本書は2017年4月1日にTeradata Japanのブログに掲載された内容を、再掲載したものです。
掲載内容の正確性・完全性・信頼性・最新性を保証するものではございません。
また、修正が必要な箇所や、ご要望についてはコメントをよろしくお願いします。
著者 山本 泰史 (やまもと やすし)
データマイニング ― 確率で考える
「紙おむつとビール」からの 20年
1992年の『ウォール・ストリート・ジャーナル』に「Supercomputers Manage Holiday Stock( スーパー・コンピュータが管理するクリスマス休暇の在庫)」なる記事が掲載された。この記事で Teradata Corporation(当時の NCR Corporation)のコンサルタントが、「紙おむつとビール」に関する分析エピソードを紹介している。記事には「夕方 5時に使い捨ておむつを買った人が、一緒に半ダースのビールを買う確率が高い」こと、そして「ビールのおつまみになるスナックの売り上げを上げるため、おむつの棚の並びにスナックを配置したところ、その時間帯のスナックの売り上げが 17%増加した」ことがつづられている。
以降、いろいろな尾ひれも付きつつ、データマイニングの典型例として引用されるこの話には、当社の社内で語られている裏話がある。まず、その後の実地調査によると、このデータが発生した店舗の商圏には工場が新設され、それに伴ってここに勤める若い家族層が移り住んできたこと。次に、この家族の夫が妻に頼まれ、仕事帰りに紙おむつを購入し、そのついでに自分用のビールを購入すること。このため、この種の購買が発生するのは夕方 5時以降の時間帯であること。この現象はこの店舗に特有であり、一般的に紙おむつと関連購買確率が高いのは、当然ベビー用品であること…などである。もちろん売り場の陳列も重要だが、ポイントカードもない時代に、データがくっきりとその店舗の顧客像を浮かび上がらせた点が、このエピソードの重要なポイントだ。
そして 2013年。Amazon のレコメンデーションを例に出すまでもなく、データマイニングの技術は広く普及し、われわれの生活の中に組み込まれている。今回は、このデータマイニングの分析手法について基礎的な整理を行い、オンラインとオフラインの双方を含めた顧客データへの適用について考える。
確率と大数の法則
データマイニングの分析手法は、リポーティングのように事実のデータをそのまま眺めるのではなく、それを用いて確率を算出する点に特徴がある。基本的なことだが、確率データは 0 から 1 の間をとり、1 に近ければ起こる確率が高く、0 に近ければ起こる確率が低い。世の中のさまざまな事象に対して広範に活用でき、便利な指標だ。 これがどのように算出されるかというと、考え方は単純で、過去に起こった同様の事象がその根拠となる。例えば 10名の顧客がいて、商品A を購入したのはこのうち 1名だけ、それ以外のデータ傾向はまったく同じであるとすると、同じデータ傾向を持つ顧客が商品A を買う確率は「1/10=0.1」である。つまり、過去の発生割合を将来の発生確率に読み替えているのだ。そのため、確率の算出は過去にそのデータが発生していることが前提となり、これをベースにして計算が行われる。以降で、このような確率を利用する分析手法の代表例を整理する。
離反/購入/成長の確率
離反を例にとると、過去に離反した顧客のデータと、離反していない顧客のデータが用いられる。この結果データ(結果変数)に対して、離反と関連性のあるデータ(説明変数)が分析に投入され、より関連性の高いデータを重視するようなモデルが作成される。作成されたモデルに予測したい顧客のデータを投入すると、その顧客の離反確率が算出される。このプロセスをスコアリングと呼ぶ。具体的な分析手法として、ロジスティック回帰分析やディシジョン・ツリー分析が挙げられる。
