はじめに
Knowledge Base for Amazon Bedrock にメタデータフィルタリング機能が追加されました。これにより、クエリに関連性の高いドキュメントのみを検索対象とすることができるため、検索精度の向上が期待できます。
たとえばニュース記事をデータソースとする場合、事前に西暦 (year) やジャンルといった情報をメタデータとして設定しておくことで、これらを使用したフィルタリングが可能になります。
やってみる (Amazon Aurora 編)
ベクトルデータベースに Aurora を使用したナレッジベースの環境が手元にあったので、こちらで試してみます。
Aurora を使用したナレッジベースの構築方法は以下の記事で紹介しています。
メタデータファイルの準備
データソースとなるファイル単位で以下のようなスキーマの JSON ファイルを準備します。
{
"metadataAttributes": {
"${attribute1}": "${value1}",
"${attribute2}": "${value2}",
...
}
}
属性値は以下のデータ型がサポートされています。
- String
- Number
- Boolean
メタデータのファイル名はデータソースとなるファイル名に .metadata.json を追加した形式とする必要があります。例えば A.txt に対してメタデータファイルを用意する場合、A.txt.metadata.json を作成し、データソースが配置されている同じ S3 バケットに配置します。
以下にご注意ください。
- メタデータのファイルサイズは 10 KB 以下にする必要があります
- ソースドキュメントと同じフォルダーに配置する必要があります
今回は Bedrock のユーザーガイドと API Reference (どちらも英語版) を S3 に配置し、それぞれ以下のようなメタデータファイルを準備しました。
{
"metadataAttributes": {
"category": "User Guide",
"service": "Bedrock",
"year": 2024
}
}
{
"metadataAttributes": {
"category": "API Reference",
