のプロセスが必要です。違いはデータが発生してからこのような知識析出と適用を進めるのか、再度同じようなデータが発生したときのために知識析出と行動選択を行なっておくのかの違いだけです。しかしながら、最初のデータと最後の行動を IF THEN形式で結びつけることによって、自動化が可能となり、行動に至るまでのサイクルタイムが短縮されることになります。また、データの発生自体を見逃してしまうリスクも回避することが可能となります。
また、同じデータが発生した、もしくは同じ情報が得られても、異なる知識や状況を人間の側が有していて、最終的な行動選択は人間がしなければならない場合もあるかもしれません。このような場合には、「半自動化」という手法を選択するのが望ましいです。別名リアルタイム・ビジネス・インテリジェンス、もしくは例外アラーティングと呼ばれるこの手法は、ある条件を設定して、データベース上に流れ込むデータがそれに合致するかどうかをモニタリングします。仮にデータが条件に合致する場合には、その旨を知らなければならない人間に通知するように設定をしておきます。通知された人間は、それ以外に把握している異なる知識や状況と合わせて、適切な行動を選択します。このような手法が「半自動化」たる所以は、IF THEN形式の IF部分を確定させ、しかしながら THEN部分は未確定で人間に判断を委ねるためです。もっともコンピューター的には THEN部分に「誰々に通知する」という行動をセットするだけなので、IF THEN形式の構造体は全自動と同じです。
以下の図3 は、「未知」の知識、「既知」の知識、そして「既知」の知識を自動化した場合のデータ発生から行動までのサイクルタイムを表現したチャートです。既知の知識を反芻して行動を起こす時間分だけ、自動化に比して時間を要し、これがボトルネックとなります。次回はこのボトルネックを解消すると共に、自動化を推し進めることによってどのようなメリットが得られるのかについて整理します。
