1.情報収集のハードル
Webからの情報収集=単純作業で時間がかかる
これまで仕事に関わる様々な情報をWebで検索してきました。一方で、自分が求めている情報がまとめられた資料がWebから見つかるなんて都合のよいことはめったにありませんでした。
なので、例えば定点で情報を整理するため、毎月決まった日付で決まったWebを訪れ、その時公開されている情報を確認。確認した情報は画面キャプチャやテキストのコピー&ペーストでExcelファイルで一覧化してストックする…といった作業を行ったことも少なくありません。
調査数が多いと地味に時間がかかるのでやり切った時に謎の達成感を感じるのですが、即時的に仕事の成果に結びつくものではないですし、もはや可能得あれば避けて通りたい仕事のひとつになってしまいました。
スクレイピング=Pythonの知識が必要…?
以前、社内でも情報収集について話題があがることがありました。方法論については他のメンバーも同じような課題を感じており「スクレイピング」の活用も検討してみたのですが、技術的な知見がなく、結果いつも通りの手作業で情報をまとめることに…。
それからしばらく経ちましたが、先日、__Microsoftの「Power Automate」を使用すれば比較的容易に解決できる__ということを知りました。なんとなく「スクレイピングはPythonが分からないと実現しない」と思いおんでいたのでかなり驚きです。
今回は「Power Automate」を使って、__指定したWebページの情報を収集し、さらにExcelファイルにまとめて保存までしえてくれるワークフロー__を作成してみました。
