0.Intro
ニーズあると思いますが意外と方法がどこにもまとまとった形で載ってませんでした。もっとスマートな方法ありそうですがひとまず成功した例を提出します。
O365グループ一覧を取得するというアクションもありますがどうも100件までしか抜けないようで(そんなわけないので何かしら設定あると思いますが)。ですので今回はGraph APIで抽出することにしました。Graph APIの結果を全件抽出するはページングが必要です。その方法も今回のポイントです。
1.Outline
全体です
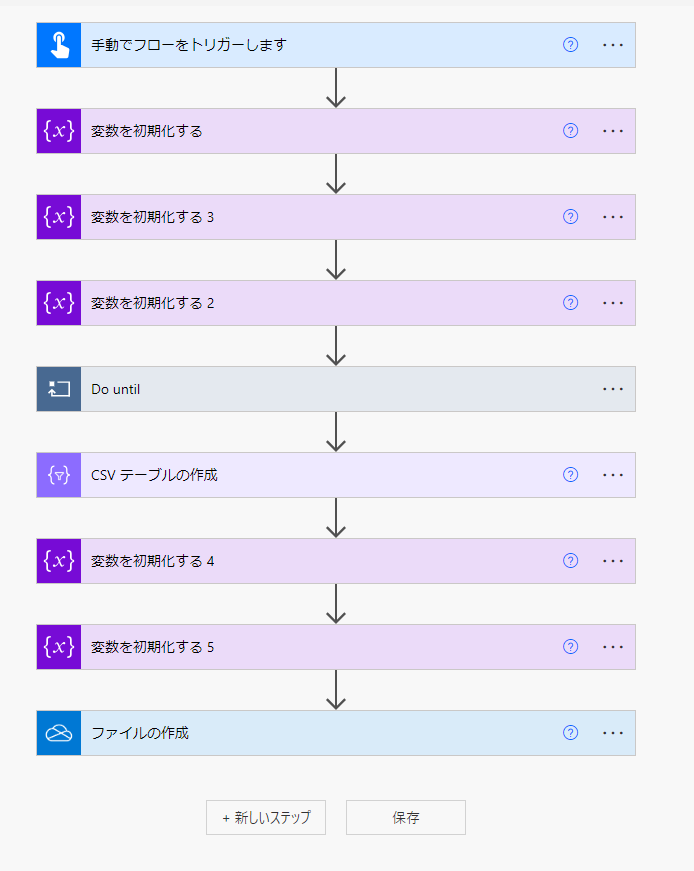
最初の変数定義
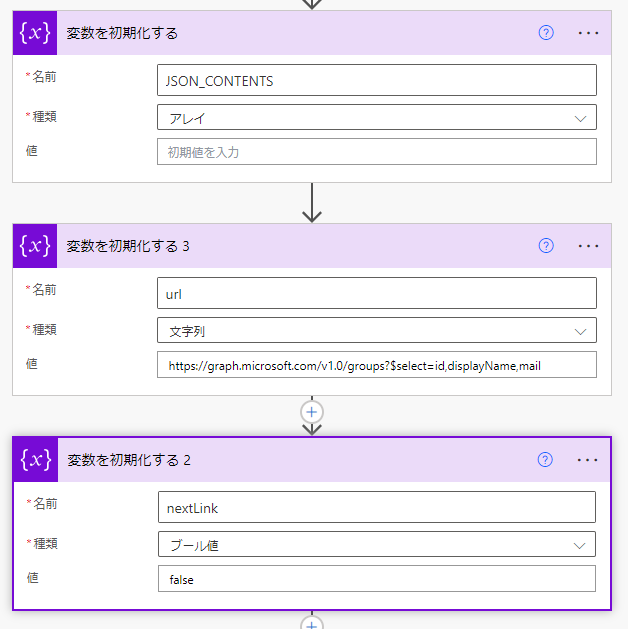
・最終CSVデータ作成用配列変数(JSON_CONTENTS)
・GraphAPI格納用変数(url)
・ループ離脱ブレイク用変数(nextLink)
です。
GraphAPI格納用変数(url)は最初に発行するGraph APIのURLで初期化しています。ポイントはデータを取得する際のJSONのスキーマを揃えるために欲しい情報をselectで絞り込んでおくことです。どうも何も指定しないとスキーマがグループごとに変わるのかエラーが出ました。