"service": "Bedrock",
"year": 2024
}
}
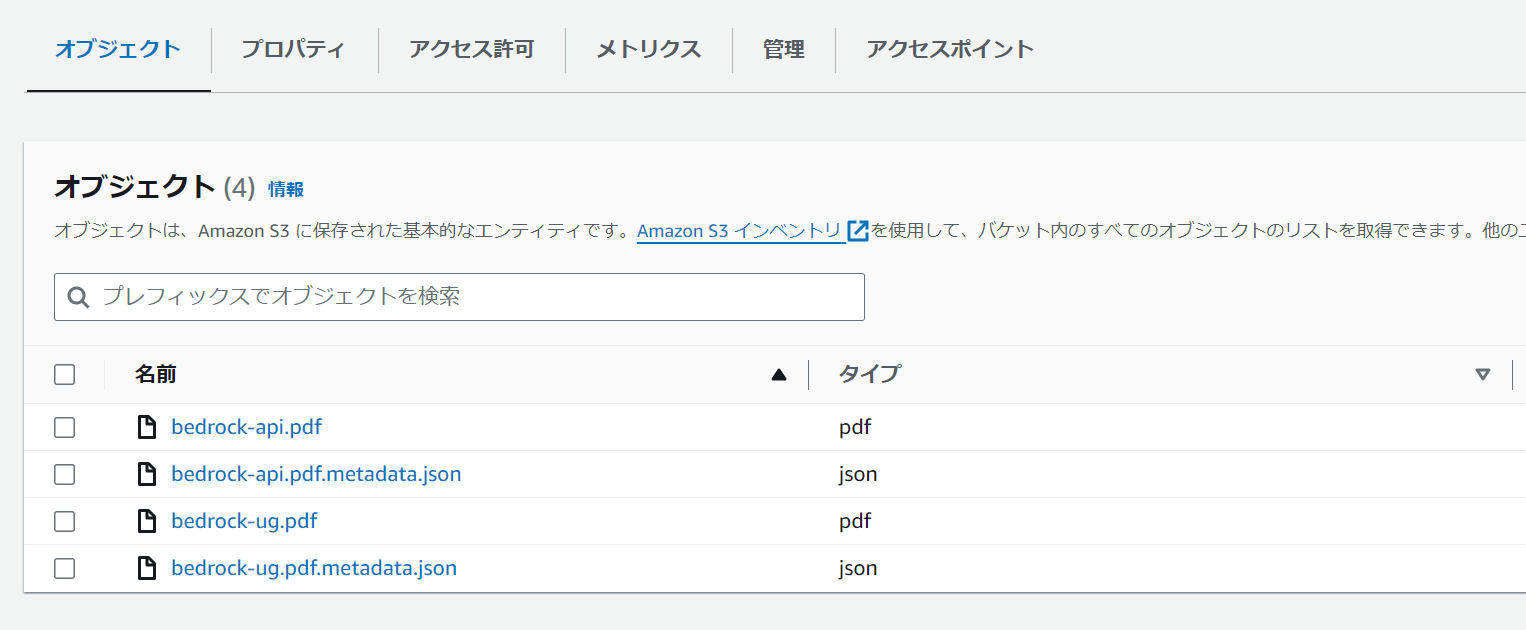
ベクトルデータベースへの列追加
使用しているベクトルデータベースをメタデータに対応した形へ変更する必要があります。
Amazon Aurora データベースクラスター内の既存のベクトルインデックスにメタデータを追加する場合は、メタデータの属性ごとにテーブルへ列を追加します。
今回のケースでは以下のような SQL を実行して既存の Aurora クラスター上のテーブルに列を追加します。
ALTER TABLE bedrock_integration.bedrock_kb
ADD COLUMN category VARCHAR(128),
ADD COLUMN service VARCHAR(128),
ADD COLUMN year SMALLINT;
本記事では詳細に触れませんが、ベクトルデータベースに Amazon OpenSearch Serverless を使用している場合は以下のいずれか対応が必要です。詳細はドキュメントを参照してください。
