本書は2017年4月1日にTeradata Japanのブログに掲載された内容を、再掲載したものです。
掲載内容の正確性・完全性・信頼性・最新性を保証するものではございません。
また、修正が必要な箇所や、ご要望についてはコメントをよろしくお願いします。
著者 山本 泰史 (やまもと やすし)
アソシエーション分析
アソシエーション分析は、マーケットバスケット分析とも呼ばれ、小売店の買い物カゴに一緒に放りこまれた商品の組み合わせを理解することから名前がつきました。しかしながら同じ考え方を利用すれば、クレジットカードの利用場所、通信や金融サービスの各商品間の購買相関にも適用することが可能な手法であり、購買にこだわらずに顧客の行動イベント(例えばWebサイトの商品閲覧)とその他の行動イベント(商品購入)の相関を導き出すことを可能とする分析手法です。アウトプットとしては決定木同様IF THEN形式のルールを析出しますが、決定木と異なる点は、それぞれのルールが独立していて、またこのルールに対して幾つかの指標を提供し、この指標に基づいてルールを評価することが可能となっている点です。また、このルールは組み合わせの数だけ存在するため、非常にコンピューター資源を多用する手法でもあります。
アソシエーション分析にて用いられるデータセットは、図40のようなイメージになります。小売店の買い物カゴになぞらえるのであれば、このデータの元となるのはレシート明細データです。ここで[商品番号]として捉えられている変数は、「アイテム」と呼ばれ、発生事象を意味します。従って必ずしも購買という発生事象にとらわれる必要はなく、ATM端末の操作や、Webサイトへのアクセス、はたまた30歳代といった事象もアイテムとして捉えられます。例えば、ある百貨店で何を購入したかではなく、どのテナントで購入したかという事象もここに含めることが可能です。

続いて、[バスケット番号]として捉えている変数部分は「コンビネーション」を意味します。同じバスケットに放り込まれた、つまり同じレシートに記載された右側の商品番号は、同じコンビネーションであると解釈されます。#1001のバスケットに商品#19332、#19345、#19233が含まれていたということを示しています。同じような概念で、ある顧客をグルーピングすることも可能です。この場合は、ある顧客の顧客番号がバスケット番号の代わりに用意され、単一顧客の発生事象、つまりアイテムが左端のデータとして用意されなければなりません。上述の百貨店テナントの例であれば、顧客+日付で変数を作成すれば、ある1日の単一顧客行動を括ることが可能となります。
最後に、[購入順]として用意されている変数は、「シーケンス」として捉えられます。この変数を用意するかどうかはオプションです。追って詳しい説明を加えますが、このデータを利用することによって発生事象を時系列順で理解することが可能となります。上述の百貨店テナントの例であれば、顧客が店内各テナントで買物をした順番をデータセットに取り込むことが可能であることを意味しています。
このデータセットは、今までの分析手法で利用しているものと若干異なります。今までに利用してきた分析手法でのデータセットは、左端に顧客もしくはそれに準ずる対象をリストアップし、それに対する各変数を右側に追加する形態でした。つまり左端の変数で全てのデータサンプルを一意に識別でき、左端の変数値は常に1回しか発生しませんでした。2回発生することは許容されていなかったのです。これに対してアソシエーション分析では、発生事象そのものが分析の対象となるため、図40の例における商品番号は何度も重複して表出することになります。そしてこの重複発生度合いを理解することがアソシエーション分析の分析テーマとなるのです。
■構築されるルール
アソシエーション分析において構築されるルールは、IF THEN形式で示されます。IF A THEN Bで、「もしAが発生したらBが発生する」というルールを言い表しているのですが、ここでAとBに該当するのが、アイテム部分に相当するデータです。上述の図40では、商品番号に該当します。アソシエーション分析は、全ての商品番号の組み合わせを吟味します。仮に商品番号が、#19332、#19345、#19233の3値しか存在しなかったとした場合、検討するルールは以下のようになります。
IF #19332, THEN #19345
IF #19345, THEN #19233
