機械学習というと深層学習(ディープラーニング)を連想されがちですが、それ以外にも沢山あります。また、ディープじゃ無いからダメかというとそうでもありません。
というわけで、前回の記事のデータを別の機械学習でやってみます。
関連シリーズ
- 第1回 TensorFlow (ディープラーニング)で為替(FX)の予測をしてみる
- 第2回 ディープじゃない機械学習で為替(FX)の予測をしてみる
- 第3回 TensorFlow (ディープラーニング)で為替(FX)の予測をしてみる CNN編
TL;DR
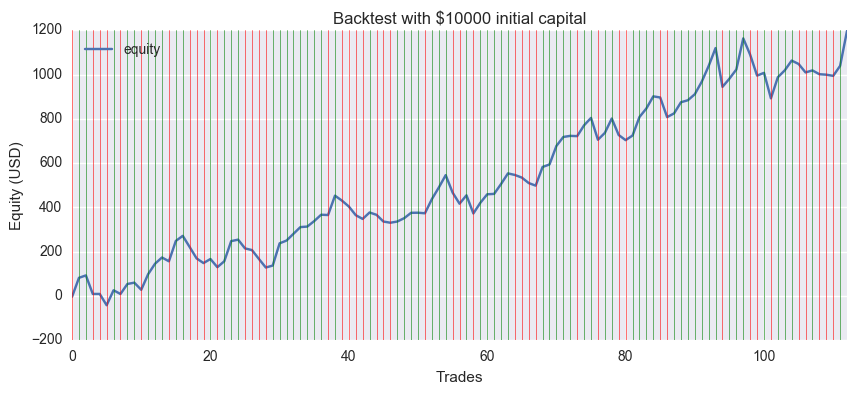
資産の増減をグラフにしました。半年ほどで12%の利益になってますが、学習の条件に対して結果がロバストでは無いので今後もうまくいくとは限りません。
GitHubにNotebookを置いてあります。
Forkして遊んでみてください。
https://github.com/hayatoy/ml-forex-prediction
Scikit-learn
Pythonで機械学習するならまずこれでしょう。インストールはpipなら
pip install -U scikit-learn
でいいと思います。
Classifierの選択
全部試してもいいんですが、あまり線形なのはノイジーなデータに対していい結果が出ないかなと予想します。
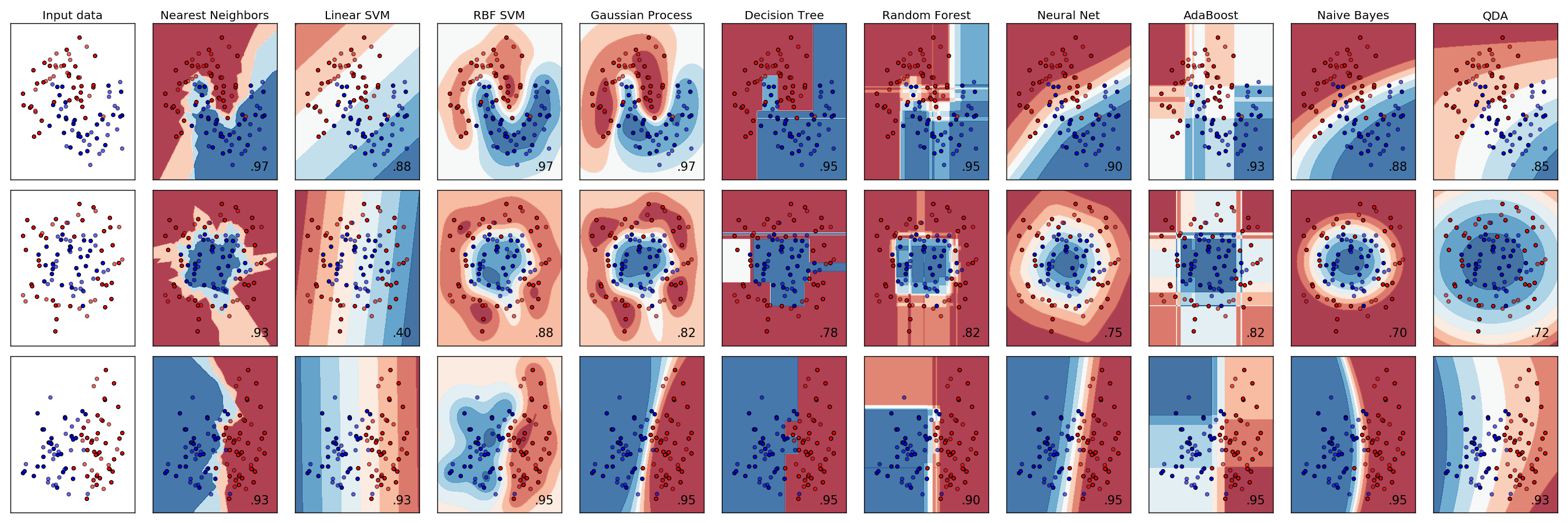
分類の例はこんな感じです1。
SVM(RBF), Naive Bayes辺りが良さそう。
データの加工
同じShapeでfitしてくれそうなのでそのまま使います。
…と思ったらクラスが1hot-vectorのままだと怒られちゃいました。(何かオプション有ったっけ?)