- コンソールで新規のナレッジベースの作成時に新しいベクトルストアをクイック作成する
- 既存のベクトルストアを使用したい場合は Engine を
faissとした新しいベクトルインデックスを作成し、ナレッジベース作成時に新しいインデックスを指定
※ つまりいずれの場合もナレッジベース自体の再作成は必要になります
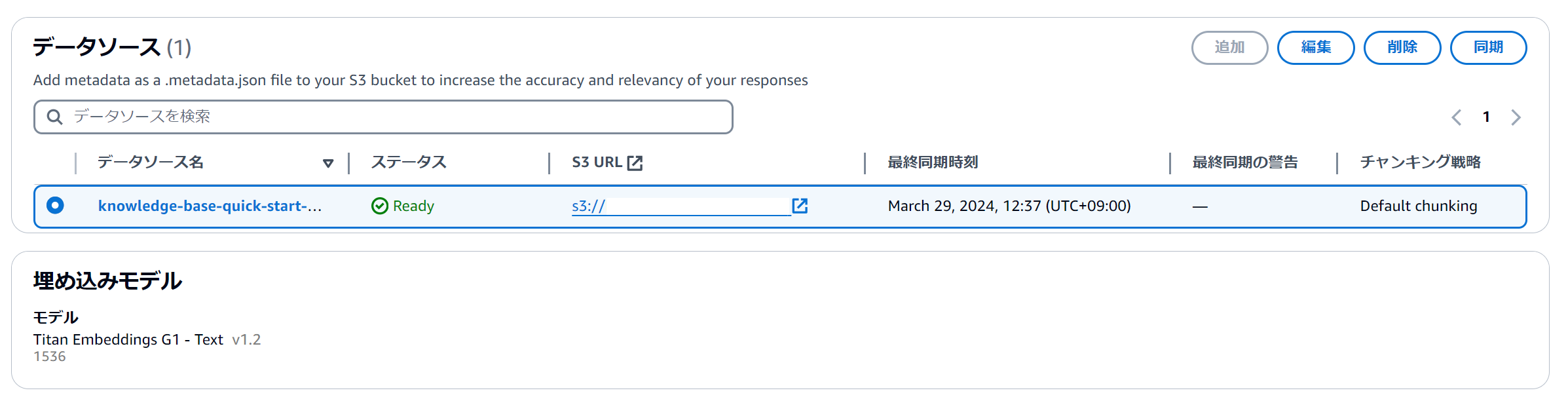
再同期
コンソールまたは StartIngestionJob API を使用してデータソースを再同期します。
事前にベクトルデータベースへの列追加が完了していない場合は同期エラーが発生します。
動作確認 (コンソール)
以下はフィルターを設定せず、「ナレッジベースから回答を得るにはどうすればいいですか」という質問をした結果です。回答結果からユーザーガイドをソースとして回答していることがわかります。
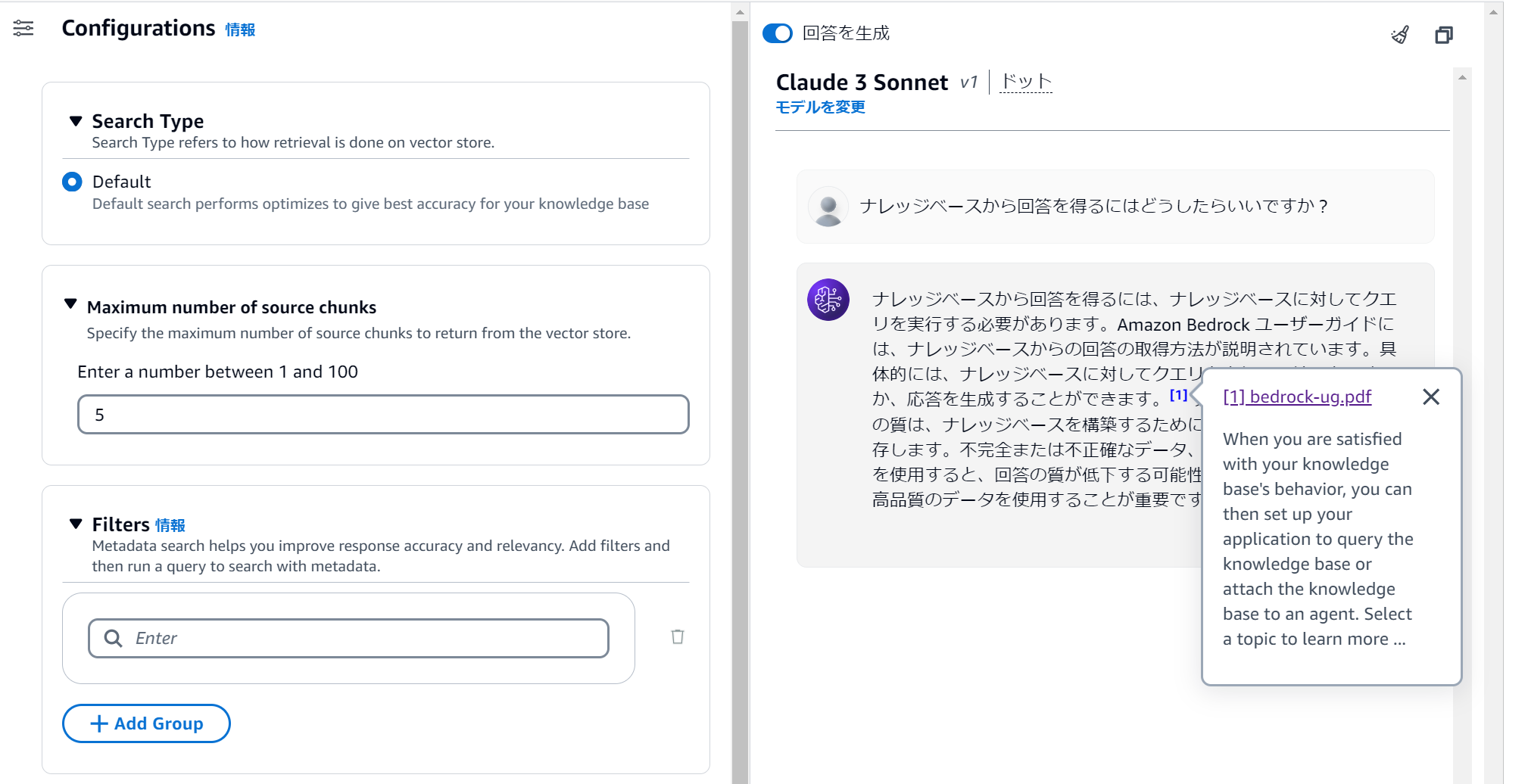
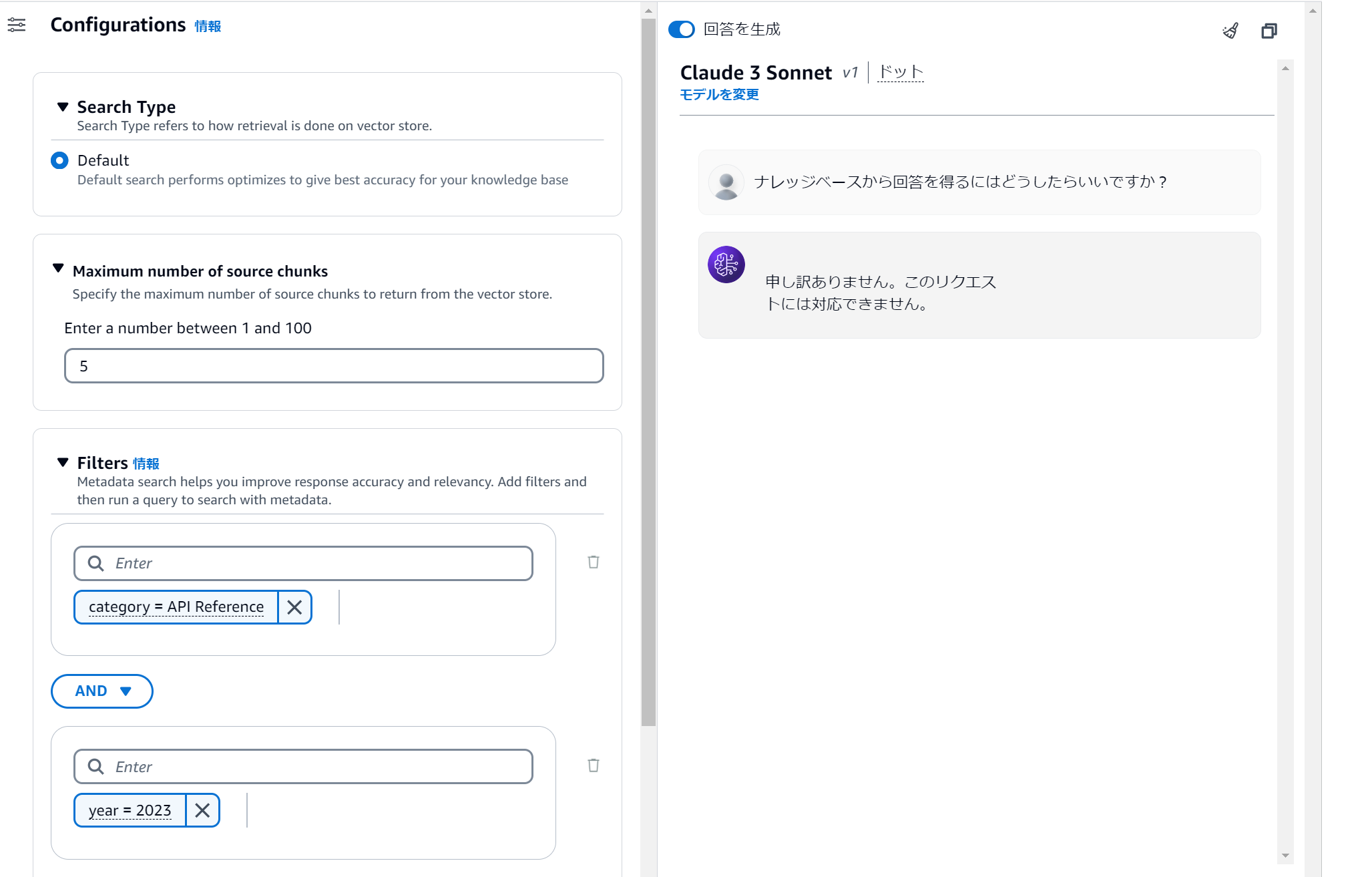