IF #19233, THEN #19332
ここで、IF部分にて指定されるアイテムを「条件部アイテム」と、そしてTHEN部分にて指定されるアイテムを「結論部アイテム」と呼ぶことが出来ます。ちなみにシーケンスを考慮する場合は、この3つのルールのそれぞれ条件部と結論部を入れ替えたルールを異なって扱います。シーケンスを考慮しない場合は、どちらが先に発生した事象かを問わず、「一緒に発生した事象」として両方を扱います。
■算出の実施
商品番号#19332では味気ないため、この商品は「膝丈のロングニットカーディガン」としましょう。合わせてデータの発生源をどこかの百貨店、もしくはアパレルショップの婦人服売場とします。また、1回の来店で洋服を10着、20着と購入する顧客はそうざらにはいないので、図40のバスケット番号に相当する変数に「顧客番号」を利用します。これによって1回の買物における購買パターンではなく、それぞれの顧客のコーディネイトパターンを理解しようと試みます。また、購入シーケンスに関してはここでは無視する(利用しない)こととします。「膝丈のロングニットカーディガン」ということは、膝のあたりまでニット地に包まれることになり、コーディネイトという観点からは、ボトムにどのような衣類を合わせるかが品揃えや接客販売上関心の高いテーマになるかと思います。端的な質問にするならば「うちのお店に来店するお客様は、”膝丈のロングニットカーディガン”にどんな衣類をコーディネイトしていらっしゃるのだろうか?」です。当然ながら、ほとんどの顧客のクローゼットはその店舗で購入された衣類で占有されたものでは有りません。また、全ての商品が「膝丈のロングニットカーディガン」と組み合わせるために購入された商品でもありません。従ってその完全な姿を得ることは難しいのですが、それでも何らかのヒントは得られるかもしれません。
このテーマに対する解を得るため、データセットを用意してアソシエーション分析を実施した結果が図41になります。おそらく婦人衣料の売場には膨大な商品が陳列され、販売されているはずですが、便宜的に5つの商品に関するルールのみを記述しています。また、各商品は単品ではなく、ある程度集約された商品分類でアイテム化しています。つまり「デニムパンツ」は、ブランドAもブランドBも、異なるサイズやカラーも同じ商品として扱っています。当然ながら単品レベルで実施したければそれも可能ですが、ここでは傾向を見たいため、このようにします。
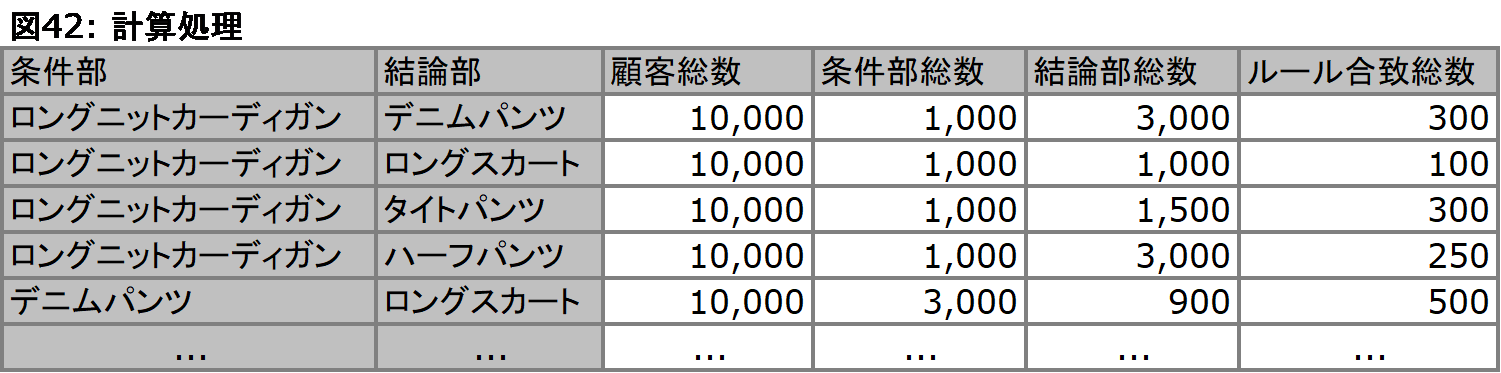
仮に5つの商品に関するルールを考えた場合、条件部と結論部には4+3+2+1 = 10通りの組み合わせに相当するルールが表出することになります。アソシエーション分析ではこの全ての組み合わせを検討し、それぞれに対してご覧の3つの指標値を算出付与します。そして、これらの指標値の算出に用いたのが、図40のデータを全て吟味し、数え上げて得られた次のようなデータです(図42)。
[顧客総数]は、コンビネーションの単位となった顧客の数を意味します。そして[条件部総数]は、条件部に記述されている商品を購入した顧客の総数であり、[結論部総数]も同様です。ルール合致総数は、顧客の中で条件部に記述された商品と、結論部に記述された商品を両方購入した顧客の数を表します。そしてさらにこの計算処理結果を利用して、図41の最終アウトプットを算出しています。

■得られた指標値の見方
図41で得られた指標値は、図42の結果を利用して以下のように算出されます。
支持度(Support) :
[ルール合致総数] / [顧客総数]にて求められます。全体の母集団の中で、このルールがどの程度発生しているか、つまり支持されているかを意味します。例えば図41、1番上の行を考えた場合、全 10,000名の顧客のうち、300名の顧客が「ロングニットカーディガン」と「デニムパンツ」という組み合わせを支持したということを告げています。この指標は0から1の値をとり、この値が高ければ高いほど、ここで示されたルールの発生頻度が高く、「よくあること」であるということになります。尚、ここでは分子に[ルール合致総数]を利用していますが、分子を代えることによって、[条件部総数]に対する支持度、[結論部総数]に対する支持度を理解することも可能です。これらの値は一般に「購買率」とも呼ばれます。
確信度(Confidence、信頼度とも) :