同時発生確率
上述の分析が単一事象の発生確率を算出するのに対して、2つの事象が同時に発生する確率を算出するのが、この手法である。商品間の関連購買確率や、チャネル間の親和性/誘導確率を算出する際に用いられる。手法としてはアソシエーション分析が代表的だ。基本的な考え方は単純で、例えば紙おむつが含まれるバスケットが 100 で、そのうち 14 のバスケットにビールも含まれるなら、14%の関連購買確率である。
確率の比較と所属確率
クラスター分析に代表される、近似の顧客をグループ化する手法も、よく利用される。この手法も確率に依存している。クラスターとは日本語で「房」を意味し、それぞれのグループを指す。データに基づいてクラスターの中心を決定し、各顧客が中心からどの程度離れているかに基づいてクラスター所属確率が決定される。各クラスターに所属する確率が比較され、各顧客は最も確率の高いクラスターに所属する。
確率データは、その後の意思決定に活用しやすいという特徴がある。例えばキャンペーン反応確率を算出し、確率を順位変換すれば、上位3万名に案内するといった条件での対象顧客抽出に活用できる。また、この確率が信頼に足るものであれば、そのまま意思決定を自動化できる。
そしてこの信頼に値するかどうかを決定付けるのが、データの種類と量である。顧客行動を予測する場合、その顧客のさまざまな側面をデータとして考慮に入れなければならない。顧客の気分や体調、財布の中身など、本来知り得ないデータも有していれば、予測の正確さは増す。だがこれは非現実的だ。しかしながら、伝統的な顧客データのみならず、オンラインにおける顧客行動や顧客の意見を含めることができれば、完全には程遠いにしても、正確さを増すことはできる。
また、データ量は結果を安定させる。サイコロを振って 1 の目が出る確率は「1/6=0.1666...」である。しかしながら実際にサイコロを 6回振って均等に 1 から 6 の目が出ることは、まずない。でもサイコロを何度も振り続ければ、次第に 1 の目が出る確率は 0.1666... に収束していくだろう。これは大数の法則と呼ばれ、データの量が多ければ結果は安定し、算出結果はより信頼に足るものとなる。
ケーススタディ
確率データを意思決定の自動化に活用している例をご紹介したい。
ある海外の金融機関では、オンライン・バンキングで表示するバナー広告を、来訪顧客に応じてパーソナライズさせている。この金融機関では、数十種類のバナー広告をランダム表示していたが、クリックスルー率は凡庸だった。そのためオンライン、オフライン双方のデータを活用して、顧客とバナー広告ごとの反応確率を算出し、確率を比較することにした。
図表はそのイメージだが、各顧客に対して、それぞれのバナー広告を提示した場合の反応確率が算出される。そしてその中で最も確率の高いバナー広告が選択され、顧客が来訪したらそのバナー広告が表示される。このようなアプローチによって、この金融機関ではクリックスルー率を 20倍以上改善することに成功した。
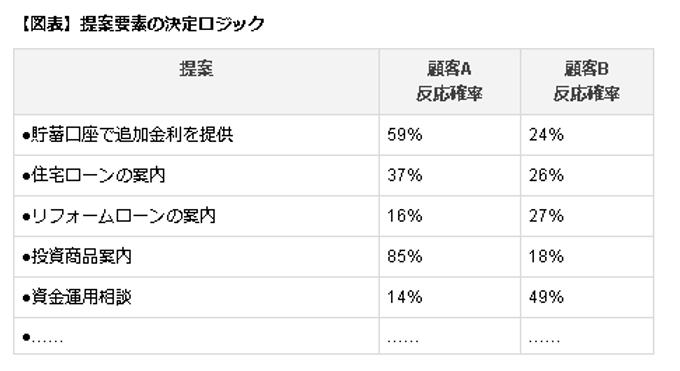
さらにこの金融機関では、得られた知識をコールセンターでの提案にも応用した。顧客がコールセンターに電話をかけ、その顧客が識別されると、エージェントの画面には、図表に基づいて確率上位3つの提案が表示される。オンライン・バンキングではバナー広告の画像が 1つ表示されるが、ここではエージェントが話をするためのスクリプトが用意され、顧客の提案許容度に応じて上から順に提案ができるようになっている。このケーススタディの肝は、オンライン、オフラインを問わず、「誰に、何を提案すべきか」という意思決定を自動化し、顧客が来訪する「真実の瞬間」に向けて、周到に準備をしている点にある。