次に API Reference をソースとして回答させるために category = API Reference を Filters に設定して実行します。
コンソールでフィルターを設定する際は値にシングルクォーテーションやダブルクォーテーションを付与しないでください。付与すると適切にフィルタリングされません。
API Referenceの情報をソースとした回答を得ることができました。
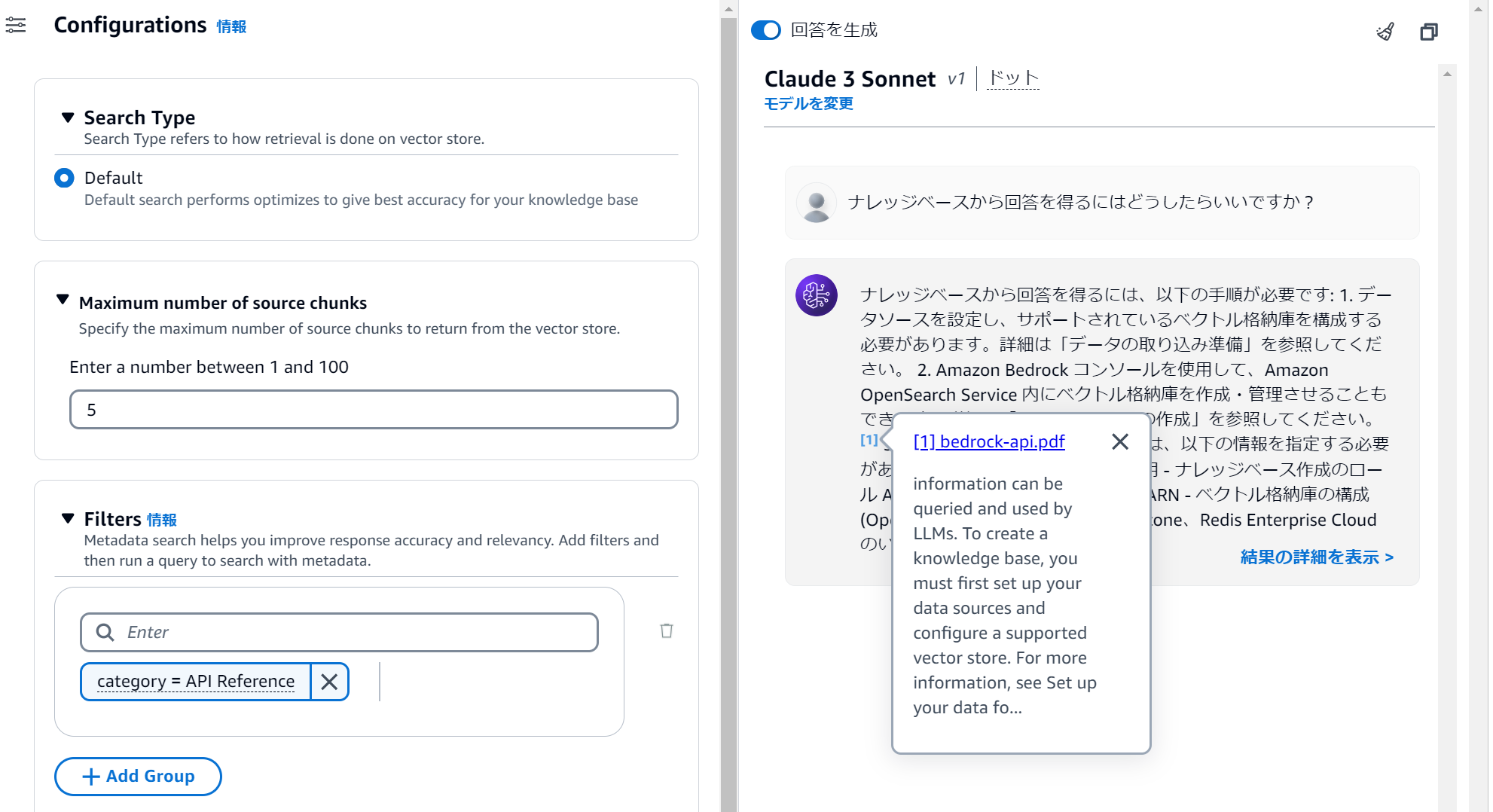
回答結果の詳細からソースチャンクを表示すると、チャンクに関連付けられたメタデータを確認できます。
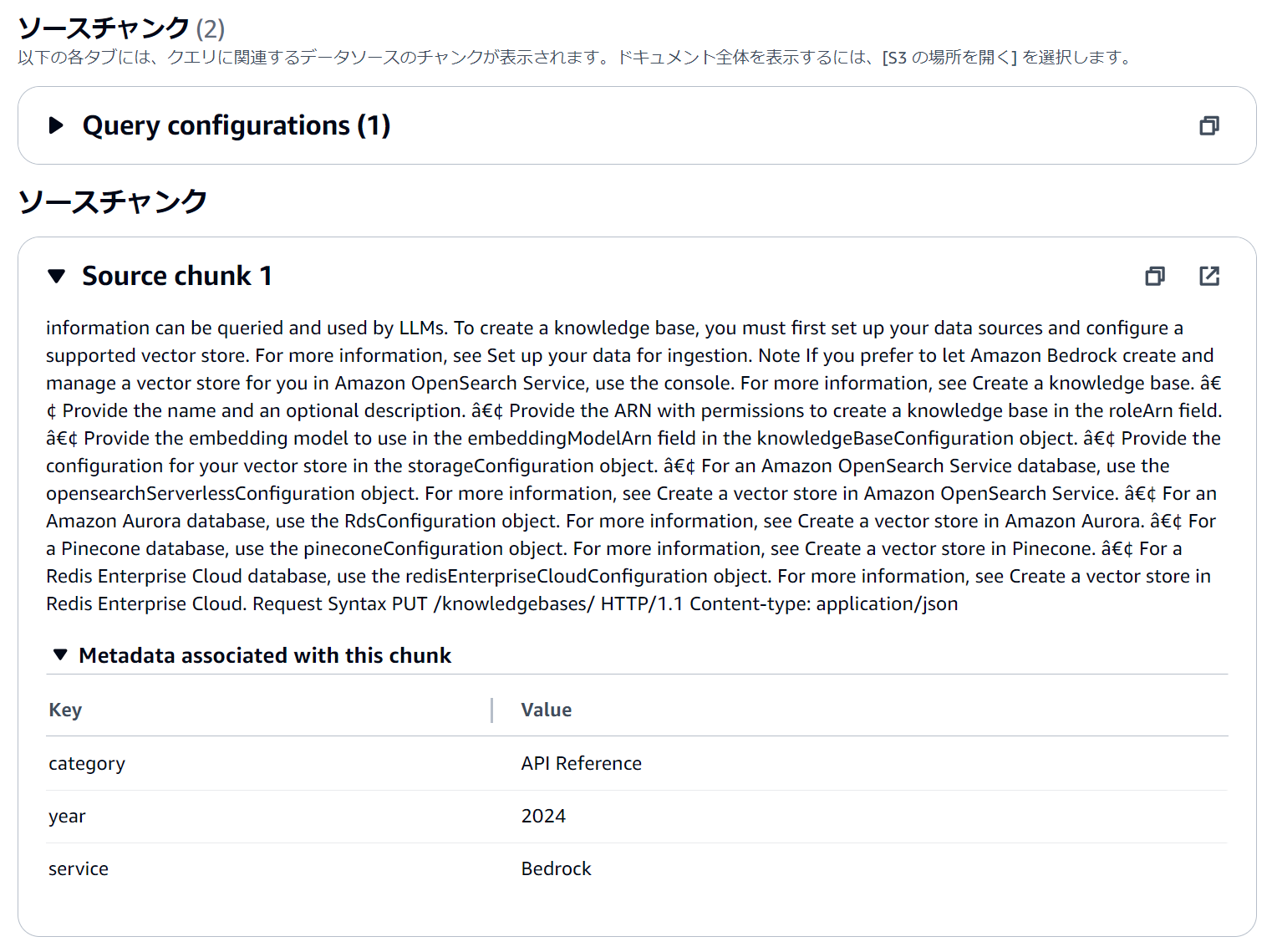
フィルターに設定可能な演算子はドキュメントに記載がありますので、以下を参照ください。
AND 条件で year = 2023 追加すると、該当するメタデータを持つソースデータがないため、ナレッジベースから回答は得られません。
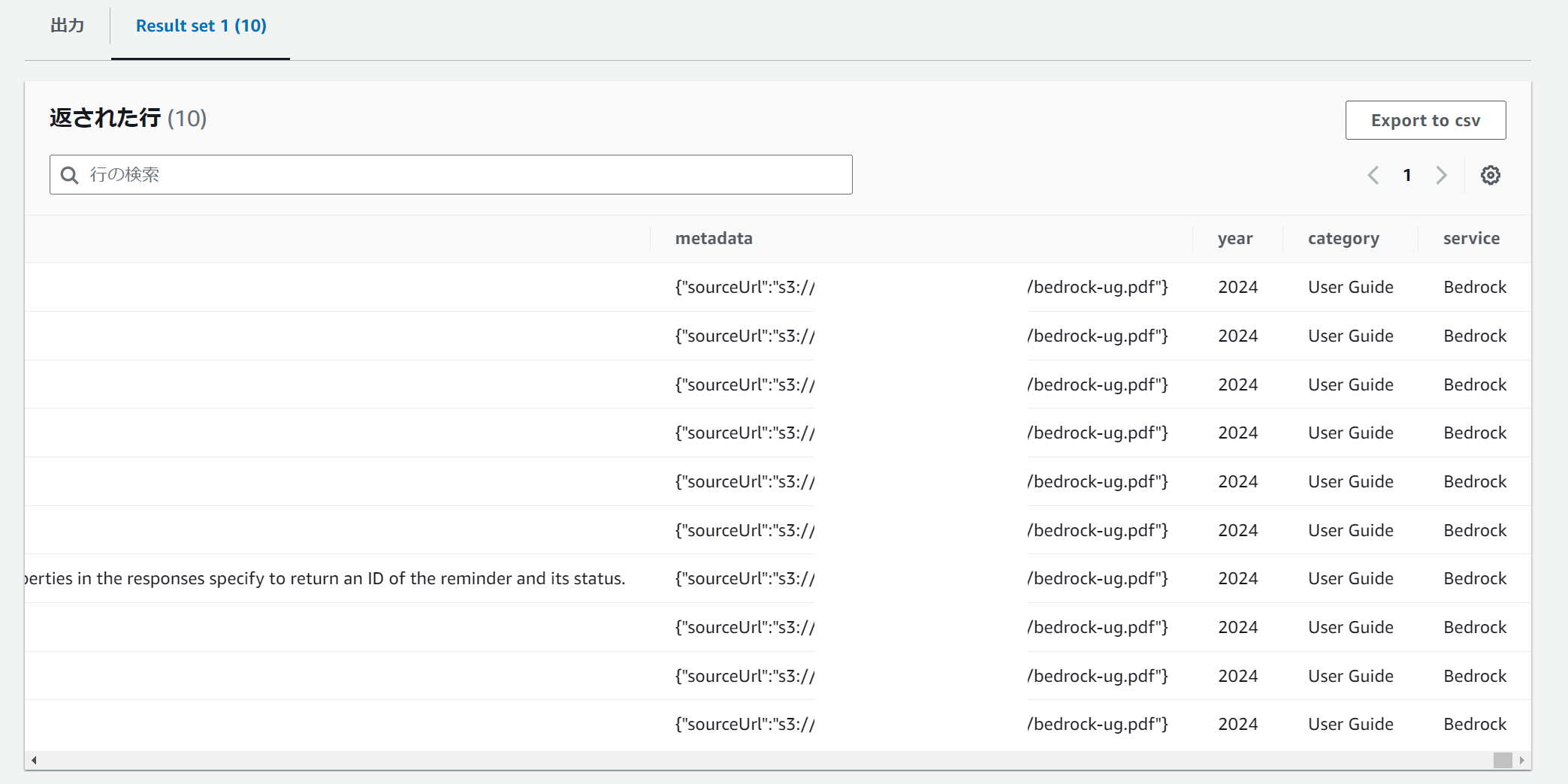