[ルール合致総数] / [条件部総数]にて求められます。条件部アイテムの発生頻度に対して、条件部アイテムと結論部アイテムの組み合わせが発生した回数の割合を示します。図41の1番上のルールを考えた場合、「ロングニットカーディガン」を購入した顧客は1,000名、その顧客の内「デニムパンツ」も購入した顧客は300名いたことを意味します。これを分母、分子に置いて計算されたのが0.3という確信度です。これは他の確信度と比較すると、相対的に高い組み合わせであることが見て取れ、多くの顧客にとっての「フェイバリット・コーディネイト」であることが想定されます。IF THENで記述されたルールが、どの程度の確信度を持っているかを意味しており、条件部アイテムが発生した場合、どの程度の確率で結論部アイテムが表出するかを表しています。一般に併買率、関連購買率と呼ばれる指標は、この値のことを意味します。この指標は0から1の値をとり、この値が高ければ高いほど、このルールで示された2つのアイテム間に強い関連性が存在することを意味しています。
改善度(Lift) :
[確信度] / ([結論部総数] / [顧客総数])で求められます。言い換えれば、[確信度] / [結論部に関する支持度]であり、分子にこのルールの確信度、分母に結論部の支持度を置くことによって、ルールの確信度を評価しています。支持度とは、その事象が「よくあること」、つまりありふれた事象であるかないかを表した指標であると説明しました。もし結論部がありふれた事象であれば、条件部との組み合わせに関してもこの事象の「ありふれた」度合いを考慮して、確信度を小さく見積もる必要があります。図41の一番上の行では、改善度は1.0となっています。これは、確信度=0.3を分子に、結論部総数/顧客総数 = 3,000 / 10,000 = 0.3を分母に置いて算出されています。結果、分母、分子共に0.3となり、0.3 / 0.3 = 1となります。これは、得られた確信度は、条件部との組み合わせにおいても正しく作用しており、結論部そのものが保持している支持度を基準にした場合と等しいということを意味しています。改善度はいかような値をもとりえますが、改善度の基準値は1.0になります。1.0より高ければ、条件部との組み合わせでは確信度が改善されたことを意味し、逆に1.0より低ければ、条件部との組み合わせによって、確信度がマイナスの方向に改善されたことを意味しています。つまり、条件部との組み合わせによって確信度がどれだけスパイクしたかを表しているのが、改善度ということになります。ルールに対して示された確信度は、支持度を基準値として高い低いという判断がなされるということです。
「ロングニットカーディガン」と「デニムパンツ」、そして「ロングニットカーディガン」と「タイトパンツ」の組み合わせを比較してみましょう。いずれも確信度は0.3です。つまり確率的には等しいように思えます。しかしながら改善度を見ると、前者が1.0、後者が2.0となっています。理由は、結論部に記された「デニムパンツ」と「タイトパンツ」の総数に表れています。前者が3,000、後者が1,500です。これは単純に母集団10,000名のうち、3,000名が「デニムパンツ」を購入、1,500名が「タイトパンツ」を購入したことを意味します。これは「デニムパンツ」がよりメジャーな商品であることを意味し、相対的に「タイトパンツ」がマイナーな(より購入発生頻度が低い)商品であることを意味します。ここから考えると、メジャーな商品とマイナーな商品が同じ確信度を表出させているのだから、マイナーな商品が含まれた組み合わせをより高く評価すべきであるというのは納得がいくものです。ここからは消費者心理に対する類推ですが、「デニムパンツ」の方がより汎用的にコーディネイトされる商品であるため、確信度は高いが、改善度はそれほどでもないのだろうと判断が成り立ちます。言うなれば「無難な、大衆受けする」商品なのです。また、「ロングニットカーディガン」と「デニムパンツ」、そして「ロングニットカーディガン」と「タイトパンツ」では、後者の方が強い結びつきであると言えます。
このような例はスーパーマーケットの特売商品や、売れ筋の商品を想像していただければ分かりやすいはずです。このような商品はどのバスケットにも含まれる割合が高く、本質的な商品間の結びつきというよりも販売の仕方や商品そのものが持つ販売力が支持度を向上させています。ほとんどは条件部アイテムの影響に頼らなくても販売できた商品であるということが、改善度によって示されるのです。
