本記事は セゾンテクノロジー Advent Calendar 2024 19 日目の記事です。
はじめに
Amazon SageMaker Lakehouse は AWS re:Invent 2024 で発表された新しいサービスです。Amazon S3 のデータレイクと、Amazon Redshift のデータウェアハウスを統合し、Apache Iceberg の API を使用してデータソースに横断的にアクセスできます。
次世代 SageMaker の概要や SageMaker Lakehouse が提供する機能については以下の記事で解説しています。
本記事では SageMaker Lakehouse にデータソース (Redshift クラスター) を登録し、Unified Studio からデータ操作する方法をハンズオン形式で記載します。
SageMaker Unified Studio 環境の構築
SageMaker Unified Studio は、データ、分析、AI 向けの統合開発環境 (IDE) です。Redshift による SQL 分析、Glue や Athena、EMR によるデータ処理、SageMakaer AI による AI/ML モデル開発、Bedrock Studio で提供されていた生成 AI アプリケーションの開発を単一の場所で実行することができます。
Unified Studio は 2024/12/19 時点で Preview として提供されています。将来的に動作や仕様が変更される可能性があります。
ドメインの作成
Amazon SageMaker platform (旧 Amazon DataZone) コンソールに移動します。

「Unified Studio ドメインを作成します」をクリックします。
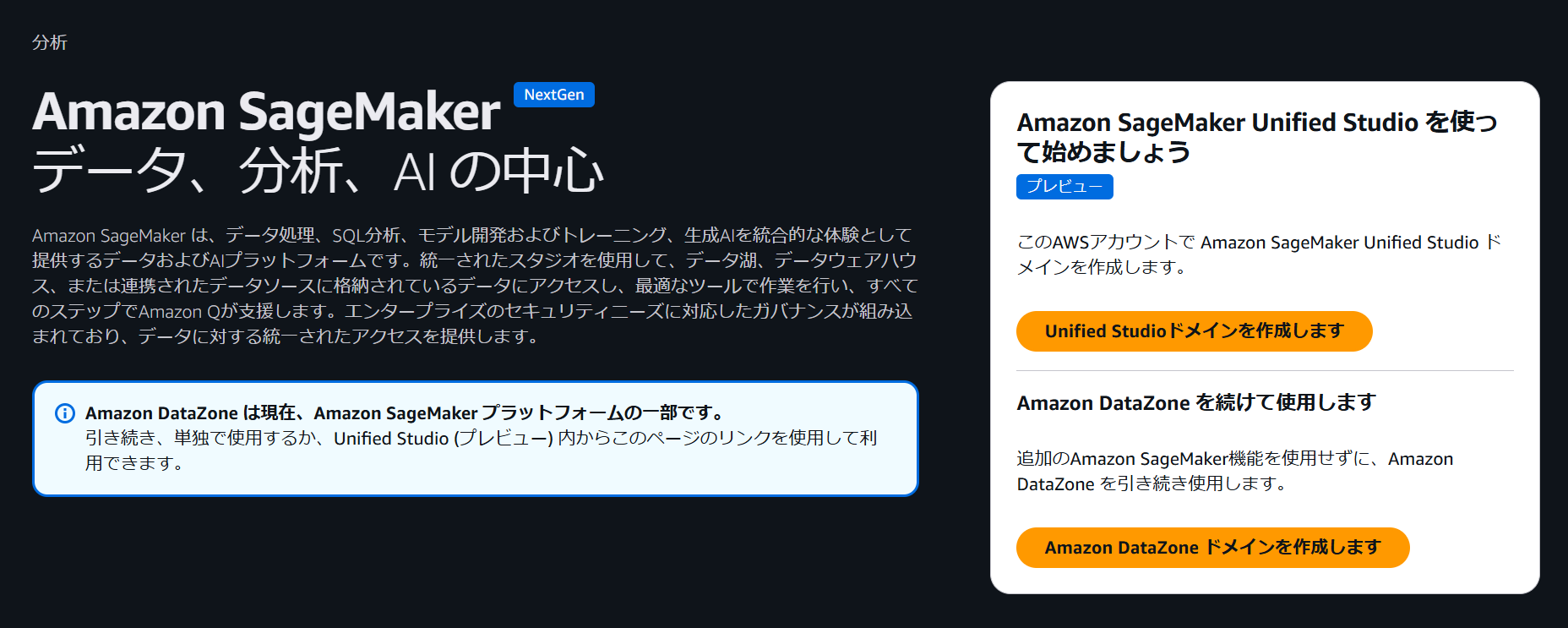
ここでは「ドメインをどのように設定しますか?」 でクイックセットアップを選択します。
Amazon Bedrock を使用たことがない環境では「アクセス可能なモデルはありません」と表示されますが、今回は Bedrock IDE による開発は取り扱わないのでスキップします。
「Amazon SageMaker Unified Studio で使用するために特別にセットアップされた VPC はありません」と表示されるので、ここでは「VPC を作成」をクリックして新規の VPC を作成します。