このフローが活用できれば、情報収集の時間が大幅に短縮できるはず!!
2.作成したもの
今回は、NTTドコモのdポイントクラブのサイトを対象に情報収集をすると仮定して、
データ収集フローを作成を試してみました。
今回集める情報/保存方法
- 各キャンペーンの概要(キャンペーン名、期間、内容)/Excelファイル
- 各キャンペーンの詳細情報が掲載されている画面キャプチャ/画像
まずは、基本的な情報の収集に挑戦します。
使用したツール
今回は主に以下2つのツールを使用しています。
- Power Automate
- Excel
作成したワークフロー
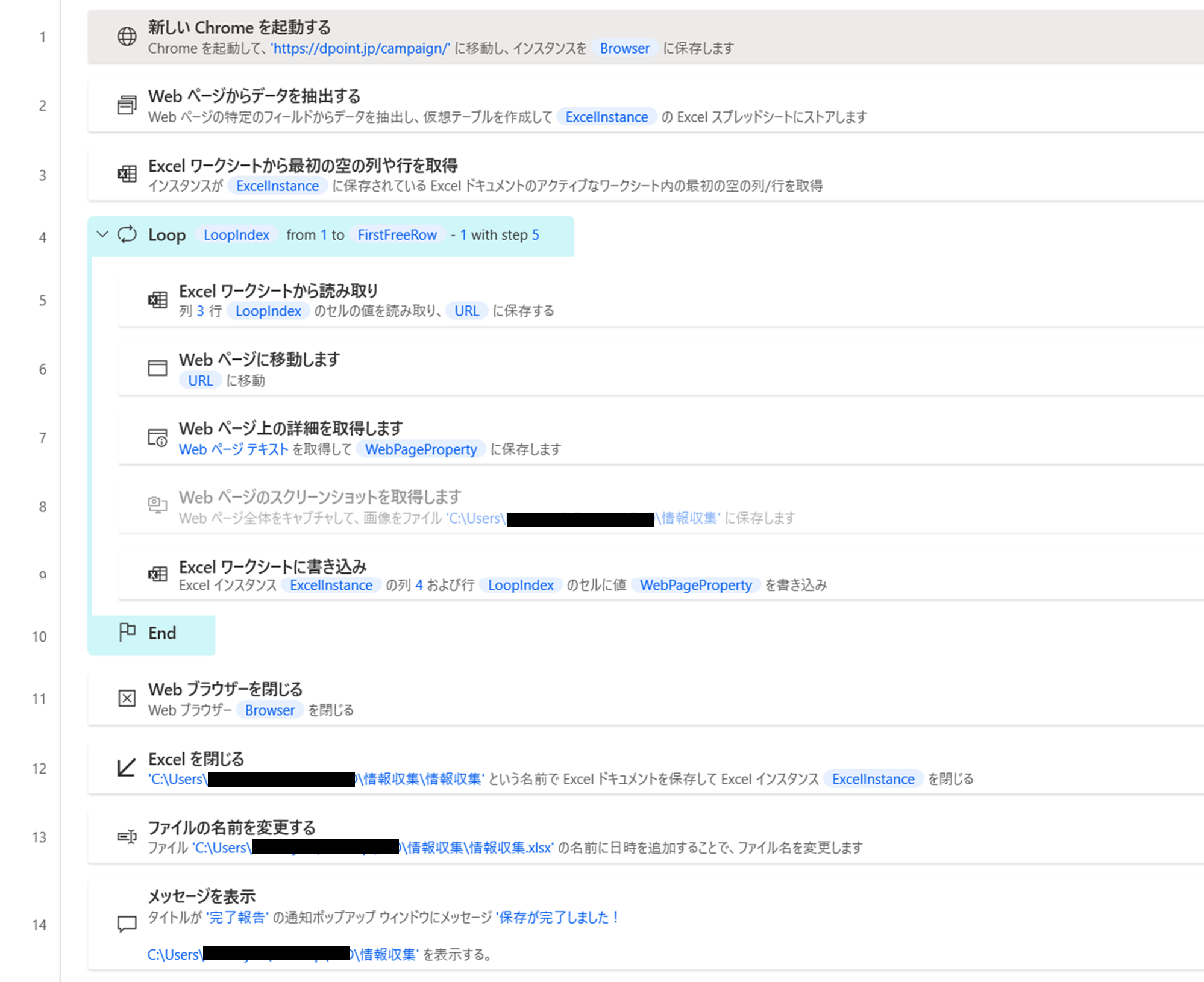
各アクションで何を実現しているか
- ブラウザ(Chrome)を起動し、情報を抽出したいサイトへ遷移させる
- 遷移先のサイトから各キャンペーンの概要情報を抽出し、Excelへ書き込む
- ループアクションおよび新しい情報を書き込むセルをアクティブにする前準備として、Excelのワークシート上の空き列の位置を取得
- ループ
- 【ループ】アクション2で作成したExcelのC列(3列目)に記録したURL(キャンペーン詳細ぺージ)の読み込み
- 【ループ】上記URL(キャンペーン詳細ぺージ)への遷移
- 【ループ】遷移先URLのテキスト情報を取得
- 【ループ】遷移先URLのスクリーンショットを取得して、指定のフォルダに保存