■ルールの評価
確信度と改善度は、アソシエーション分析で得られたルールを考察する上で、2つの視点を与えてくれます。確信度は、純粋な発生確率を理解することを可能にしてくれますが、結びつきが強いルールであるかは説明していません。改善度を合わせて利用することによって、そのルールが本質的な関連性を意味しているかどうかを見分けることが可能となります。一方で、改善度だけを見た場合にもそのルールの本質的な関連性を見誤る可能性があります。改善度100のルールが存在したとしましょう。改善度の基準値は1ですから、一見かなりの結びつきの強さを思わせる値です。しかしながらこれを分解したところ、[確信度] = 0.000001、[結論部の支持度] = 0.00000001であり、この2つの値を利用して改善度を算出したことによって[改善度] = 100が得られたとしたら、このルールは有意と言えるでしょうか。現実の例にあてはめれば、「3年に1度売れるか売れないかの結論部商品がたまたま売れた。そのとき一緒に購入されたのが条件部商品だった」といったところです。このルールは信頼に足るものでしょうか。それとも偶然の産物でしょうか。得られたルールを正しく評価するためには、このような偶然と思われるルールを足切りし、正しいルールを適用する他ありません。あるアイテムの発生頻度があまりに多すぎる場合と、あまりに少なすぎる場合に露見してしまう改善度の弱点を回避し、適切にルールを発見する必要があります。例えば改善度 < 1.0を無視すると共に、結論部アイテムの発生総数 > 100などのような形で絞り込むことによって、本来求めたいルールを見出すことが可能となります。ただし、上述の絞り込み条件は分析ケースごとに微調整を加える必要があります。多くのケースにおいて改善度 = 1.xは凡庸なものであり、膨大に存在します。この場合改善度のハードルを上げて(例えば改善度 > 10.0)ルールを識別することが必要になりますし、結論部アイテムの発生総数は、バスケット数全体とのバランスや、安定した結果が得られる絶対値(例えば10以上等)を考慮して決定し、足切りをしなければなりません。そして現実にはさらに既知のルールや、説明不能なルールも排除(無視)することによって、本来発見したかった未知のルールにたどり着くことになります(もちろん欲しいルールが見つからないケースもあります)。
一方で別な観点として、無条件に足切りしてはいけない場合もあります。もし、実施したいと思っているマーケティング活動のテーマが、「スーパーニッチなコンビネーション」やそのコンビネーションを生成させた「スーパーニッチなセグメント」の発見にあり、当該セグメントが自社のビジネスにおいて収益採算に見合うのであれば、偶然と思われる中にあるルールこそ探しているものです。例えばオンラインCD販売サイトの場合、売場スペースは無限にあり、1枚のCDを追加で陳列するコストは限りなく低く済みます。メジャーセグメントを理解するコストも、スーパーニッチセグメントを理解するコストもさしたる差はありません。そしてこれらの顧客における1人あたりの収益貢献度は、それぞれのセグメントが購入するCDの販売パフォーマンスと正比例の関係にありません。逆にスーパーニッチの方のほうがヘビーリスナーかもしれませんし、街のCDショップに陳列してないCDを探す顧客という意味においては、欲求の度合いが高い顧客かもしれません。街のCDショップが新譜やメジャーなミュージシャンの作品に重心を置く理由は売場の販売効率です。しかしながら、そのような販売効率の足かせが存在しないビジネス形態であれば、どちらのセグメントも等しく考えることが可能になります。そのとき、改善度の持つ指標特性がまさに「それを指し示してくれる道標(みちしるべ)」になるのです。
■指標の変化を捉える
ルールに関する指標は、異なるデータに対してアソシエーション分析を行なえば、当然ながら結果が変化します。従って、どのように母集団を定義するかが重要になります。また、異なるデータに対してこの分析手法を実施することによって、得られる変化を積極的に活用することも1つの適用方法です。以下は、アソシエーション分析を適用して得られた結果から「真っ赤な、大き目の革製トートバック」に対するルールだけをピックアップしたものです。しかしながら対象となるデータセットは2つに分けています。左側は4月から9月の「春夏」データ、そして右側は10月から3月の「秋冬」データです。「真っ赤な、大き目の革製トートバック」を肩にかけた人を頭に思い浮かべて頂きたいのですが、かなりインパクトのある商品であり、一緒に着用する洋服、特にその色合いにはかなり気を使うはずです。シックに抑える顧客かもしれませんし、もしくは正反対の、余程バサラな色彩感覚を持ち合わせている顧客かもしれません。そこで、ここでは結論部の商品を「色」でグルーピングしています。