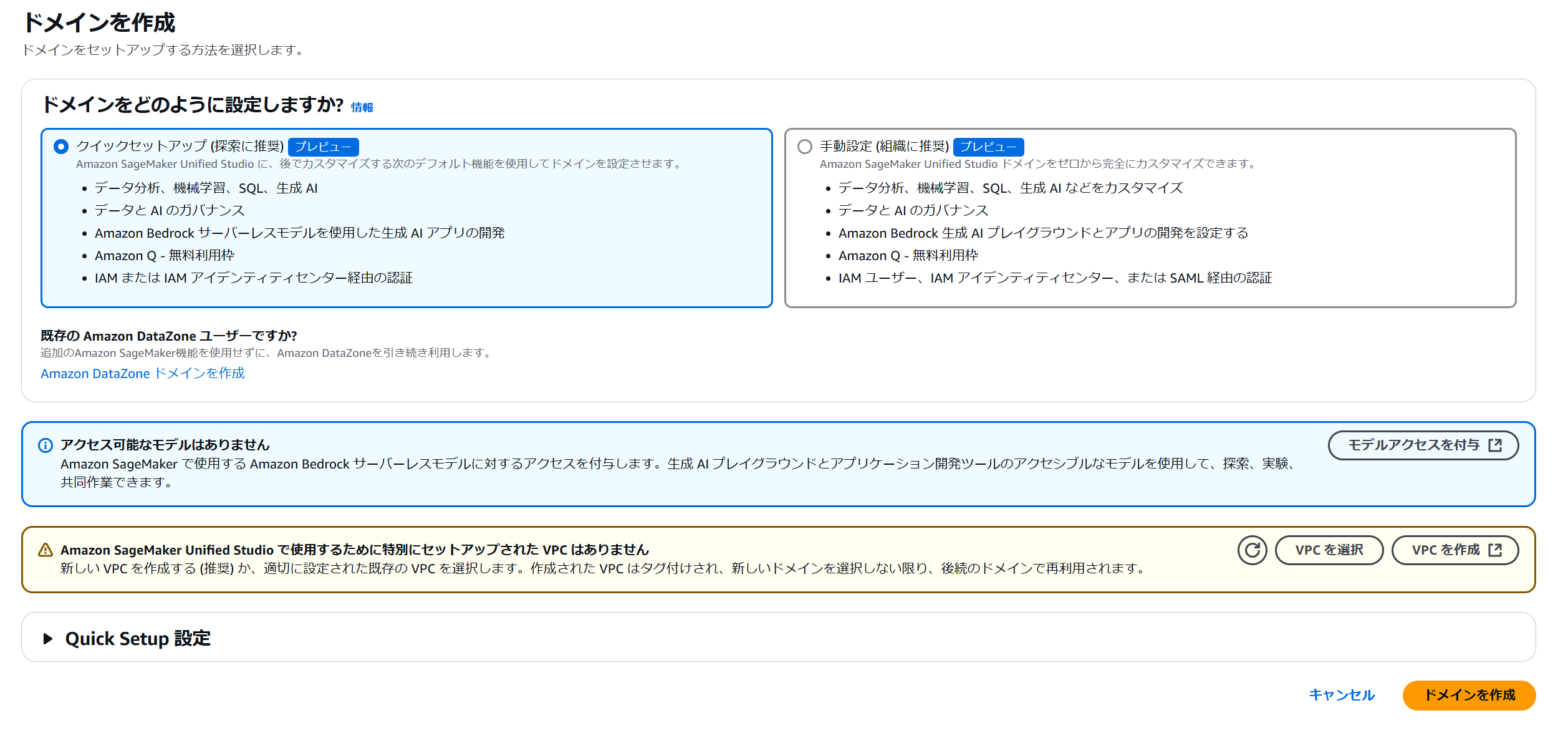
CloudFormation スタッククイック作成画面が立ち上がるので、デフォルト設定のままスタックを作成します。
パラメータ useVpcEndpoints をデフォルトの false から true に変更すると、Unified Studio が連携する各種 AWS サービスの VPC エンドポイントが作成され、追加費用が発生します。要件に応じて変更を検討してください。
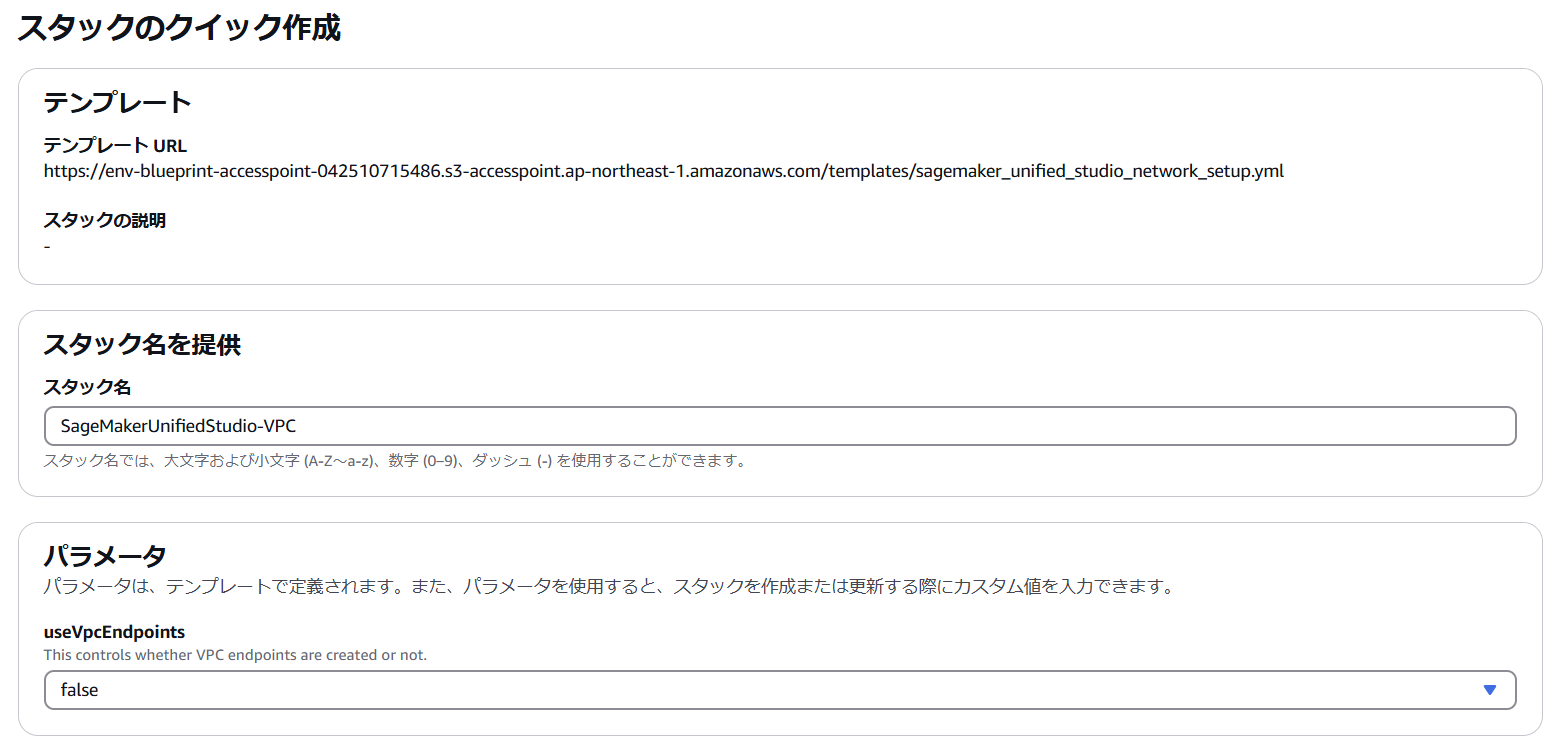
useVpcEndpoints をデフォルトの false で作成した場合は以下のようなシンプルな構成の VPC が作成されます。
「Amazon SageMaker Unified Studio で使用するために特別にセットアップされた VPC はありません」の更新ボタンをクリックすると警告が消えます。
Quick Setup 設定ではドメイン名および暗号化設定のカスタマイズができますが、今回は変更せずにドメインを作成します。

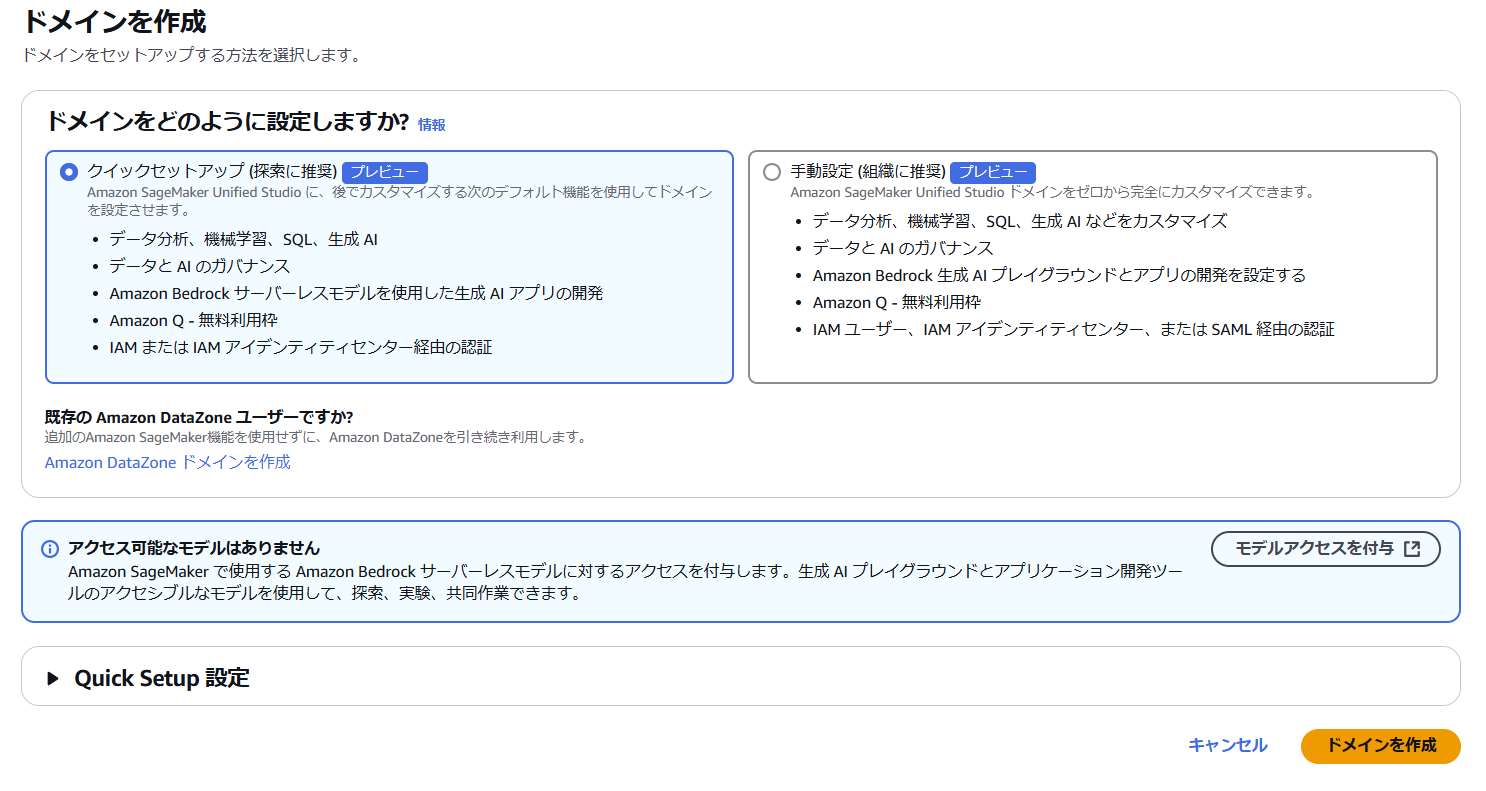
以下の画面が表示されれば、Unified Studio の作成は完了です。

Unified Studio に対するアクセスの設定 (オプション)
Unified Studio は AWS IAM または SSO でアクセスできます。ドメインを作成した IAM プリンシパルに対し、デフォルトでアクセス権が追加されています。それ以外のユーザーにアクセスを許可する場合は個別に追加する必要があります。
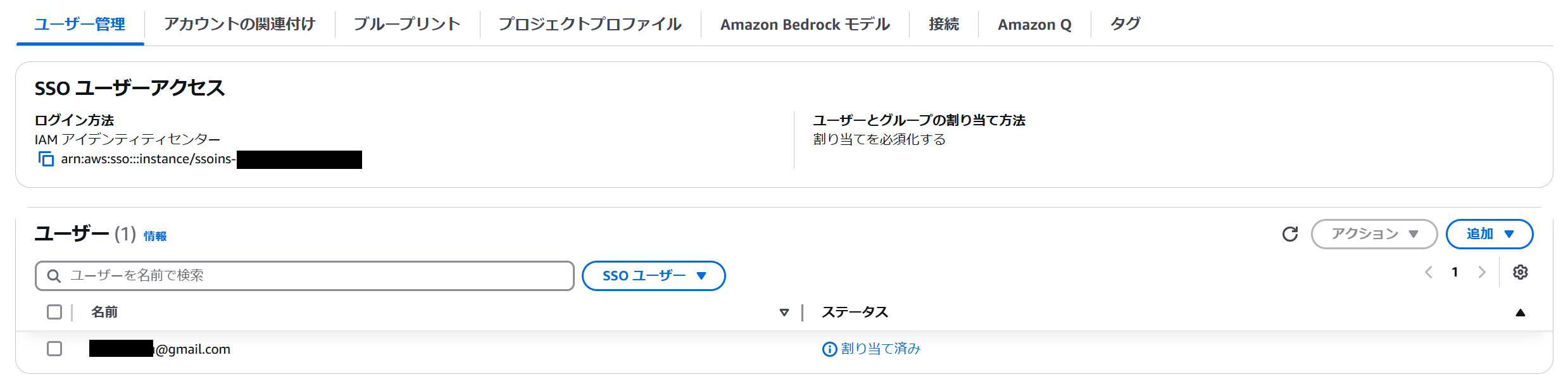
ここでは SSO ユーザーの追加方法を紹介します。ドメインの詳細画面のユーザ登録タブで SSO ユーザーアクセス設定をクリックします。
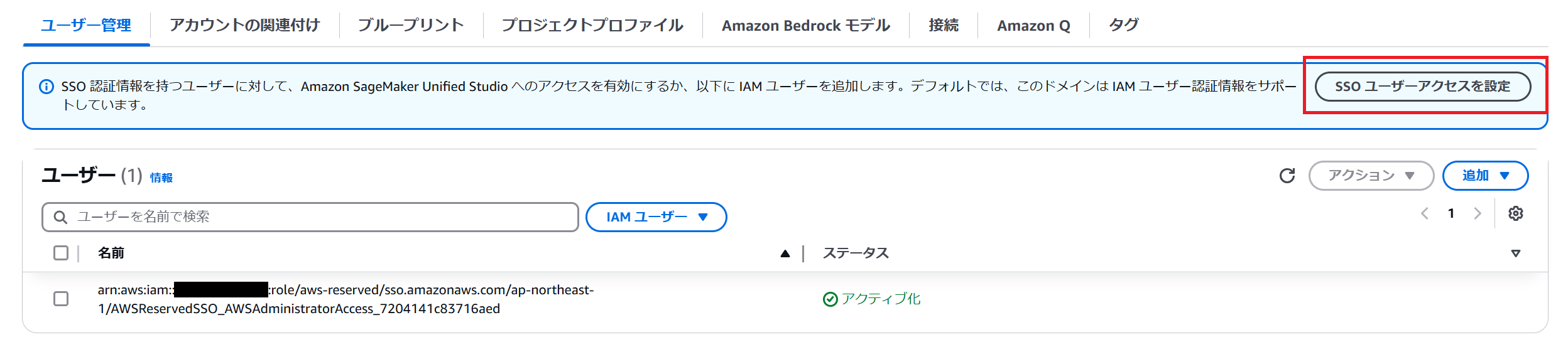
ステップ 1 で認証方法を設定します。ここでは IAM アイデンティティセンターを選択します。
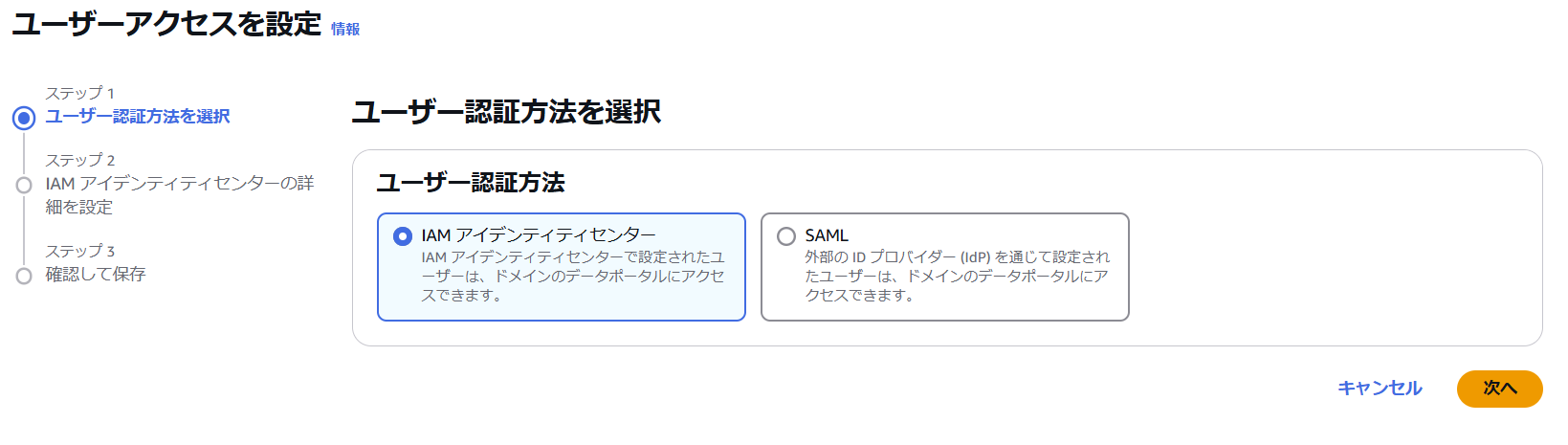