その次のDo untilです。
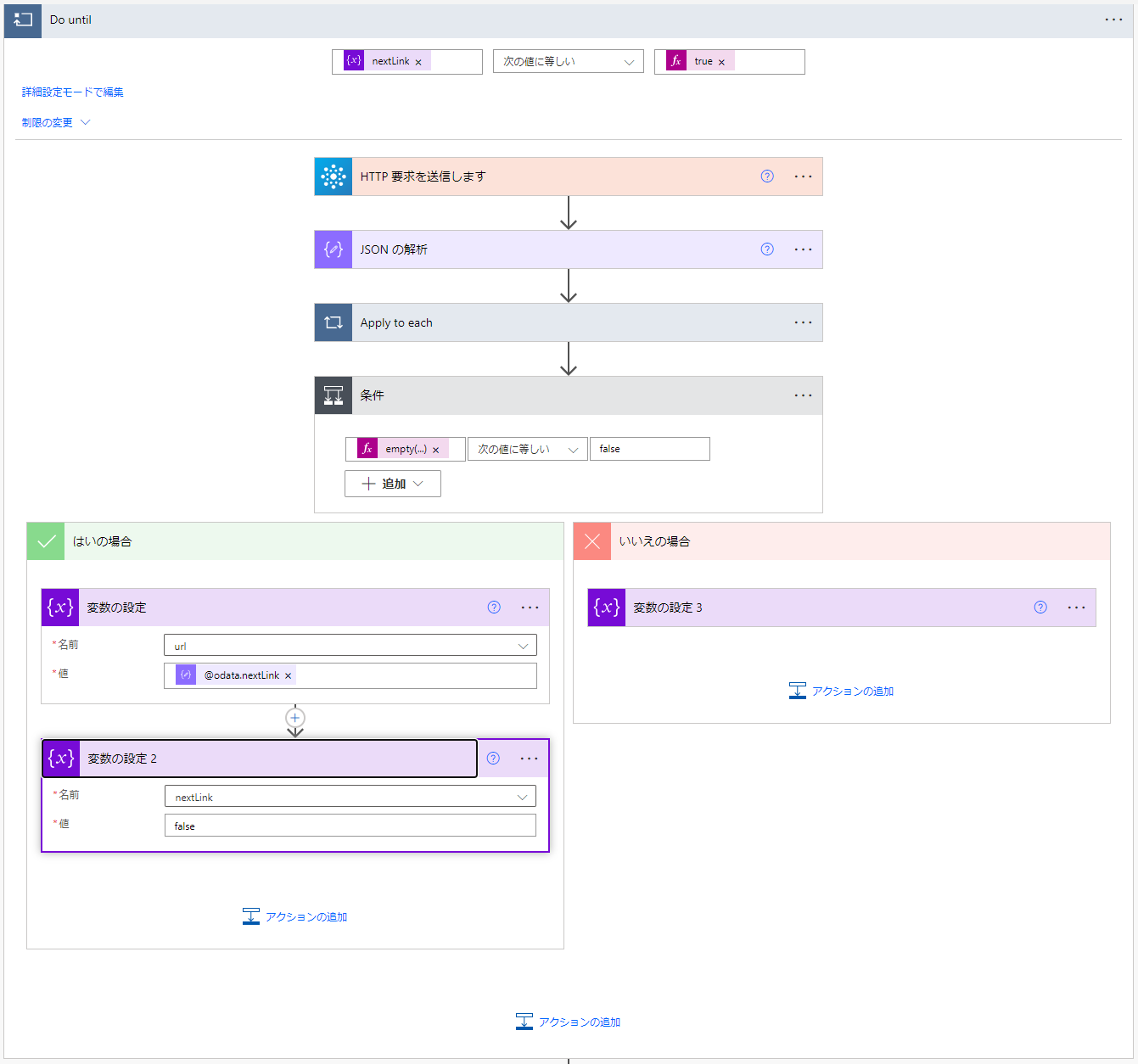
まずGraph APIを叩き、その結果を取得します。ここでは取得したいのは結果の外側のみです。具体的にはJSONの解析のスキーマは以下です。
{
"type": "object",
"properties": {
"@@odata.context": {
"type": "string"
},
"@@odata.nextLink": {
"type": "string"
},
"value": {
"type": "array"
}
}
}
肝要なのは次ページを取得する為の @@odata.nextLink と実データのvalue です。
次の Apply to eachでvalueの中身を取得していきます。
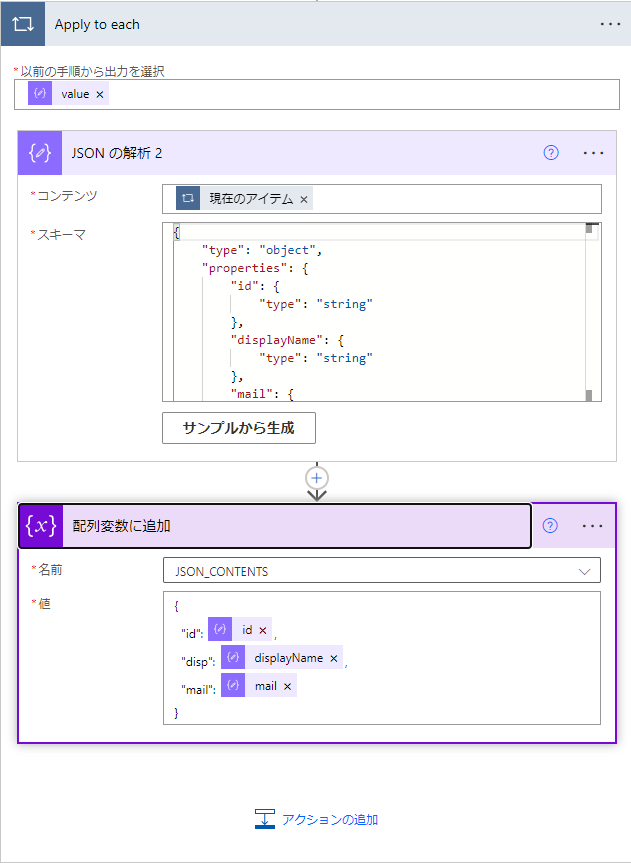