結果を見ると、購入はモノトーンと茶系の色に集中していることが伺えます。しかしながら春夏と秋冬では、色合いの濃さに違いが見られるようです。また、改善度を見ると黒、グレーはどちらを見ても高い値にあり、本来の結びつきが強いのは、この2色であることが想定されます。もっとも、今我々は、「真っ赤な、大き目の革製トートバック」を基準に物事を把握しようとしていますが、この商品を購入した顧客心理としては「普段から購入する商品はどうしてもモノトーンが多い。だからアクセントをつけるために真っ赤なバッグが必要!」だったのかもしれません。
そしてもう1つ着目すべき点は、支持度合いです。このバッグの購入顧客の組み合わせ購入の支持度合いは春夏と秋冬で倍の違いを示しています。そしてこの結果は確信度にも表れています。元々色を基準にしているため、確信度そのものはおしなべて高い値です。しかしながらこれらの顧客は、より秋冬物の方に食指が動くことが見て取れます。これが正しいとすれば、これらの顧客に対して検討すべき次の商品オファー、案内クリエイティブに用いる商品イメージ写真、重点的に案内をするタイミング等はより明確になるはずです。
この例は、あくまで分かりやすい結果が得られるように作成したデータですが、複数のデータに対してアソシエーション分析を適用することによって得られる変化は、この例以外にも更なる理解を我々に与えてくれます。例えば関連購買を誘発するような陳列をする前と後にデータを分ければ、その効果を見ることが出来ます。店舗Aと店舗Bのデータに分ければ、商圏毎の顧客嗜好の違いが映し出されるかもしれません。もしくは単純な店舗運営や陳列の巧拙がそこに表出するかも知れません。例えば「パスタ」と「パスタソース」、「ワイン」と「チーズ」といったルールは、驚くようなルールではありません。別段データマイニングを利用しなくとも思いつくルールです。普通に考えれば強い結びつきが得られるはずですが、実際は陳列やチラシの訴求方法に差があれば、この値には差が出ます。これはつまり、その店舗の来店客あたりの買上点数に差が出ることを意味し、そしてそれはそのままその店舗の販売力を意味します。昨今のように人口が伸び悩み、オーバーストア化していくとき、「顧客が1回来店してくれること」の価値は今まで以上に希少になってきます。この数少ないチャンスに「もう1品」買って頂けるかどうかは、非常に重要なテーマであるはずです。そして、アソシエーション分析に限らずデータマイニングのテーマは、必ずしも「センセーショナルで、突飛な」ルールを発見することではありません。得られたルールを用いて日常業務を、顧客へのアプローチを改善することにあるのです。

■アイテム化に関する考察
ここまで「膝丈のロングニットカーディガン」や「真っ赤な、大き目の革製トートバック」といった、いかにもという商品をアイテムの例として用意しましたが、アイテムは、「何らかの事象が発生したこと」として捉えることが可能です。ここではその例を幾つか見て行きます。
複数の商品を集約する
どのようなルールを導き出したいのかにもよりますが、いわゆる単一の商品に限る必要はありません。特定ブランドのシャンプーに関するルールを導き出したい場合もあれば、シャンプーというカテゴリーそのものに対するルールを導き出したい場合もあると思います。必要なレベルに商品を集約することによって、このような作業を行なうことが可能です。また条件部アイテムと結論部アイテムのレベルが異なっても構いません。例えばネイビーブルーの紳士スーツ(ブランド、サイズ、スタイルは問わないため、集約)に対して関連性が強い商品を単品(例: ポールスチュアートのドレスシャツ、白地にピンストライプの青)で導き出すことが可能です。
複数商品のコンビネーション