AWS IAM Identity Center でユーザー認証を行う場合、IAM Identity Center のリージョンと SageMaker ドメインのリージョンが一致している必要があります。
ステップ 2 でユーザーとグループの割り当て方法を選択します。ここでは「割り当てを必須化する」を選択します。必須化しないを選択した場合は、すべての IAM アイデンティティセンターのユーザーとグループへアクセスが許可されます。
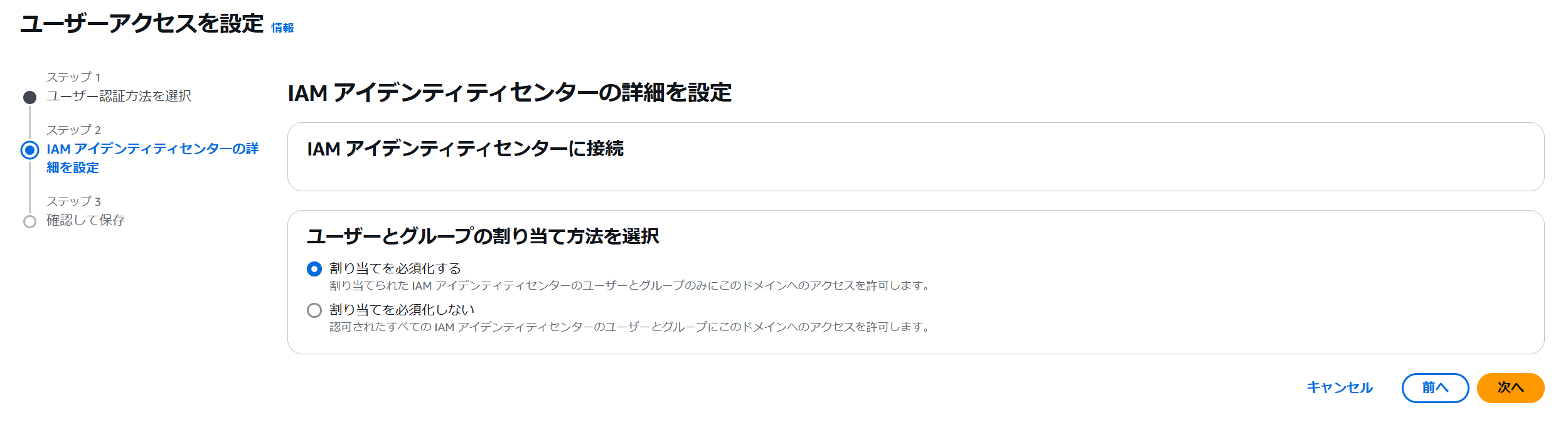
ステップ 3 確認画面に移動したら、ステップ 2 の編集をクリックします。2024/12/19 時点でコンソールの不具合か、IAM Identity Center のインスタンスが自動で入力されないためです。
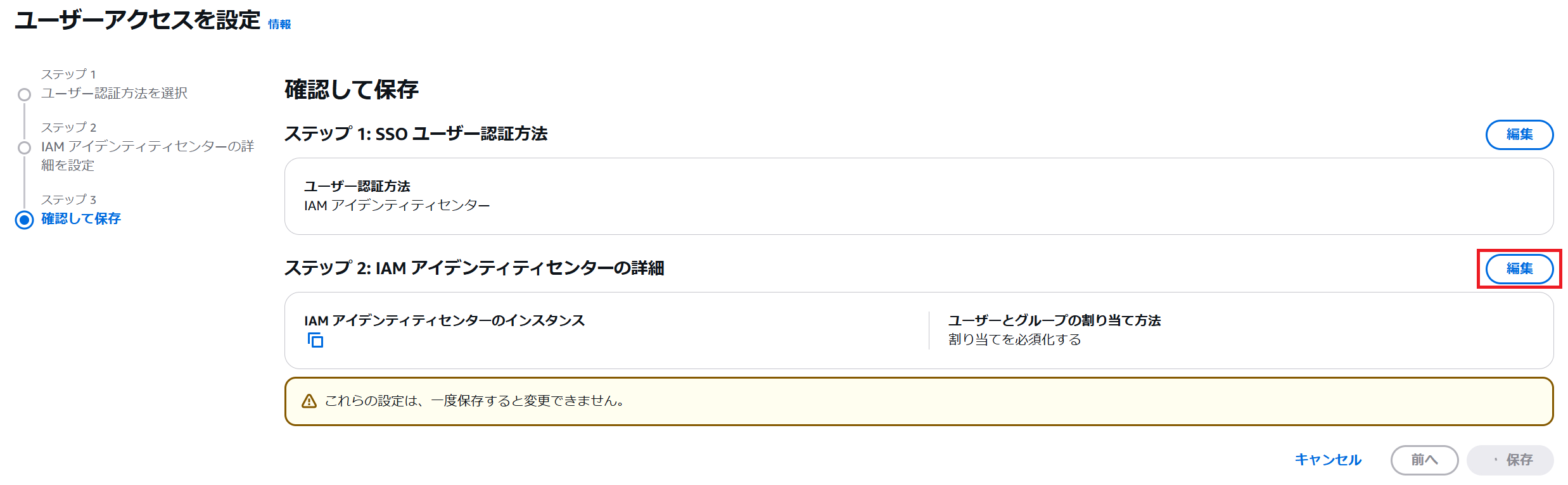
今度は自動で接続が設定されるので次へをクリックします。
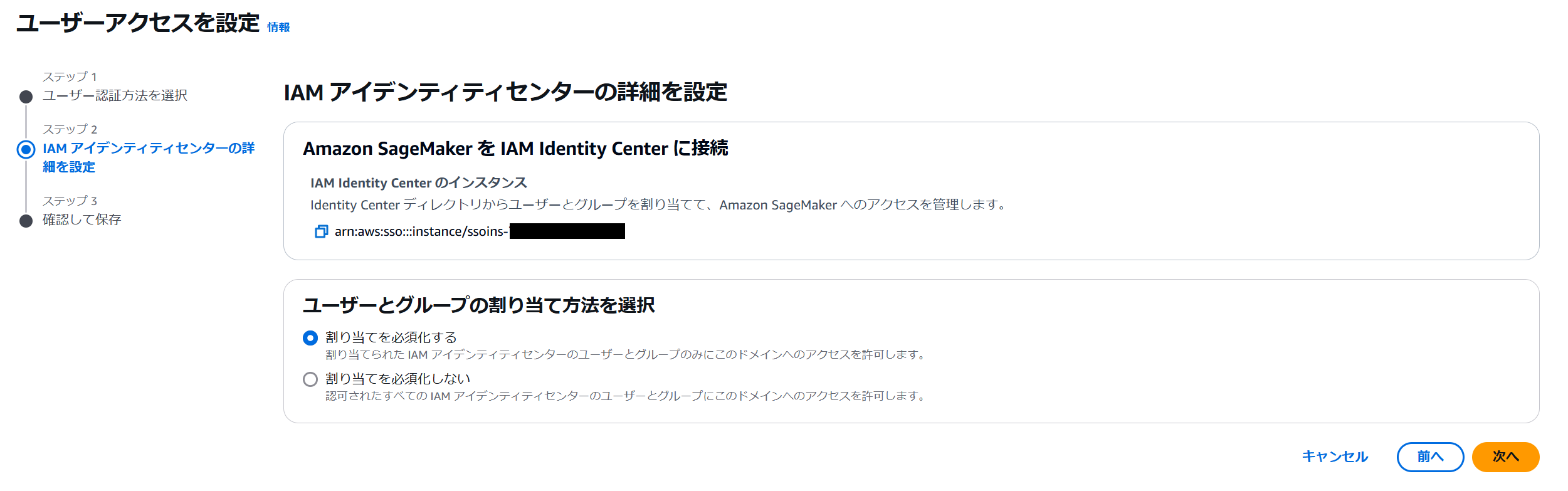
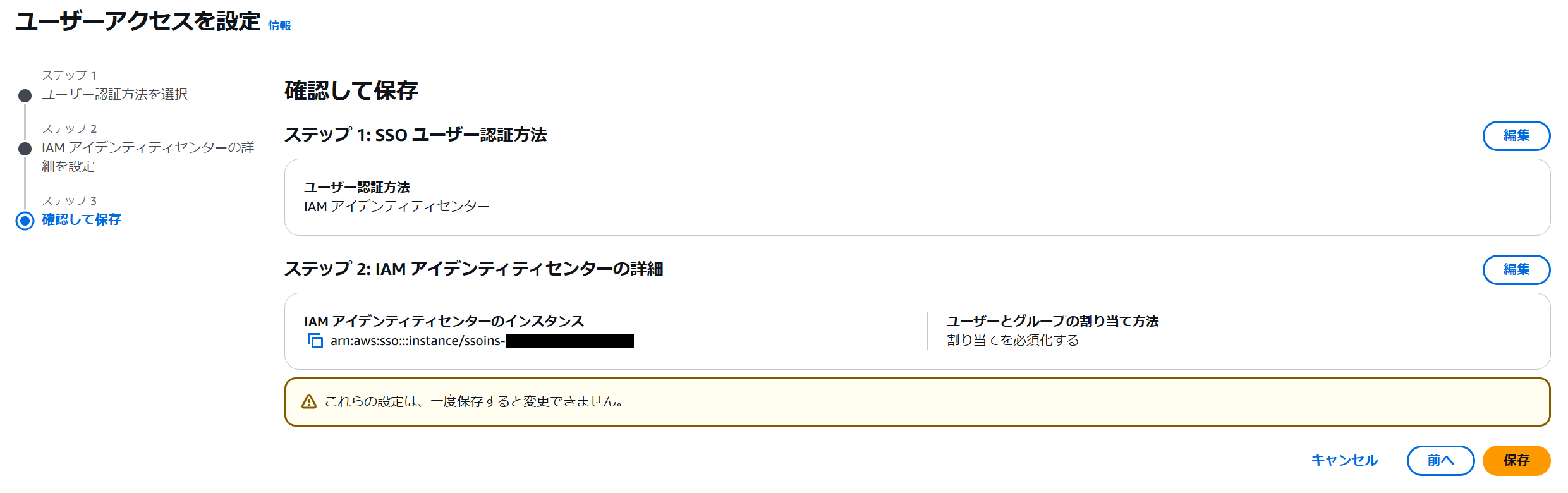
確認画面に戻ったら設定を保存します。
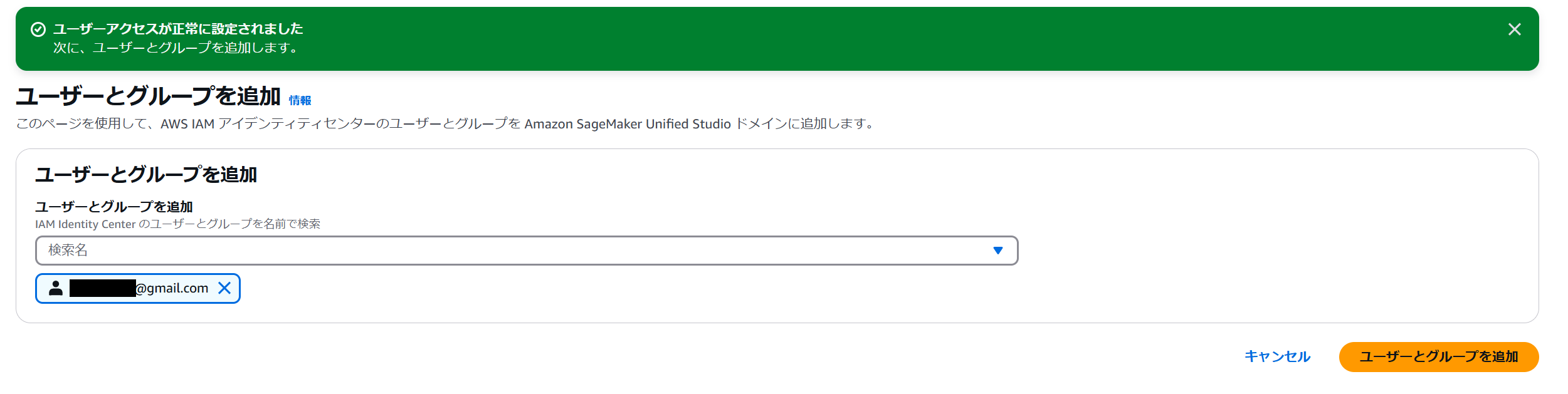
そのままユーザーとグループの追加画面に遷移します。任意のユーザーやグループを追加し、ステータスが割り当て済みになれば OK です。
Unified Studio へのログインとプロジェクトの作成
Unified Studio の URL はドメインの詳細から確認できます。

SSO ユーザー または IAM でサインインします。2024/12/19 時点では IAM でサインインした場合にコンソール上でエラー表示が頻発する (ただし操作自体は問題なくできる) ため、SSO ユーザーを使用するのが無難かもしれません。

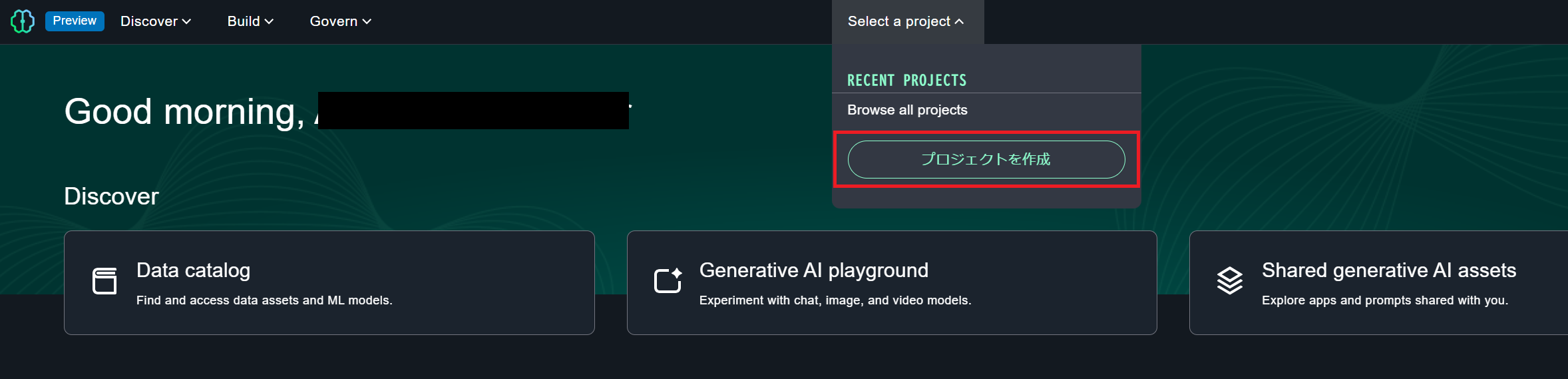
サインインしたら画面上部の「select a project」からプロジェクトを作成をクリックします。ユーザーは作成したプロジェクト内でデータ分析やモデル開発などの作業を行うことができます。
プロジェクトを作成の Step 1 で任意のプロジェクト名を入力します。今回はデータ分析機能のみをハンズオンするため、プロジェクトのプロファイルで「SQL analytics」を選択します。