- 【ループ】アクション2で作成したExcelのD列(4列目)を選択し、上記テキスト情報を記録
- 上記1~5のフローを、全てのURLで実行したらループ終了
- ブラウザを閉じる
- Excelファイルを指定名称で保存
- 上記で保存したファイルの名称に作業した日付を追加して名称変更
- 作業完了をメッセージ表示で通知
各アクションでの指定内容詳細
設定が特に難しかった、工夫した部分を抜粋してご紹介します。
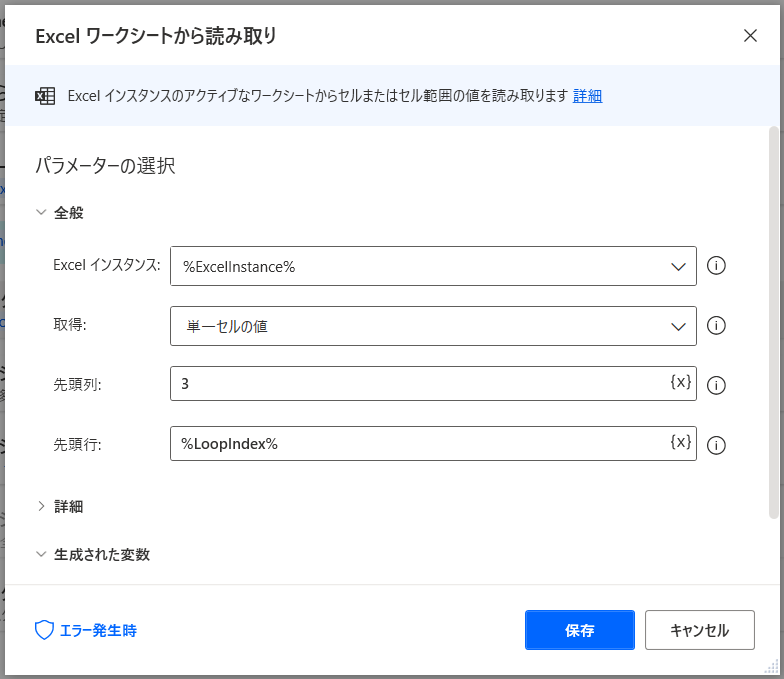
アクション5
【ループ】アクション2で作成したExcelのC列(3列目)に記録したURL(キャンペーン詳細ぺージ)の読み込み
⇒前段階でアクション3でLoopIndexの変数を設定しています。Loopの回数=LoopIndex=読み込むExcelの行番号となるので、Loopを繰り返すたびに、読み込む行が1行ずつ下がるような設定です。
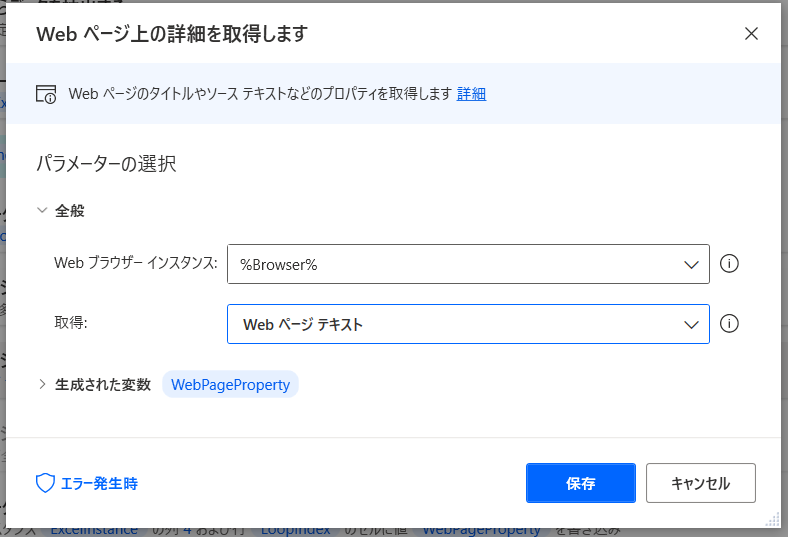
アクション7
【ループ】遷移先URLのテキスト情報を取得
⇒難しい設定ではありませんが、取得の項目を「Webページテキスト」を選択することでテキスト情報のみ取得することができます。
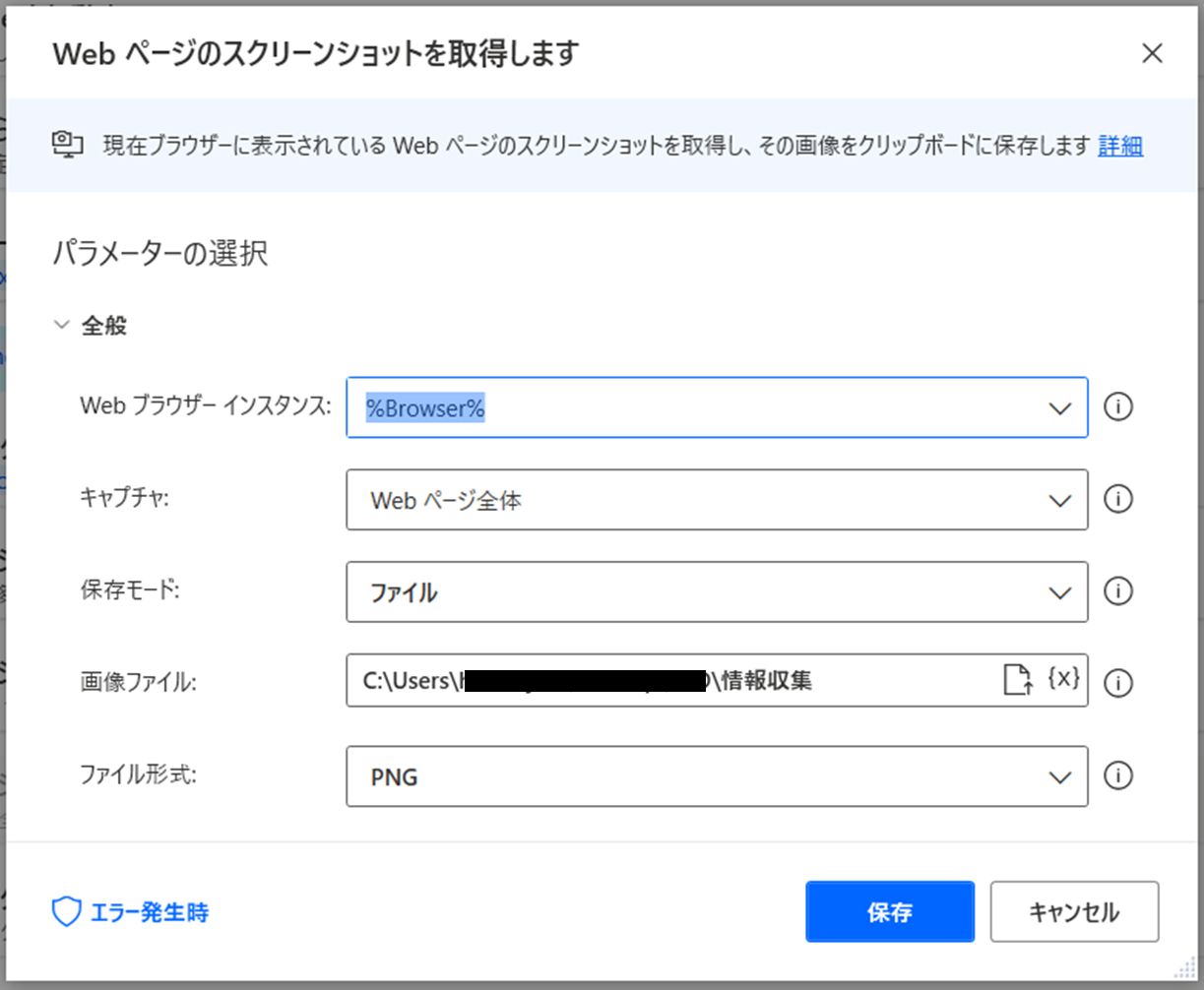
アクション8
【ループ】遷移先URLのスクリーンショットを取得して、指定のフォルダに保存
⇒本来であれば、ここでスクリーンショットを取得したかったのですが、なぜかエラーになってしまいました。もう少し研究が必要そうです。失敗例の参考として設定状況を記載しておきます。