また、商品Aと商品Bを一緒に購入したという条件に対するルールを導き出すことも可能です。ここまでで説明してきた例では、簡略化のため条件部アイテム、結論部アイテムともに1つの商品を想定してきましたが、それぞれが複数の商品の組み合わせでも構いません。また商品Aを購入したが商品Bを購入しないという条件に対するルールを導き出すことも可能です。つまりは、あるコンビネーションを1つのアイテムとして捉えることによって、それを条件部(あるいは結論部)にまとめいれることが可能となります。例を挙げると、IF 豚挽き肉 AND 絹ごし豆腐 THEN テンメンジャン (IF A and B THEN C)、IF 豚挽き肉 AND NOT 茄子 THEN 絹ごし豆腐(IF A and not B THEN C)といったところでしょうか。もともとアソシエーション分析の意味は、複数事象のコンビネーションが発生する頻度の強さ、弱さを理解することにあり、これを顧客マーケティングの観点で捉えた場合、顧客の背後に存在する生活の有様を捉えることにあります。単一の事象そのものは、言わば点です。しかしながら複数の事象をつなげることにより、線になり、面となります。豚挽き肉の購入、絹ごし豆腐の購入、テンメンジャンの購入はそれぞれ点ですが、それぞれをつなげることにより、夕食のテーブルに並ぶ麻婆豆腐が「面」として浮かび上がってくることになります。その意味においてこのような商品ではないアイテムをアイテム化し、ルールに組み入れることができれば、顧客の背後に存在する生活を記述するのにより適したルールが構築可能となります。
商品ではないアイテム
アイテムには商品以外の事象を含めることが可能です。例えば、女性が購入(顧客のデモグラフィック属性)、海岸沿いの店舗で購入(購買チャネル)、夏の暑い日に(購入タイミング)、商品紹介ページを閲覧、コールセンターからなされたアウトバウンドコール(コンタクトチャネル)、...このような事象と商品を組み合わせることによって、ルールが記述する条件部、結論部に幅が生まれることになります。
時系列化されたアイテム
ある銀行が、結婚(口座名義変更)、子供の成長(教育/進学ローン)、マイホーム購入(住宅ローン)といった生活ステージイベントの全てに関われるとしたとき、マイホーム購入はどのような順番で表れる確率が高いでしょうか。また、それは年収や口座預金額のような変数で分けた場合に違いが表れるでしょうか。このようにそれぞれのイベントにはシーケンスが存在する場合があります。
アソシエーション分析において、条件部、もしくは結論部内に存在する複数のアイテムには、順序を設定することが可能です。例えば個人の普通預金口座を考え、結論部に口座「閉」設を置くとしましょう。つまり離反済みの顧客を含めて分析の対象とするのです。このデータに対してそれぞれの口座操作をアイテム化し、どのような順番の発生頻度が高いかを見ることは、離反の兆候を見る上で有意義であることでしょう。またこの兆候が見られる顧客には早急に何らかの手当てをする必要があります。例えばIF 1.[3ヶ月の預入無し]、2.[自動引き落とし終了(電気or水道orガス)]、3.[残高照会]、4.[預金残高の95%以上引出] THEN [口座閉設]となるかもしれません。このような順序は、あらゆる業界における顧客の時系列行動に当てはめることが出来ます。
またオンラインストアのバスケットであれば、バスケットに投入された商品の順番も情報として蓄積されるため、単一バスケット内の順序も検討のテーマになります。来店を牽引した商品はおそらく最初にバスケットに含まれることでしょうし、来店してから購入することに決めた商品はバスケットに後から含まれることになるでしょう。オンラインストアが商品をプッシュする際に、ホームページやメールマガジン、そしてバナー広告等、サイトの外側でプッシュするべき商品と、サイト内でリコメンデーション等を駆使してプッシュすべき商品を理解することに活用することも出来るかもしれません。一方で物理店舗のように、精算時の会計登録順と、バスケットへの商品投入順が一致しない場合にはこれを考慮できませんが、例えば百貨店において、最初に購入したテナント、その次に購入したテナントといった形で考慮することは可能です。幸か不幸か、百貨店で買物をする際の精算はそのブランド毎に行なわれるため、一度来店して複数のショップで購入すれば、レシートは複数枚になります。レシートに付与されたタイムスタンプからシーケンスを得て、各ブランドを商品と考えれば、来店の動機となったと想定される最初に立ち寄ったブランドを理解することも可能となりますし、その後の買い廻りパターンも理解できるようになります。