1hot-vectorからbinaryに変換ですが、今回は2クラスなので取ってくる場所を変えるだけで良さそうです。
>> train_y
[[ 0. 1.]
[ 0. 1.]
[ 1. 0.]
[ 0. 1.]
[ 0. 1.]
[ 0. 1.]
[ 1. 0.]
[ 0. 1.]
[ 1. 0.]
[ 0. 1.]]
>> train_y[:,1]
[ 1. 1. 0. 1. 1. 1. 0. 1. 0. 1.]
多クラスだとこの方法は使えないですね。何かカッコイイやり方無いかな。
学習させてみる
前回同様、前半90%をトレーニング、後半10%をテストに使います。0.502118を下回るとランダムに予測するより悪い事になります。
とりあえず公平にデフォルトパラメータで実施。
SVM (RBF)
from sklearn import svm
train_len = int(len(train_x)*0.9)
clf = svm.SVC(kernel='ref')
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
結果:0.49694435509810231
Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
結果:0.52331939530395621
Random Forest
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(random_state=0)
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
結果:0.49726600192988096
Naive Bayes
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
結果:0.50112576391122543
Nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
結果:0.49726600192988096
QDA
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as QDA
clf = QDA()
clf.fit(train_x[:train_len], train_y[:train_len,1])
clf.score(train_x[train_len:], train_y[train_len:,1])
結果:0.50981022836925061
まとめ
| 順位 | モデル | Accuracy |
|---|---|---|
| 1 | BiRNN(LSTM) | 0.528883 |
| 2 | Gradient Boosting | 0.523319 |
| 3 | QDA | 0.509810 |
| 多いクラスの割合 | 0.502118 | |
| 4 | Naive Bayes | 0.501126 |
| 5 | Random Forest | 0.497266 |
| 6 | Nearest Neighbors | 0.497266 |
| 7 | SVM (RBF) | 0.496944 |
前回のLSTMがやっぱり1位。2位はKaggleでも人気のGradient Boostingでした。
…って、あれ?パラメータ調整していないとはいえ、SVMが最下位?そんなはずは・・またの機会にGrid Searchで最適なパラメータを探索してみます。
PnL (Profit & Loss)を計算
正解率が悪いからといって、損益が悪くなるとは限りません。50%の正解率でも利益 > 損失なら良いわけですからね。
今回のデータは次の期間の終値が上がるか下がるかを予測しました。
なので
(次の終値 - 現在の終値) * ロット - コミッション
を損益として計算しました。
(実際には現在の終値が確定した時点でPredictするので、終値でポジションは取れません。週の中日なら多少上下するだけですが週末を挟むと大きく値が動いている可能性があります)
github版のEUR/USD日足データです。緑のラインは正解、赤のラインは不正解を意味します。
初期資産は10000ドル、取引単位は10000通貨、コミッション(スプレッド)は0で、最終利益はプラス1197ドルとなりました。スプレッドを平均2pipsに設定してもまだプラス900ドル位ある計算です。
一見良さそうですが・・・
トレーニング期間を変えるとすぐにダメになってしまうので、モデルとデータ選択が良いというわけではなく偶々いい感じにフィットしただけのようです。
GitHubにNotebookを置いてありますので、お試しあれ。
https://github.com/hayatoy/ml-forex-prediction