概要
前回に引き続いてworld bankからのグラフの書き方である。
今回はpandasの使い方もちょっとウンチクしてみようか・・
まずはサンプル
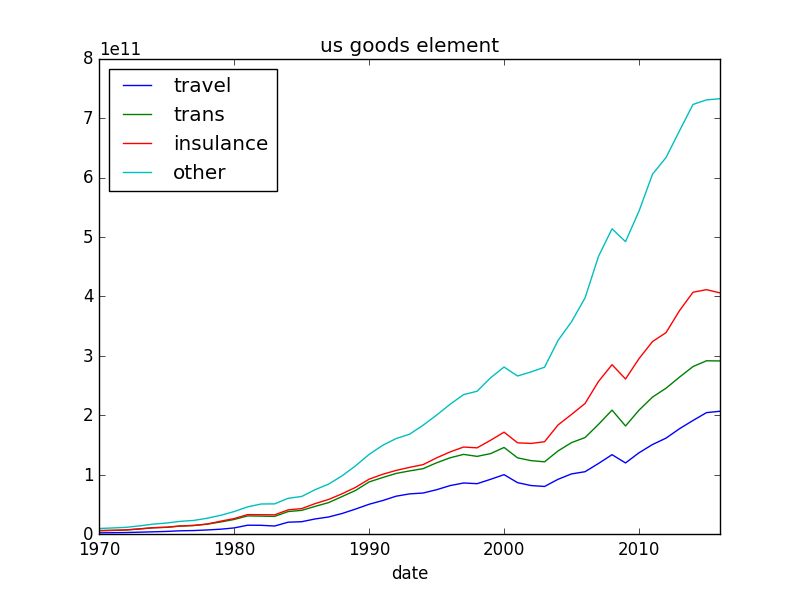
今回は、このグラフである。
簡単かと思うんだが、けっこう悩んだ。プログラムはこんな感じ
coding:utf-8
import wbdata
import pandas
import matplotlib.pyplot as plt
cc = ["CHN"]
ic = {"TX.VAL.TRVL.ZS.WT":"travel","TX.VAL.TRAN.ZS.WT":"trans","TX.VAL.INSF.ZS.WT":"insulance",
"TX.VAL.OTHR.ZS.WT":"other"}
df = wbdata.api.get_dataframe(ic,country=cc,convert_date=False)
ic1={'TX.VAL.SERV.CD.WT':'service'}
df2 = wbdata.api.get_dataframe(ic1,country=cc,convert_date=False)
dfu00 = df2.unstack(0)
dfu0 = dfu00.unstack(0)
dfu = df.unstack(level=0)
dfu2 = dfu.unstack(0)
dfu3 = pandas.DataFrame(dfu0.values*dfu2.values/100,columns=dfu2.columns,index=dfu2.index)
dfu3[["travel","trans","insulance","other"]].sort_index(0)['1970':'2016'].plot(stacked=True);
plt.legend(loc='best');
plt.title("us goods element")
plt.show()
ウンチク箇所
今回は4つの指標を取り出して、その合計を計算しているグラフで
ある。
.plot(stacked=True)というので簡単にできる。
そして、その4つの指標が%なので、合計数と掛け算をしないといけない。
そこが、
dfu3 = pandas.DataFrame(dfu0.values*dfu2.values/100,columns=dfu2.columns,index=dfu2.index)
というところである。
また、unstackを2回実施するというのも、ちょっとコツである。
unstackの意味
ここは、pandasのseriesというデータ形式の問題である。
wbdata.api.get_dataframe
では、seriesという形式でdataframeに格納する。
っで、seriesというのはなんだ?というと、1次元の配列である。
簡単にいうと、以下のような構造で格納する
travel CHI 1960 v1
1961 v2
1962 v3
・・
2016 v56
trans CHI 1960 vv1
1961 vv2
1962 vv3
・・
2016 vv56
列としては1列しかなく、travel,CHI,1960というのは、行のラベルの意味しかないということになる。
この「行のラベル」をindexというデータで表現しているのが、sereisである。
まあ、簡単にいうと、データを縦に並べただけということである。
そこで、unstackをするとまずは、CHIが列になる。
普通は、国別にグラフを書くので、unstackは1回だが、今回は国別
ではなく、"travel","trans","insulance","other"を列に
したいので、2回のunstackが必要であるということである。
わかったかなあ?
そういえば・・
プログラムはcc=["CHN"]になっているが、グラフと同じにするにはUSにしないと同じにならないので念のため