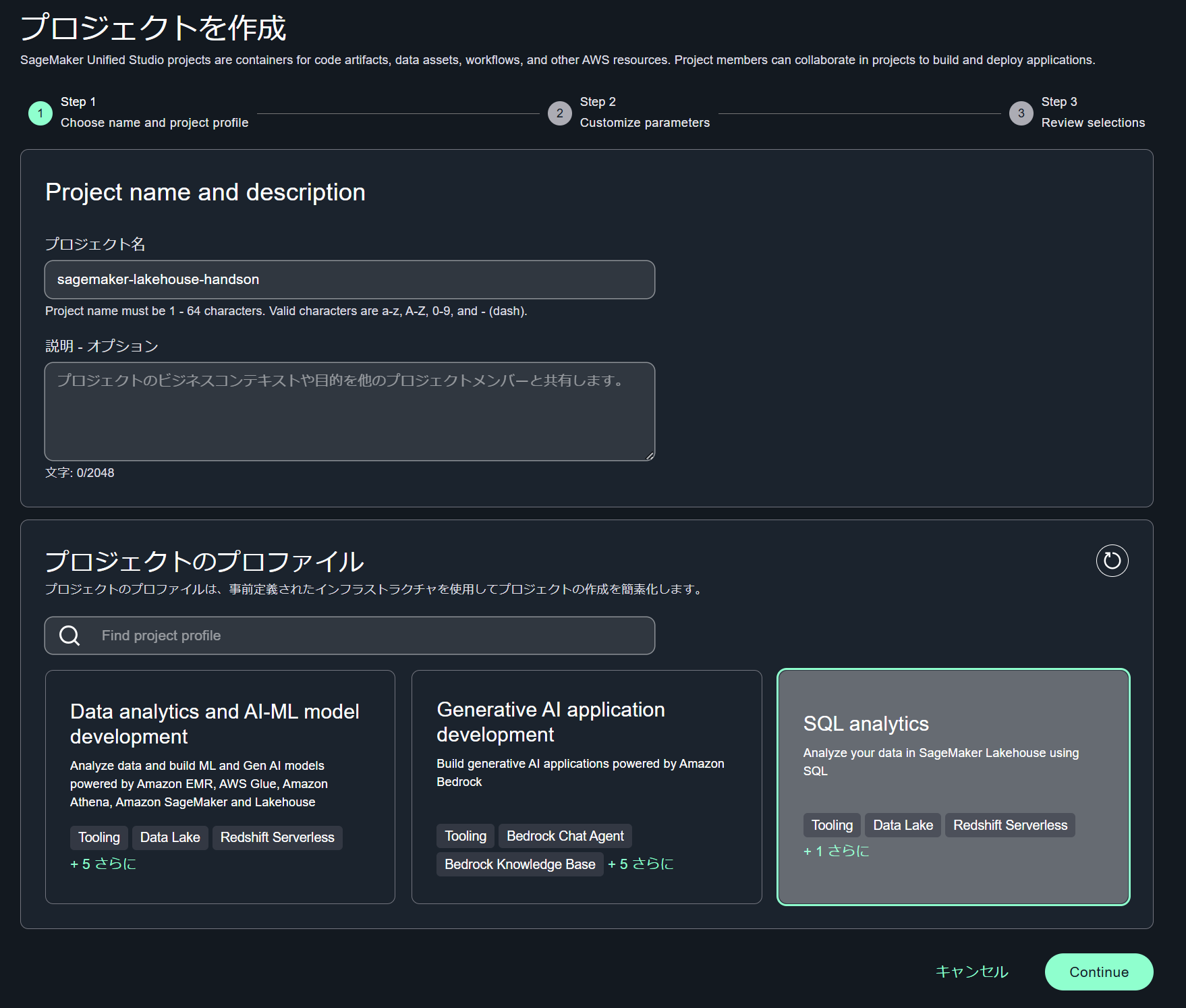
プロジェクト作成により、プロジェクトに紐づく Glue データベース、Athena ワークグループ、Redshift Servelress などのリソースが自動で作成されます。プロジェクト上で分析作業を行う場合にこれらのリソースが使用されます。
Step 2 でプロジェクトに紐づいて作成されるリソースの名称などをオプションで変更できます。ここではデフォルト値のまま次に進みます。
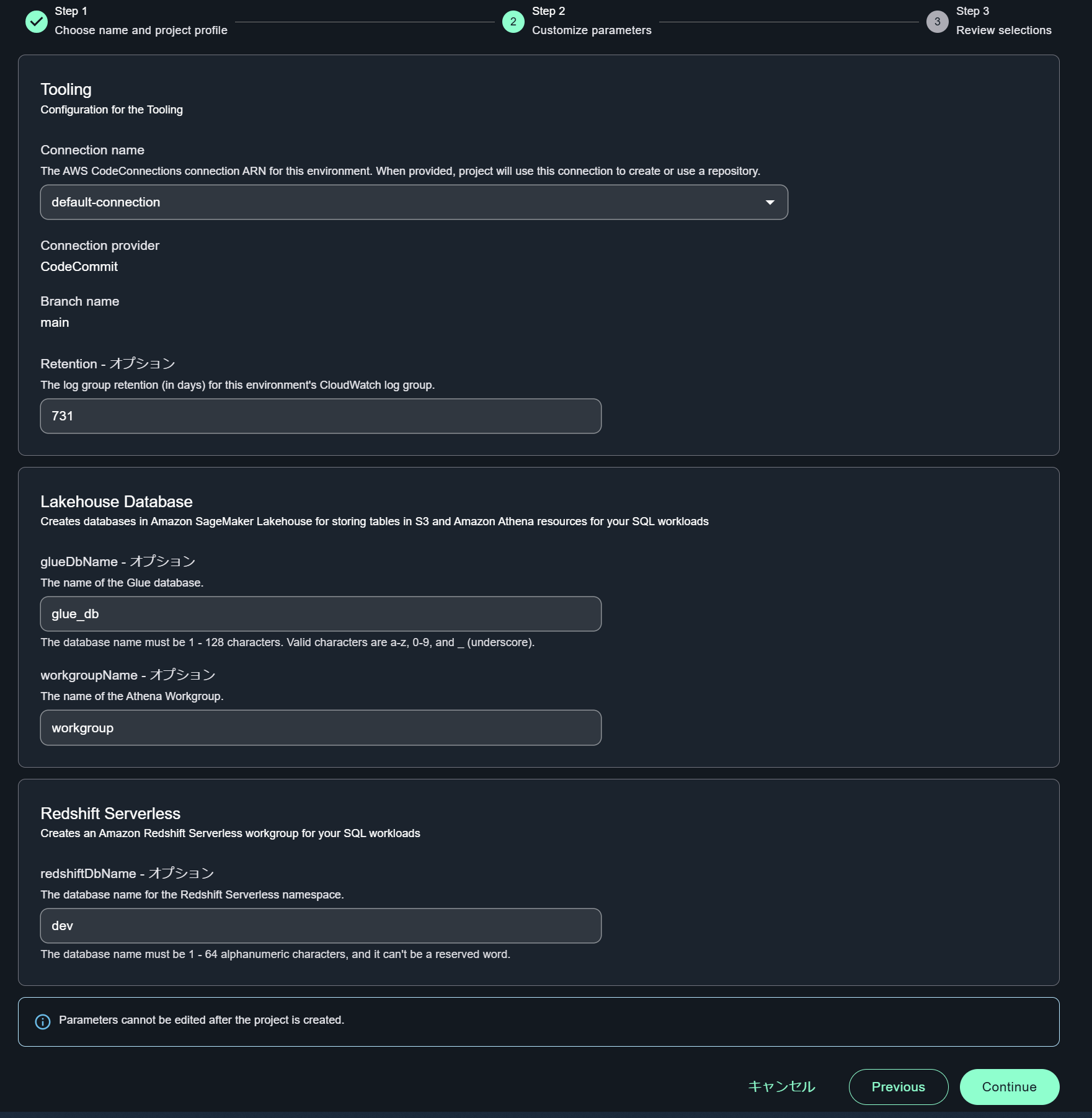
Step 3 で設定値を確認し、プロジェクトの作成をクリックします。
プロジェクトの作成は 5 分程度かかるので気長に待ちます。
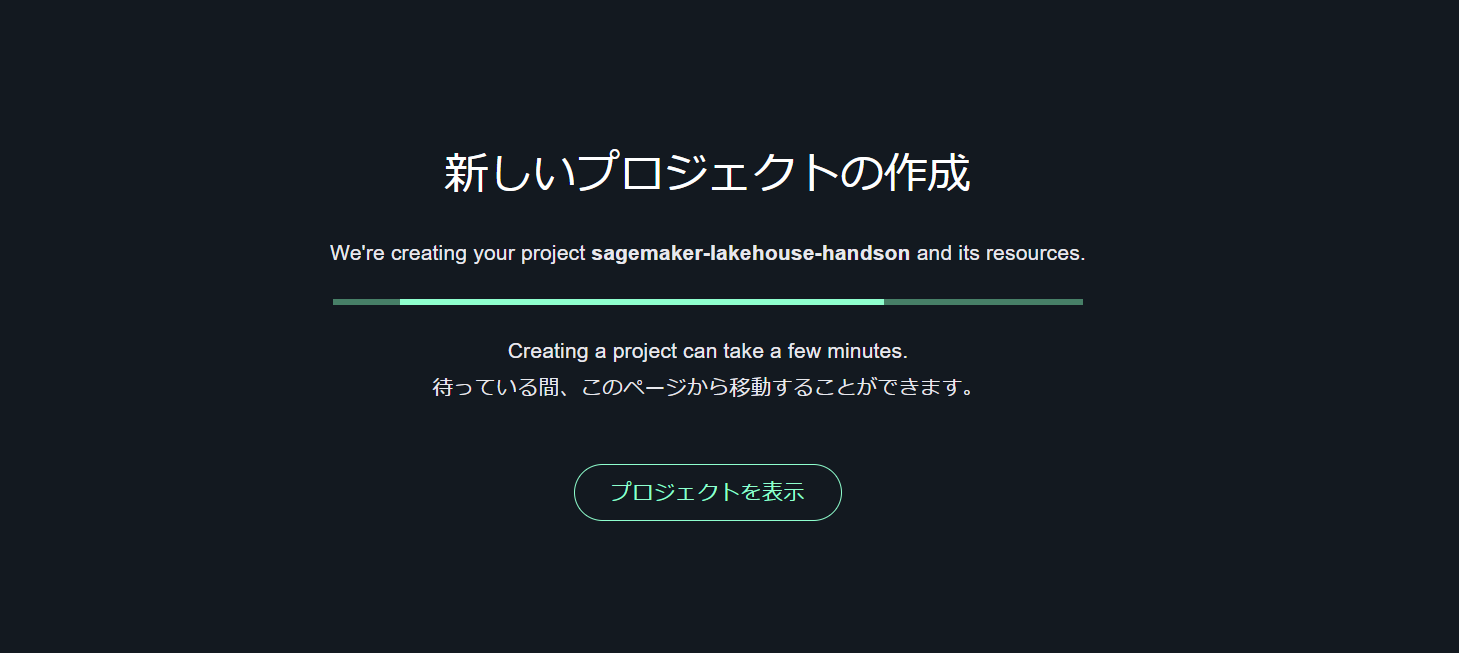
プロジェクトの作成の作成が完了したら、プロジェクトの詳細に記載されているプロジェクトロールの名前を控えておきます。これは後続の手順 (プロジェクトからカタログへのアクセス許可) で必要になります。
データソース (Redshift Serverless) の準備
今回のハンズオンのデータソースとなる Reshift Serverless を個別に作成します。すでに既存の Redshift クラスターが存在する場合はそちらを使用することもできます。
名前空間/ワークグループの作成
ステップ 1 で任意のワークグループ名を入力します。ベース容量を最小の 8 に設定しておきます。
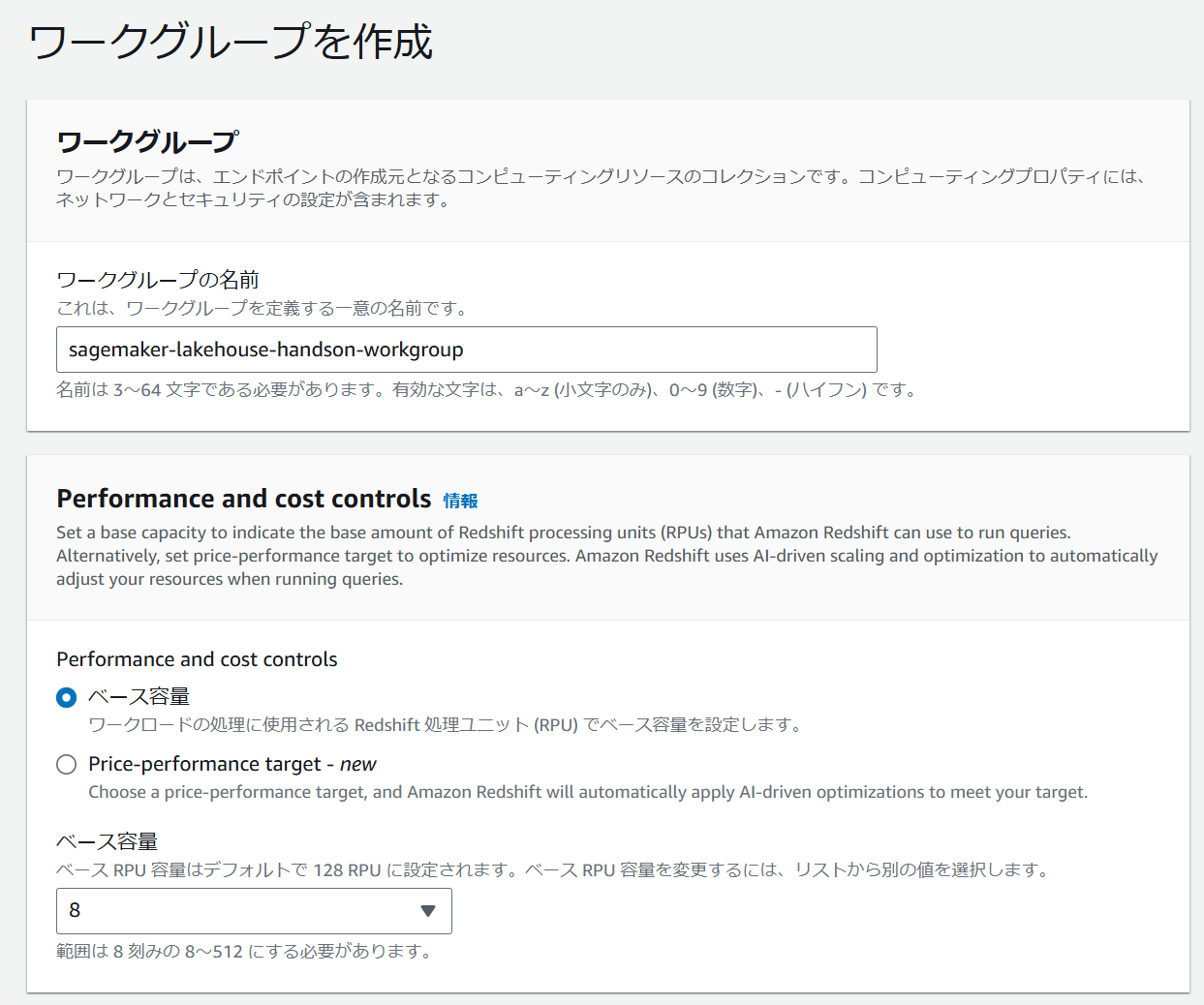
画面下部のネットワークとセキュリティで Redshift Serverless を配置する VPC やサブネット、セキュリティグループを設定し次に進みます。SageMaker Unified Studio から直接 Redshift Serverless のエンドポイントに疎通できる必要はないため、そのあたりの設定は不要です。
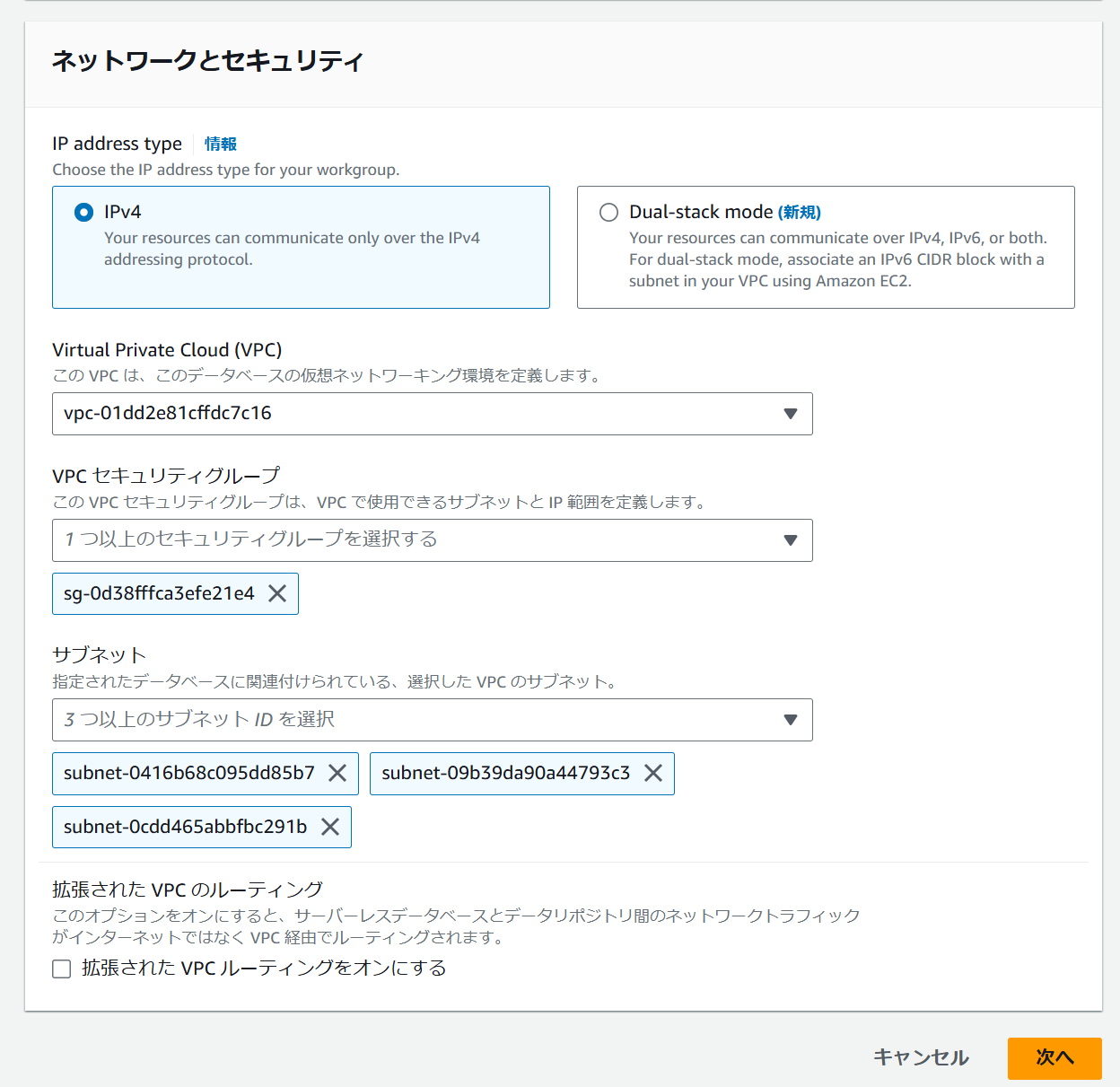
ステップ 2 で任意の名前空間の名前を入力します。
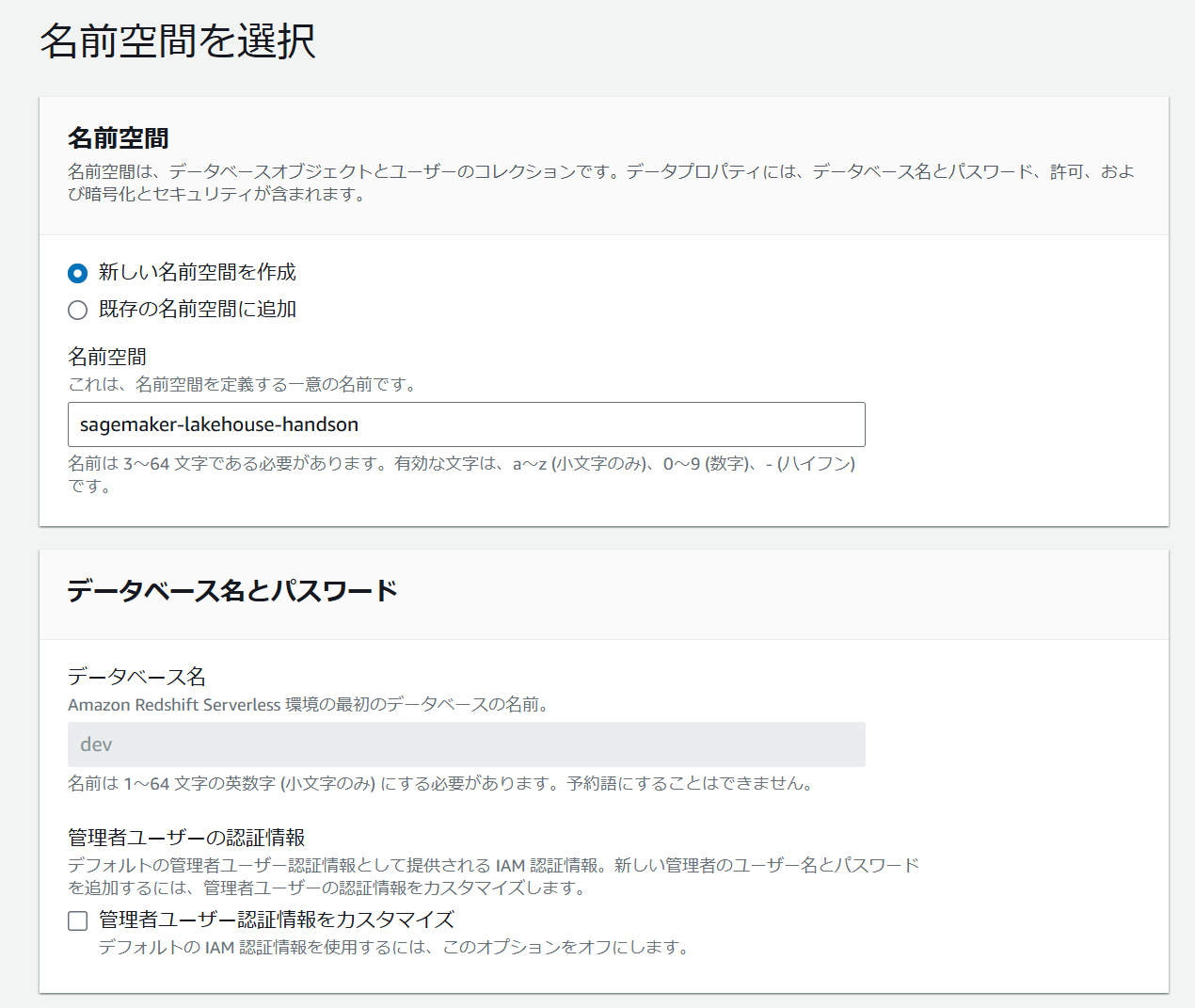
許可の設定で IAM ロールを関連付けます。ここでは IAM ロールを作成から新規のデフォルトロールを作成しています。暗号化とセキュリティの設定はデフォルトのまま次へ進みます。