valueの中身のそれぞれに対してJSONの解析を適用して中身を分解し取得します。JSONの解析のスキーマは先程指定した項目のみです。今回は
{
"type": "object",
"properties": {
"id": {
"type": "string"
},
"displayName": {
"type": "string"
},
"mail": {
"type": [
"string",
"null"
]
}
}
}
としています。mailは空のものがありエラーとなったのでnullを許容するようにしています。
こちらのサイトを参考にしました。
Power Automate で null の動作を確認する
ただnullを許容するこちらの書き方をすると「動的なコンテンツ」に出なくなったのでまずフローの次の項目に値をセットしてからスキーマを上記に書き換えると良いようです。
取得した中身は最終CSVデータ作成用配列変数(JSON_CONTENTS)に配列の形でAppendしていきます。
発行したGraph APIからのデータを全件取得したらページングの有無確認です。
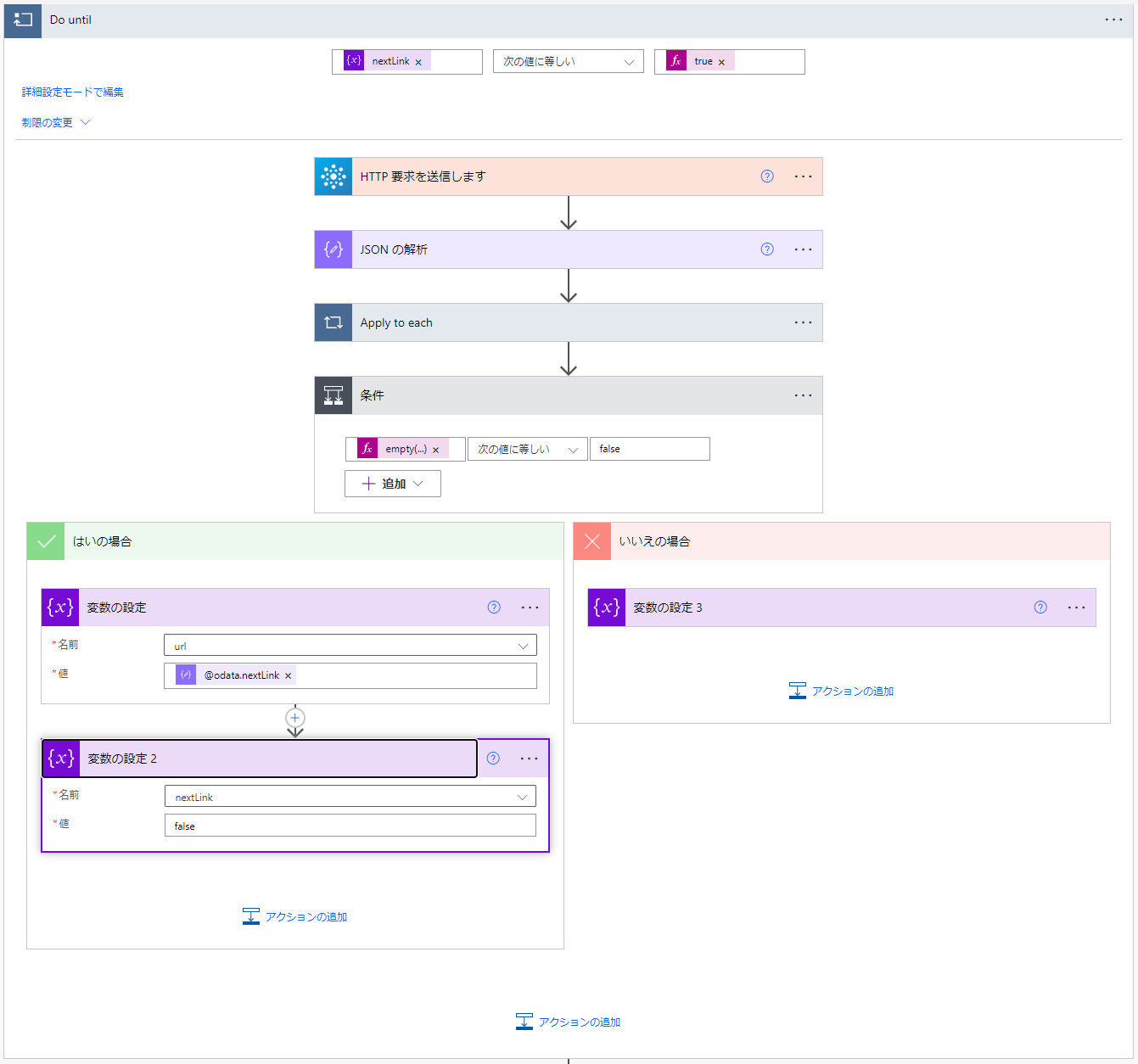