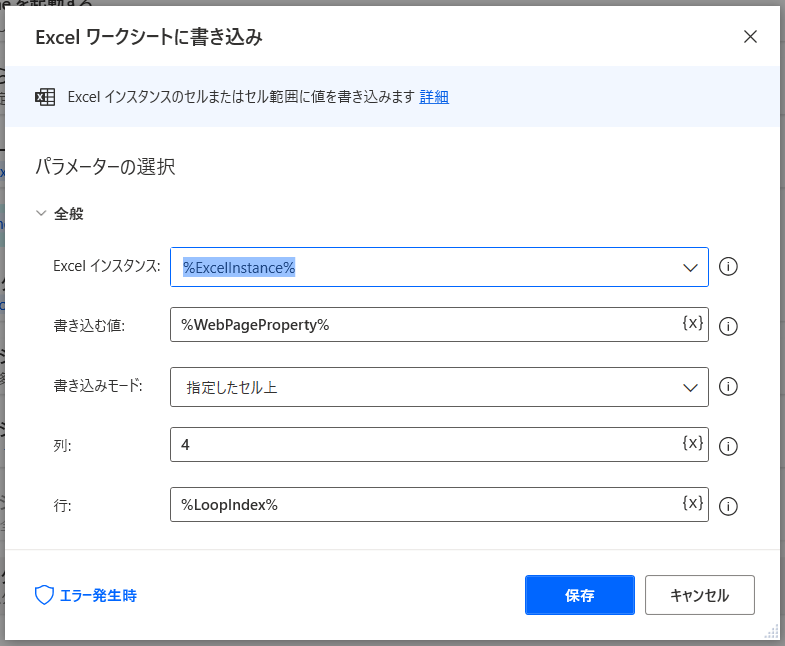
アクション9
【ループ】アクション2で作成したExcelのD列(4列目)を選択し、上記テキスト情報を記録
アクション5と同様に行の指定にLoopIndexの変数を設定しています。Loopの回数=LoopIndex=書き込むExcelの行番号となるので、Loopを繰り返すたびに、書き込む行が1行ずつ下がるような設定です。これで、アクション5で読み込んだURLの隣のセルに、新しい情報を追加することができました。
★結果★
少し細かいですが、このような表にまとめることができました。

A列:タイトル
B列:日付情報
C列:詳細ページURL
D列:詳細ページのテキスト情報
だいたい130個のキャンペーンの情報を収集するのに10分程度の処理時間がかかりました。
手作業でやったらものすごい時間になりそうですね。
3.苦労したこと&今後の展望
苦労したこと
- 行番号の設定の仕方(解決)⇒一度設定してみたらある程度仕組みを理解できました。
- 画面キャプチャの方法(未解決) ⇒設定が悪い?サイトのつくりとあっていない?
今後の展望
- 画面キャプチャを取得し、保存時に案件に応じた名称にする
- 今回取得ができなかった要素の抽出(対象サービスなど)
- 取得したテキスト情報の成型
こんなことにチャレンジして、実際の業務に活かせるような形に仕上げたいです。
最後までお読みいただき、ありがとうございました!