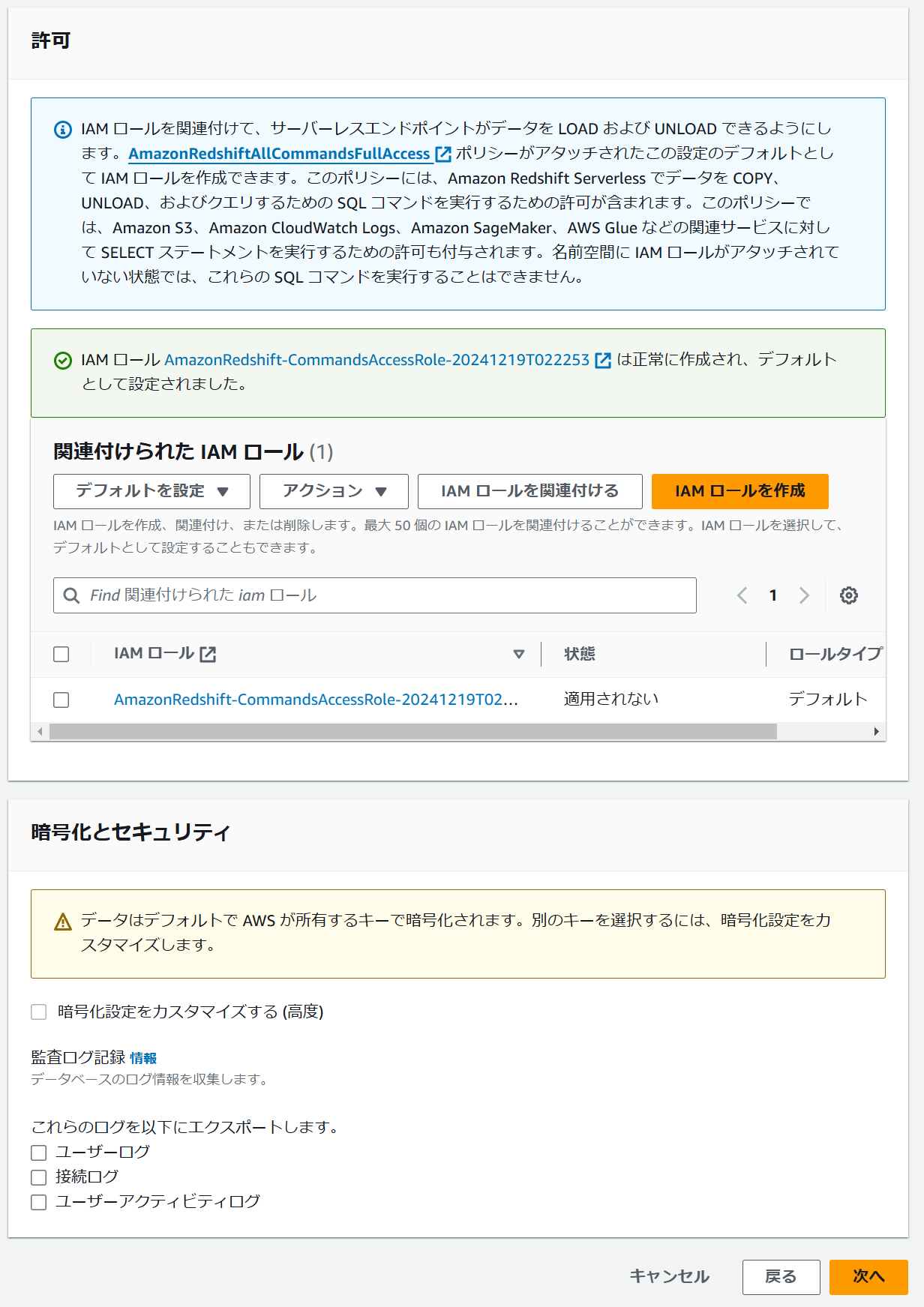
ステップ 3 で設定値を確認し、名前空間/ワークグループ を作成します。
サンプルデータの挿入
作成された名前空間はデータが空っぽですので、サンプルデータを挿入しておきます。Redshift クエリエディタ v2 を開きます。
アカウントでクエリエディタ v2 を初めて使用する場合、設定が表示されます。KMS による暗号化設定は後から変更できないため、設定時はご注意ください。
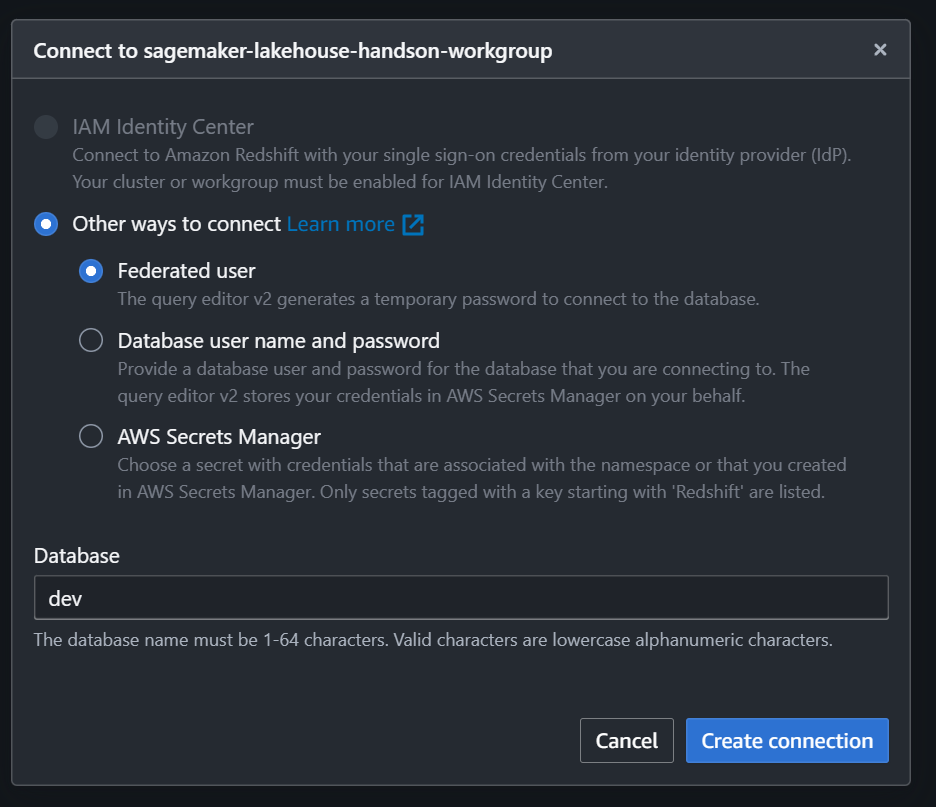
先ほど作成したワークグループに Federated user で接続します。
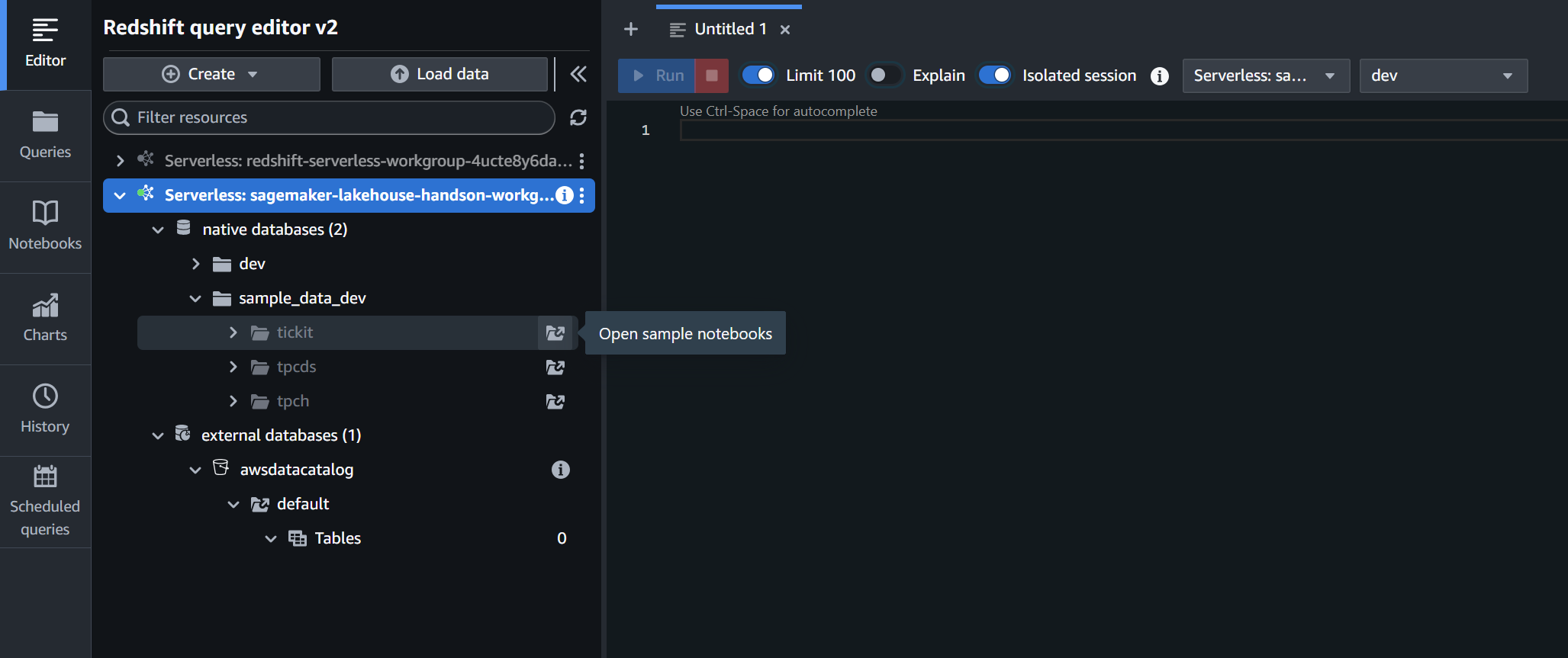
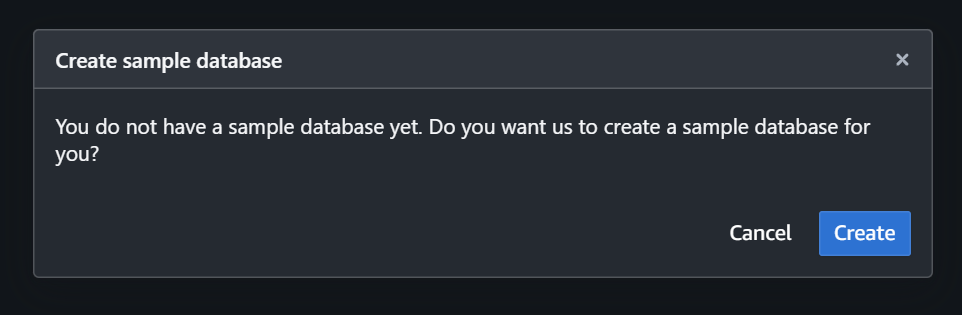
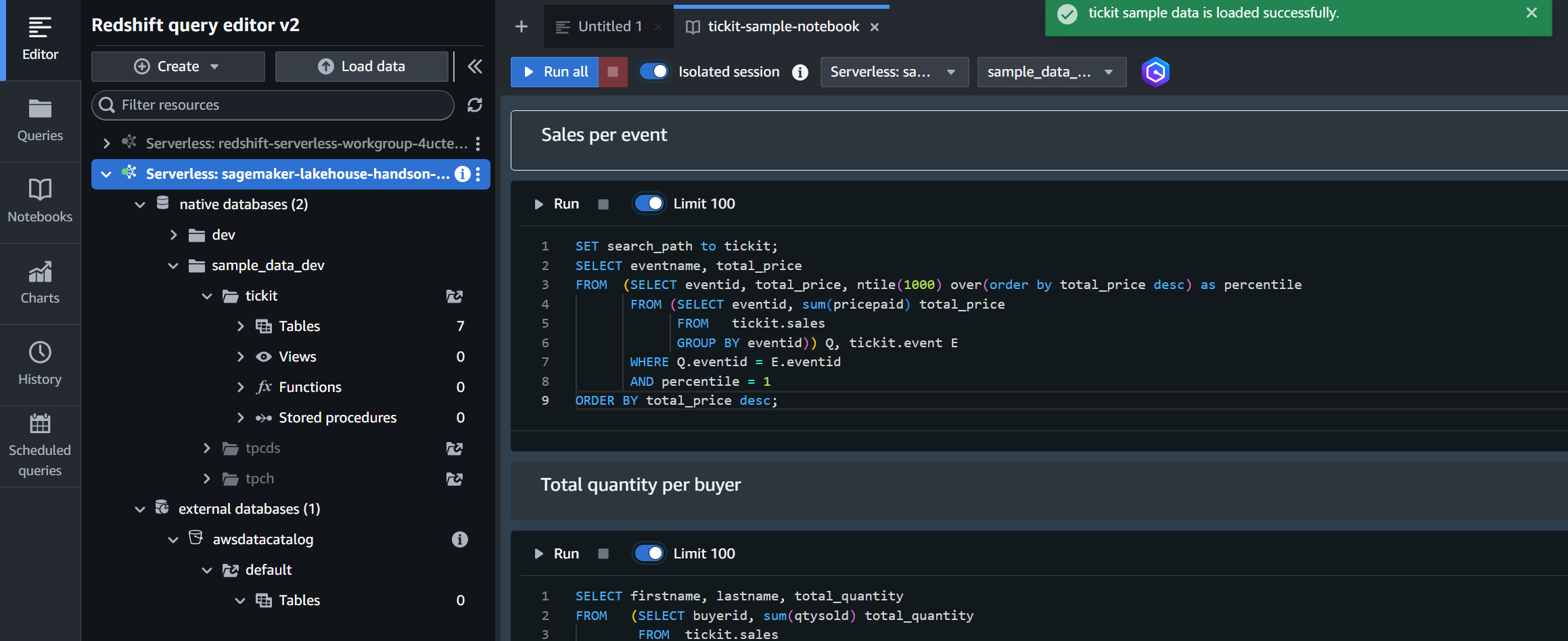
native databases (2) → sample_data_dev → tickit の Open sample notebooks をクリックするとサンプルデータベースの作成に関する確認画面が表示されるので、Create をクリックして作成を完了します。
Redshift Serverless を SageMaker Lakehouse へ登録する
先ほど作成した Redshift Serverless の名前空間を SageMaker Lakehouse に登録します。SageMaker Lakehouse は Glue Data Catalog と Lake Formation 上に構築されているため、Lake Formation でカタログの作成と権限設定をおこなうことで、Lakehouse から Redshift 上のデータを参照できるようになります。
名前空間の登録
Redshift コンソールで作成した名前空間の設定画面からアクション → Register with AWS Glue Data Catalog をクリックします。
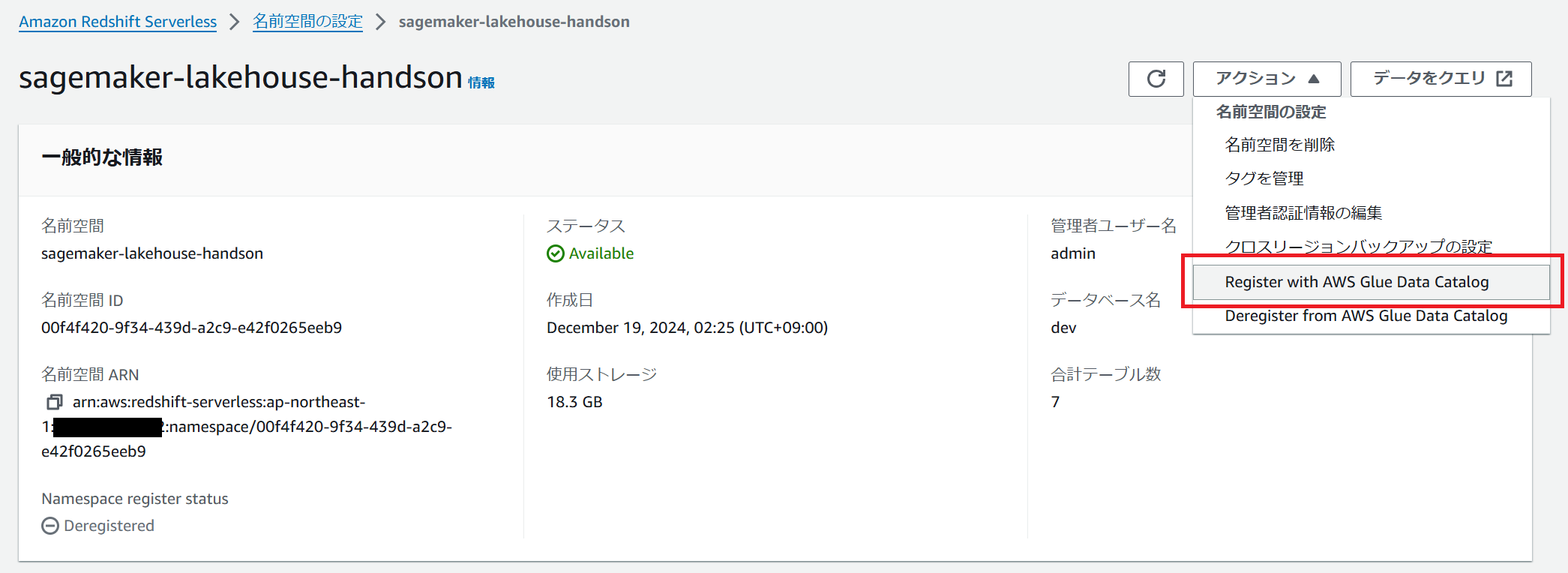
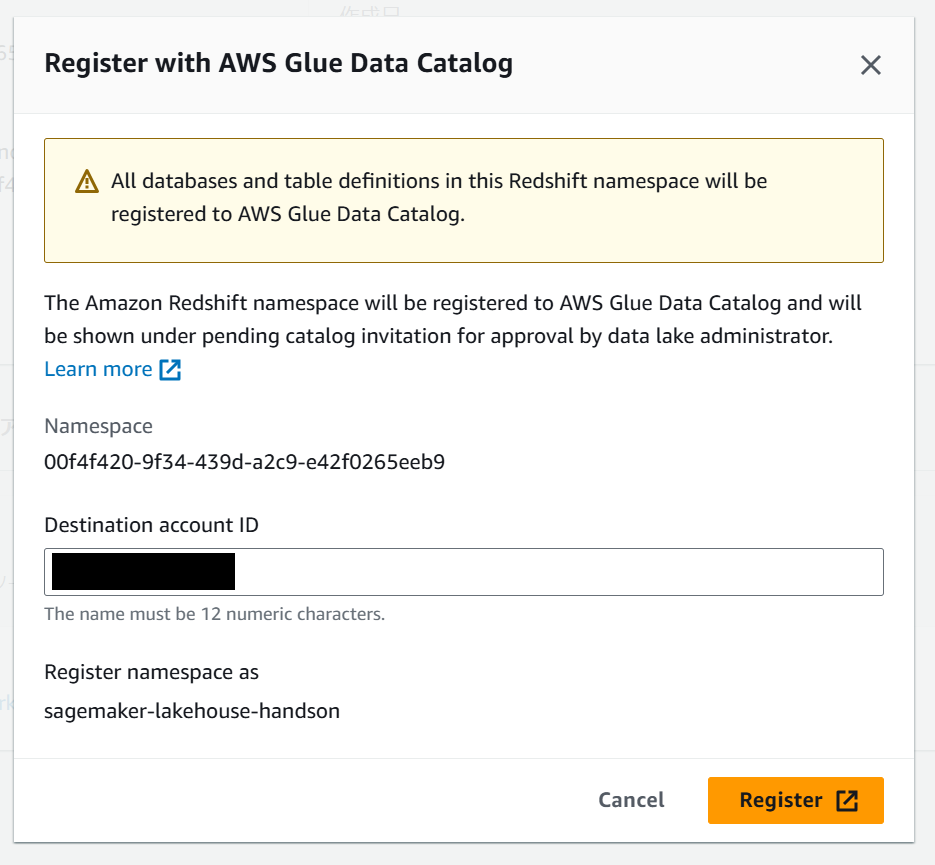