条件の箇所は @@odata.nextLink が空かどうかの判定をしています。
空でなかったら @@odata.nextLink をurlに次回発行するurlを格納、ブレイクしないようにループ離脱ブレイク用変数(nextLink)はfalseを設定。
@@odata.nextLinkがからの場合は次ページが存在しないので ループ離脱ブレイク用変数(nextLink) をtrueに設定しループを終えます。
ループの外は出力部分です。
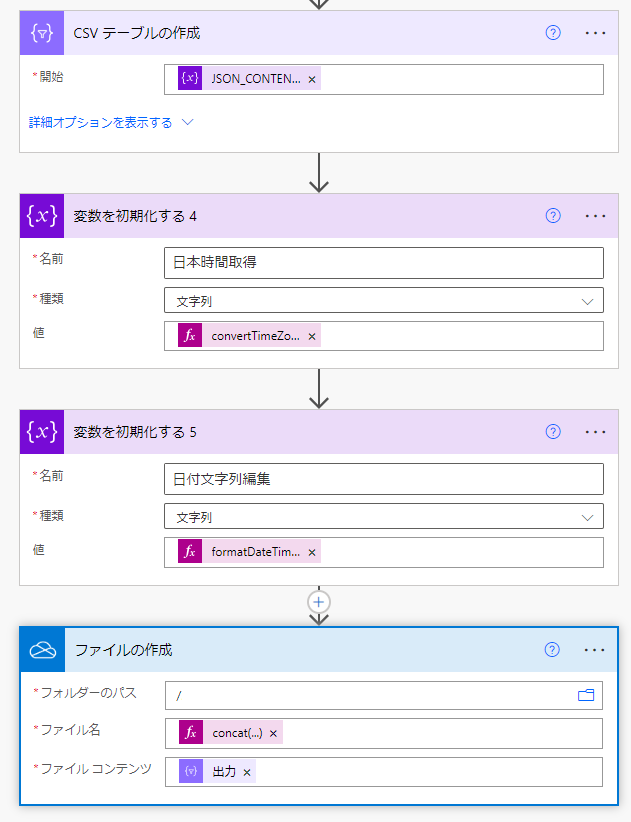
CSVテーブルの生成に取得した情報を格納した配列をそのまま与えます。これでCSVに変換してくれます。
ファイル名を時間にしたかったので時間を文字列へ編集。
OneDriveにファイルを生成、ファイル名は時間を編集した文字列、ファイルの中身は先程作成したCSVです。
2.終わり
無事目的とするCSVを生成することが出来ました。
今回はO365グループを抽出していますが、今回の内容をテンプレにすればGetするGraph APIどれでも叩けるかと思います。