Aurora クラスター上のデータを SQL で参照すると、追加した列にメタデータの値がそのまま挿入されていることがわかります。
select * from bedrock_integration.bedrock_kb where year = 2024 limit 10;
動作確認 (boto3)
コンソールと同様の確認を boto3 でも試してみます。boto3 のバージョンは v1.34.73 で動作確認しています。
以下はコード例です。
import boto3
def main():
client = boto3.client("bedrock-agent-runtime")
response = client.retrieve_and_generate(
input={"text": "ナレッジベースから回答を得るにはどうしたらいいですか?"},
retrieveAndGenerateConfiguration={
"type": 'KNOWLEDGE_BASE',
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "KB12345678",
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": 5,
"filter": {
"equals": {
"key": "category",
"value": "API Reference"
}
}
}
}
}
}
)
print(f'Answer: {response["output"]["text"]}')
print(f'\nMetadata: {response["citations"][0]["retrievedReferences"][0]["metadata"]}')
if __name__ == "__main__":
main()
実行すると以下の結果を得られました。
$ python kb.y
Answer: ナレッジベースから回答を得るには、以下の手順が必要です:
1. データソースを設定し、サポートされているベクトル格納庫を構成する必要があります。詳細は「データの取り込み準備」を参照してください。
2. Amazon Bedrock コンソールを使用して、Amazon OpenSearch Service 内にベクトル格納庫を作成・管理させることもできます。詳細は「ナレッジベースの作成」を参照してください。 3. ナレッジベースを作成する際には、以下の情報を指定する必要があります:
- ナレッジベース名と説明
- ナレッジベース作成のための IAM ロール ARN
- 使用する埋め込みモデル
- ベクトル格納庫の構成 (OpenSearch Service、Aurora、Pinecone、Redis Enterprise Cloud のいずれか)
Metadata: {'category': 'API Reference', 'year': 2024.0, 'service': 'Bedrock'}
複合条件としたい場合の Filter の設定例は以下のようになります。
"filter": {
"andAll": [
{
"equals": {
"key": "category",
"value": "API Reference"
}
},
{
"equals": {
"key": "year",
"value": 2023
}
}
]
}
参考
以上です。
参考になれば幸いです。