確認画面が表示されるので、Register をクリックします。
Lake Formation の設定
後述の手順 (Federated カタログの作成) の前提作業として Lake Formation の各種設定をおこないます。
Lake Formation のコンソールに移動し、Administration → Administrative roles and tasks から Data lake administrators を追加します。
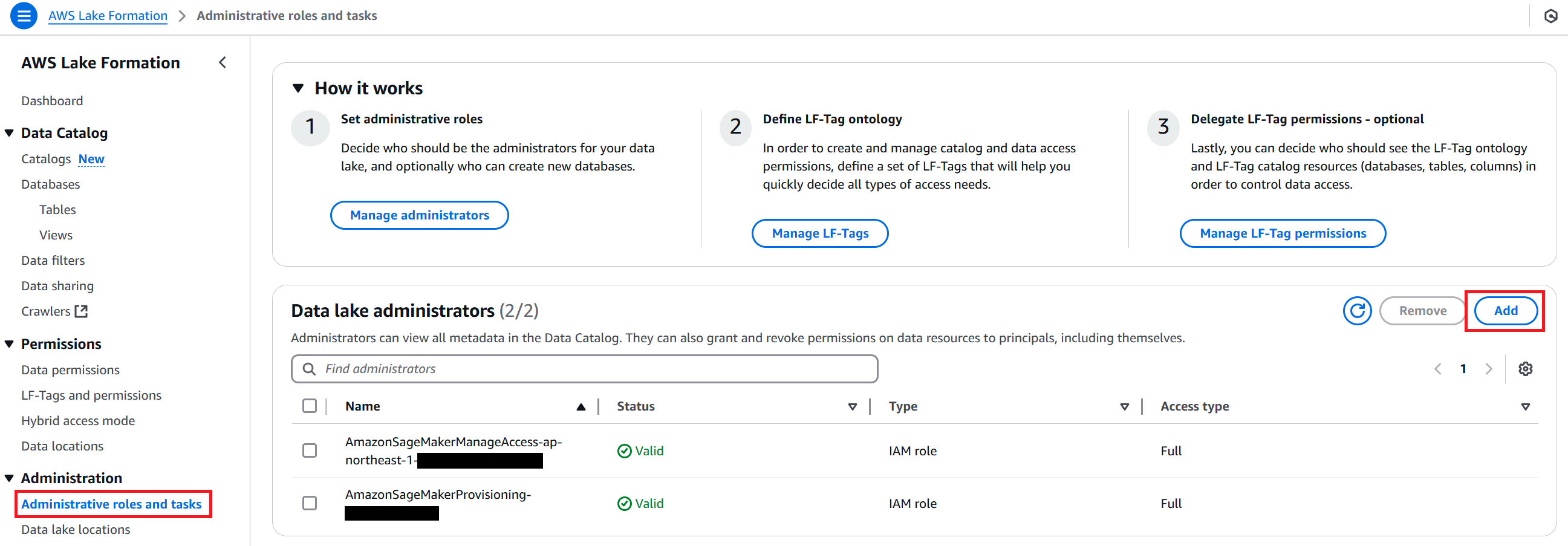
Read-only Administrator として AWSServiceRoleForRedshift を追加します。
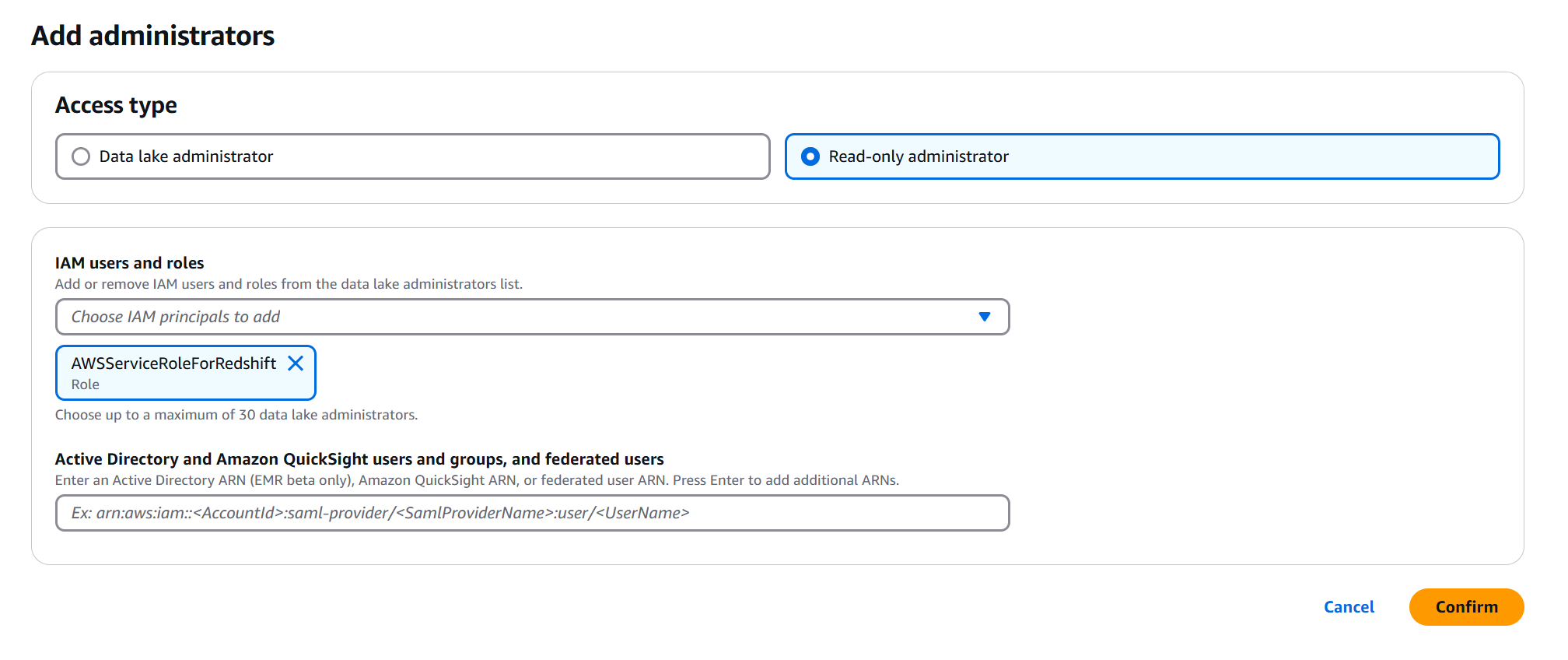
同様の手順で、Data lake administrator としてこのハンズオンで作業している IAM を追加します。
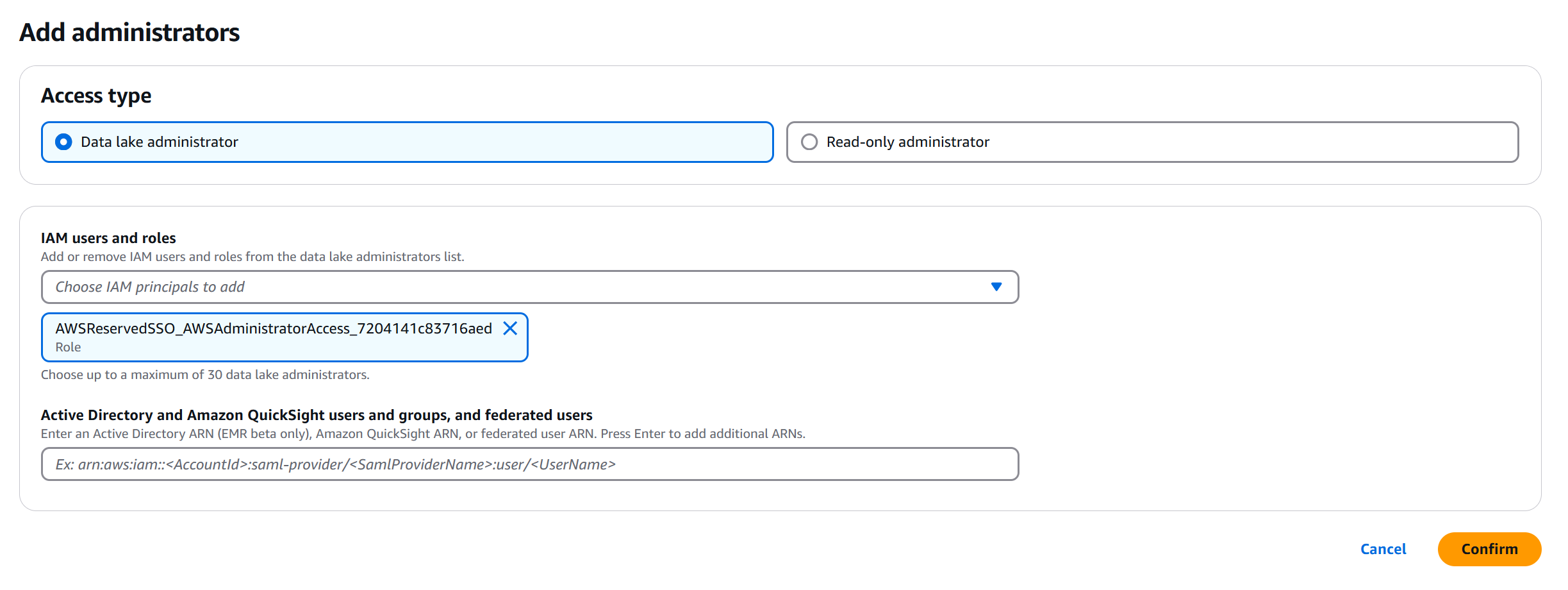
同じ IAM に対し、カタログを作成する権限を付与します。Catalog creators で Grant をクリックして Create catalog 権限を追加します。

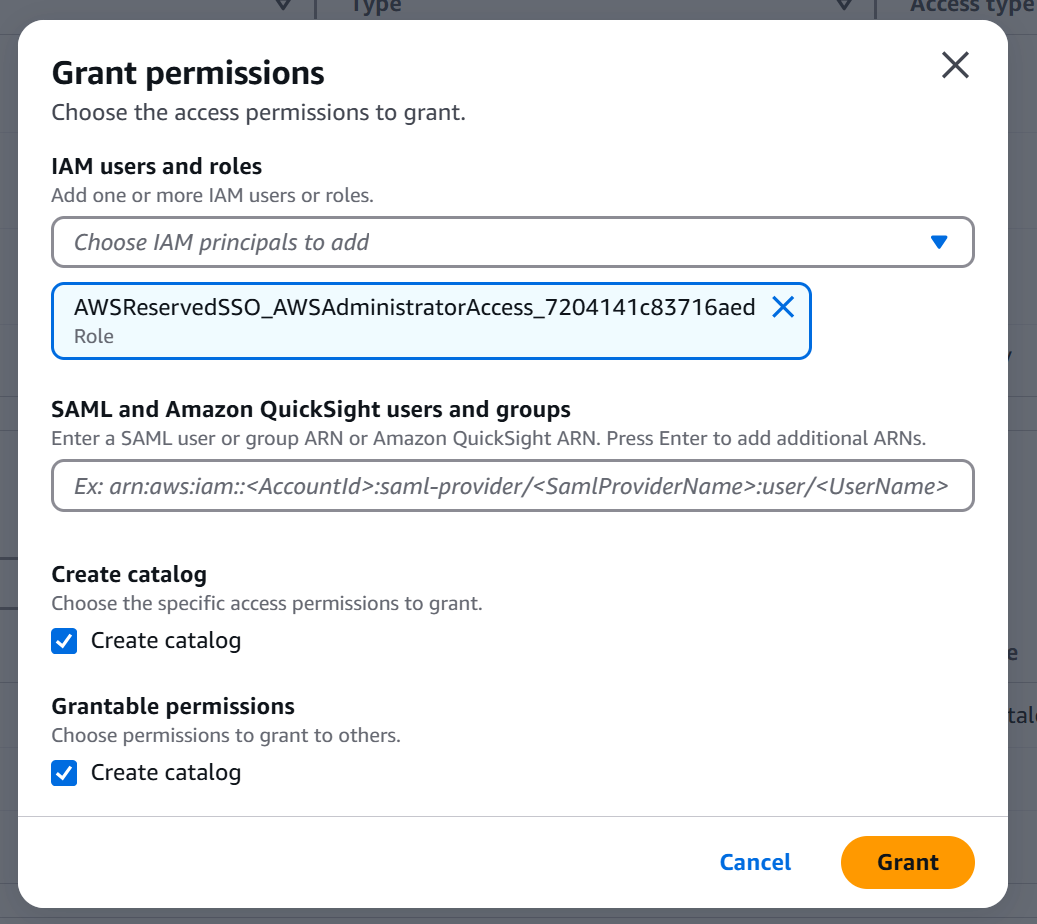
以上で Lake Formation の事前準備は完了です。
Federated カタログの作成
SageMaker Lakehouse で利用できるテクニカルカタログには Managed カタログと Federated カタログの 2 種類があります。既存のリソースを Lakehouse から参照するには Federated カタログの作成が必要です。
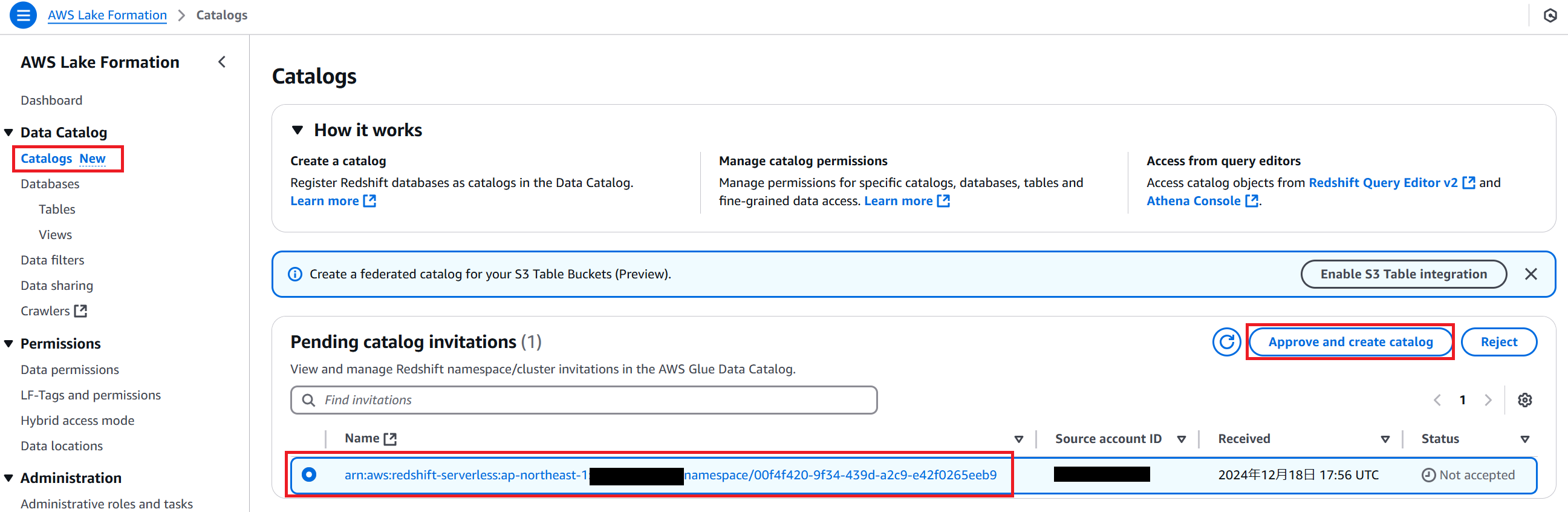
Lake Formation コンソールに新しく作成されている Catalogs というメニューに移動すると、Pending catalog invitaions に先ほど登録をおこなった Redshift Serverless の名前空間が表示されています。これを選択し、Approve and ceate catalog をクリックします。
Step 1 で任意のカタログ名を入力します。カタログタイプは自動で Federated が選択されています。
「Access this catalog from Apache Iceberg compatible engines.」にチェックを入れたままにしておくことで Athena や EMR 上の Apache Spark などの Iceberg 互換のクエリエンジンから Redshift 上のデータへアクセスできるようになります。
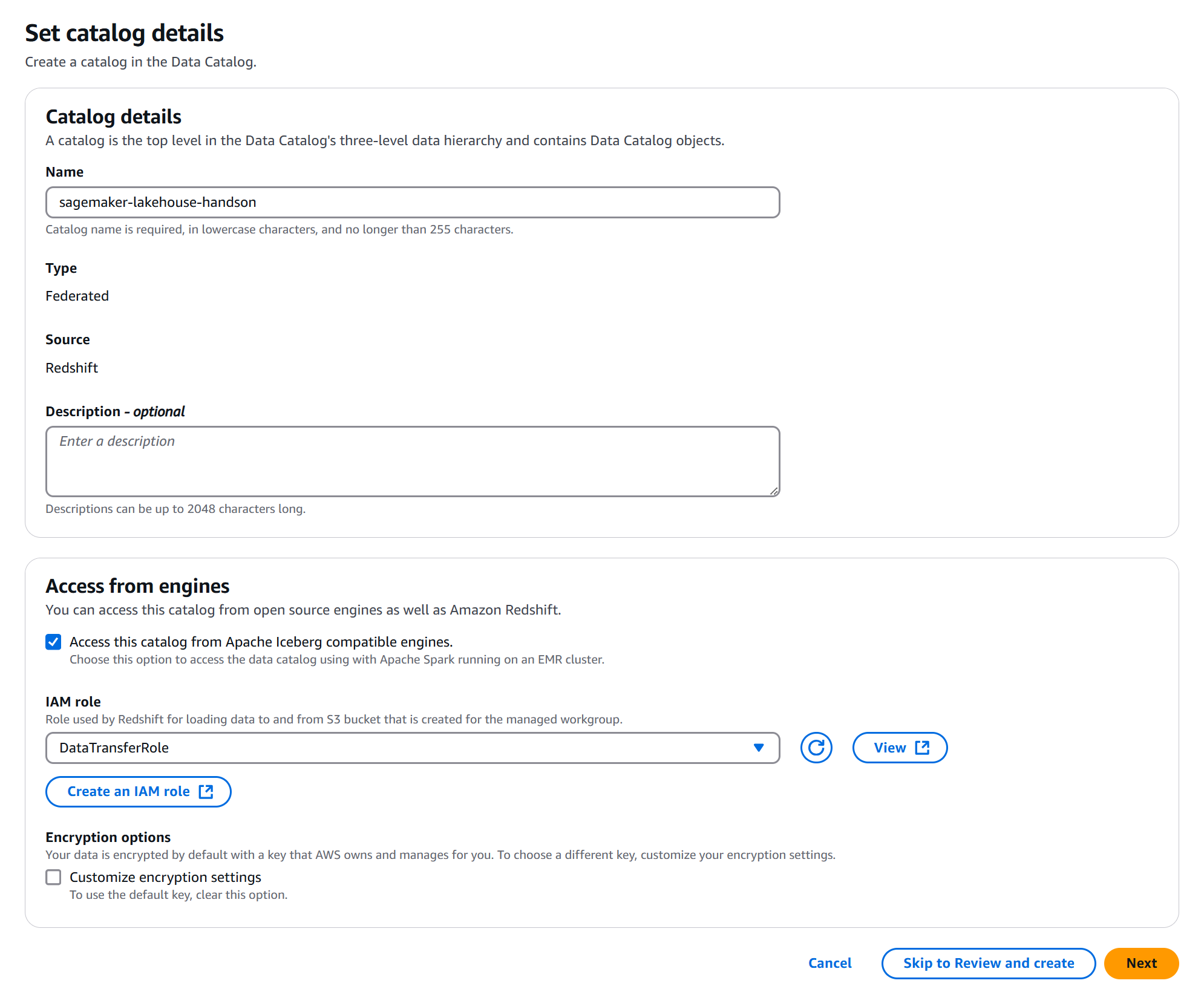
IAM role には Redshift と S3 との間でデータを転送するためのデータ転送ロールを設定する必要があります。以下の IAM ポリシーと信頼ポリシーを設定した IAM ロールを作成し、指定してください。
{
"Version": "2012-10-17",
"Id": "glue-enable-datalake-access",
"Statement": [
{
"Sid": "DataTransferRolePolicy",
"Effect": "Allow",
"Action": [
"glue:GetCatalog",
"glue:GetDatabase",
"kms:GenerateDataKey",
"kms:Decrypt"
],
"Resource": "*"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"redshift.amazonaws.com",
"glue.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
ドキュメントの記載は以下を参照してください。
Step 2 の Grant permission で Unified Studio で作成したプロジェクトのプロジェクトロールに、Federated カタログに対する権限を設定します。Add permission をクリックします。
この設定をおこなわないと、Unified Studio からデータを参照することはできないため、ご注意ください。
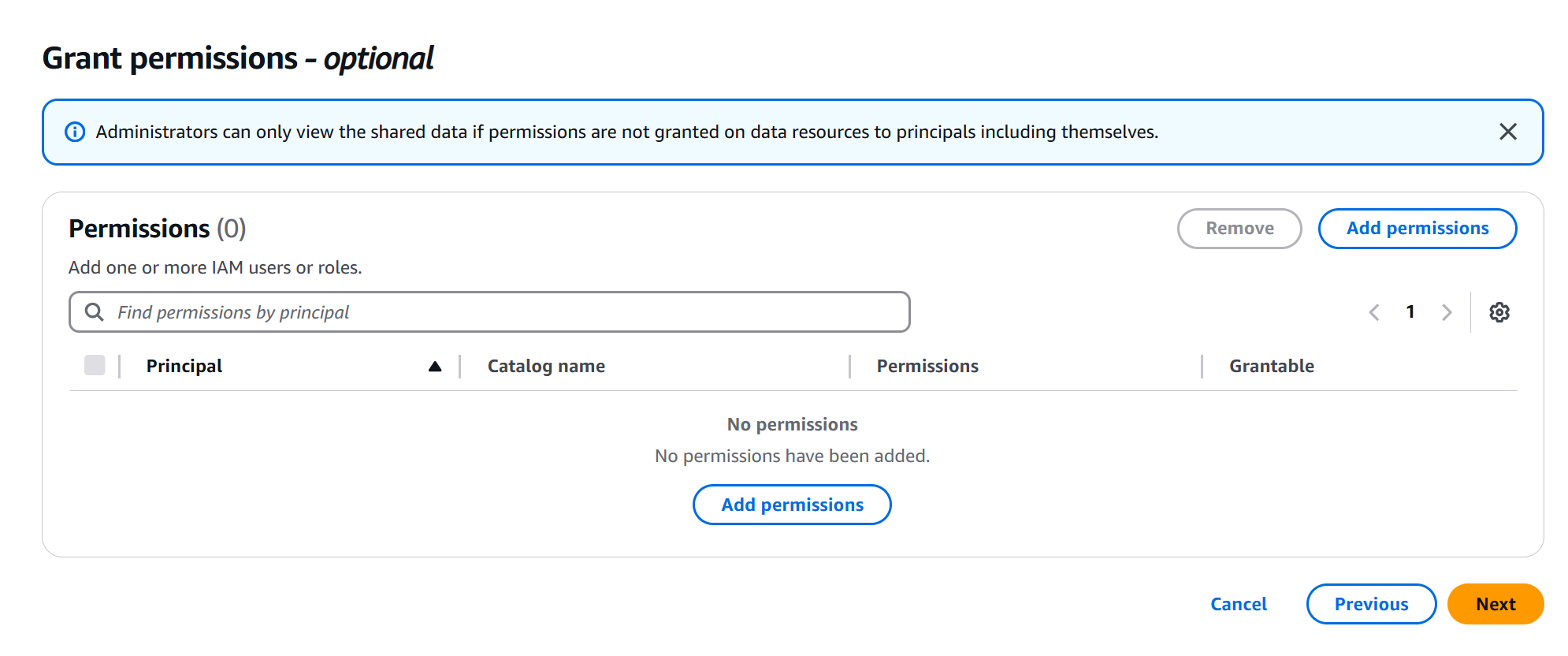
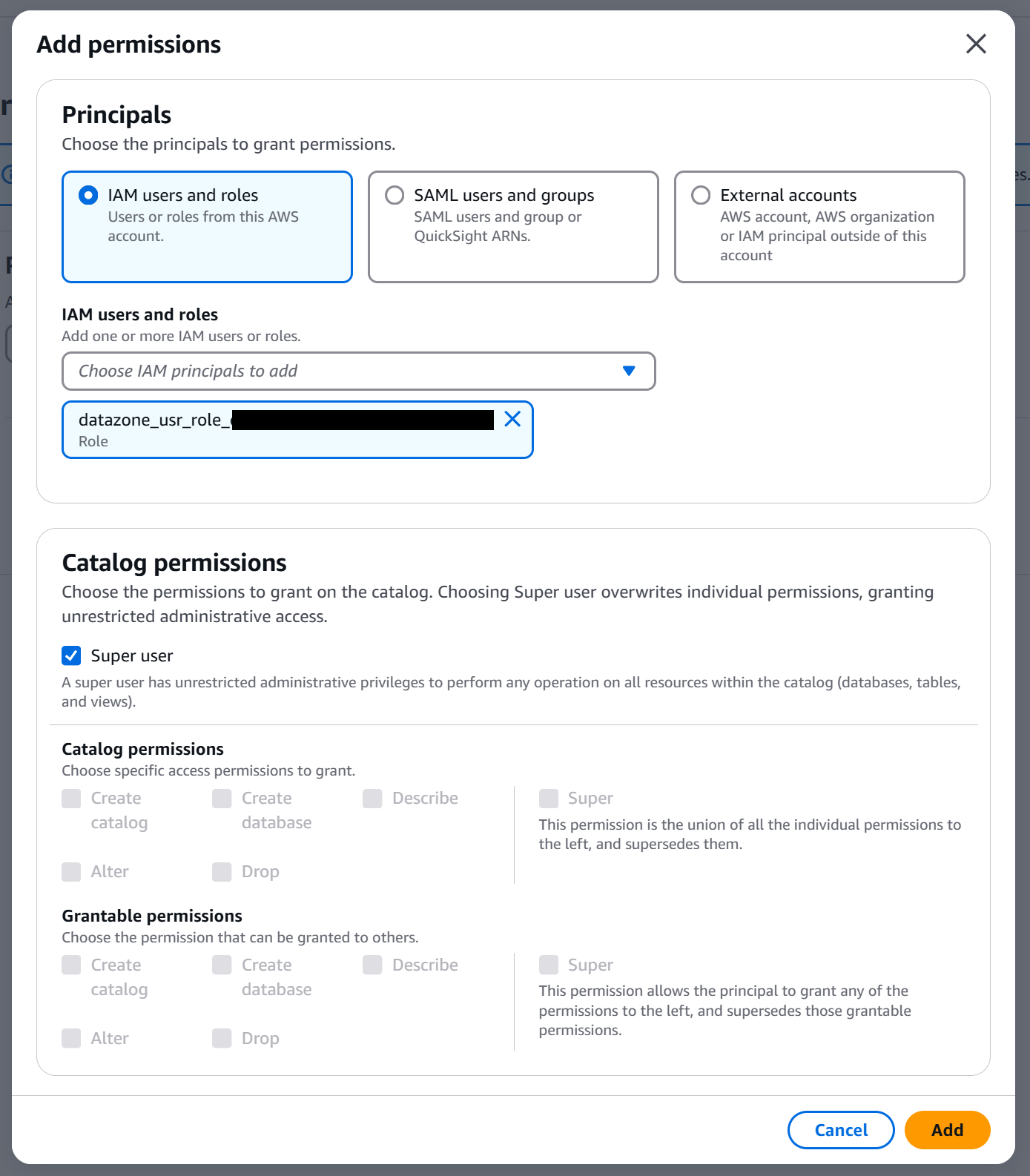
IAM users and roles でプロジェクトロール (datazone_usr_role_xxxxxxxxxxxxx_xxxxxxxxxxxxxx) を選択します。Catalog permissions では Super user を選択して、権限を追加します。
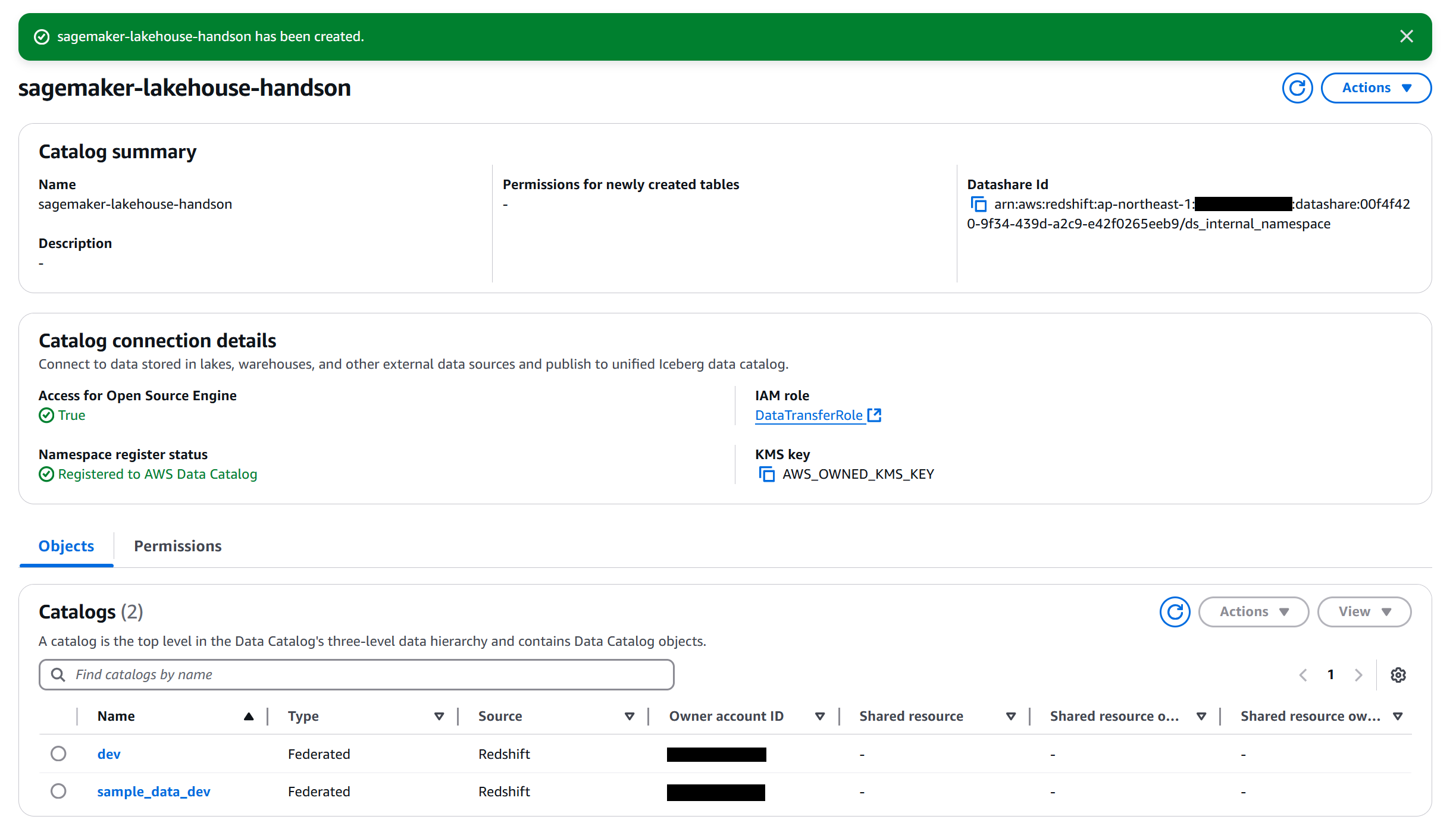
Step 3 で設定内容を確認し、カタログを作成します。以下のような画面が表示されれば作成完了です。
Lakehouse 経由で Athena からクエリを実行
カタログの作成が完了し、Lakehouse 経由で Redshift 上のデータへ複数のコンピュートリソースからアクセスできるようになりました。ここでは先ほど作成したサンプルデータベースに対し、Athena からクエリを実行します。
Unified Studio のプロジェクト → データを選択すると先ほど Lakehouse に登録したカタログが参照できるようになっているはずです。サンプルデータベースの任意のテーブルをクリックして、Query with Athena を選択します。
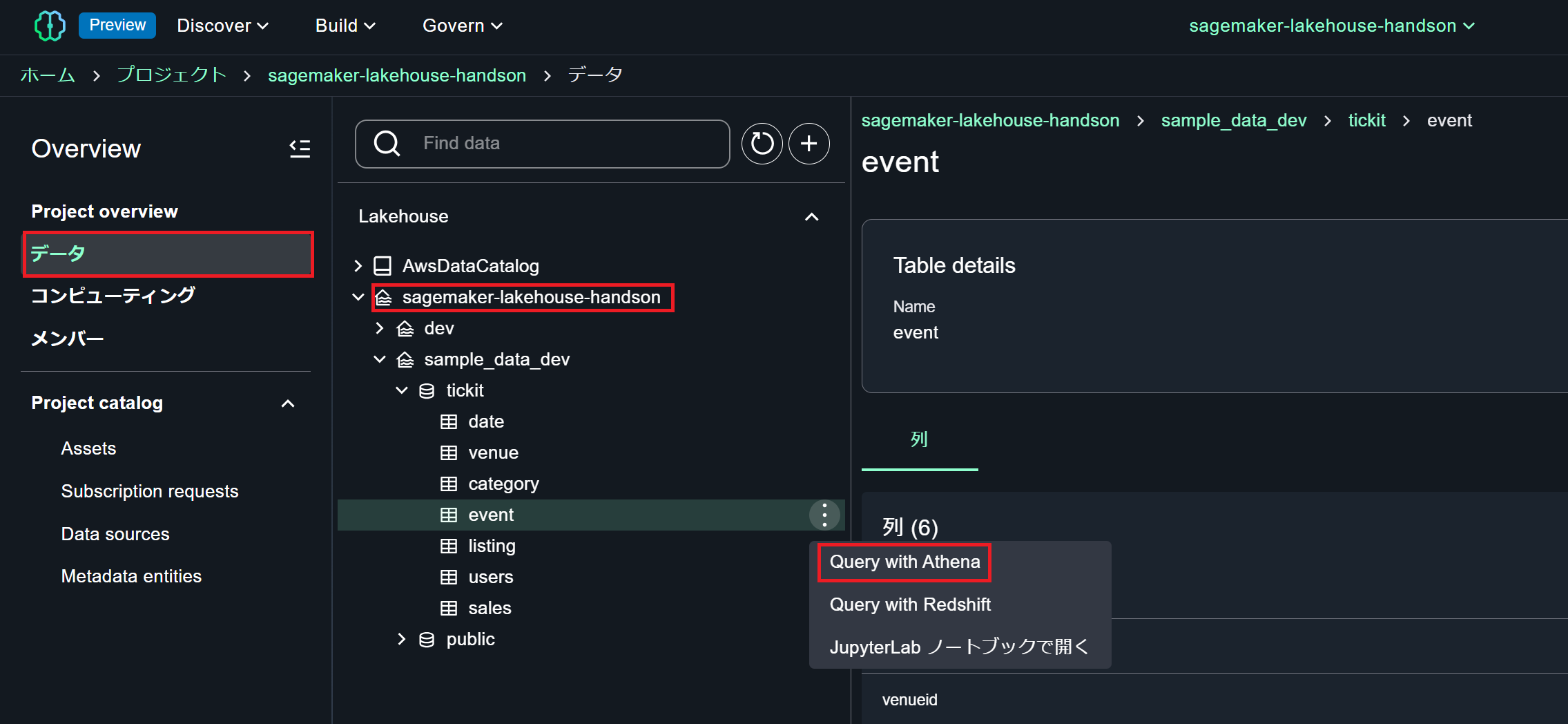
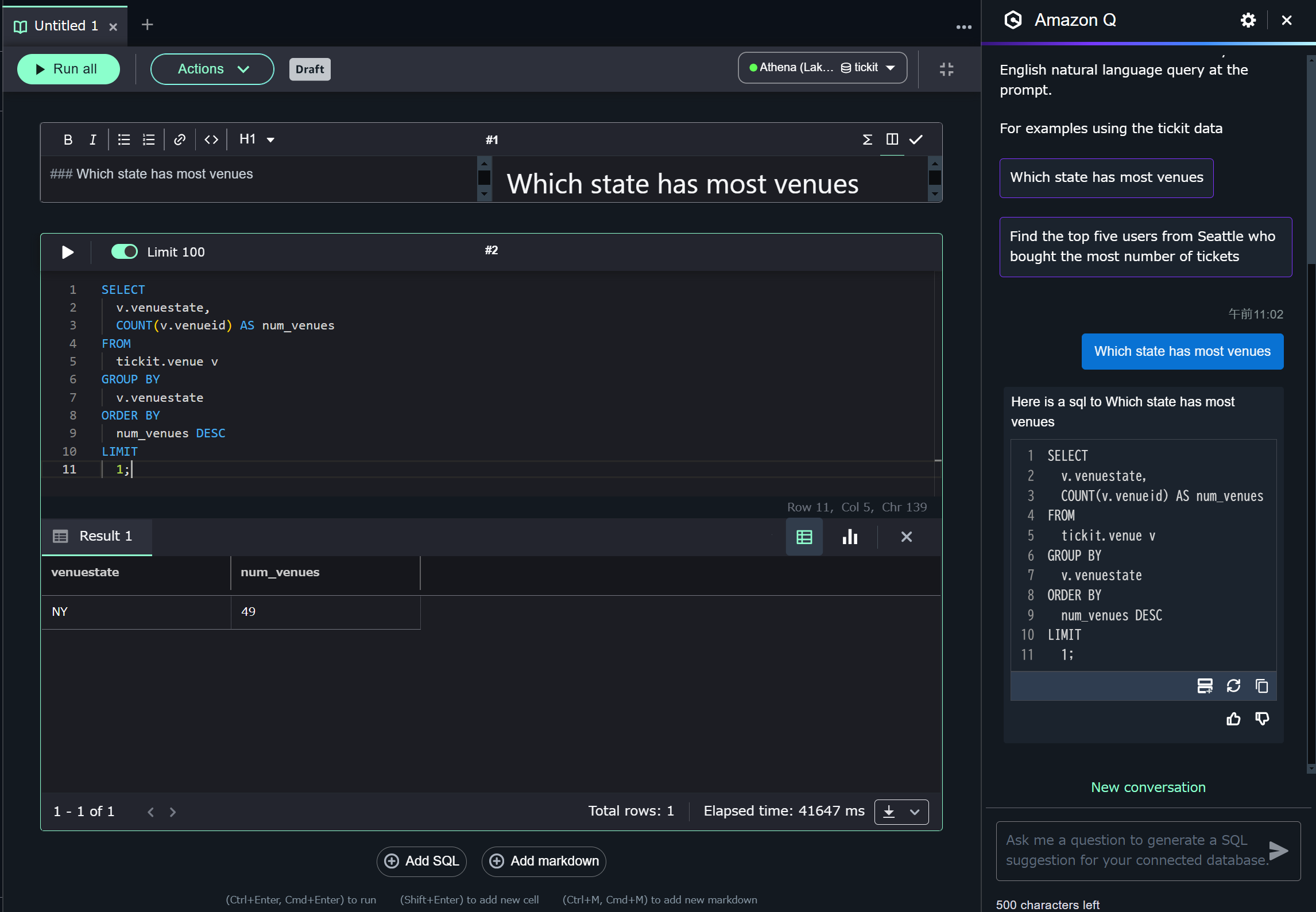
select 文が自動的に発行され、結果が返ってきます。Lakehouse に登録した Redshift のデータを Athena からクエリ実行できました!

クエリは Unified Studio プロジェクト作成時に自動作成された Athena Workgroup で実行されます
Unified Studio は Amazon Q Developer ともネイティブに統合されているため、もちろん自然言語からクエリを生成し、実行することもできます。
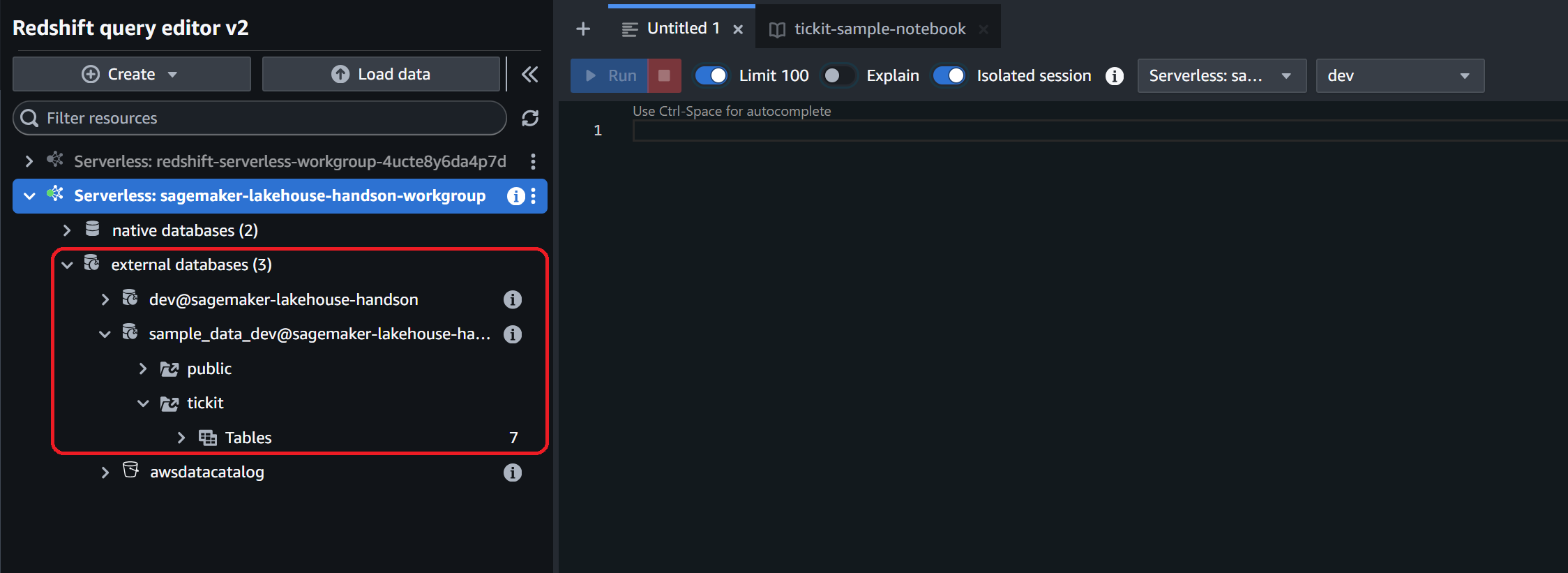
また Lake Formation のカタログに登録されたことで、Redshift 上でも external databases として認識されるようになります。
ハンズオン手順は以上です。SageMaker Lakehouse は、S3 や Redshift、フェデレーション先のリソース (BigQuery や Snowflake など) に、シームレスなアクセスを提供します。このハンズオンはその機能の一部分のみ体験するものですが、どなたかの参考になれば幸いです。